Plotly与Dash融合:构建交互式Web数据仪表板(实战攻略)
发布时间: 2024-09-30 03:17:39 阅读量: 113 订阅数: 34 

Python库Plotly:科学与工程数据可视化的全面指南及Dash框架集成
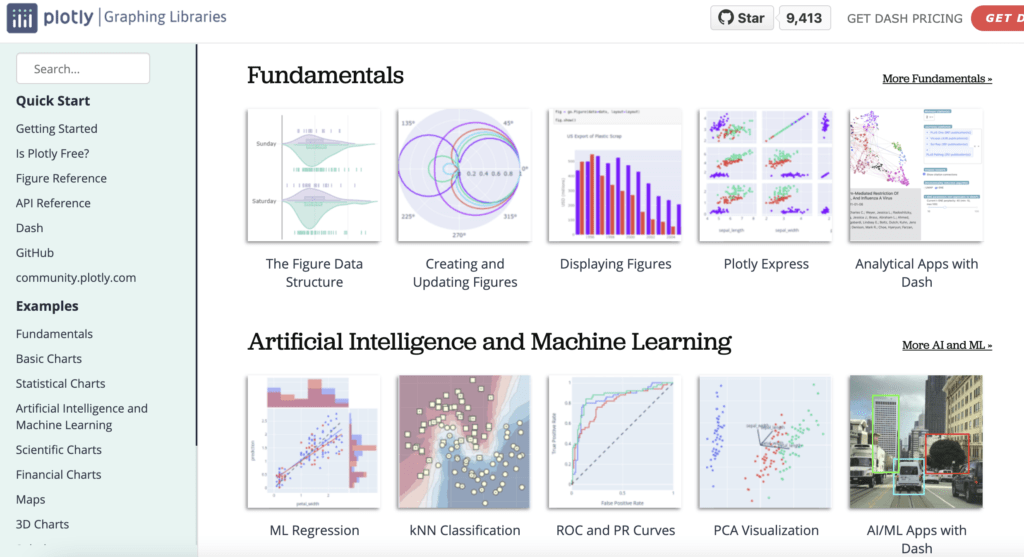
# 1. Plotly与Dash简介
在数据可视化领域,Plotly和Dash是两个强有力的工具,它们在数据分析和Web应用开发中发挥着关键作用。Plotly是一个强大的图表库,能够创建交互式的、可嵌入的图形,适用于多种数据分析场景。而Dash,作为Plotly的扩展,它是一个专门为数据分析和可视化设计的Web框架。Dash使得创建复杂的仪表板变得简单,无需使用JavaScript或其他前端技术。
本章我们将对Plotly和Dash进行概览,介绍它们在数据可视化和交互式Web应用中的作用,以及它们如何帮助用户快速构建丰富的用户界面。
接下来,我们将深入探讨Plotly的基础图表构建,并逐步深入到Dash的应用构建基础,最终通过实战案例,实现一个功能完整的交互式Web数据仪表板。这不仅包括理论知识,还包括实战技巧,确保读者能够应用这些技术构建自己的项目。
# 2. Plotly的基础图表构建
## 2.1 Plotly图表类型和特性
### 2.1.1 理解不同图表类型及其应用
在数据可视化领域,选择正确的图表类型对于传达信息至关重要。Plotly支持多种图表类型,如散点图、条形图、折线图、箱形图等,每种图表都有其独特的用途。
**散点图**:适用于展示两个变量之间的关系。
```python
import plotly.express as px
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length")
fig.show()
```
在上述代码中,我们使用Plotly Express的`scatter`方法创建了一个散点图。通过调整`x`和`y`参数,我们指定了数据集中要显示的变量。
**条形图**:适合展示分类数据的频率或分布。
```python
fig = px.bar(df, x="species", y="sepal_length")
fig.show()
```
条形图通过`bar`方法生成,这里展示了不同种类的鸢尾花(Iris)的萼片长度的分布情况。
**折线图**:常用于展示数据随时间的变化趋势。
```python
df = px.data.stocks(indexed=True)
fig = px.line(df, title='Stock Price Movement')
fig.show()
```
通过`line`方法,我们绘制了随时间变化的股票价格走势图。
每种图表类型都有其内在的属性和调整选项,允许用户通过少量代码实现丰富的可视化效果。
### 2.1.2 图表自定义与样式调整
Plotly提供了广泛的方法来自定义图表的外观。用户可以修改颜色、字体、图表标题、图例等,以适应其数据和设计偏好。
```python
fig.update_layout(
title='Customized Scatter Plot',
xaxis=dict(title='X-axis Title'),
yaxis=dict(title='Y-axis Title'),
font=dict(family='Arial', size=12, color='#7f7f7f')
)
```
上述代码展示了如何修改布局属性。`update_layout`方法允许我们改变图表的标题、轴标签、字体样式等。
除了布局调整,Plotly还允许用户添加注释、图形形状以及定制的颜色渐变和模式。
## 2.2 Plotly数据可视化技巧
### 2.2.1 数据清洗与预处理
在进行数据可视化之前,数据通常需要进行清洗和预处理。Plotly本身不提供数据处理功能,但可以和如Pandas等数据处理库很好地协同工作。
```python
import pandas as pd
import plotly.express as px
# 示例数据
data = {'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]}
df = pd.DataFrame(data)
df = df.melt(id_vars=['A'], var_name='Variable', value_name='Value')
fig = px.bar(df, x='A', y='Value', color='Variable')
fig.show()
```
在这个示例中,我们首先创建了一个包含两列数据的DataFrame。然后,使用`melt`方法将其重塑为适合绘图的格式,最后用Plotly Express绘制了一个堆叠条形图。
### 2.2.2 高级图表交互功能
Plotly图表的特点之一是它们的高交互性。用户可以通过悬停、点击、缩放等操作与图表互动,以获得更深入的洞察。
```python
fig.update_traces(hoverinfo='x+y', marker=dict(size=10))
```
这段代码设置了当鼠标悬停在图表上时显示的额外信息,并调整了图表元素(如点标记)的大小。
## 2.3 Plotly图表的布局与设计
### 2.3.1 调整图表布局和颜色方案
良好的视觉设计能够提升图表的可读性,并吸引用户的注意力。Plotly提供了灵活的方式来调整图表布局和颜色。
```python
fig.update_layout(
plot_bgcolor='white',
paper_bgcolor='lightgrey',
font=dict(color='black'),
title_font=dict(size=25),
legend=dict(orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1)
)
```
此代码段将图表背景设为白色,将纸张背景设为浅灰色,设置了字体颜色、标题字体大小,并调整了图例的位置和方向。
### 2.3.2 创建响应式布局的图表
随着用户访问的设备多样化,创建响应式设计的图表变得越来越重要。Plotly图表天生具有一定的响应性,通过适当的调整可以进一步优化。
```python
fig.update_layout(autosize=True, width=None, height=None)
```
通过设置`autosize`为`True`,图表将会根据其容器的大小自动调整尺寸,以实现响应式效果。
## 2.4 小结
在本小节中,我们深入探讨了Plotly图表类型和特性的基础知识,包括不同图表的适用场景和基本的自定义方法。此外,我们还涉及了数据清洗与预处理的重要性,并展示了如何利用Plotly的高级交互功能来增强用户体验。通过调整布局和颜色方案,我们学习了如何进行基础设计以提升图表的吸引力。最后,我们了解了如何制作响应式图表以适应不同设备和屏幕尺寸的需求。通过这些内容,我们为构建高级的、交互式的图表打下了坚实的基础。
# 3. Dash框架的构建基础
## 3.1 Dash应用的结构与组件
### 3.1.1 Dash应用的目录结构和文件组成
Dash应用程序的目录结构和文件组成是其基础,它们共同定义了应用程序的整体框架。一个标准的Dash应用通常包含以下几个部分:
- `app.py`:这是Dash应用的主文件,包含了应用程序的主要逻辑。
- `assets/`:此目录用于存放自定义CSS样式、JavaScript文件和其他静态资源。
- `data/`:存储应用程序数据的目录,比如CSV文件、JSON文件或其他数据格式。
- `tests/`:包含单元测试的目录,确保应用的功能按预期工作。
- `Procfile`:如果是将Dash应用部署到Heroku这样的平台上,这个文件指明了如何启动应用。
- `requirements.txt`:列出了项目的所有依赖。
在`app.py`文件中,首先需要导入Dash库及其组件,然后创建一个Dash应用实例,并定义布局和回调函数。布局部分定义了应用的界面元素,而回调函数则赋予界面交互能力。
下面是一个简单的Dash应用目录结构示例:
```
my-dash-app/
|-- app.py
|-- assets/
| `-- style.css
|-- data/
| `-- mydata.csv
|-- tests/
| `-- test_app.py
|-- Procfile
`-- requirements.txt
```
### 3.1.2 核心组件介绍:Input, Output, State
Dash的核心组件主要分为三类:`Input`、`Output`和`State`。理解这三种组件对于构建功能丰富的Dash应用至关重要。
- `Input` 组件:这是用户与之交互的组件,比如按钮、输入框、下拉菜单等。用户的行为会改变这些组件的状态,并触发回调函数的执行。
- `Output` 组件:当回调函数被触发时,可以更新`Output`组件的属性。比如,可以更新图表的数据、HTML内容或更新其他UI组件。
- `State` 组件:与`Input`组件不同,`State`组件包含的信息不会触发回调函数,但是当`Input`组件触发回调函数时,`State`组件的值可以作为额外信息传递给回调函数。
下面是一个简单的Dash应用组件使用示例:
```python
import dash
from dash import html, dcc
from dash.dependencies import Input, Output, State
app = dash.Dash(__name__)
app.layout = html.Div([
html.H1('Dash Input-Output-State Example'),
dcc.Input(id='input-component', value='Initial value', type='text'),
html.Button('Submit', id='submit-button', n_clicks=0),
html.Div(id='output-component', style={'margin-top': 20})
])
@app.callback(
Output('output-component', 'children'),
Input('submit-button', 'n_clicks'),
State('input-component', 'value')
)
def update_output(n_clicks, value):
return html.Div([
'The button has been pressed',
html.Br(),
f'{n_clicks} times.',
html.Br(),
f'The input value is "{value}".'
])
if __name__ == '__main__':
app.run_server(debug=True)
```
在这个示例中,我们定义了一个文本输入框和一个提交按钮。点击按钮会触发`update_output`回调函数,该函数接收按钮的点击次数和输入框的值作为参数,然后将结果显示在页面上。
## 3.2 Dash的布局设计与组件交互
### 3.2.1 设计响应式布局
Dash应用需要对不同设备和屏幕尺寸有良好的适应性,这就是响应式布局的意义。Dash通过HTML和Bootstrap组件提供了灵活的布局选项。
利用HTML的布局组件如`Div`、`Row`、`Column`等,可以创建网格结构,并通过CSS样式调整布局的响应式行为。Dash的`dash_core_components`和`dash_html_components`库提供了对Bootstrap类的支持,使得布局的创建和调整变得容易。
示例

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 Plotly 专栏!本专栏深入探讨了 Plotly 库,这是一个强大的 Python 数据可视化库。从初学者到高级用户,我们涵盖了各种主题,包括:
* 交互式图表和仪表盘的创建
* 高级图表定制技巧
* 动态数据故事的构建
* Plotly 与 Dash 的融合
* 图表元素和结构的解析
* 探索性数据分析
* 图表性能优化
* 数据清洗和预处理
* 金融分析和生物信息学可视化
* 机器学习结果的可视化
* 多维数据可视化
* 复杂图表和仪表盘的创建
* 图表外观定制
* 图表交互性开发
无论您是数据科学家、分析师还是开发人员,本专栏都将为您提供使用 Plotly 提升数据可视化技能所需的知识和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Groovy实战秘籍】:动态脚本技术在企业级应用中的10大案例分析
# 摘要
Groovy作为一种敏捷的Java平台语言,其灵活的语法和强大的编程范式受到企业级应用开发者的青睐。本文首先概述了Groovy语言的特性及其在企业级应用中的前景,随后详细探讨了其基础语法、编程范式和测试调试方法。接着,本文深入分析了动态脚本技术在企业级应用中的实际应用场景、性能优化及安
构建SAP金税接口的终极步骤

# 摘要
本文旨在深入理解SAP金税接口的需求与背景,并详细探讨其理论基础、设计与开发过程、实际案例分析以及未来展望。首先介绍了SAP系统的组成、架构及数据流和业务流程,同时概述了税务系统的金税系统功能特点及其与SAP系统集成的必要性。接着,深入分析了接口技术的分类、网络协议的应用,接口需求分析、设计方案、实现、测试、系统集成与部署的步骤和细节。文章还包括了多个成功的案例分享、集成时
直播流量提升秘籍:飞瓜数据实战指南及案例研究

# 摘要
直播流量作为当前数字营销的关键指标,对品牌及个人影响力的提升起到至关重要的作用。本文深入探讨直播流量的重要性及其影响因素,并详细介绍了飞瓜数据平台的功能与优势。通过分析飞瓜数据在直播内容分析、策略优化以及转化率提高等方面的实践应用,本文揭示了如何利用该平台提高直播效果。同时,通过对成功与失败案例的对比研究,提出了有效的实战技巧和经验启示。最后,本文展望了未来直播流量优化的新兴技术应用趋势,并强调了策略的持续优化
网络延迟分析:揭秘分布式系统延迟问题,专家级缓解策略
# 摘要
网络延迟是分布式系统性能的关键指标,直接影响用户体验和系统响应速度。本文从网络延迟的基础解析开始,深入探讨了分布式系统中的延迟理论,包括其成因分析、延迟模型的建立与分析。随后,本文介绍了延迟测量工具与方法,并通过实践案例展示了如何收集和分析数据以评估延迟。进一步地,文章探讨了分布式系统延迟优化的理论基础和技术手段,同时提供了优化策略的案例研究。最后,
【ROS机械臂视觉系统集成】:图像处理与目标抓取技术的深入实现

# 摘要
本文详细介绍了ROS机械臂视觉系统集成的各个方面。首先概述了ROS机械臂视觉系统集成的关键概念和应用基础,接着深入探讨了视觉系统的基础理论与工具,并分析了如何在ROS环境中实现图像处理。随后,文章转向机械臂控制系统的集成,并通过实践案例展现了ROS与机械臂的实际集成过程。在视觉系统与机械臂的协同工作方面,本文讨论了实时图像处理技术、目标定位以及动作
软件测试效率提升攻略:掌握五点法的关键步骤

# 摘要
软件测试效率的提升对确保软件质量与快速迭代至关重要。本文首先强调了提高测试效率的重要性,并分析了影响测试效率的关键因素。随后,详细介绍了五点法测试框架的理论基础,包括其原则、历史背景、理论支撑、测试流程及其与敏捷测试的关联。在实践应用部分,本文探讨了通过快速搭建测试环境、有效管理测试用例和复用,以及缺陷管理和团队协作,来提升测试效率。进一步地,文章深入讨论了自动化测试在五点法中的应用,包括工具选择、脚本编写和维护,以及集成和持续集成的方
【VBScript脚本精通秘籍】:20年技术大佬带你从入门到精通,掌握VBScript脚本编写技巧
# 摘要
VBScript是微软公司开发的一种轻量级的脚本语言,广泛应用于Windows环境下的自动化任务和网页开发。本文首先对VBScript的基础知识进行了系统性的入门介绍,包括语言语法、数据类型、变量、操作符以及控制结构。随后,深入探讨了VBScript的高级特性,如过程、函数、面向对象编程以及与ActiveX组件的集成。为了将理
高速数据传输:利用XILINX FPGA实现PCIE数据传输的优化策略

# 摘要
本文详细探讨了高速数据传输与PCIe技术在XILINX FPGA硬件平台上的应用。首先介绍了PCIe的基础知识和FPGA硬件平台与PCIe接口的设计与配置。随后,针对基于FPGA的PCIe数据传输实现进行了深入分析,包括链路初始化、数据缓冲、流控策略以及软件驱动开发。为提升数据传输性能,本文
【MAC用户须知】:MySQL数据备份与恢复的黄金法则

# 摘要
MySQL作为广泛使用的开源关系型数据库管理系统,其数据备份与恢复技术对于保障数据安全和业务连续性至关重要。本文从基础概念出发,详细讨论了MySQL数据备份的策略、方法、最佳实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )