Flask.request全解析:构建RESTful API的秘籍与最佳实践
发布时间: 2024-10-14 22:03:46 阅读量: 63 订阅数: 30 

Python中Flask-RESTful编写API接口(小白入门)

# 1. Flask.request概述
## 1.1 Flask.request简介
Flask是一个轻量级的Web应用框架,它提供了一个全局对象`request`,用于处理HTTP请求。`Flask.request`对象包含了客户端发出的所有请求信息,是Web开发中处理用户输入的关键。
## 1.2 Flask.request的作用
`Flask.request`使得开发者能够方便地获取请求数据,包括HTTP方法、URL、路径、头信息、表单数据、JSON请求体以及文件上传等。这些信息对于Web应用的功能实现至关重要。
```python
from flask import request
@app.route('/hello', methods=['GET'])
def hello():
user_agent = request.headers.get('User-Agent')
return f'Hello, Flask! Your browser is {user_agent}'
```
在上面的例子中,我们通过`request.headers`获取了客户端的用户代理信息。这只是`Flask.request`功能的一个简单展示。在接下来的章节中,我们将深入探讨`Flask.request`的更多用途和特性。
# 2. 理解Flask.request对象
Flask框架的核心之一是`request`对象,它代表了客户端的请求信息。在本章节中,我们将深入探讨`Flask.request`对象的不同方面,包括它的基本属性、数据获取方式以及参数解析机制。通过对这些内容的理解,开发者可以更加高效地处理HTTP请求,构建更加健壮的Web应用。
### 2.1 Flask.request的基本属性
`Flask.request`对象包含了请求相关的各种信息,如请求方法、URL、路径以及请求头等。掌握这些属性对于处理不同的HTTP请求至关重要。
#### 2.1.1 如何获取请求方法
Flask中,可以通过`request.method`属性来获取请求的方法,这在处理不同类型的HTTP请求时非常有用。例如,你可能需要区分GET请求和POST请求。
```python
from flask import request
@app.route('/api/data', methods=['GET', 'POST'])
def handle_data():
if request.method == 'GET':
# 处理GET请求
return jsonify({'message': 'Data retrieved successfully'})
elif request.method == 'POST':
# 处理POST请求
return jsonify({'message': 'Data received successfully'})
```
在此代码段中,`request.method`用于判断当前请求是GET还是POST。根据不同的方法类型,服务器会执行不同的处理逻辑。
#### 2.1.2 获取请求URL和路径
请求的URL可以分为路径部分和查询字符串部分。Flask提供了`request.url`和`request.path`属性来分别获取完整的请求URL和请求路径。
```python
from flask import request
@app.route('/api/<int:item_id>')
def get_item(item_id):
full_url = request.url # 包含查询字符串的完整URL
path = request.path # 路径部分,例如 /api/42
return jsonify({'full_url': full_url, 'path': path})
```
在这个例子中,`request.url`将返回类似`***`的字符串,而`request.path`将返回`/api/42`。
#### 2.1.3 处理请求头信息
HTTP头信息包含了客户端请求的元数据,如用户代理、内容类型等。Flask允许通过`request.headers`访问这些信息。
```python
from flask import request
@app.route('/api/header-info')
def get_header_info():
user_agent = request.headers.get('User-Agent')
content_type = request.headers.get('Content-Type')
return jsonify({'User-Agent': user_agent, 'Content-Type': content_type})
```
在这个例子中,我们获取了用户代理和内容类型两个常见的HTTP头信息。
### 2.2 Flask.request的数据获取
Web应用通常需要处理来自客户端的多种数据类型,如表单数据、JSON请求体以及文件上传等。Flask提供了相应的方法来处理这些数据。
#### 2.2.1 获取表单数据
表单数据通常通过GET或POST请求发送。Flask通过`request.form`访问这些数据。
```python
from flask import request
@app.route('/api/form-data', methods=['POST'])
def handle_form_data():
username = request.form.get('username')
password = request.form.get('password')
return jsonify({'username': username, 'password': password})
```
在这个例子中,我们从POST请求中获取了用户名和密码。`request.form`是一个特殊的字典,包含了表单数据。
#### 2.2.2 处理JSON请求体
现代Web应用广泛使用JSON格式进行数据交换。Flask通过`request.json`访问JSON请求体。
```python
from flask import request
@app.route('/api/json-data', methods=['POST'])
def handle_json_data():
data = request.json
return jsonify({'received_data': data})
```
在这个例子中,我们获取了JSON格式的请求体数据。`request.json`是一个Python字典,包含了JSON数据。
#### 2.2.3 文件上传处理
文件上传是Web应用的常见需求。Flask提供了`request.files`来处理上传的文件。
```python
from flask import request, render_template
import os
@app.route('/api/upload', methods=['POST'])
def upload_file():
uploaded_file = request.files['file']
file_path = os.path.join('uploads', uploaded_file.filename)
uploaded_file.save(file_path)
return jsonify({'message': 'File uploaded successfully', 'file_path': file_path})
```
在这个例子中,我们从POST请求中获取了上传的文件,并将其保存在服务器上。
### 2.3 Flask.request的参数解析
Flask路由参数和查询字符串是构建动态URL和传递参数的强大工具。我们将探讨它们的用法和Flask提供的高级功能。
#### 2.3.1 路由参数解析
Flask路由可以包含变量部分,称为路由参数。这些参数在请求URL中捕获,并可以在视图函数中使用。
```python
from flask import request
@app.route('/api/user/<username>')
def get_user(username):
return jsonify({'username': username})
```
在这个例子中,`<username>`是一个路由参数,任何匹配`/api/user/<some_username>`的URL都会触发这个视图函数,并将`some_username`作为`username`参数传递给函数。
#### 2.3.2 查询字符串解析
查询字符串是URL的一部分,位于`?`之后,用于传递额外的参数。Flask可以通过`request.args`访问这些参数。
```python
from flask import request
@app.route('/api/search')
def search():
query = request.args.get('query')
return jsonify({'search_query': query})
```
在这个例子中,我们从查询字符串中获取了`query`参数。`request.args`是一个特殊的字典,包含了所有的查询参数。
#### 2.3.3 动态路由的高级用法
Flask支持使用转换器来捕获特定类型的路由参数,例如整数、浮点数等。
```python
from flask import request
@app.route('/api/user/<int:user_id>')
def get_user(user_id):
return jsonify({'user_id': user_id})
```
在这个例子中,`<int:user_id>`指定了路由参数`user_id`必须是一个整数。如果请求的URL不匹配,Flask将返回一个404错误。
在本章节中,我们介绍了`Flask.request`对象的基本属性、数据获取方式以及参数解析机制。通过这些内容的学习,开发者可以更加高效地处理HTTP请求,构建更加健壮的Web应用。在下一章节中,我们将探讨如何利用这些知识来构建RESTful API的基础。
# 3. 构建RESTful API的基础
在本章节中,我们将深入探讨构建RESTful API的基础知识,为构建一个高效、规范的API打下坚实的基础。我们将从RESTful API设计原则开始,逐步深入到Flask中的路由配置,以及请求和响应对象的使用。
## 3.1 RESTful API设计原则
RESTful API的设计原则是构建REST架构风格服务的基础。REST(Representational State Transfer,表现层状态转换)是一种软件架构风格,它定义了一组设计原则,用于实现网络中的分布式系统。
### 3.1.1 资源的表述和识别
RESTful API的核心概念之一是资源(Resource)。资源可以是任何事物,例如文档、图片、用户数据等。在RESTful API中,每个资源都由一个URI(Uniform Resource Identifier,统一资源标识符)来唯一标识。
例如,我们可以定义一个用户资源的URI为`/users/{user_id}`。通过这个URI,我们可以获取特定用户的信息。
### 3.1.2 使用HTTP方法进行CRUD操作
在RESTful API中,HTTP方法被用来表示对资源的操作。CRUD(Create, Read, Update, Delete)是Web应用中最基本的数据操作。
- `GET`:用来读取资源。
- `POST`:用来创建资源。
- `PUT`:用来更新资源。
- `DELETE`:用来删除资源。
通过这些方法,我们可以实现对资源的增删改查操作。
### 3.1.3 状态码和响应格式
HTTP状态码用于表示API请求的处理结果。例如,`200 OK`表示请求成功,`404 Not Found`表示资源未找到。在设计RESTful API时,合理使用HTTP状态码非常重要。
响应格式通常包括JSON(JavaScript Object Notation)和XML(Extensible Markup Language)。JSON是最常用的格式,因为它易于读写,且支持多种编程语言。
## 3.2 Flask中的路由配置
在Flask中,路由是将URL映射到相应的视图函数。RESTful API的路由配置需要遵循特定的设计原则,以确保API的清晰和一致性。
### 3.2.1 路由的基本用法
在Flask中,使用`@app.route()`装饰器来定义路由。例如,定义一个获取用户列表的路由:
```python
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/users', methods=['GET'])
def get_users():
# 假设这里从数据库获取用户数据
users = [{'id': 1, 'name': 'Alice'}, {'id': 2, 'name': 'Bob'}]
return jsonify(users)
```
### 3.2.2 路由的变量规则和转换器
在设计RESTful API时,我们经常需要捕获URL中的变量部分。Flask允许我们定义带有变量规则的路由。例如,获取特定用户的信息:
```python
@app.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
# 假设这里根据user_id获取用户信息
user = {'id': user_id, 'name': 'Alice'}
return jsonify(user)
```
在这个例子中,`<int:user_id>`定义了一个整数类型的变量`user_id`。
### 3.2.3 动态路由与RESTful URL设计
RESTful URL设计应该清晰地表达资源的操作。例如,我们可以通过不同的HTTP方法来区分操作:
```python
@app.route('/users', methods=['POST'])
def create_user():
# 创建新用户的逻辑
pass
@app.route('/users/<int:user_id>', methods=['PUT'])
def update_user(user_id):
# 更新用户信息的逻辑
pass
```
## 3.3 请求和响应对象的使用
在Flask中,`request`对象用于访问请求数据,`response`对象用于构建响应数据。理解这些对象的使用对于构建RESTful API至关重要。
### 3.3.1 创建和配置响应对象
`response`对象可以通过`make_response()`函数创建,并进行配置。例如,我们可以自定义一个响应的状态码和头部信息:
```python
from flask import make_response
@app.route('/users', methods=['GET'])
def get_users():
users = [{'id': 1, 'name': 'Alice'}, {'id': 2, 'name': 'Bob'}]
response = make_response(jsonify(users), 200)
response.headers['X-Custom-Header'] = 'Value'
return response
```
### 3.3.2 利用Flask的Response对象进行自定义
`Response`类是Flask中响应对象的基础类。我们可以通过继承这个类来创建自定义的响应对象。例如,我们可以创建一个支持分页的响应类:
```python
from flask import Response
class PaginatedResponse(Response):
def __init__(self, items, page, per_page, total):
super(PaginatedResponse, self).__init__(json.dumps({
'items': items,
'total': total,
'page': page,
'per_page': per_page
}), mimetype='application/json')
self.headers['X-Total-Count'] = str(total)
@app.route('/users', methods=['GET'])
def get_users():
# 分页逻辑
items = [{'id': 1, 'name': 'Alice'}, {'id': 2, 'name': 'Bob'}]
page = 1
per_page = 10
total = 100
return PaginatedResponse(items, page, per_page, total)
```
### 3.3.3 错误处理和异常捕获
在构建RESTful API时,合理的错误处理和异常捕获是必不可少的。Flask提供了`abort`函数和错误处理器来帮助我们处理这些情况。
```python
from flask import abort
@app.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
# 用户查找逻辑
user = find_user_by_id(user_id)
if not user:
abort(404, description="User not found")
return jsonify(user)
@app.errorhandler(404)
def handle_404(error):
return jsonify({'error': error.description}), 404
```
在本章节中,我们介绍了构建RESTful API的基础知识,包括RESTful API设计原则、Flask中的路由配置以及请求和响应对象的使用。这些知识将为我们构建高效、规范的API打下坚实的基础。
# 4. RESTful API的高级实践
在本章节中,我们将深入探讨RESTful API的高级实践,包括分页、过滤和排序功能的实现,身份验证和授权的策略,以及API版本管理和文档的创建。这些实践对于构建健壮、安全且易于维护的RESTful API至关重要。
## 4.1 分页、过滤和排序
RESTful API通常处理大量数据,因此分页、过滤和排序是必不可少的功能。这些功能帮助客户端有效地管理和呈现数据,同时减轻服务器的负载。
### 4.1.1 实现API分页功能
分页是将数据分割成更小、更易于管理的块的过程。以下是一个简单的分页实现示例:
```python
from flask import request, jsonify
from app.models import Item
@app.route('/items', methods=['GET'])
def get_items():
page = request.args.get('page', 1, type=int)
per_page = request.args.get('per_page', 10, type=int)
items = Item.query.paginate(page=page, per_page=per_page)
items_list = [item.to_dict() for item in items.items]
return jsonify({
'data': items_list,
'total': items.total,
'pages': items.pages
})
```
在这个例子中,我们使用了Flask的`request`对象来获取查询参数`page`和`per_page`,然后使用SQLAlchemy的`paginate`方法来进行分页。这种方法返回一个包含分页数据的`Pagination`对象。
### 4.1.2 请求数据的过滤
过滤允许客户端根据特定条件获取数据。以下是一个使用SQLAlchemy进行过滤的示例:
```python
from flask import request, jsonify
from app.models import Item
@app.route('/items', methods=['GET'])
def get_items():
name = request.args.get('name')
items = Item.query.filter(Item.name.contains(name)) if name else Item.query.all()
items_list = [item.to_dict() for item in items]
return jsonify({
'data': items_list
})
```
在这个例子中,我们使用了`filter`方法来根据名称过滤项目。如果`name`参数存在,我们使用`contains`方法进行模糊匹配;否则,我们返回所有项目。
### 4.1.3 结果排序的实现
排序允许客户端根据特定属性对数据进行排序。以下是一个使用SQLAlchemy进行排序的示例:
```python
from flask import request, jsonify
from app.models import Item
@app.route('/items', methods=['GET'])
def get_items():
sort_by = request.args.get('sort_by', 'created_at')
sort_order = request.args.get('sort_order', 'desc')
items = Item.query.order_by(getattr(Item, sort_by, Item.created_at).desc() if sort_order == 'desc' else getattr(Item, sort_by).asc())
items_list = [item.to_dict() for item in items]
return jsonify({
'data': items_list
})
```
在这个例子中,我们使用了`order_by`方法来根据`sort_by`参数对项目进行排序。`sort_order`参数用于指定排序的方向。
### 4.1.4 实现分页、过滤和排序的表格总结
| 功能 | 方法 | 说明 |
| ---------- | ------------ | ------------------------------------------------------------ |
| 分页 | paginate | 分割数据为更小的块,通常使用页码和每页条数作为参数 |
| 过滤 | filter | 根据客户端定义的条件筛选数据,支持模糊匹配等操作 |
| 排序 | order_by | 根据客户端定义的属性对数据进行排序,支持正序和倒序 |
## 4.2 身份验证和授权
身份验证和授权是保护API安全的关键步骤。身份验证用于验证用户身份,而授权用于确定用户是否有权限执行特定操作。
### 4.2.1 基于HTTP的认证机制
HTTP提供了几种内置的认证机制,如基本认证和摘要认证。以下是使用基本认证的示例:
```python
from flask import request, Response
from functools import wraps
def require_auth(f):
@wraps(f)
def decorated(*args, **kwargs):
auth = request.authorization
if not auth or not check_user_password(auth.username, auth.password):
return Response(
'Could not verify your access level for that URL.\n'
'You have to login with proper credentials', 401,
{'WWW-Authenticate': 'Basic realm="Login Required"'})
return f(*args, **kwargs)
return decorated
@app.route('/secret')
@require_auth
def get_secret_data():
return jsonify({'data': 'This is a secret!'})
```
在这个例子中,我们定义了一个`require_auth`装饰器,它检查请求头中的`Authorization`字段,以确保用户已通过认证。
### 4.2.2 使用Flask-HTTPAuth扩展
Flask-HTTPAuth是一个Flask扩展,它简化了HTTP认证的实现。以下是使用Flask-HTTPAuth的基本示例:
```python
from flask import Flask, request, Response
from flask_httpauth import HTTPBasicAuth
auth = HTTPBasicAuth()
@auth.verify_password
def verify_password(username, password):
if username == 'admin' and password == 'secret':
return username
@app.route('/secret')
@auth.login_required
def get_secret_data():
return jsonify({'data': 'This is a secret!'})
```
在这个例子中,我们使用`verify_password`方法来验证用户名和密码。如果验证成功,`login_required`装饰器允许访问受保护的路由。
### 4.2.3 OAuth2.0协议的集成
OAuth2.0是一个授权框架,允许第三方应用程序访问服务器资源。以下是使用Flask-OAuthlib集成OAuth2.0的示例:
```python
from flask import Flask, request, redirect
from flask_oauthlib.client import OAuth
app = Flask(__name__)
oauth = OAuth(app)
github = oauth.remote_app(
'github',
consumer_key='your-key',
consumer_secret='your-secret',
request_token_params={
'scope': 'email',
},
base_url='***',
request_token_url=None,
access_token_method='POST',
access_token_url='***',
authorize_url='***',
)
@github.tokengetter
def get_github_access_token():
return request.headers.get('Authorization', None)
@app.route('/login')
def login():
return github.authorize(callback='***')
@app.route('/callback')
def authorized():
resp = github.authorized_response()
if resp is None:
return 'Access denied: reason=%s error=%s' % (
request.args['error_reason'],
request.args['error_description']
)
session['github_token'] = resp['access_token']
return redirect('/')
@app.route('/profile')
def profile():
if 'github_token' not in session:
return redirect('/login')
resp = github.get('/user')
return jsonify(resp.data)
```
在这个例子中,我们使用`oauth.remote_app`来定义GitHub的OAuth2.0认证。然后,我们定义了`login`和`authorized`路由来处理用户的登录和授权。
### 4.2.4 实现身份验证和授权的mermaid流程图
```mermaid
graph LR
A[开始] --> B{用户请求资源}
B -->|未认证| C[重定向至认证服务器]
C --> D[用户认证]
D -->|成功| E[返回认证令牌]
E --> F[使用令牌访问资源]
F -->|成功| G[允许访问]
F -->|失败| B[用户未认证]
D -->|失败| B
```
## 4.3 API版本管理和文档
随着API的发展,版本管理和文档编制变得至关重要。它们确保API的向后兼容性,并帮助开发者理解和使用API。
### 4.3.1 版本控制策略
API版本控制可以通过不同的策略实现,如URI路径、请求头或查询参数。
#### 通过URI路径实现版本控制
```python
@app.route('/v1/items', methods=['GET'])
def get_items_v1():
# ...
return jsonify({
'data': items_list
})
@app.route('/v2/items', methods=['GET'])
def get_items_v2():
# ...
return jsonify({
'data': items_list_v2
})
```
在这个例子中,我们将不同的API版本放在不同的URI路径下。
#### 通过请求头实现版本控制
```python
from flask import request, jsonify
@app.route('/items', methods=['GET'])
def get_items():
version = request.headers.get('Accept')
if version == 'application/vnd.myapp.v1+json':
# ...
return jsonify({
'data': items_list_v1
})
elif version == 'application/vnd.myapp.v2+json':
# ...
return jsonify({
'data': items_list_v2
})
```
在这个例子中,我们将版本信息放在`Accept`请求头中。
### 4.3.2 自动生成API文档
自动生成API文档可以帮助开发者快速理解API的使用方法。Swagger和ReDoc是流行的API文档生成工具。
#### 使用Flask-Swagger-UI
Flask-Swagger-UI是一个Flask扩展,它可以将Swagger API文档集成到你的Flask应用中。
```python
from flask import Flask
from flask_swagger_ui import get_swaggerui_blueprint
app = Flask(__name__)
SWAGGER_URL = '/swagger'
API_URL = '/static/swagger.json' # Our API spec in JSON format
swaggerui_blueprint = get_swaggerui_blueprint(
SWAGGER_URL,
API_URL,
config={'app_name': "My API"}
)
app.register_blueprint(swaggerui_blueprint, url_prefix=SWAGGER_URL)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
```
在这个例子中,我们使用Flask-Swagger-UI来生成API文档。
### 4.3.3 API变更和兼容性管理
API变更时,应该遵循语义化版本控制原则,并确保向后兼容性。
### 4.3.4 实现API版本管理和文档的表格总结
| 版本控制策略 | 描述 |
| ------------ | ------------------------------------------------------------ |
| URI路径 | 将不同版本的API放在不同的URI路径下 |
| 请求头 | 将版本信息放在`Accept`请求头中 |
| 自动生成文档 | 使用Swagger、ReDoc等工具自动生成API文档 |
| 变更和兼容性 | 遵循语义化版本控制原则,确保向后兼容性 |
通过本章节的介绍,我们深入探讨了RESTful API的高级实践,包括分页、过滤和排序功能的实现,身份验证和授权的策略,以及API版本管理和文档的创建。这些实践对于构建健壮、安全且易于维护的RESTful API至关重要。
# 5. 性能优化与安全最佳实践
性能优化和安全性是任何Web应用的两个重要方面,尤其是在构建RESTful API时。在本章节中,我们将深入探讨如何通过各种策略和技术来优化Flask应用的性能,以及如何确保应用的安全性。我们将从性能优化策略开始,然后探讨Flask的安全扩展,最后讨论错误处理和日志记录的最佳实践。
## 5.1 性能优化策略
性能优化是确保用户获得快速响应体验的关键。在本节中,我们将探讨几种常见的性能优化策略,包括缓存机制的应用、使用Gunicorn和Nginx进行部署,以及数据库查询优化。
### 5.1.1 缓存机制的应用
缓存是提高应用性能的有效手段之一。通过缓存常用的数据,可以显著减少数据库的查询次数,从而加快响应速度。在Flask中,可以使用Flask-Caching扩展来轻松实现缓存。
```python
from flask import Flask
from flask_caching import Cache
app = Flask(__name__)
# 配置缓存类型为简单缓存
app.config['CACHE_TYPE'] = 'simple'
cache = Cache(app)
@cache.cached(timeout=50)
def get_data():
# 这个函数将会被缓存
return some_expensive_operation()
@app.route('/')
def index():
data = get_data()
return render_template('index.html', data=data)
```
在这个例子中,`get_data` 函数的返回值将被缓存50秒。如果在此期间有相同的请求,Flask-Caching将直接返回缓存的数据,而不是执行函数中的代码。
### 5.1.2 Gunicorn和Nginx的部署
Gunicorn是一个Python WSGI HTTP服务器,用于运行Python应用。它与Nginx结合使用可以进一步提高性能和可靠性。
#### Gunicorn部署
首先,你需要安装Gunicorn:
```bash
pip install gunicorn
```
然后,你可以使用以下命令来启动Gunicorn:
```bash
gunicorn -w 4 -b ***.*.*.*:8000 your_application:app
```
这里 `-w 4` 表示启动4个工作进程,`-b ***.*.*.*:8000` 表示绑定到本地地址和端口。
#### Nginx配置
接下来,配置Nginx来代理Gunicorn:
```nginx
server {
listen 80;
server_***;
location / {
proxy_pass ***
*** $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
```
通过这样的配置,Nginx将作为反向代理服务器,处理所有的HTTP请求,并将请求转发给Gunicorn服务器。
### 5.1.3 数据库查询优化
数据库查询优化是提升应用性能的另一个关键点。以下是一些常用的优化技巧:
#### 使用索引
为数据库表中的经常查询的列创建索引可以显著提高查询速度。
```sql
CREATE INDEX idx_column_name ON table_name (column_name);
```
#### 避免N+1查询问题
在处理关联对象时,确保使用适当的查询策略来避免N+1查询问题。
```python
# 假设有User和Post模型
users = User.query.all()
for user in users:
print(user.name, [post.title for post in user.posts])
```
为了避免N+1问题,可以使用SQLAlchemy的`joinedload`:
```python
from sqlalchemy.orm import joinedload
users = User.query.options(joinedload(User.posts)).all()
```
#### 使用ORM优化器
ORM框架通常提供查询优化工具,例如SQLAlchemy的`contains_eager`。
```python
from sqlalchemy.orm import contains_eager
query = (
Session()
.query(User)
.outerjoin(User.posts)
.options(contains_eager(User.posts))
)
```
这些技巧可以帮助你减少不必要的数据库查询,并提高应用的性能。
## 5.2 Flask安全扩展
安全是构建Web应用时不可忽视的方面。Flask提供了多个扩展来增强应用的安全性,包括Flask-Security、CSRF保护机制和SQL注入防护。
### 5.2.1 Flask-Security介绍
Flask-Security是一个集成用户认证、授权和会话管理的安全扩展。
```python
from flask_security import Security, SQLAlchemyUserDatastore
# 配置Flask-Security
security = Security(app, SQLAlchemyUserDatastore(user_model, role_model))
```
在这个例子中,`SQLAlchemyUserDatastore` 使用SQLAlchemy模型来管理用户和角色数据。
### 5.2.2 CSRF保护机制
CSRF(跨站请求伪造)是一种常见的Web安全威胁。Flask-WTF扩展可以帮助我们轻松地为表单添加CSRF保护。
```python
from flask_wtf.csrf import CSRFProtect
from flask import Flask
app = Flask(__name__)
# 启用CSRF保护
csrf = CSRFProtect(app)
# 在表单类中添加CSRF令牌
class LoginForm(Form):
remember = BooleanField('remember me')
next = HiddenField()
def validate_next(self, field):
if not field.data:
self.next.data = url_for('index')
```
在Flask应用中启用CSRF保护后,所有表单都将包含一个隐藏的CSRF令牌字段。
### 5.2.3 SQL注入防护
SQL注入是另一种常见的安全威胁。使用SQLAlchemy ORM可以有效地防止SQL注入,因为它提供了参数化查询。
```python
from sqlalchemy import Table, Column, Integer, String
from sqlalchemy.sql.expression import desc
from sqlalchemy.orm import sessionmaker
from flask_sqlalchemy import SQLAlchemy
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///example.db'
db = SQLAlchemy(app)
class User(db.Model):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(100))
email = Column(String(100))
# 使用参数化查询
session = db.session()
stmt = User.__table__.select().where(User.email == '***')
user = session.execute(stmt).scalar()
```
在这个例子中,即使用户输入的电子邮件地址包含恶意SQL代码,也不会被SQL注入,因为SQLAlchemy使用参数化查询。
## 5.3 错误处理和日志记录
良好的错误处理和日志记录对于维护和调试Web应用至关重要。在本节中,我们将讨论如何定制错误页面、实现日志记录策略,以及进行异常监控和报告。
### 5.3.1 定制错误页面
Flask允许你为不同状态码定制错误页面。
```python
from flask import render_template
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
@app.errorhandler(500)
def internal_server_error(e):
return render_template('500.html'), 500
```
在这个例子中,当发生404或500错误时,将显示自定义的HTML页面。
### 5.3.2 日志记录策略
使用Python内置的`logging`模块可以实现强大的日志记录功能。
```python
import logging
from logging.handlers import RotatingFileHandler
# 配置日志记录器
handler = RotatingFileHandler('application.log', maxBytes=10000, backupCount=1)
handler.setLevel(***)
app.logger.addHandler(handler)
@app.route('/')
def index():
***('Request received')
return 'Hello, World!'
```
在这个例子中,每当有请求访问首页时,都会在日志文件中记录一条信息。
### 5.3.3 异常监控和报告
使用Sentry等工具可以帮助你监控和报告应用中的异常。
```python
from sentry_sdk import init, capture_message
init(dsn='***')
@app.route('/')
def index():
try:
# 可能抛出异常的代码
pass
except Exception as e:
capture_message(str(e))
raise e
```
在这个例子中,每当有异常发生时,都会通过Sentry发送一个消息。
在本章节中,我们介绍了性能优化和安全最佳实践,这些策略对于构建高效且安全的RESTful API至关重要。通过应用这些技术和方法,你可以显著提高你的Flask应用的性能,并确保其安全性。
# 6. 案例分析:一个完整的RESTful API项目
## 6.1 项目需求和规划
在本章节中,我们将深入探讨如何规划和实现一个完整的RESTful API项目。我们会从功能需求分析开始,然后是API设计与文档编写,最后是技术选型和架构设计。
### 6.1.1 功能需求分析
在开始编码之前,我们需要对项目进行彻底的需求分析。这包括确定API的目标用户、核心功能、数据模型以及非功能性需求(如性能和安全要求)。例如,假设我们要构建一个任务管理API,我们需要确定用户如何添加、更新、删除和查询任务。此外,我们还需要了解认证机制(如OAuth2.0)和授权需求。
### 6.1.2 API设计与文档编写
一旦我们明确了功能需求,下一步就是设计RESTful API。我们将创建一个清晰的资源模型,并定义每个资源的端点。对于每个端点,我们需要确定HTTP方法(如GET、POST、PUT、DELETE)以及它们如何影响资源状态。此外,我们还需要编写详细的API文档,这样开发者才能明白如何使用我们的API。
### 6.1.3 技术选型和架构设计
在技术选型方面,我们需要选择合适的编程语言、框架和工具。对于Python,我们可能会选择Flask作为我们的框架。此外,我们还需要决定是否使用ORM(如SQLAlchemy)和数据库(如PostgreSQL)。架构设计将涉及到API的部署架构,包括如何将我们的API与前端应用、数据库和其他服务集成。
### 代码示例和解释
以下是一个简单的Flask应用初始化代码示例,展示了如何设置Flask应用和路由。
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Welcome to the Task Management API'
if __name__ == '__main__':
app.run(debug=True)
```
在此代码中,我们创建了一个简单的Flask应用,并定义了一个根路由。这只是开始,后续我们会添加更多的API端点和逻辑。
### 6.2 实现过程详解
在本节中,我们将详细介绍API实现过程中的关键步骤,包括环境搭建、核心API实现以及单元测试和集成测试。
### 6.2.1 环境搭建和初始化
首先,我们需要搭建开发环境。这通常涉及到创建虚拟环境、安装依赖包和配置项目结构。例如,我们可以使用以下命令创建一个虚拟环境并安装Flask:
```bash
python3 -m venv venv
source venv/bin/activate
pip install flask
```
然后,我们初始化Flask应用,如前节所示。
### 6.2.2 核心API实现
核心API实现是项目的核心部分。我们需要定义端点、处理逻辑和数据存储。例如,以下是一个简单的任务添加端点的示例:
```python
@app.route('/tasks', methods=['POST'])
def create_task():
data = request.json
# 这里可以添加逻辑来处理数据,并保存到数据库
return jsonify({'message': 'Task created successfully'}), 201
```
### 6.2.* 单元测试和集成测试
为了确保API的质量,我们需要编写单元测试和集成测试。单元测试通常针对单个函数或方法,而集成测试则测试端点与数据库等外部服务的交互。以下是使用pytest框架编写的一个简单的单元测试示例:
```python
import pytest
from app import app
@pytest.fixture
def client():
app.config['TESTING'] = True
with app.test_client() as client:
yield client
def test_create_task(client):
response = client.post('/tasks', json={'title': 'Test Task'})
assert response.status_code == 201
```
在此代码中,我们设置了一个测试客户端,并编写了一个简单的测试函数来验证任务创建端点。
## 6.3 部署与维护
在本节中,我们将讨论如何部署和维护我们的API,包括应用部署流程、持续集成和部署以及性能监控和调优。
### 6.3.1 应用部署流程
应用部署通常涉及到选择合适的服务器和部署策略。例如,我们可以使用Gunicorn作为WSGI服务器,并使用Nginx作为反向代理。以下是一个简单的Gunicorn启动命令:
```bash
gunicorn -w 4 -b *.*.*.*:8000 app:app
```
### 6.3.2 持续集成和部署
为了确保代码质量和快速交付,我们会设置持续集成和持续部署(CI/CD)流程。例如,我们可以使用GitHub Actions、Jenkins或GitLab CI来自动化测试和部署流程。
### 6.3.3 性能监控和调优
最后,我们需要监控API的性能,并根据需要进行调优。我们可以使用像Prometheus和Grafana这样的工具来监控应用的性能指标,并使用像Gunicorn的负载均衡器来优化性能。
在本章节中,我们通过一个完整的RESTful API项目案例,展示了从需求分析到部署维护的全过程。通过实践,我们深入理解了构建高质量API的关键步骤和最佳实践。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析 Flask.request,为 Python 开发者提供全面的指南。从基本用法到高级技巧,再到性能优化和安全防护,本专栏涵盖了使用 Flask.request 构建 RESTful API 和高性能 WSGI 应用所需的一切知识。通过掌握 Flask.request 的奥秘,开发者可以打造可维护、可扩展且健壮的 API 系统,有效提升并发处理能力,并防范请求攻击。本专栏还深入探讨了 Flask.request 背后的原理,帮助开发者深入理解 Werkzeug 和请求解析过程。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
无线通信的黄金法则:CSMA_CA与CSMA_CD的比较及实战应用

# 摘要
本文系统地探讨了无线通信中两种重要的载波侦听与冲突解决机制:CSMA/CA(载波侦听多路访问/碰撞避免)和CSMA/CD(载波侦听多路访问/碰撞检测)。文中首先介绍了CSMA的基本原理及这两种协议的工作流程和优劣势,并通过对比分析,深入探讨了它们在不同网络类型中的适用性。文章进一步通
Go语言实战提升秘籍:Web开发入门到精通

# 摘要
Go语言因其简洁、高效以及强大的并发处理能力,在Web开发领域得到了广泛应用。本文从基础概念到高级技巧,全面介绍了Go语言Web开发的核心技术和实践方法。文章首先回顾了Go语言的基础知识,然后深入解析了Go语言的Web开发框架和并发模型。接下来,文章探讨了Go语言Web开发实践基础,包括RES
【监控与维护】:确保CentOS 7 NTP服务的时钟同步稳定性
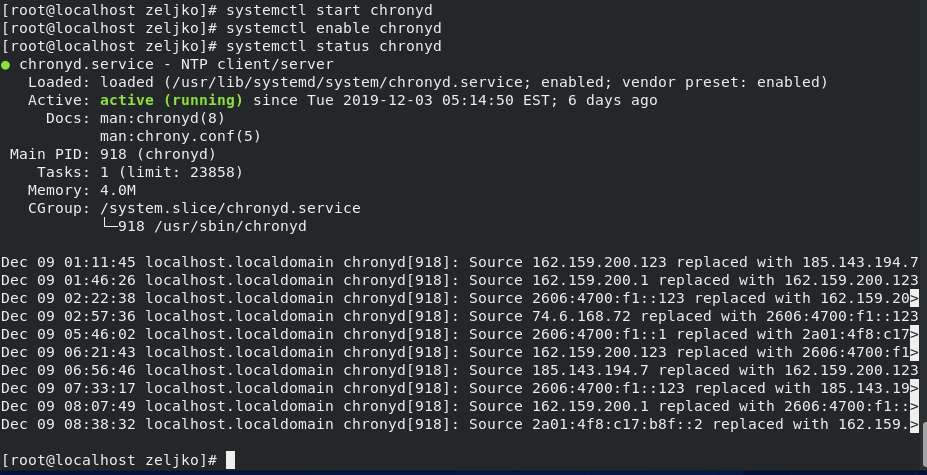
# 摘要
本文详细介绍了NTP(Network Time Protocol)服务的基本概念、作用以及在CentOS 7系统上的安装、配置和高级管理方法。文章首先概述了NTP服务的重要性及其对时间同步的作用,随后深入介绍了在CentOS 7上NTP服务的安装步骤、配置指南、启动验证,以及如何选择合适的时间服务器和进行性能优化。同时,本文还探讨了NTP服务在大规模环境中的应用,包括集
【5G网络故障诊断】:SCG辅站变更成功率优化案例全解析
# 摘要
随着5G网络的广泛应用,SCG辅站作为重要组成部分,其变更成功率直接影响网络性能和用户体验。本文首先概述了5G网络及SCG辅站的理论基础,探讨了SCG辅站变更的技术原理、触发条件、流程以及影响成功率的因素,包括无线环境、核心网设备性能、用户设备兼容性等。随后,文章着重分析了SCG辅站变更成功率优化实践,包括数据分析评估、策略制定实施以及效果验证。此外,本文还介绍了5
PWSCF环境变量设置秘籍:系统识别PWSCF的关键配置

# 摘要
本文全面阐述了PWSCF环境变量的基础概念、设置方法、高级配置技巧以及实践应用案例。首先介绍了PWSCF环境变量的基本作用和配置的重要性。随后,详细讲解了用户级与系统级环境变量的配置方法,包括命令行和配置文件的使用,以及环境变量的验证和故障排查。接着,探讨了环境变量的高级配
掌握STM32:JTAG与SWD调试接口深度对比与选择指南

# 摘要
随着嵌入式系统的发展,调试接口作为硬件与软件沟通的重要桥梁,其重要性日益凸显。本文首先概述了调试接口的定义及其在开发过程中的关键作用。随后,分别详细分析了JTAG与SWD两种常见调试接口的工作原理、硬件实现以及软件调试流程。在此基础上,本文对比了JTAG与SWD接口在性能、硬件资源消耗和应用场景上的差异,并提出了针对STM32微控制器的调试接口选型建议。最后,本文探讨
ACARS社区交流:打造爱好者网络

# 摘要
ACARS社区作为一个专注于ACARS技术的交流平台,旨在促进相关技术的传播和应用。本文首先介绍了ACARS社区的概述与理念,阐述了其存在的意义和目标。随后,详细解析了ACARS的技术基础,包括系统架构、通信协议、消息格式、数据传输机制以及系统的安全性和认证流程。接着,本文具体说明了ACARS社区的搭
Paho MQTT消息传递机制详解:保证消息送达的关键因素
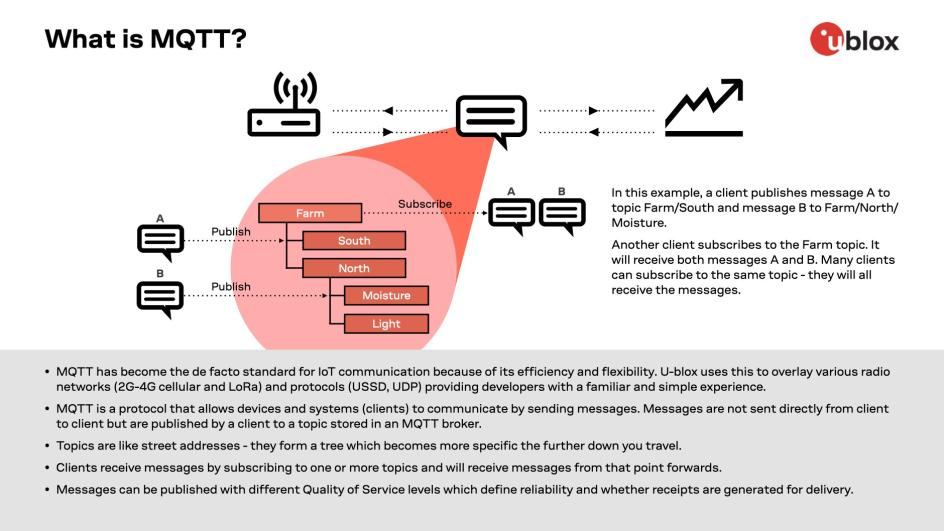
# 摘要
本文深入探讨了MQTT消息传递协议的核心概念、基础机制以及保证消息送达的关键因素。通过对MQTT的工作模式、QoS等级、连接和会话管理的解析,阐述了MQTT协议的高效消息传递能力。进一步分析了Paho MQTT客户端的性能优化、安全机制、故障排查和监控策略,并结合实践案例,如物联网应用和企业级集成,详细介绍了P
保护你的数据:揭秘微软文件共享协议的安全隐患及防护措施{安全篇

# 摘要
本文对微软文件共享协议进行了全面的探讨,从理论基础到安全漏洞,再到防御措施和实战演练,揭示了协议的工作原理、存在的安全威胁以及有效的防御技术。通过对安全漏洞实例的深入分析和对具体防御措施的讨论,本文提出了一个系统化的框架,旨在帮助IT专业人士理解和保护文件共享环境,确保网络数据的安全和完整性。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )