探讨C语言中的模块化编程与库文件使用
发布时间: 2024-02-28 02:47:38 阅读量: 48 订阅数: 27 
# 1. 引言
## 1.1 介绍C语言的重要性和应用领域
C语言作为一种广泛应用于系统编程和嵌入式领域的语言,具有高效、跨平台等特点,成为编程学习和应用的重要基础。
## 1.2 简要介绍模块化编程的概念
模块化编程是一种将大型程序划分为小型、功能独立的模块,以便于管理、维护和重用的编程方法。它有助于提高代码的可读性和可维护性,实现代码的组件化和复用性。
## 1.3 概述本文的内容和结构
本文将深入探讨C语言中的模块化编程与库文件的使用,包括模块化编程的优势、原则和方法、标准库文件的使用以及自定义库文件的创建与使用等内容。同时,我们还会分享优化模块化编程与库文件使用的实用技巧和最佳实践。
# 2. C语言中的模块化编程
### 2.1 详细解释模块化编程的定义和优势
模块化编程是一种将程序分解为独立的、相互关联的模块或功能单元的编程方式。在C语言中,模块化编程可以通过使用函数、结构体和文件来实现。
#### 模块化编程的优势包括:
- **代码重用性**:通过将功能封装在模块中,可以在不同的地方重复使用同一段代码,提高开发效率。
- **可维护性**:模块化编程使得代码更易于维护和修改,因为各模块相对独立,修改一个模块不会对其他模块造成影响。
- **可读性**:模块化编程使得代码结构更清晰,易于阅读和理解。
- **团队协作**:对于大型项目来说,不同的模块可以由不同的团队成员负责开发,有利于团队协作。
### 2.2 讨论模块化编程的原则和方法
#### 模块化编程的原则包括:
- **高内聚低耦合**:模块内部的元素彼此紧密联系,模块之间的联系尽可能减少,以降低模块之间的依赖性。
- **单一责任**:每个模块应当只负责一项具体的功能,以保持模块的简洁性和可维护性。
- **接口分离**:模块之间的通信应当通过定义良好的接口来实现,以隔离模块之间的变化。
#### 实现模块化编程的方法包括:
- **函数**:将相关的代码封装在函数中,提供清晰的接口和功能模块。
- **结构体**:通过结构体,可以封装相关数据和函数,实现数据和操作的组合。
- **文件**:将相关的函数和数据定义放在同一个文件中,便于管理和维护。
### 2.3 提供使用模块化编程的实际例子
下面是一个简单的C语言模块化编程示例,实现了一个简单的求和功能:
```c
// 模块1:sum.h
#ifndef SUM_H
#define SUM_H
int sum(int a, int b);
#endif
// 模块2:sum.c
#include "sum.h"
int sum(int a, int b) {
return a + b;
}
// 模块3:main.c
#include <stdio.h>
#include "sum.h"
int main() {
int result = sum(3, 5);
printf("The sum is: %d", result);
return 0;
}
```
在这个例子中,`sum.h`定义了函数`sum`的接口,`sum.c`实现了`sum`函数,`main.c`中调用了`sum`函数,实现了模块化编程的思想。
这个例子展示了模块化编程的优势,代码结构清晰,各模块功能独立,易于维护和扩展。
这就是C语言中模块化编程的基本原则、方法和实际示例。
在接下来的章节中,我们将继续探讨库文件的概念及在C语言中的具体应用。
# 3. C语言中的库文件概述
在C语言编程中,库文件扮演着非常重要的角色。库文件包含了各种函数、数据结构和其他代码,能够被程序员用来简化开发过程、提高代码的复用性和可维护性。
#### 3.1 解释库文件在C语言中的作用和重要性
库文件的主要作用是将功能模块化,使得开发人员可以通过调用库中的函数和数据结构来完成特定任务,而不必重复编写相同的代码。库文件的重要性体现在以下几个方面:
- **代码复用性**:通过使用库文件,可以避免重复编写已经实现过的功能,提高代码的复用性。
- **模块化编程**:库文件可以帮助开发人员将程序分解为逻辑上相对独立的模块,提升代码的组织结构。
- **提高效率**:库文件中通常包含了经过优化的代码,可以提高程序的执行效率和性能。
#### 3.2 介绍不同类型的库文件:静态库和动态库
在C语言中,主要有两种类型的库文件:静态库(Static Library)和动态库(Dynamic Library)。
- **静态库**:在编译时被链接到程序中,程序运行时不再需要独立的库文件,整个库文件的代码被复制到可执行文件中。
- **动态库**:在运行时被加载到内存中,程序在执行时动态链接到库文件,因此可执行文件相对较小。
#### 3.3 讨论库文件的使用场景和注意事项
使用库文件能够极大地简化开发工作,提高代码的组织性和可维护性,但在使用库文件时需要注意以下事项:
- **版本兼容性**:确保所使用的库文件与编译器版本及系统环境兼容。
- **路径设置**:在使用库文件时,需要设置正确的路径以便编译器能够找到相应的库文件。
- **冲突解决**:当多个库文件中包含相同函数或变量时,需要注意命名冲突并进行解决。
库文件的使用可以极大地提高代码开发的效率和质量,合理利用不同类型的库文件能够让程序更加健壮和可扩展。
# 4. 使用标准库文件
C语言中的标准库文件对于开发人员来说至关重要,它提供了丰富的函数和头文件,可以用于各种用途,包括输入输出操作、字符串处理、内存管理等。本章将简要介绍C语言中的标准库文件,并演示如何使用常见的标准库函数和头文件。
#### 4.1 简要介绍C语言中的标准库文件
C语言标准库是C语言的核心部分,包含在C编译器中。它提供了一系列的函数和头文件,为程序开发者提供了丰富的功能和工具。标准库被分为若干个头文件,每个头文件中包含了一组相关的函数原型和宏定义。
#### 4.2 演示如何使用常见的标准库函数和头文件
让我们以一个简单的例子来演示如何使用C语言标准库中的`stdio.h`头文件和其中的`printf()`函数。下面是一个简单的C程序:
```c
#include <stdio.h>
int main() {
printf("Hello, this is a demonstration of using standard library in C.\n");
return 0;
}
```
##### 代码说明
- `#include <stdio.h>`:这行代码包含了`stdio.h`头文件,使得我们可以使用其中定义的函数和宏。
- `printf("Hello, this is a demonstration of using standard library in C.\n");`:这行代码使用`printf()`函数打印一条消息到标准输出。
##### 代码运行结果
当我们编译并运行上述代码时,将会在屏幕上打印出:Hello, this is a demonstration of using standard library in C.
#### 4.3 讨论标准库文件的代码示例和实践应用
通过上述示例程序,我们展示了如何使用C语言标准库中的`printf()`函数,这只是标准库中众多函数和工具的冰山一角。在实际开发中,标准库文件几乎无处不在,我们可以使用其中的函数来进行文件操作、内存分配、数学计算等各种任务。
标准库是C语言的核心,熟练掌握其中的函数和头文件,对于成为一名优秀的C程序员至关重要。当然,随着C语言标准的不断更新,标准库文件也在不断增强和完善,开发者需要不断学习和掌握新的特性和函数。
在下一章中,我们将进一步探讨如何自定义库文件,并应用到实际的项目中,以实现模块化编程和代码复用的目标。
希望这篇文章能够对您有所帮助,如果有任何疑问或建议,欢迎交流讨论。
# 5. 自定义库文件的创建与使用
在C语言中,除了使用标准库文件外,我们还可以创建自定义的库文件来实现代码的模块化和复用。下面将指导如何创建和使用自定义库文件。
#### 5.1 指导如何创建自定义的库文件
要创建自定义的库文件,需要完成以下步骤:
1. 编写自定义的函数或代码块,并将其封装在一个或多个源文件中。
2. 使用编译器将源文件编译成目标文件(.obj或.o)。
3. 使用库管理工具将目标文件打包成库文件(.lib或.a)。
下面是一个简单的示例,假设我们有一个名为`custom_math.c`的源文件包含了自定义的数学函数:
```c
// custom_math.c
int add(int a, int b) {
return a + b;
}
int subtract(int a, int b) {
return a - b;
}
```
#### 5.2 讨论如何在项目中使用自定义的库文件
要在项目中使用自定义的库文件,可以按照以下步骤进行:
1. 创建一个头文件(.h)用于声明自定义函数的原型。
2. 在需要使用这些函数的源文件中包含该头文件。
3. 编译时链接对应的库文件。
下面是一个示例,假设我们有一个名为`custom_math.h`的头文件:
```c
// custom_math.h
#ifndef CUSTOM_MATH_H
#define CUSTOM_MATH_H
int add(int a, int b);
int subtract(int a, int b);
#endif
```
在另一个文件`main.c`中使用这些自定义函数:
```c
// main.c
#include <stdio.h>
#include "custom_math.h"
int main() {
int result1 = add(5, 3);
int result2 = subtract(10, 7);
printf("Addition result: %d\n", result1);
printf("Subtraction result: %d\n", result2);
return 0;
}
```
#### 5.3 提供创建和调用自定义库文件的示例代码
接下来,编译和链接这些文件,生成可执行文件:
```bash
gcc -c custom_math.c -o custom_math.o
gcc main.c custom_math.o -o math_program
./math_program
```
通过以上步骤,我们成功创建并调用了自定义的库文件,实现了代码的模块化和复用。
# 6. 优化模块化编程与库文件的技巧
在软件开发中,优化模块化编程和库文件的使用是提高代码质量和效率的重要一环。通过一些技巧和方法,我们可以使代码更易维护、复用性更高,以下是一些实用的技巧:
#### 6.1 分享优化模块化编程和库文件使用的实用技巧
- **命名规范**:遵循一致的命名规范,使代码更易于理解和管理。
- **单一职责**:确保每个模块或函数只负责一项具体的任务,避免功能过于复杂。
- **模块化设计**:将功能拆分为独立的模块,提高代码的可重用性和可维护性。
- **文档注释**:添加清晰的注释和文档,方便他人理解代码逻辑和使用方式。
#### 6.2 探讨提高代码复用性和可维护性的方法
- **接口设计**:定义清晰的接口,降低模块之间的耦合度,方便替换和升级。
- **封装性**:使用封装尽可能隐藏实现细节,提高安全性和可靠性。
- **代码重构**:定期对代码进行重构,消除冗余和提取共性部分,优化结构。
#### 6.3 总结模块化编程与库文件使用的最佳实践和建议
- **持续学习**:不断学习新的模块化编程技术和最佳实践,保持代码的更新与优化。
- **代码审查**:定期进行代码审查,发现潜在问题并进行改进。
- **测试驱动开发**:采用测试驱动开发的方式编写代码,确保高质量的软件交付。
通过以上技巧和方法,我们可以更好地应用模块化编程和库文件,提高代码的可维护性和可复用性,从而使软件开发工作更加高效和可靠。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
学习率对RNN训练的特殊考虑:循环网络的优化策略

# 1. 循环神经网络(RNN)基础
## 循环神经网络简介
循环神经网络(RNN)是深度学习领域中处理序列数据的模型之一。由于其内部循环结
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
激活函数理论与实践:从入门到高阶应用的全面教程

# 1. 激活函数的基本概念
在神经网络中,激活函数扮演了至关重要的角色,它们是赋予网络学习能力的关键元素。本章将介绍激活函数的基础知识,为后续章节中对具体激活函数的探讨和应用打下坚实的基础。
## 1.1 激活函数的定义
激活函数是神经网络中用于决定神经元是否被激活的数学函数。通过激活函数,神经网络可以捕捉到输入数据的非线性特征。在多层网络结构
Epochs调优的自动化方法
# 1. Epochs在机器学习中的重要性
机器学习是一门通过算法来让计算机系统从数据中学习并进行预测和决策的科学。在这一过程中,模型训练是核心步骤之一,而Epochs(迭代周期)是决定模型训练效率和效果的关键参数。理解Epochs的重要性,对于开发高效、准确的机器学习模型至关重要。
在后续章节中,我们将深入探讨Epochs的概念、如何选择合适值以及影响调优的因素,以及如何通过自动化方法和工具来优化Epochs的设置,从而
【损失函数与随机梯度下降】:探索学习率对损失函数的影响,实现高效模型训练

# 1. 损失函数与随机梯度下降基础
在机器学习中,损失函数和随机梯度下降(SGD)是核心概念,它们共同决定着模型的训练过程和效果。本
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
【批量大小与存储引擎】:不同数据库引擎下的优化考量

# 1. 数据库批量操作的理论基础
数据库是现代信息系统的核心组件,而批量操作作为提升数据库性能的重要手段,对于IT专业人员来说是不可或缺的技能。理解批量操作的理论基础,有助于我们更好地掌握其实践应用,并优化性能。
## 1.1 批量操作的定义和重要性
批量操作是指在数据库管理中,一次性执行多个数据操作命
【算法竞赛中的复杂度控制】:在有限时间内求解的秘籍
# 1. 算法竞赛中的时间与空间复杂度基础
## 1.1 理解算法的性能指标
在算法竞赛中,时间复杂度和空间复杂度是衡量算法性能的两个基本指标。时间复杂度描述了算法运行时间随输入规模增长的趋势,而空间复杂度则反映了算法执行过程中所需的存储空间大小。理解这两个概念对优化算法性能至关重要。
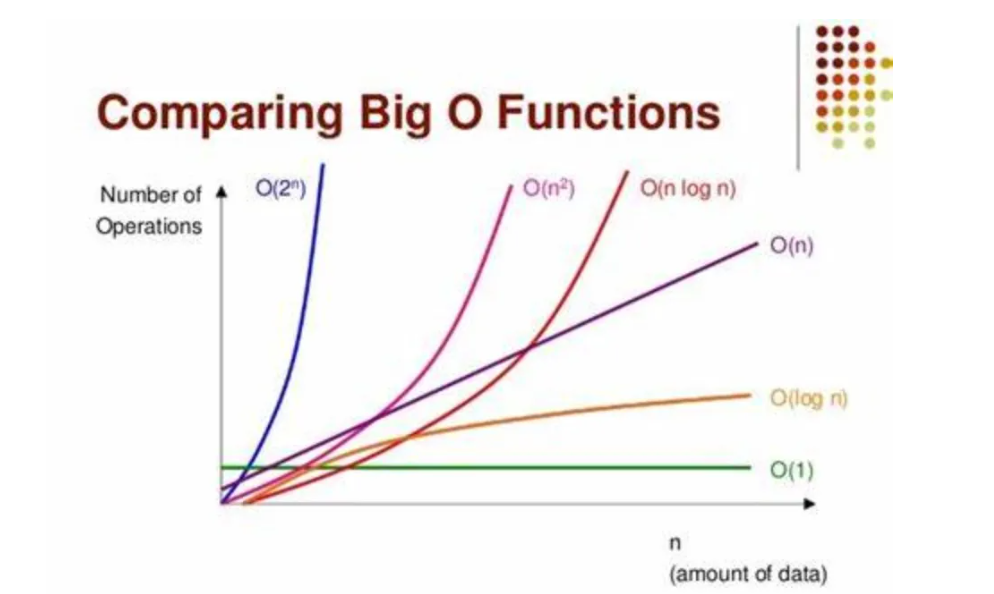
## 1.2 大O表示法的含义与应用
大O表示法是用于描述算法时间复杂度的一种方式。它关注的是算法运行时
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )