使用Jenkins进行持续集成与测试
发布时间: 2024-03-10 17:17:34 阅读量: 71 订阅数: 47 

持续集成工具jenkins
# 1. 什么是持续集成与测试
## 1.1 什么是持续集成
持续集成是一种软件开发实践,旨在通过频繁地将代码集成到共享存储库中,并进行自动化构建和测试,从而快速发现和解决集成错误。它的核心理念是尽早地发现问题,并确保开发人员的代码变更不会破坏现有功能。
## 1.2 持续集成的优势
- 快速发现和解决错误:持续集成能够快速反馈代码集成是否成功,并能够快速发现潜在的问题。
- 自动化构建和测试:通过自动化构建和测试,能够降低手动操作的出错几率,提高开发效率。
- 提高代码质量:持续集成可以帮助开发团队及时发现和解决代码质量问题,减少技术债务的积累。
## 1.3 测试在持续集成中的重要性
在持续集成中,测试起着至关重要的作用。通过自动化测试,可以有效地验证代码的正确性和稳定性,帮助开发人员保证代码变更不会引入新的问题。因此,持续集成与测试紧密结合,相辅相成,共同推动软件开发过程的持续改进与稳定性提升。
# 2. Jenkins简介与安装
Jenkins是一款开源的持续集成工具,可以帮助开发团队自动化地进行构建、测试和部署。本章将介绍Jenkins的简介与安装步骤。
### 2.1 什么是Jenkins
Jenkins是一个基于Java开发的持续集成工具,最初是Hudson项目的一部分,后来由于某些分歧而分拆出来。Jenkins提供了一种易于扩展的插件系统,支持构建、部署和自动化测试等各种操作。
### 2.2 Jenkins的优势与特点
- **易于安装与配置**:Jenkins支持各种平台,包括Linux、Windows和Mac OS等,安装过程简单快捷。
- **丰富的插件支持**:Jenkins拥有大量的插件,可以实现与各种开发、构建、测试工具的集成,满足各种需求。
- **强大的可扩展性**:Jenkins提供了丰富的API和插件开发文档,支持自定义插件来扩展功能。
- **可视化界面**:Jenkins提供直观的Web界面,便于用户进行操作和管理。
- **社区和生态**:Jenkins拥有庞大的用户社区和生态圈,有丰富的资源和支持。
### 2.3 在Linux/Windows上安装Jenkins的步骤指南
#### 在Linux上安装Jenkins
1. 添加Jenkins的APT仓库到系统源列表中:
```shell
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
```
2. 安装Jenkins及其依赖项:
```shell
sudo apt update
sudo apt install openjdk-8-jdk jenkins
```
3. 启动Jenkins服务并设置开机自启动:
```shell
sudo systemctl start jenkins
sudo systemctl enable jenkins
```
4. 访问Jenkins Web界面:在浏览器中输入`http://your-server-ip:8080`,根据屏幕指引完成初始化设置。
#### 在Windows上安装Jenkins
1. 下载Jenkins的Windows安装包:访问[Jenkins官方网站](https://www.jenkins.io/download/)下载Windows安装包。
2. 双击安装包并根据向导进行安装。
3. 安装完成后,Jenkins会自动启动并在系统托盘中显示Jenkins图标。
4. 点击图标打开Jenkins Web界面,根据屏幕指引完成初始化设置。
通过上述步骤,您可以在Linux和Windows系统上成功安装Jenkins,并开始使用它进行持续集成与测试。
# 3. 使用Jenkins进行持续集成
在本章中,我们将深入探讨如何使用Jenkins进行持续集成。首先我们会介绍Jenkins的基本概念,然后讲解如何配置Jenkins进行自动构建,并分享使用Jenkins进行持续集成的最佳实践。
#### 3.1 Jenkins的基本概念
Jenkins是一个开源的持续集成工具,可以用于自动化构建、测试和部署软件项目。它支持各种编程语言和工具,并提供了丰富的插件生态系统。以下是几个重要的概念:
- Jobs(任务):Jenkins中的最基本单元,用于描述一个构建过程,并记录构建的结果。
- Builds(构建):Job执行的一个实例被称为Build,它包括了构建的输入、输出以及构建过程的日志。
- Plugins(插件):Jenkins通过插件来扩展功能,例如集成不同的版本控制工具、构建工具、测试工具等。
#### 3.2 配置Jenkins进行自动构建
在Jenkins中配置自动构建的步骤如下:
1. 登录Jenkins并创建一个新的Job。
2. 配置源代码管理,如Gi

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB C4.5算法性能提升秘籍】:代码优化与内存管理技巧

# 摘要
本论文首先概述了MATLAB中C4.5算法的基础知识及其在数据挖掘领域的应用。随后,探讨了MATLAB代码优化的基础,包括代码效率原理、算法性能评估以及优化技巧。深入分析了MATLAB内存管理的原理和优化方法,重点介绍了内存泄漏的检测与预防
【稳定性与混沌的平衡】:李雅普诺夫指数在杜芬系统动力学中的应用

# 摘要
本文旨在介绍杜芬系统的概念与动力学基础,深入分析李雅普诺夫指数的理论和计算方法,并探讨其在杜芬系统动力学行为和稳定性分析中的应用。首先,本文回顾了杜芬系统的动力学基础,并对李雅普诺夫指数进行了详尽的理论探讨,包括其定义、性质以及在动力系统中的角色。
QZXing在零售业中的应用:专家分享商品快速识别与管理的秘诀

# 摘要
QZXing作为一种先进的条码识别技术,在零售业中扮演着至关重要的角色。本文全面探讨了QZXing在零售业中的基本概念、作用以及实际应用。通过对QZXing原理的阐述,展示了其在商品快速识别中的核心技术优势,例如二维码识别技术及其在不同商品上的应用案例。同时,分析了QZXing在提高商品识别速度和零售效率方面的实际效果
【AI环境优化高级教程】:Win10 x64系统TensorFlow配置不再难

# 摘要
本文详细探讨了在Win10 x64系统上安装和配置TensorFlow环境的全过程,包括基础安装、深度环境配置、高级特性应用、性能调优以及对未来AI技术趋势的展望。首先,文章介绍了如何选择合适的Python版本以及管理虚拟环境,接着深入讲解了GPU加速配置和内存优化。在高级特性应用
【宇电温控仪516P故障解决速查手册】:快速定位与修复常见问题

# 摘要
本文全面介绍了宇电温控仪516P的功能特点、故障诊断的理论基础与实践技巧,以及常见故障的快速定位方法。文章首先概述了516P的硬件与软件功能,然后着重阐述了故障诊断的基础理论,包括故障的分类、系统分析原理及检测技术,并分享了故障定位的步骤和诊断工具的使用方法。针对516P的常见问题,如温度显示异常、控制输出不准确和通讯故障等,本文提供了详尽的排查流程和案例分析,并探讨了电气组件和软件故障的修复方法。此外
【文化变革的动力】:如何通过EFQM模型在IT领域实现文化转型

# 摘要
EFQM模型是一种被广泛认可的卓越管理框架,其在IT领域的适用性与实践成为当前管理创新的重要议题。本文首先概述了EFQM模型的核心理论框架,包括五大理念、九个基本原则和持续改进的方法论,并探讨了该模型在IT领域的具体实践案例。随后,文章分析了EFQM模型如何在IT企业文化中推动创新、强化团队合作以及培养领导力和员工发展。最后,本文研究了在多样化
RS485系统集成实战:多节点环境中电阻值选择的智慧
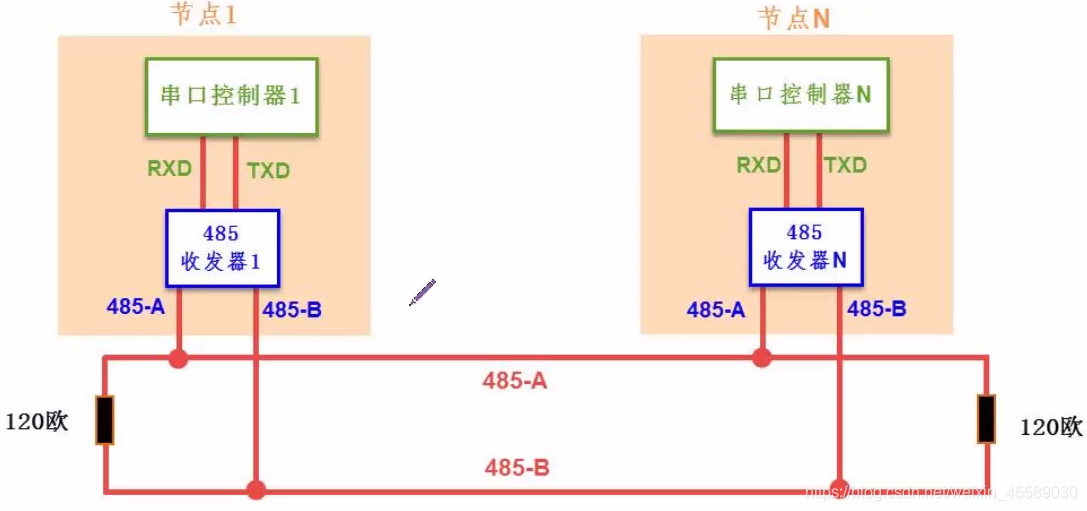
# 摘要
本文系统性地探讨了RS485系统集成的基础知识,深入解析了RS485通信协议,并分析了多节点RS485系统设计中的关键原则。文章
【高级电磁模拟】:矩量法在复杂结构分析中的决定性作用
# 摘要
本文全面介绍了电磁模拟与矩量法的基础理论及其应用。首先,概述了矩量法的基本概念及其理论基础,包括电磁场方程和数学原理,随后深入探讨了积分方程及其离散化过程。文章着重分析了矩量法在处理多层介质、散射问题及电磁兼容性(EMC)方面的应用,并通过实例展示了其在复杂结构分析中的优势。此外,本文详细阐述了矩量法数值模拟实践,包括模拟软件的选用和模拟流程,并对实际案例
SRIO Gen2在云服务中的角色:云端数据高效传输技术深度支持

# 摘要
本文旨在深入探讨SRIO Gen2技术在现代云服务基础架构中的应用与实践。首先,文章概述了SRIO Gen2的技术原理,及其相较于传统IO技术的显著优势。然后,文章详细分析了SRIO Gen2在云服务中尤其是在数据中心的应用场景,并提供了实际案例研
先农熵在食品质量控制的重要性:确保食品安全的科学方法

# 摘要
本文深入探讨了食品质量控制的基本原则与重要性,并引入先农熵理论,阐述其科学定义、数学基础以及与热力学第二定律的关系。通过对先农熵在食品稳定性和保质期预测方面作用的分析,详细介绍了先农熵测量技术及其在原料质量评估、加工过程控制和成品质量监控中的应用。进一步,本文探讨了先农熵与其他质量控制方法的结合,以及其在创新食品保存技术和食品安全法规标准中的应用。最后,通过案例分析,总结了先农熵在食品质量控制中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )