Flask.request实战指南:揭秘高性能WSGI应用的构建技巧
发布时间: 2024-10-14 22:08:00 阅读量: 34 订阅数: 29 

example.flask.crud-app:使用Flask和SQLAlchemy构建CRUD应用程序

# 1. Flask.request的基础知识
在Flask框架中,`Flask.request` 对象提供了对客户端HTTP请求的处理能力。它包含了客户端请求的所有信息,如查询字符串、表单数据、JSON负载等。开发者可以通过这些信息进行业务逻辑的处理,实现Web应用的动态响应。
## 1.1 Flask.request的简单使用
要访问请求对象中的数据,首先需要理解其结构。以下是一些基本的请求属性:
```python
from flask import request
@app.route('/user/<int:user_id>')
def get_user(user_id):
# 获取用户ID
user_id = request.path_params['user_id']
# 获取GET请求的参数
query_string = request.args.get('query')
# 获取POST请求的数据
post_data = request.json
return jsonify({'user_id': user_id, 'query': query_string, 'post_data': post_data})
```
在这个例子中,我们通过`request.path_params`访问了URL路径参数,通过`request.args`获取了GET请求的查询参数,通过`request.json`获取了POST请求的JSON负载数据。
Flask.request对象还提供了多种方法来处理请求,如`request.method`可以获取请求的HTTP方法,`request.headers`可以获取请求头信息等。这些方法和属性构成了Flask.request的基础,是处理Web请求不可或缺的部分。
# 2. Flask.request的高级特性
## 2.1 Flask.request的上下文管理
### 2.1.1 上下文的概念和作用
在Flask中,上下文管理是一个核心概念,它允许你在不直接传递request对象的情况下访问请求数据。上下文分为“请求上下文”和“应用上下文”。
- **请求上下文**:每当一个请求到达Flask应用时,Flask会为这个请求创建两个局部变量:`request`和`session`。这些变量只能在处理函数中访问,它们是请求上下文的一部分。
- **应用上下文**:应用上下文通常是当代码在处理请求之外运行时需要访问Flask应用对象时创建的。它使得在不直接调用Flask应用对象的情况下访问全局应用对象成为可能。
### 2.1.2 上下文的应用示例
让我们通过一个简单的示例来看看上下文是如何在Flask应用中工作的。
```python
from flask import Flask, request
app = Flask(__name__)
@app.route('/greet')
def greet():
user_agent = request.headers.get('User-Agent')
return f'Hello, your browser is {user_agent}.'
@app.route('/greet/context')
def greet_context():
with app.app_context():
# 这里可以直接访问Flask的全局对象
return 'Hello, this is a test from app context.'
if __name__ == '__main__':
app.run()
```
在这个例子中,我们定义了两个路由:`/greet` 和 `/greet/context`。`/greet` 路由展示了如何使用`request`对象来访问请求头部信息。而`/greet/context` 路由展示了如何使用`app.app_context()`上下文管理器来访问应用的全局对象。
### 2.1.3 代码逻辑逐行解读分析
```python
with app.app_context():
```
这行代码创建了一个应用上下文,使得在接下来的代码块中可以访问Flask的全局对象。
```python
return 'Hello, this is a test from app context.'
```
这行代码返回了一个简单的字符串,但重要的是,它是在应用上下文的范围内执行的。
### 2.1.4 上下文管理在Web应用中的实践案例
在Web应用中,上下文管理器可以用于多种场景。例如,当你的应用需要访问全局配置或应用对象来执行某些操作时,你可以在任何地方通过创建一个应用上下文来实现。
```python
from flask import current_app
@app.before_request
def log_request_info():
current_***(f'Request handled by {request.remote_addr}')
```
在这个例子中,我们使用`@app.before_request` 装饰器来在每个请求之前执行一些操作。`current_app` 是一个特殊的对象,它代表当前的应用实例,并且在请求上下文中可用。我们使用它来记录请求的来源地址。
### 2.1.5 表格:上下文管理的优势和局限
| 特性 | 优势 | 局限 |
| ------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 请求上下文 | 允许在视图函数中直接访问请求数据,无需显式传递 | 仅在当前请求的处理函数中可用 |
| 应用上下文 | 允许在视图函数外的地方访问Flask全局对象,如配置和应用实例 | 需要显式地创建和销毁上下文,否则可能会导致资源泄露 |
| 应用上下文中的`current_app` | 提供对当前应用实例的访问,无需引用全局Flask对象 | 只在应用上下文中有效,需要在合适的上下文中使用 |
### 2.1.6 mermaid流程图:上下文的生命周期
```mermaid
graph TD
A[开始请求] --> B{Flask应用是否已创建}
B -->|否| C[创建Flask应用实例]
B -->|是| D[请求上下文开始]
C --> D
D --> E{是否有请求对象}
E -->|否| F[创建请求对象]
E -->|是| G[请求对象已存在]
F --> G
G --> H[处理视图函数]
H --> I[请求上下文结束]
I --> J[响应返回客户端]
J --> K[结束请求]
```
在本章节中,我们探讨了Flask中的上下文管理的概念和作用,并通过实际的代码示例和表格分析了上下文的使用方法和流程。通过理解上下文管理,开发者可以更加灵活地编写Flask应用,优化资源使用,并提高代码的可维护性。在下一节中,我们将深入讨论Flask.request的请求处理特性,包括请求对象的属性和方法,以及如何解析和处理请求。
# 3. Flask.request的实践应用
## 3.1 Flask.request在Web应用中的应用
### 3.1.1 Web应用的基本结构和流程
在深入了解Flask.request在Web应用中的应用之前,我们首先需要了解Web应用的基本结构和流程。一个典型的Web应用通常包括前端用户界面、后端服务器处理逻辑以及数据库存储三个主要部分。用户通过浏览器与Web应用的前端界面交互,前端将用户的请求发送到后端服务器,服务器处理请求并与数据库交互,最后将处理结果返回给前端,前端再将结果呈现给用户。
这个过程中,Flask.request扮演着前端与后端交互的关键角色。它不仅承载了用户请求的数据,还提供了多种方法和属性来帮助开发者解析这些数据,并做出相应的处理。
### 3.1.2 Flask.request在Web应用中的实践案例
为了更好地理解Flask.request的实际应用,我们来看一个简单的Web应用实践案例。假设我们要创建一个简单的博客应用,用户可以查看博客列表和博客详情。
在这个案例中,Flask.request用于获取用户请求的参数,比如用户想要查看的博客ID。通过这些参数,后端服务器可以从数据库中检索相应的博客内容,并将其返回给前端显示。
```python
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/blog/<int:post_id>', methods=['GET'])
def get_blog(post_id):
# 假设get_post_data是一个函数,用于从数据库中检索博客数据
post_data = get_post_data(post_id)
return jsonify(post_data)
def get_post_data(post_id):
# 这里应该有数据库查询逻辑
return {
'id': post_id,
'title': 'Example Blog Post',
'content': 'This is an example of blog post content.'
}
if __name__ == '__main__':
app.run()
```
在这个例子中,我们定义了一个路由`/blog/<int:post_id>`,它接受GET请求并期望一个博客ID作为参数。Flask.request对象的`args`属性被用来获取这个参数。然后,我们使用这个参数来从数据库中检索博客数据,并将其转换为JSON格式返回给客户端。
### 3.1.3 代码逻辑的逐行解读分析
```python
from flask import Flask, request, jsonify
app = Flask(__name__)
```
这段代码导入了Flask应用实例和request对象,并创建了一个Flask应用实例。
```python
@app.route('/blog/<int:post_id>', methods=['GET'])
def get_blog(post_id):
```
这段代码定义了一个路由`/blog/<int:post_id>`,它接受GET请求,并且指定了一个处理函数`get_blog`,其中`post_id`是路径中的一个变量部分。
```python
post_data = get_post_data(post_id)
return jsonify(post_data)
```
在`get_blog`函数内部,我们调用了一个自定义函数`get_post_data`来获取博客数据,并将结果转换为JSON格式返回。
```python
def get_post_data(post_id):
# 这里应该有数据库查询逻辑
return {
'id': post_id,
'title': 'Example Blog Post',
'content': 'This is an example of blog post content.'
}
```
`get_post_data`函数是一个示例函数,它应该包含从数据库检索博客数据的逻辑。在这个示例中,我们简单地返回了一个包含博客信息的字典。
### 3.1.4 代码逻辑的参数说明
- `Flask(__name__)`:创建Flask应用实例。
- `request`:Flask提供的全局对象,用于处理客户端请求。
- `jsonify`:Flask提供的一个函数,用于将Python字典转换为JSON格式的响应。
- `post_id`:路由中的变量部分,代表博客的ID。
通过这个实践案例,我们可以看到Flask.request如何在Web应用中获取用户请求的参数,并使用这些参数来进行数据处理。这只是一个简单的例子,实际上Flask.request可以处理更复杂的数据结构,比如表单数据、JSON数据等,并且可以与数据库进行交云。
## 3.2 Flask.request在RESTful API设计中的应用
### 3.2.1 RESTful API的基本概念和原则
RESTful API是一种软件架构风格,它定义了一组约束条件和原则,用于设计网络应用程序的前后端交互。RESTful API的主要特点是无状态、可缓存、客户端-服务器分离、统一接口和分层系统。RESTful API使用HTTP协议的标准方法,如GET、POST、PUT、DELETE等来实现资源的增删改查。
在RESTful API设计中,Flask.request对象用于解析客户端发送的HTTP请求,并提取请求中的参数。这些参数可能包括URL路径变量、查询字符串、请求体等。
### 3.2.2 Flask.request在RESTful API设计中的实践案例
假设我们要设计一个RESTful API来管理用户信息。这个API应该允许用户获取用户列表、查看单个用户详情、创建新用户、更新用户信息和删除用户。
```python
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/users', methods=['GET'])
def get_users():
# 获取查询参数
page = request.args.get('page', default=1, type=int)
# 假设get_users_data是一个函数,用于从数据库中检索用户数据
users_data = get_users_data(page)
return jsonify(users_data)
@app.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
# 假设get_user_data是一个函数,用于从数据库中检索单个用户数据
user_data = get_user_data(user_id)
return jsonify(user_data)
@app.route('/users', methods=['POST'])
def create_user():
# 假设create_user_data是一个函数,用于创建新用户
user_data = request.json
new_user_data = create_user_data(user_data)
return jsonify(new_user_data), 201
@app.route('/users/<int:user_id>', methods=['PUT'])
def update_user(user_id):
# 假设update_user_data是一个函数,用于更新用户信息
user_data = request.json
updated_user_data = update_user_data(user_id, user_data)
return jsonify(updated_user_data)
@app.route('/users/<int:user_id>', methods=['DELETE'])
def delete_user(user_id):
# 假设delete_user_data是一个函数,用于删除用户
delete_user_data(user_id)
return jsonify({'message': 'User deleted'}), 204
# ... 这里省略了数据库操作的函数实现 ...
if __name__ == '__main__':
app.run()
```
在这个例子中,我们定义了多个路由来处理不同的HTTP方法和对应的用户操作。`get_users`函数处理GET请求来获取用户列表,`get_user`函数处理GET请求来获取单个用户的详情,`create_user`函数处理POST请求来创建新用户,`update_user`函数处理PUT请求来更新用户信息,`delete_user`函数处理DELETE请求来删除用户。
### 3.2.3 代码逻辑的逐行解读分析
```python
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/users', methods=['GET'])
def get_users():
page = request.args.get('page', default=1, type=int)
users_data = get_users_data(page)
return jsonify(users_data)
```
这段代码定义了一个GET路由`/users`,它接受查询参数`page`来分页获取用户列表。
```python
@app.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
user_data = get_user_data(user_id)
return jsonify(user_data)
```
这段代码定义了一个GET路由`/users/<int:user_id>`,它接受用户ID作为路径变量,并返回单个用户的详情。
```python
@app.route('/users', methods=['POST'])
def create_user():
user_data = request.json
new_user_data = create_user_data(user_data)
return jsonify(new_user_data), 201
```
这段代码定义了一个POST路由`/users`,它接受JSON格式的请求体来创建新用户。
```python
@app.route('/users/<int:user_id>', methods=['PUT'])
def update_user(user_id):
user_data = request.json
updated_user_data = update_user_data(user_id, user_data)
return jsonify(updated_user_data)
```
这段代码定义了一个PUT路由`/users/<int:user_id>`,它接受用户ID作为路径变量,并接受JSON格式的请求体来更新用户信息。
```python
@app.route('/users/<int:user_id>', methods=['DELETE'])
def delete_user(user_id):
delete_user_data(user_id)
return jsonify({'message': 'User deleted'}), 204
```
这段代码定义了一个DELETE路由`/users/<int:user_id>`,它接受用户ID作为路径变量来删除用户。
### 3.2.4 代码逻辑的参数说明
- `request.args`:用于获取URL查询参数。
- `request.json`:用于获取JSON格式的请求体数据。
- `user_id`:URL路径变量,代表用户的唯一标识。
通过这些实践案例,我们可以看到Flask.request如何在RESTful API设计中发挥作用,它帮助我们解析客户端的请求,并根据不同的HTTP方法来执行相应的数据库操作。
## 3.3 Flask.request在Web爬虫中的应用
### 3.3.1 Web爬虫的基本原理和方法
Web爬虫(也称为网络蜘蛛或网络机器人)是一种自动访问网站并从中提取信息的程序。它通常从一个初始URL开始,解析页面内容,提取新的URL链接,然后访问这些链接,重复这一过程。
Flask.request在Web爬虫中的应用通常涉及到模拟HTTP请求,获取响应内容,并解析这些内容以提取所需数据。Flask本身不是专门用于爬虫的工具,但是可以用来创建爬虫的基础服务或中间件。
### 3.3.2 Flask.request在Web爬虫中的实践案例
假设我们要创建一个简单的Web爬虫来抓取一个博客网站的文章标题和链接。我们将使用Flask来模拟HTTP请求,并使用BeautifulSoup库来解析HTML内容。
```python
from flask import Flask, request, Response
from bs4 import BeautifulSoup
import requests
app = Flask(__name__)
@app.route('/scrape', methods=['GET'])
def scrape_blog():
# 目标博客网站的URL
target_url = '***'
# 发送HTTP请求
response = requests.get(target_url)
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取文章标题和链接
posts = soup.find_all('a', class_='post-title')
results = []
for post in posts:
title = post.get_text()
link = post['href']
results.append({'title': title, 'link': link})
return jsonify(results)
if __name__ == '__main__':
app.run()
```
在这个例子中,我们定义了一个GET路由`/scrape`,它发送一个HTTP请求到目标博客网站,并使用BeautifulSoup来解析HTML页面。然后,我们查找所有的文章标题和链接,并将结果以JSON格式返回。
### 3.3.3 代码逻辑的逐行解读分析
```python
from flask import Flask, request, Response
from bs4 import BeautifulSoup
import requests
app = Flask(__name__)
@app.route('/scrape', methods=['GET'])
def scrape_blog():
target_url = '***'
response = requests.get(target_url)
soup = BeautifulSoup(response.text, 'html.parser')
posts = soup.find_all('a', class_='post-title')
results = []
for post in posts:
title = post.get_text()
link = post['href']
results.append({'title': title, 'link': link})
return jsonify(results)
```
这段代码定义了一个GET路由`/scrape`,它首先发送一个HTTP请求到目标博客网站,然后解析HTML内容以查找文章标题和链接,并将结果以JSON格式返回。
### 3.3.4 代码逻辑的参数说明
- `requests.get(target_url)`:发送一个GET请求到目标URL。
- `BeautifulSoup(response.text, 'html.parser')`:解析HTTP响应的HTML内容。
- `soup.find_all('a', class_='post-title')`:查找所有包含特定类名的文章标题链接。
通过这个实践案例,我们可以看到Flask.request如何在Web爬虫中发挥作用,它用于发送HTTP请求并获取响应内容,然后可以与其他库(如BeautifulSoup)结合来解析HTML并提取所需数据。
# 4. Flask.request的性能优化和安全策略
在本章节中,我们将深入探讨如何对Flask.request进行性能优化和安全策略的实施。随着Web应用的日益复杂和用户量的不断增长,性能优化和安全防护成为了每个开发者都必须面对的重要课题。我们将从性能优化的角度出发,探讨WSGI应用的性能瓶颈和优化方法,以及Flask.request的性能优化实践。接着,我们将讨论Web应用面临的安全威胁和防护措施,以及Flask.request的安全使用策略。最后,我们将介绍Flask.request的调试和测试方法,包括调试工具、单元测试和集成测试。
## 4.1 Flask.request的性能优化
### 4.1.1 WSGI应用的性能瓶颈和优化方法
WSGI(Web Server Gateway Interface)是Python中用于Web服务器和Web应用或框架之间的一种简单通用的接口。然而,在处理大量并发请求时,WSGI应用可能会遇到性能瓶颈。以下是一些常见的性能瓶颈及其优化方法:
#### 性能瓶颈
1. **I/O密集型操作**:当应用程序执行大量磁盘I/O或网络I/O操作时,可能会导致性能瓶颈。
2. **计算密集型操作**:长时间运行的CPU密集型任务会阻塞主线程,影响性能。
3. **数据库查询**:数据库操作是Web应用中最常见的瓶颈之一,尤其是慢查询和不合理的数据结构设计。
#### 优化方法
1. **异步处理I/O**:使用异步库(如`asyncio`)或异步框架(如`Quart`)来处理I/O密集型操作,可以提高性能。
2. **多进程或多线程**:对于CPU密集型任务,可以使用多进程或多线程来分散计算负载。
3. **数据库优化**:优化SQL查询,使用数据库索引,合理设计数据模型和查询逻辑,减少不必要的数据加载。
### 4.1.2 Flask.request的性能优化实践
Flask.request的性能优化不仅仅依赖于WSGI层面的处理,还包括Flask应用本身的一些实践。以下是一些实践中的性能优化策略:
#### 1. 使用缓存
缓存是提高Web应用性能的重要手段。例如,可以使用`Flask-Caching`扩展来缓存视图函数的返回值。
```python
from flask import Flask
from flask_caching import Cache
app = Flask(__name__)
cache = Cache(app, config={'CACHE_TYPE': 'simple'})
@cache.cached(timeout=50)
def get_data():
# Heavy computation or data retrieval logic
return computation_or_retrieval_logic()
@app.route('/')
def index():
return get_data()
```
#### 2. 减少视图函数的执行时间
确保视图函数尽可能高效,避免在视图函数中进行复杂的逻辑处理。
#### 3. 使用生产级WSGI服务器
Flask自带的WSGI服务器(如`Werkzeug`开发服务器)不适合生产环境,应使用`Gunicorn`、`uWSGI`等生产级WSGI服务器。
### 4.1.3 代码逻辑分析
在上述代码示例中,我们使用了`Flask-Caching`扩展来缓存视图函数`get_data`的返回值。这个函数被`@cache.cached(timeout=50)`装饰器装饰,意味着函数的返回值将在50秒内被缓存。如果在这段时间内再次访问,将直接返回缓存的结果,避免了重复执行耗时的计算或数据检索逻辑。
### 4.1.4 参数说明
- `CACHE_TYPE`: 缓存类型,这里使用的是`simple`,表示简单缓存。
- `timeout`: 缓存的超时时间,单位是秒。
## 4.2 Flask.request的安全策略
### 4.2.1 Web应用的安全威胁和防护措施
Web应用面临着多种安全威胁,包括但不限于:
#### 安全威胁
1. **SQL注入**:攻击者通过输入恶意SQL代码来篡改或非法获取数据。
2. **跨站脚本攻击(XSS)**:攻击者在网页中注入恶意脚本,以窃取用户信息或破坏用户浏览体验。
3. **跨站请求伪造(CSRF)**:攻击者利用用户的身份,欺骗服务器执行非预期的操作。
#### 防护措施
1. **使用参数化查询**:避免直接将用户输入拼接到SQL查询中,使用参数化查询来防止SQL注入。
2. **内容安全策略(CSP)**:通过设置合适的CSP,可以限制网页中加载的资源,防止XSS攻击。
3. **CSRF令牌**:在Web表单中添加CSRF令牌,并验证请求中的令牌值,以防止CSRF攻击。
### 4.2.2 Flask.request的安全使用策略
Flask框架提供了一些内置的安全功能和策略,以及一些扩展来帮助开发者提高Web应用的安全性。
#### 1. 使用安全的请求处理
Flask默认启用了CSRF保护,开发者可以通过`CsrfProtect`扩展来进一步加强CSRF保护。
```python
from flask_wtf.csrf import CsrfProtect
from flask import Flask
app = Flask(__name__)
CsrfProtect(app)
# 在表单中生成CSRF令牌
from flask_wtf import FlaskForm
from wtforms import StringField
from wtforms.validators import DataRequired
class LoginForm(FlaskForm):
username = StringField('Username', validators=[DataRequired()])
password = StringField('Password', validators=[DataRequired()])
csrf_token = HiddenField('csrf_token', default=lambda: request.cookies.get('csrf_token'))
```
#### 2. 使用安全的模板过滤器
Flask内置了一些安全的模板过滤器,如`escape`,用于防止XSS攻击。
```html
<!-- 安全地渲染用户输入 -->
{{ user_input|escape }}
```
### 4.2.3 代码逻辑分析
在上述代码示例中,我们使用了`Flask-WTF`扩展来启用CSRF保护,并在表单中生成了CSRF令牌。`CsrfProtect`扩展是一个Flask扩展,用于为应用添加CSRF保护功能。在表单类`LoginForm`中,我们定义了一个`csrf_token`字段,该字段通过Flask的`request`对象获取了CSRF令牌。
### 4.2.4 参数说明
- `FlaskForm`: Flask-WTF扩展提供的表单基类。
- `StringField`: 用于创建文本输入字段。
- `DataRequired`: 验证器,确保输入不为空。
## 4.3 Flask.request的调试和测试
### 4.3.1 Flask.request的调试工具和方法
调试是开发过程中不可或缺的一部分,Flask提供了多种工具和方法来帮助开发者进行调试。
#### 调试工具
1. **Flask的内置调试器**:在开发模式下,Flask可以启用内置的调试器,提供交互式的调试环境。
2. **Flask-Profiler**:这是一个Flask扩展,用于性能分析和性能监控。
#### 调试方法
1. **日志记录**:使用Python的`logging`模块或Flask的`logger`来记录应用的运行状态和错误信息。
2. **错误处理**:合理设置错误处理器,记录并展示错误信息。
### 4.3.2 Flask.request的单元测试和集成测试
单元测试和集成测试是确保代码质量和应用稳定性的关键。
#### 1. 使用`pytest`进行单元测试
`pytest`是一个强大的Python测试框架,可以用来编写Flask应用的单元测试。
```python
import pytest
from flask import Flask
from myapp import app
def test_index():
with app.test_client() as client:
response = client.get('/')
assert response.status_code == 200
```
#### 2. 使用`Flask-Testing`扩展进行集成测试
`Flask-Testing`扩展提供了简单的测试工具,可以用来模拟客户端请求。
```python
from flask_testing import TestCase
from myapp import app
class MyTest(TestCase):
def create_app(self):
return app
def test_index(self):
response = self.client.get('/')
self.assertEqual(response.status_code, 200)
```
### 4.3.3 代码逻辑分析
在上述代码示例中,我们展示了如何使用`pytest`进行Flask应用的单元测试。`pytest`与Flask的`test_client`结合使用,可以在不启动完整应用的情况下测试视图函数。我们定义了一个`test_index`函数,用于测试主页视图返回的状态码是否为200。
在第二个代码示例中,我们使用了`Flask-Testing`扩展进行集成测试。我们定义了一个`MyTest`类,该类继承自`TestCase`,并重写了`create_app`方法来提供应用实例。`test_index`方法模拟了一个GET请求到主页,并验证响应的状态码是否为200。
### 4.3.4 参数说明
- `pytest`: Python的测试框架。
- `test_client()`: Flask提供的测试客户端,用于模拟HTTP请求。
- `create_app()`: Flask-Testing扩展要求的函数,用于提供应用实例。
### 4.3.5 表格展示
| 测试类型 | 使用工具 | 描述 |
| --- | --- | --- |
| 单元测试 | pytest | 测试应用的最小部分,确保功能正确 |
| 集成测试 | Flask-Testing | 测试应用的多个部分协同工作,确保整体功能正确 |
| 性能测试 | Flask-Profiler | 性能分析和性能监控,优化性能瓶颈 |
### 4.3.6 mermaid流程图展示
```mermaid
graph LR
A[开始] --> B{是否为单元测试}
B -- 是 --> C[使用pytest]
B -- 否 --> D{是否为集成测试}
C --> E[模拟HTTP请求]
D -- 是 --> F[使用Flask-Testing]
F --> G[模拟客户端请求]
E --> H[验证结果]
G --> H[验证结果]
H --> I[结束]
```
在本章节中,我们详细探讨了Flask.request的性能优化和安全策略,以及调试和测试的方法。通过上述内容的介绍,我们可以看到,性能优化和安全策略是保障Web应用稳定运行和数据安全的重要手段。同时,良好的调试和测试习惯可以帮助我们及时发现和修复问题,提高代码质量。在接下来的章节中,我们将通过具体的实践案例,进一步展示Flask.request在不同场景下的应用。
# 5. Flask.request的调试和测试
## 5.1 Flask.request的调试工具和方法
在Flask应用开发过程中,调试是一个不可或缺的环节。Flask提供了一些内置的调试工具和方法,可以帮助开发者快速定位和解决问题。其中最为常用的是`flask shell`和`flask run`命令。
### 5.1.1 Flask shell
`flask shell`命令允许开发者打开一个交互式的Python shell,其中包含了Flask应用的上下文环境。这意味着你可以直接访问`flask.request`对象以及其他Flask应用相关的变量和方法。
```python
$ flask shell
Python 3.8.1 (default, Jan 8 2020, 20:33:51)
[GCC 8.3.0] on linux
App: myapp [development]
Instance: /path/to/myapp/instance
>>> from myapp import app
>>> from myapp.models import User
>>> User.query.all()
```
### 5.1.2 Flask run
`flask run`命令用于启动Flask开发服务器,它会自动应用Flask应用的上下文。这个命令对于本地开发和测试非常有用。
```python
$ flask run
* Running on ***
```
### 5.1.3 Flask CLI
Flask命令行接口(CLI)提供了许多有用的命令,如`flask routes`可以列出应用中的路由,`flask -h`可以查看所有可用的命令。
```python
$ flask routes
Endpoint Methods Rule
-------------------------------- -------- -----------------------
hello GET /hello
static GET /static/<path:filename>
```
### 5.1.4 IPython和PDB
除了Flask内置的调试工具,开发者还可以使用IPython和PDB进行更深入的调试。IPython提供了增强的交互式Python环境,而PDB则是Python的标准调试工具。
```python
# 使用IPython
$ ipython
In [1]: %load_ext flask
# 使用PDB
import pdb; pdb.set_trace()
```
## 5.2 Flask.request的单元测试和集成测试
编写测试用例是保证Flask应用质量和可靠性的关键步骤。Flask提供了一些内置的测试工具,可以帮助开发者编写和运行测试。
### 5.2.1 Flask测试客户端
Flask测试客户端可以模拟HTTP请求,允许开发者在不启动服务器的情况下测试视图函数。
```python
from flask import Flask
from flask.testing import FlaskClient
app = Flask(__name__)
@app.route('/hello')
def hello():
return 'Hello, World!'
# 使用Flask测试客户端
def test_hello(client):
response = client.get('/hello')
assert response.data == b'Hello, World!'
```
### 5.2.2 Flask的测试框架集成
Flask可以与多种Python测试框架集成,如pytest和unittest。
#### pytest
pytest是一个非常流行的Python测试框架,它支持自动发现测试用例,提供了丰富的插件系统。
```python
# 安装pytest
$ pip install pytest
# 编写pytest测试用例
def test_hello(client):
response = client.get('/hello')
assert response.data == b'Hello, World!'
```
#### unittest
unittest是Python标准库的一部分,提供了一个丰富的测试框架。
```python
# 编写unittest测试用例
import unittest
class MyTestCase(unittest.TestCase):
def setUp(self):
self.client = app.test_client()
def test_hello(self):
response = self.client.get('/hello')
self.assertEqual(response.data, b'Hello, World!')
```
### 5.2.3 测试覆盖率
为了确保测试用例的全面性,可以使用测试覆盖率工具来评估测试覆盖率。
```python
# 安装coverage
$ pip install coverage
# 使用coverage运行测试
$ coverage run -m unittest discover
```
### 5.2.4 测试报告
除了代码覆盖率,还可以生成详细的测试报告,如HTML报告。
```python
# 安装pytest-html
$ pip install pytest-html
# 使用pytest-html生成HTML测试报告
$ pytest --html=report.html
```
通过使用这些工具和方法,开发者可以确保Flask应用的稳定性和可靠性。下一章节我们将继续探讨Flask.request在生产环境中的高级应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析 Flask.request,为 Python 开发者提供全面的指南。从基本用法到高级技巧,再到性能优化和安全防护,本专栏涵盖了使用 Flask.request 构建 RESTful API 和高性能 WSGI 应用所需的一切知识。通过掌握 Flask.request 的奥秘,开发者可以打造可维护、可扩展且健壮的 API 系统,有效提升并发处理能力,并防范请求攻击。本专栏还深入探讨了 Flask.request 背后的原理,帮助开发者深入理解 Werkzeug 和请求解析过程。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Nginx终极优化手册】:提升性能与安全性的20个专家技巧
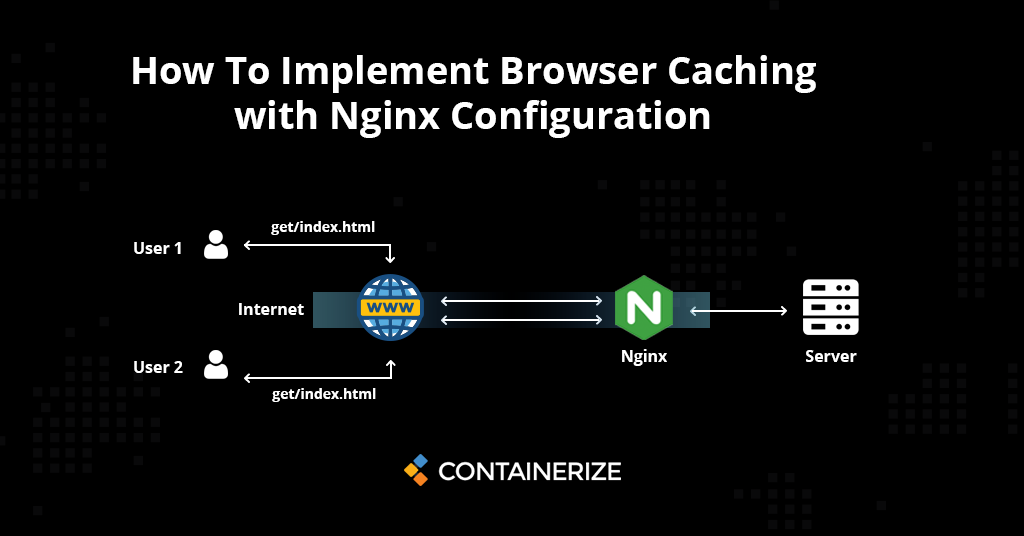
# 摘要
本文详细探讨了Nginx的优化方法,涵盖从理论基础到高级应用和故障诊断的全面内容。通过深入分析Nginx的工作原理、性能调优、安全加固以及高级功能应用,本文旨在提供一套完整的优化方案,以提升Nginx
【云计算入门】:从零开始,选择并部署最适合的云平台

# 摘要
云计算作为一种基于互联网的计算资源共享模式,已在多个行业得到广泛应用。本文首先对云计算的基础概念进行了详细解析,并深入探讨了云服务模型(IaaS、PaaS和SaaS)的特点和适用场景。随后,文章着重分析了选择云服务提供商时所需考虑的因素,包括成本、性能和安全性,并对部署策略进行了讨论,涉及不同云环境(公有云、私有云和混合云)下的实践操作指导。此外,本文还覆盖了云安全和资源管理的实践,包括
【Python新手必学】:20分钟内彻底解决Scripts文件夹缺失的烦恼!
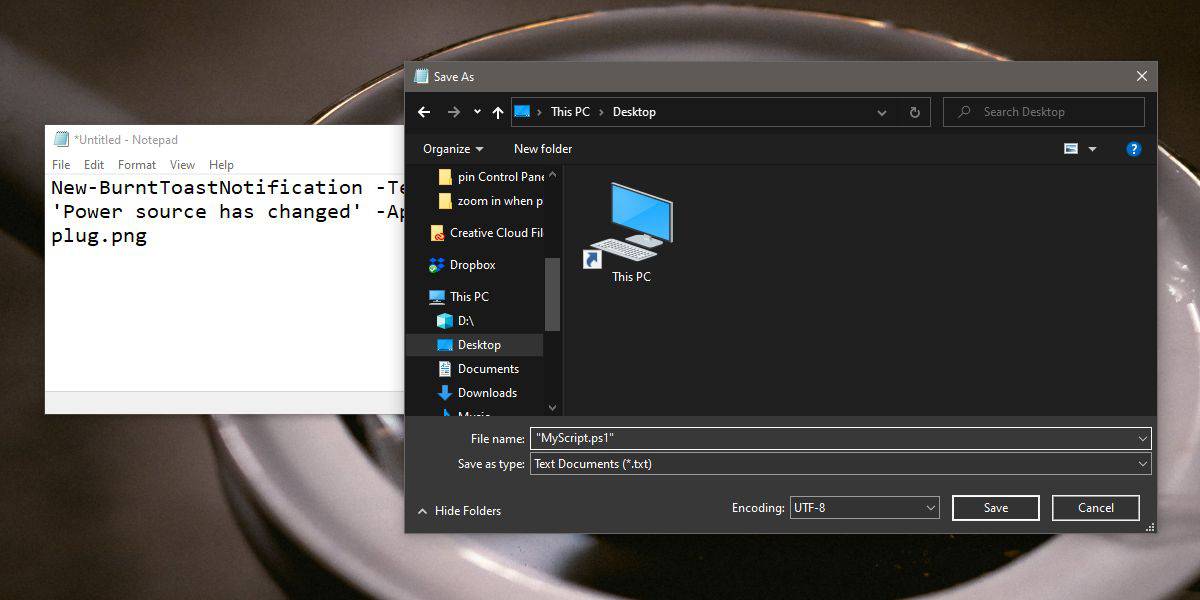
# 摘要
Python作为一种流行的编程语言,其脚本的编写和环境设置对于初学者和专业开发者都至关重要。本文从基础概念出发,详细介绍了Python脚本的基本结构、环境配置、调试与执行技巧,以及进阶实践和项目实战策略。重点讨论了如何通过模块化、包管理、利用外部库和自动化技术来提升脚本的功能性和效率。通过对Python脚本从入门到应用的系统性讲解,本文
【Proteus硬件仿真】:揭秘点阵式LED显示屏设计的高效流程和技巧
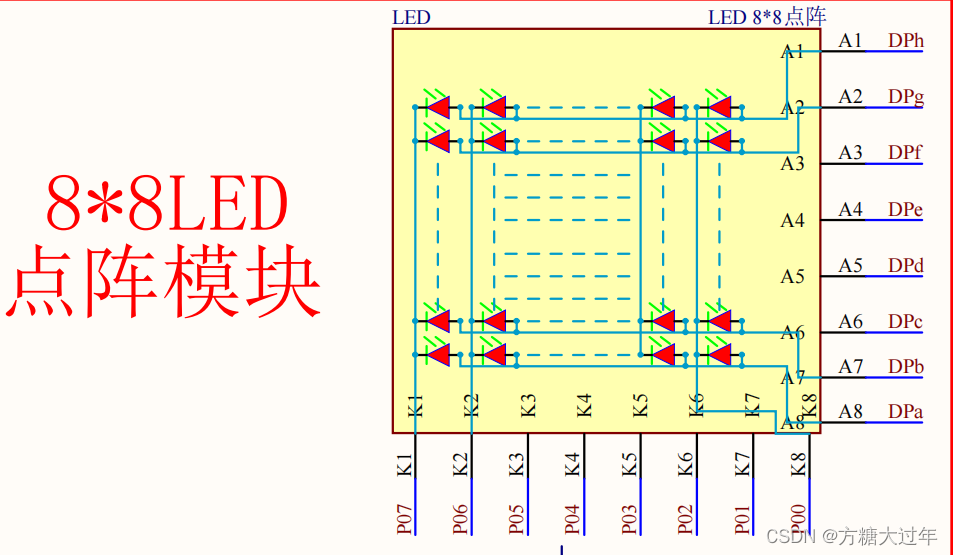
# 摘要
本论文旨在为点阵式LED显示屏的设计与应用提供全面的指导。首先介绍了点阵式LED显示屏的基础知识,并详细阐述了Proteus仿真环境的搭建与配置方法。随后,论文深入探讨了LED显示屏的设计流程,包括硬件设计基础、软件编程思路及系统集成测试,为读者提供了从理论到实践的完整知识链。此外,还分享了一些高级应用技巧,如多彩显示、微控制器接口设计、节能优化与故障预防等,以帮助读者提升产
Nginx配置优化秘籍:根目录更改与权限调整,提升网站性能与安全性

# 摘要
Nginx作为一个高性能的HTTP和反向代理服务器,广泛应用于现代网络架构中。本文旨在深入介绍Nginx的基础配置、权限调整、性能优化、安全性提升以及高级应用。通过探究Nginx配置文件结构、根目录的设置、用户权限管理以及缓存控制,本文为读者提供了系统化的部署和管理Nginx的方法。此外,文章详细阐述了Nginx的安全性增强措施,包括防止安全威胁、配置SSL/TLS
数字滤波器优化大揭秘:提升网络信号效率的3大策略
# 摘要
数字滤波器作为处理网络信号的核心组件,在通信、医疗成像以及物联网等众多领域发挥着关键作用。本文首先介绍了数字滤波器的基础知识和分类,探讨了其在信号数字化过程中的重要性,并深入分析了性能评价的多个指标。随后,针对数字滤波器的优化策略,本文详细讨论了算法效率提升、硬件加速技术、以及软件层面的优化技巧。文章还通过多个实践应用案例,展示了数字滤波器在不同场景下的应用效果和优化实例。最后,本文展望了数字滤波器未来的发展趋势,重点探讨了人工智能与机器学习技术的融合、绿色计算及跨学科技术融合的创新方向。
# 关键字
数字滤波器;信号数字化;性能评价;算法优化;硬件加速;人工智能;绿色计算;跨学科
RJ-CMS模块化设计详解:系统可维护性提升50%的秘密
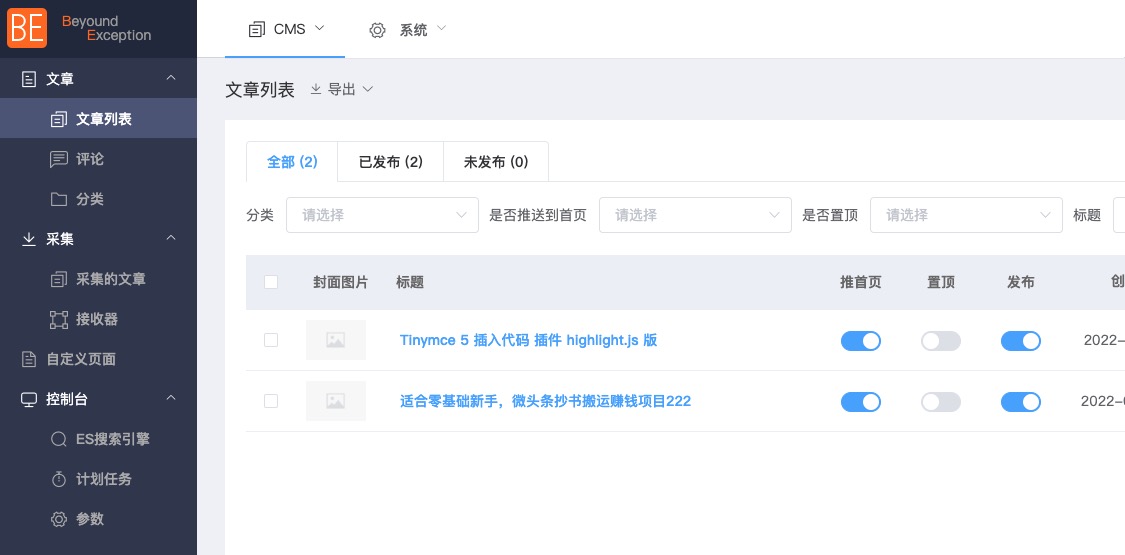
# 摘要
随着互联网技术的快速发展,内容管理系统(CMS)的模块化设计已经成为提升系统可维护性和扩展性的关键技术。本文首先介绍了RJ-CMS的模块化设计概念及其理论基础,详细探讨了模块划分、代码组织、测试与部署等实践方法,并分析了模块化系统在配置、性能优化和安全性方面的高级技术。通过对RJ-CMS模块化设计的深入案例分析,本文旨在揭示模块化设计在实际应用中的成功经验、面临的问题与挑战,并展望其未来发展趋势,以期为CMS的模块化设计提供参考和借鉴。
# 关
AUTOSAR多核实时操作系统的设计要点

# 摘要
随着计算需求的增加,多核实时操作系统在满足确定性和实时性要求方面变得日益重要。本文首先概述了多核实时操作系统及其在AUTOSAR标准中的应用,接着探讨了多核系统架构的设计原则,包括处理多核处理器的挑战、确定性和实时性以及系统可伸缩性。文章重点介绍了多核实时操作系统的关键技术,如任务调度、内存管理、中断处理及服务质量保证。通过分析实际的多核系统案例,评估了性能并提出了优化策略。最后,本文
五个关键步骤:成功实施业务参数配置中心系统案例研究

# 摘要
本文对业务参数配置中心进行了全面的探讨,涵盖了从概念解读到实际开发实践的全过程。首先,文章对业务参数配置中心的概念进行了详细解读,并对其系统需求进行了深入分析与设计。在此基础上,文档深入到开发实践,包括前端界面开发、后端服务开发以及配置管理与动态加载。接着,文中详细介绍了业务参数配置中心的部署与集成过程,包括环境搭建、系统集成测试和持续集成与自动化部署。最后,通过对成功案例的分析,文章总结了在项目实施过程中的经验教训和
Origin坐标轴颜色与图案设计:视觉效果优化的专业策略
# 摘要
本文全面探讨了Origin软件中坐标轴设计的各个方面,包括基本概念、颜色选择、图案与线条设计,以及如何将这些元素综合应用于提升视觉效果。文章首先介绍了坐标轴设计的基础知识,然后深入研究了颜色选择对数据表达的影响,并探讨了图案与线条设计的理论和技巧。随后,本文通过实例分析展示了如何综合运用视觉元素优化坐标轴,并探讨了交互性设计对用户体验的重要性。最后,文章展望了高级技术如机器学习在视觉效果设计中的应用,以及未来趋势对数据可视化学科的影响。整体而言,本文为科研人员和数据分析师提供了一套完整的坐标轴设计指南,以增强数据的可理解性和吸引力。
# 关键字
坐标轴设计;颜色选择;数据可视化;交
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )