【效率之选】:C++ find与各类查找算法性能深度对比
发布时间: 2024-10-19 14:15:42 阅读量: 44 订阅数: 40 

数据结构、算法与应用 C++语言描述 原书第2版.pdf

# 1. C++查找算法概览
在计算机科学领域,查找算法是基础且极其重要的数据处理工具,它涉及到数据检索的效率和准确性。C++作为一门强大的编程语言,提供了多种查找算法,满足不同场合下的查找需求。本章将为读者提供C++查找算法的概览,初步了解各种查找方法,为深入学习和应用打下基础。随后的章节将深入探讨具体算法,评估效率,并介绍高级和实用技术。
## 1.1 查找算法的重要性
查找算法是信息检索的关键技术之一。在数据分析、数据库管理和软件开发等多个领域,查找算法的效率直接影响到程序的性能。了解不同查找算法的特点和适用环境,对于编写高效、优化的代码至关重要。
## 1.2 查找算法的分类
在C++中,查找算法可以从基本的线性查找到高效的二分查找,再到复杂的并行查找和分布式查找等多种类型。每种算法都有其特点、适用场景和效率差异,合理选择和应用查找算法是提高程序性能的关键。
## 1.3 本章小结
通过本章概览,我们已经初步了解了查找算法在C++编程中的重要性、主要类型以及应用的广泛性。接下来的章节,我们将深入探讨C++标准库提供的查找函数,评估它们的效率,并进一步了解高级查找算法和它们在实际应用中的选择与优化策略。
# 2. C++中的基本查找函数
## 2.1 std::find与迭代器
### 2.1.1 std::find函数的使用方法
`std::find` 是C++标准库提供的一个用于查找序列中元素的函数模板。它是容器类库中find成员函数的一个泛化版本。`std::find`可以用于所有支持迭代器的容器,比如`std::vector`, `std::list`, `std::deque`等。
`std::find`函数的原型如下:
```cpp
template< class InputIt, class T >
InputIt find( InputIt first, InputIt last, const T& value );
```
参数解释:
- `first`:指向序列开始的迭代器。
- `last`:指向序列结束的迭代器。
- `value`:需要查找的元素值。
返回值:若找到了该元素,则返回一个指向该元素的迭代器;否则,返回`last`。
使用示例:
```cpp
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
int valueToFind = 3;
auto result = std::find(vec.begin(), vec.end(), valueToFind);
if (result != vec.end()) {
std::cout << "Found: " << *result << std::endl;
} else {
std::cout << "Not Found" << std::endl;
}
return 0;
}
```
### 2.1.2 与手写循环的比较
手写循环查找可以让我们精确地控制查找过程中的每一步,同时在查找过程中可以执行一些额外的操作。然而,在大多数情况下,使用`std::find`更为简洁且效率并不亚于手写循环。
手写循环查找的一个简单例子:
```cpp
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
int valueToFind = 3;
for (auto it = vec.begin(); it != vec.end(); ++it) {
if (*it == valueToFind) {
std::cout << "Found: " << *it << std::endl;
break;
}
}
return 0;
}
```
使用`std::find`的优点:
- 代码可读性更强,易于理解。
- 灵活性较高,可以查找任何容器中的元素。
- 标准库经过优化,可能比手写循环更快。
缺点:
- 无法在查找过程中插入额外操作。
- 在一些非标准库容器中可能不具备。
### 2.2 查找算法的效率评估
#### 2.2.1 时间复杂度分析
`std::find`的时间复杂度通常是O(n),因为它在最坏的情况下需要遍历整个序列。在平均情况下,如果元素位于序列的中间位置,则也会需要O(n/2)的时间复杂度,这仍然被视为O(n)。
时间复杂度是衡量算法性能的重要指标之一,表示了算法操作的数量与输入数据大小之间的关系。通常,我们更倾向于选择时间复杂度更低的算法。
#### 2.2.2 实际测试与数据解读
实际测试是评估查找算法效率的重要手段。通过测试不同大小序列中的查找性能,可以直观地比较不同算法的优势和劣势。
```cpp
#include <iostream>
#include <vector>
#include <chrono>
#include <algorithm>
int main() {
std::vector<int> vec(1000000, 1); // 创建包含一百万个元素的向量
int valueToFind = 1;
auto start = std::chrono::high_resolution_clock::now();
auto result = std::find(vec.begin(), vec.end(), valueToFind);
auto stop = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(stop - start).count();
std::cout << "Time taken by function: " << duration << " microseconds" << std::endl;
return 0;
}
```
在实际测试中,我们可以得到查找操作消耗的时间,从而评估算法的效率。
## 2.3 标准库中的其它查找工具
### 2.3.1 std::find_if的使用场景
`std::find_if`是`std::find`的一个扩展版本,它允许用户根据更复杂的条件来进行查找。
```cpp
template< class InputIt, class UnaryPredicate >
InputIt find_if( InputIt first, InputIt last, UnaryPredicate p );
```
参数解释:
- `first`, `last`:同`std::find`。
- `p`:一个一元谓词(可以是一个函数指针、lambda表达式或函数对象),用于确定查找条件。
使用示例:
```cpp
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
auto result = std::find_if(vec.begin(), vec.end(), [](int i) { return i % 2 == 0; });
if (result != vec.end()) {
std::cout << "Found even number: " << *result << std::endl;
} else {
std::cout << "Not Found" << std::endl;
}
return 0;
}
```
### 2.3.2 std::binary_search与有序序列
`std::binary_search`是一个在有序序列中进行查找的函数模板,它采用二分查找算法,因此在最坏的情况下,时间复杂度为O(log n)。
```cpp
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
std::sort(vec.begin(), vec.end()); // 确保序列是有序的
int valueToFind = 3;
if (std::binary_search(vec.begin(), vec.end(), valueToFind)) {
std::cout << "Found: " << valueTo
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
C++算法库专栏深入探讨了C++标准库中sort和find算法的内部机制、优化技巧和性能分析。它涵盖了从二叉树原理到内存管理、泛型编程和并发技术等广泛主题。专栏文章提供了详细的指南,帮助开发者掌握sort和find算法的极致优化策略,并了解其在实际项目中的应用和局限性。此外,专栏还探讨了自定义查找算法库的创建、C++算法库的拓展以及与其他语言排序函数的性能对比,为开发者提供了全面的C++算法库知识和实践技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ADS变压器模型精确仿真:挑战与对策

# 摘要
本文综合探讨了ADS变压器模型的基本概念、仿真理论基础、技术挑战以及实践对策,并通过案例分析具体展示了变压器模型的构建与仿真流程。文中首先介绍了ADS变压器模型的重要性及仿真理论基础,深入讲解了电磁场理论、变压器原理和仿真软件ADS的功能。接着,本文详细阐述了在变压器模型精确仿真中遇到的技术挑战,包括模型精确度与计算资源的平衡、物理现象复杂性的多维度仿真以及实验验证与仿真
【微信小程序用户信息获取案例研究】:最佳实践的深度解读
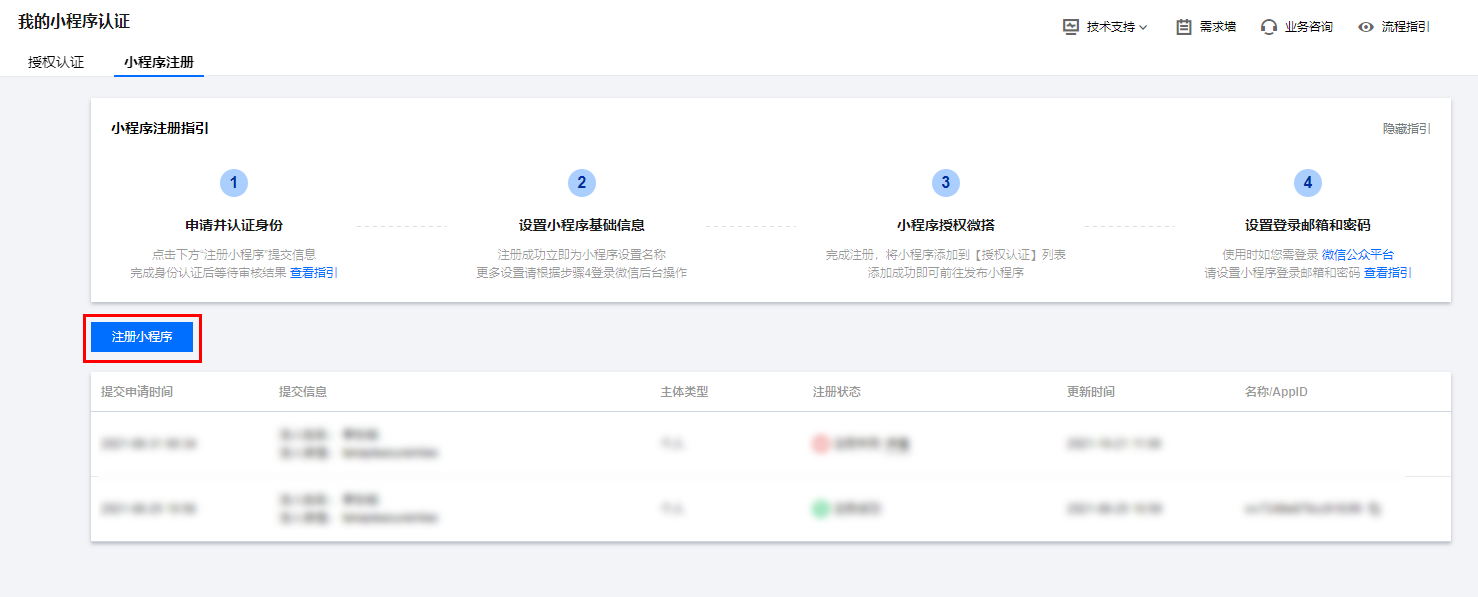
# 摘要
微信小程序作为一种新型的应用程序形态,为用户提供便捷的服务同时,也带来了用户信息获取与管理的挑战。本文全面概述了微信小程序在用户信息获取方面的理论基础、实践应用以及进阶技巧。首先,介绍了微信小程序用户信息获取的机制和权限要求,随后分析了用户信息的存储方式和安全管理。接着,本文通过编程实现与应用实例,展示了用户信息获取的实践过程和解决方法。此外,还探
VCS高级玩家指南:精通版本冲突解决和合并策略
# 摘要
版本控制系统(VCS)在软件开发中扮演着至关重要的角色,其变迁反映了软件工程的发展。本文首先概述了版本控制系统的概念和理论基础,探讨了版本冲突的类型、原因及其根本成因。接着分析了版本控制的工作流程,包括分支模型和版本历史管理。本文详细介绍了在不同项目环境中VCS合并策略的实践技巧,包括企业级、开源项目以及小团队的特定需求。最后,文章展望了自动化和智能化的VCS合并策略的未来趋势,特别是深度学习在代码合并中的
FLAC安全防护指南:代码和数据的终极保护方案
# 摘要
本文对FLAC加密技术进行了全面的概述和深入的原理分析。首先介绍了加密技术的基本理论,包括对称与非对称加密技术的演进和历史。随后详细探讨了FLAC加密算法的流程和其独特的优势与特点,以及密钥管理与保护机制,如密钥的生命周期管理和安全的生成、存储、销毁策略。在代码安全实践章节,分析了FLAC代码保护方法、常见代码攻击的防御手段,以及FLAC在软件开发生命周期中的应用。数据保护实践章节涵盖了
【深入剖析MPU-9250】:掌握9轴传感器核心应用与优化技巧(权威指南)

# 摘要
MPU-9250是一款高性能的多轴运动处理单元,集成了加速度计、陀螺仪和磁力计传感器,广泛应用于需要精确定位和运动检测的场合。本文首先介绍MPU-9250传感器的基本概念及其硬件接口,详细解析I2C和SPI两种通信协议。接着,文章深入探讨了固件开发、编程技巧及调试过程,为开发者提供了丰富的工具链信息。此外,还着重分析了多轴传感器数据融合技术
【故障与恢复策略模拟】:PowerWorld故障分析功能的实战演练
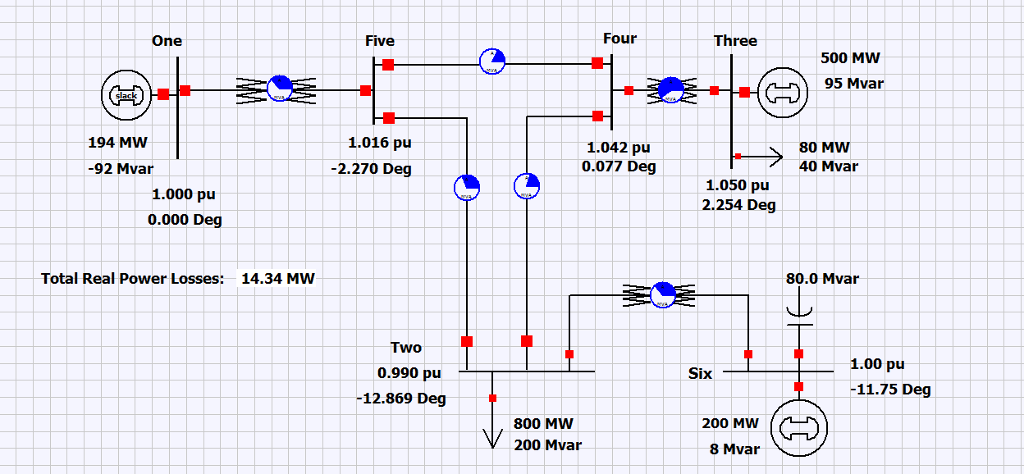
# 摘要
本文旨在详细探讨PowerWorld在电力系统故障分析中的应用。首先,概述了故障分析功能和相关理论基础,并介绍了如何准备PowerWorld模拟环境。随后,通过模拟各类电力系统故障,分析了故障模式和恢复策略,并详细演练了故障模拟。进一步地,本文深入分析了收集到的故障数据,并评估了故障恢复的效率,提出了优化建议。最
【RTL8822CS模块操作系统兼容性】:硬件集成的最佳实践
# 摘要
RTL8822CS模块是一个高集成度的无线通讯解决方案,广泛应用于多种操作系统环境中。本文首先概述了RTL8822CS模块的基本功能与特点以及其在不同操作系统下的工作原理。随后,文章深入探讨了该模块的硬件集成理论,包括技术参数解析、操作系统兼容性策略和驱动程序开发基础。接着,作者通过实际案例分析了RTL8822CS模块在Windows、Linux和macOS操作系
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )