学习C语言中的文件操作与IO操作
发布时间: 2024-02-28 02:39:33 阅读量: 47 订阅数: 29 

Linux文件IO操作例程
# 1. I. 简介
## A. C语言中文件操作的重要性
在C语言中,文件操作是非常重要的一部分。通过文件操作,我们可以读取外部文件中的数据,也可以将程序中生成的数据写入到文件中保存。文件操作还可以用于数据持久化,以及跟其他程序进行数据交换等场景。因此,掌握C语言中的文件操作对于开发实际应用非常重要。
## B. 为什么需要学习IO操作
在计算机编程中,IO操作指的是输入输出操作。文件操作是IO操作的一种,它涉及到程序与外部存储设备(如硬盘、U盘、网络文件等)之间的数据交互。学习IO操作有助于我们更好地理解计算机系统中数据的流动,提高程序的灵活性和适用性。通过学习IO操作,可以更好地处理文件、流和网络中的数据,从而实现更多样化的应用程序。
接下来,我们将深入学习C语言中文件操作与IO操作的具体内容。
# 2. 文件基本操作
在C语言中,文件操作是非常重要的一部分,它允许我们在程序中对文件进行读取和写入操作。文件的操作包括打开文件、关闭文件、读写文件以及移动文件指针。接下来我们将逐一介绍这些基本的文件操作。
### A. 打开文件
在C语言中,我们使用`fopen`函数来打开文件。`fopen`函数接受两个参数:文件名和打开模式。打开模式可以是`r`(只读)、`w`(只写)、`a`(追加)、`r+`(读写)、`w+`(读写,先截断文件)、`a+`(读写,追加)等。
```c
// 示例代码:以只读模式打开文件
#include <stdio.h>
int main() {
FILE *file;
file = fopen("example.txt", "r");
if (file == NULL) {
printf("无法打开文件\n");
return 1;
}
// 其他操作...
fclose(file); // 关闭文件
return 0;
}
```
在示例代码中,我们使用`fopen`函数以只读模式打开文件。如果文件打开失败,我们将输出错误消息并返回。
### B. 关闭文件
在C语言中,我们使用`fclose`函数来关闭文件。关闭文件是一个良好的编程习惯,它可以释放系统资源并确保文件操作的安全性。
```c
// 示例代码:关闭文件
#include <stdio.h>
int main() {
FILE *file;
file = fopen("example.txt", "r");
if (file == NULL) {
printf("无法打开文件\n");
return 1;
}
// 文件操作...
fclose(file); // 关闭文件
return 0;
}
```
在示例代码中,我们使用`fclose`函数关闭已打开的文件。
### C. 读写文件
在C语言中,我们使用`fprintf`和`fscanf`来进行文件的读写操作,这两个函数与`printf`和`scanf`十分相似。另外,`fputc`和`fgetc`函数可以用于单个字符的读写操作。
```c
// 示例代码:写入文件
#include <stdio.h>
int main() {
FILE *file;
file = fopen("example.txt", "w");
fprintf(file, "Hello, File IO!"); // 将内容写入文件
fclose(file); // 关闭文件
return 0;
}
```
在示例代码中,我们使用`fprintf`将内容写入文件。
### D. 移动文件指针
在C语言中,我们使用`fseek`函数来移动文件指针,以便进行文件的随机读写操作。
```c
// 示例代码:移动文件指针
#include <stdio.h>
int main() {
FILE *file;
file = fopen("example.txt", "r");
fseek(file, 5, SEEK_SET); // 从文件开头偏移5个字节
// 文件操作...
fclose(file); // 关闭文件
return 0;
}
```
在示例代码中,我们使用`fseek`函数将文件指针从文件开头偏移5个字节处。
以上便是文件基本操作的介绍,包括打开文件、关闭文件、读写文件和移动文件指针。在实际应用中,这些操作可以帮助我们处理各种文件操作需求。
# 3. III. 文件操作的权限与错误处理
在文件操作过程中,我们经常需要考虑文件的权限设置以及错误处理。文件的权限设置可以控制对文件的读、写、执行等操作,而错误处理则能帮助我们在程序运行中更好地处理异常情况。
#### A. 文件权限设置
在C语言中,文件权限可以通过`fopen()`函数的第二个参数来设置。常见的权限参数包括:
- "r":只读模式,文件必须存在
- "w":只写模式,如果文件存在则清空文件内容,如果文件不存在则创建文件
- "a":追加模式,如果文件存在则将数据追加到文件末尾,如果文件不存在则创建文件
- "r+":读写模式,文件必须存在
- "w+":读写模式,如果文件存在则清空文件内容,如果文件不存在则创建文件
- "a+":读写模式,如果文件存在则将数据追加到文件末尾,如果文件不存在则创建文件
通过这些权限设置,我们可以灵活地控制文件的读写权限和创建方式。
#### B. 文件操作错误处理
在C语言中,文件操作可能会出现各种错误,我们可以通过`errno`全局变量来获取错误码,通过`perror()`函数来打印错误信息。另外,我们还可以通过`ferror()`函数来检查文件操作是否出现了错误。
#### C. 文件结尾标记
在C语言中,文件的结尾通常由`EOF`标记表示,当文件读到结尾时,`EOF`标记将会被返回。因此,在文件读取操作中,我们通常会使用`feof()`函数来检查是否已经到达文件结尾,以便正确处理文件读取循环的结束条件。
以上就是文件操作的权限设置、错误处理和文件结尾标记的相关内容,这些是在进行文件操作时需要重点关注和处理的问题。接下来,我们将详细介绍文件读写操作及其实例练习。
# 4. IV. 文件读操作
在C语言中,文件读操作是非常常见和重要的操作之一。通过文件读操作,我们可以从文件中获取数据,并对数据进行处理和分析。本节将介绍文件读操作的几种常见方法,包括逐行读取文件、读取整个文件和格式化读取文件的方法。
#### A. 逐行读取文件
逐行读取文件是一种常见的文件读操作,通常用于读取文本文件的内容。在C语言中,可以使用`fgets()`函数来逐行读取文件的内容。
下面是一个示例代码,演示了如何逐行读取文件:
```c
#include <stdio.h>
int main() {
FILE *file;
char buffer[255];
// 打开文件
file = fopen("example.txt", "r");
// 逐行读取文件内容
while (fgets(buffer, 255, file) != NULL) {
printf("%s", buffer);
}
// 关闭文件
fclose(file);
return 0;
}
```
代码解析:
- 首先,通过`fopen()`函数打开名为"example.txt"的文件,并指定以只读模式打开(`"r"`)。
- 然后,使用`fgets()`函数逐行读取文件内容,将每行的内容存储在`buffer`数组中,并通过`printf()`函数输出到控制台。
- 最后,使用`fclose()`函数关闭文件。
#### B. 读取整个文件
除了逐行读取文件,有时候我们也需要一次性读取整个文件的内容。在C语言中,可以使用`fread()`函数来实现这一操作。
下面是一个示例代码,演示了如何读取整个文件的内容:
```c
#include <stdio.h>
int main() {
FILE *file;
char buffer[255];
// 打开文件
file = fopen("example.txt", "r");
// 读取整个文件内容
fread(buffer, sizeof(char), 255, file);
// 输出文件内容
printf("%s", buffer);
// 关闭文件
fclose(file);
return 0;
}
```
代码解析:
- 首先,通过`fopen()`函数打开名为"example.txt"的文件,并指定以只读模式打开(`"r"`)。
- 然后,使用`fread()`函数读取文件内容,将整个文件的内容存储在`buffer`数组中,并通过`printf()`函数输出到控制台。
- 最后,使用`fclose()`函数关闭文件。
#### C. 格式化读取文件
有时候,文件中的数据可能是按照一定格式排列的,比如数字、字符串等。在C语言中,可以使用`fscanf()`函数按照指定的格式从文件中读取数据。
下面是一个示例代码,演示了如何格式化读取文件的内容:
```c
#include <stdio.h>
int main() {
FILE *file;
char name[50];
int age;
// 打开文件
file = fopen("example.txt", "r");
// 格式化读取文件内容
fscanf(file, "%s %d", name, &age);
// 输出读取的数据
printf("Name: %s, Age: %d\n", name, age);
// 关闭文件
fclose(file);
return 0;
}
```
代码解析:
- 首先,通过`fopen()`函数打开名为"example.txt"的文件,并指定以只读模式打开(`"r"`)。
- 然后,使用`fscanf()`函数按照指定的格式读取文件内容,将读取的数据存储在`name`和`age`变量中,并通过`printf()`函数输出到控制台。
- 最后,使用`fclose()`函数关闭文件。
以上是文件读操作的几种常见方法,通过这些方法,我们可以灵活处理文件中的数据,并实现各种文件读取需求。
# 5. V. 文件写操作
文件写操作是文件操作中非常重要的一部分,它包括了向文件中写入数据、追加内容到文件以及文件格式化写入。在C语言中,文件写操作使用的函数包括fwrite()、fprintf()等,下面我们将详细介绍这些文件写操作的内容。
**A. 写入文件**
写入文件是指向已经打开的文件写入数据。在C语言中,可以使用fwrite()函数进行文件写操作。这个函数的原型如下:
```c
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
```
- ptr: 指向要被写入的数据的指针
- size: 要被写入的每个数据项的大小,以字节为单位
- nmemb: 要被写入的数据项的个数
- stream: 指向要被写入的文件的指针
下面是一个简单的例子,演示了如何使用fwrite()向文件中写入数据:
```c
#include <stdio.h>
int main() {
FILE *fp;
char data[] = "Hello, this is a test for fwrite!\n";
fp = fopen("test.txt", "w");
fwrite(data, sizeof(char), strlen(data), fp);
fclose(fp);
return 0;
}
```
这段代码会向名为test.txt的文件中写入字符串"Hello, this is a test for fwrite!\n",然后关闭文件。需要注意的是,如果指定的文件不存在,该函数会自动创建新文件。
**B. 追加内容到文件**
除了写入文件外,有时候我们需要在已有文件的末尾追加内容,这时可以使用fopen()函数中的 "a" 模式或者使用fseek()函数将文件指针移动到文件末尾,然后再使用fwrite()向文件中写入数据。
下面是一个使用 "a" 模式追加内容到文件的例子:
```c
#include <stdio.h>
int main() {
FILE *fp;
char data[] = "This content will be appended to the end of the file!\n";
fp = fopen("test.txt", "a");
fwrite(data, sizeof(char), strlen(data), fp);
fclose(fp);
return 0;
}
```
这段代码会打开名为test.txt的文件,并在文件末尾追加字符串"This content will be appended to the end of the file!\n",然后关闭文件。
**C. 文件格式化写入**
有时候,我们需要将变量以特定格式写入文件,这时可以使用fprintf()函数进行文件格式化写入。下面是一个例子:
```c
#include <stdio.h>
int main() {
FILE *fp;
int num = 123;
float fnum = 3.14;
fp = fopen("test.txt", "w");
fprintf(fp, "This is a number: %d, and this is a float number: %.2f\n", num, fnum);
fclose(fp);
return 0;
}
```
这段代码会将整型变量num和浮点型变量fnum以特定格式写入文件test.txt中,并在写入后关闭文件。
以上就是文件写操作的内容,包括了常规的写入文件、追加内容到文件以及文件格式化写入。通过这些操作,我们可以实现对文件的灵活处理。
# 6. VI. 文件操作实例与练习
在本章节中,我们将通过具体的示例和练习来实践文件操作的知识。首先我们会展示文本文件的读写操作示例,然后是二进制文件的读写操作示例。最后,我们将提供一些练习题目,并附上相应的解答。
#### A. 文本文件的读写操作示例
下面是一个Python的示例,演示如何进行文本文件的读写操作:
```python
# 打开一个文本文件进行写入
file = open("example.txt", "w")
file.write("Hello, this is a text file example.")
file.close()
# 打开刚才写入的文件进行读取
file = open("example.txt", "r")
content = file.read()
print("文件内容:", content)
file.close()
```
**代码总结:** 上述代码首先打开一个名为`example.txt`的文本文件,以写入模式(`w`)向文件中写入一行文本,然后再以读取模式(`r`)重新打开文件,读取并打印文件内容。
**结果说明:** 程序将输出“文件内容:Hello, this is a text file example.”,表示文件读取成功。
#### B. 二进制文件的读写操作示例
接下来是一个Java的示例,演示如何进行二进制文件的读写操作:
```java
import java.io.*;
public class BinaryFileExample {
public static void main(String[] args) {
try {
// 写入二进制数据到文件
FileOutputStream fos = new FileOutputStream("example.bin");
DataOutputStream dos = new DataOutputStream(fos);
dos.writeInt(42);
dos.close();
// 读取二进制数据
FileInputStream fis = new FileInputStream("example.bin");
DataInputStream dis = new DataInputStream(fis);
int num = dis.readInt();
System.out.println("读取到的数据:" + num);
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
**代码总结:** 该Java程序首先以二进制方式向文件`example.bin`写入整数42,然后再以相同的方式读取文件中的数据,并将其输出。
**结果说明:** 运行程序将输出“读取到的数据:42”,表示成功读取了二进制文件中的数据。
#### C. 练习题目及解答
1. 编写一个Python程序,从`input.txt`中读取整数,计算它们的和,并将结果写入`output.txt`中。
**解答:**
```python
# 读取input.txt中的整数并计算和
input_file = open("input.txt", "r")
numbers = input_file.read().split()
sum_numbers = sum(map(int, numbers))
input_file.close()
# 将计算结果写入output.txt
output_file = open("output.txt", "w")
output_file.write(str(sum_numbers))
output_file.close()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
QPSK调制解调信号处理艺术:数学模型与算法的实战应用
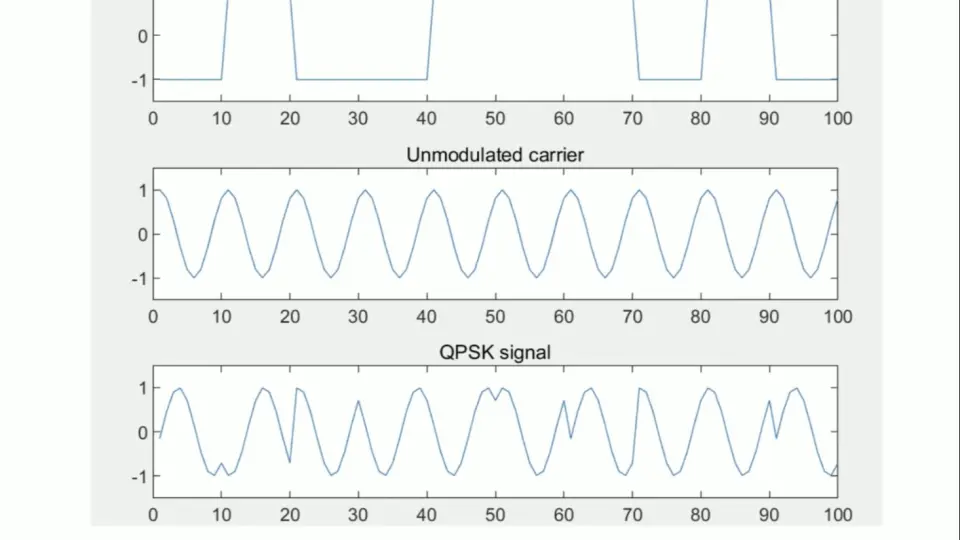
# 摘要
本文系统地探讨了QPSK(Quadrature Phase Shift Keying)调制解调技术的基础理论、实现算法、设计开发以及在现代通信中的应用。首先介绍了QPSK调制解调的基本原理和数学模型,包括信号的符号表示、星座图分析以及在信号处理中的应用。随后,深入分析了QPSK调制解调算法的编程实现步骤和性能评估,探讨了算法优化与
Chan氏算法之信号处理核心:揭秘其在各领域的适用性及优化策略

# 摘要
Chan氏算法作为信号处理领域的先进技术,其在通信、医疗成像、地震数据处理等多个领域展现了其独特的应用价值和潜力。本文首先概述了Cha
全面安防管理解决方案:中控标软件与第三方系统的无缝集成

# 摘要
随着技术的进步,安防管理系统集成已成为构建现代化安全解决方案的重要组成部分。本文首先概述了安防管理系统集成的概念与技术架构,强调了中控标软件在集成中的核心作用及其扩展性。其次,详细探讨了与门禁控制、视频监控和报警系统的第三方系统集成实践。在集成过程中遇到的挑战,如数据安全、系统兼容性问题以及故障排除等,并提出相应的对策。最后,展望了安防集成的未来趋势,包括人工智能、物联网技术
电力系统继电保护设计黄金法则:ETAP仿真技术深度剖析
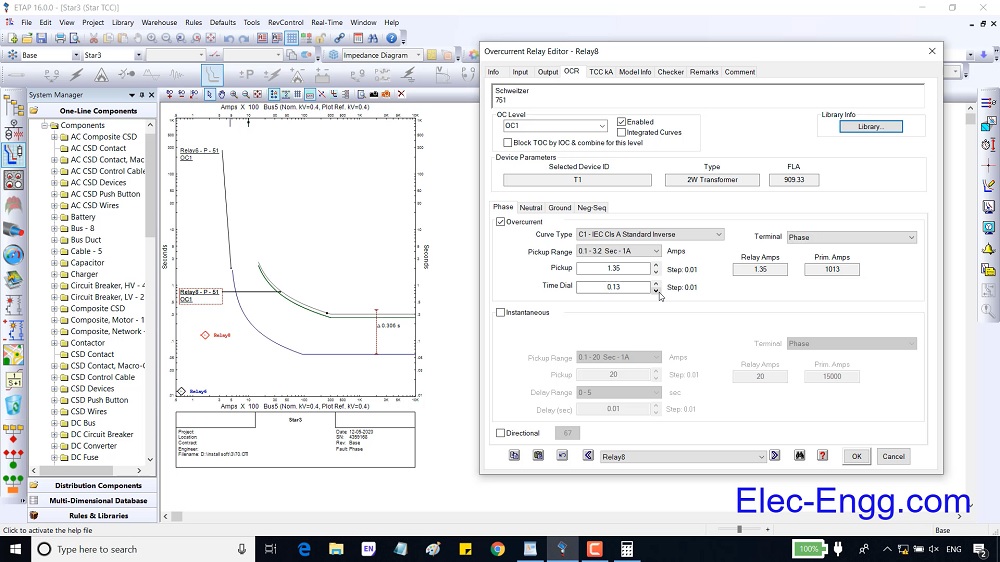
# 摘要
本文对电力系统继电保护进行了全面概述,详细介绍了ETAP仿真软件在继电保护设计中的基础应用与高级功能。文章首先阐述了继电保护的基本理论、设计要求及其关键参数计算,随后深入探讨了ETAP在创建电力系统模型、故障分析、保护方案配置与优化方面的应用。文章还分析了智能化技术、新能源并网对继电保护设计的影响,并展望了数字化转型下的新挑战。通过实际案例分析
进阶技巧揭秘:新代数控数据采集优化API性能与数据准确性

# 摘要
数控数据采集作为智能制造的核心环节,对提高生产效率和质量控制至关重要。本文首先探讨了数控数据采集的必要性与面临的挑战,并详细阐述了设计高效数据采集API的理论基础,包括API设计原则、数据采集流程模型及安全性设计。在实践方面,本文分析了性能监控、数据清洗预处理以及实时数据采集的优化方法。同时,为提升数据准确性,探讨了数据校验机制、数据一致性
从零开始学FANUC外部轴编程:基础到实战,一步到位

# 摘要
本文旨在全面介绍FANUC外部轴编程的核心概念、理论基础、实践操作、高级应用及其在自动化生产线中的集成。通过系统地探讨FANUC数控系统的特点、外部轴的角色以及编程基础知识,本文提供了对外部轴编程技术的深入理解。同时,本文通过实际案例,演示了基本与复杂的外部轴编程技巧,并提出了调试与故障排除的有效方法。文章进一步探讨了外部轴与工业机器人集成的高级功能,以及在生产线自动化
GH Bladed 高效模拟技巧:中级到高级的快速进阶之道

# 摘要
GH Bladed是一款专业的风力发电设计和模拟软件,广泛应用于风能领域。本文首先介绍了GH Bladed的基本概念和基础模拟技巧,涵盖软件界面、参数设置及模拟流程。随后,文章详细探讨了高级模拟技巧,包括参数优化和复杂模型处理,并通过具体案例分析展示了软件在实际项目中的应
【跨平台驱动开发挑战】:rockusb.inf在不同操作系统的适应性分析

# 摘要
本文旨在深入探讨跨平台驱动开发领域,特别是rockusb.inf驱动在不同操作系统环境中的适配性和性能优化。首先,对跨平台驱动开发的概念进行概述,进而详细介绍rockusb.inf驱动的核心功能及其在不同系统中的基础兼容性。随后,分别针对Windows、Linux和macOS操作系统下rockusb.inf驱动的适配问题进行了深入分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )