Python字符串字母个数统计与网络爬虫:从网络中提取有价值的信息
发布时间: 2024-06-25 08:52:01 阅读量: 73 订阅数: 31 

统计字符串中每个字母的个数

# 1. Python字符串字母个数统计
Python字符串字母个数统计是一种常见的文本处理任务,它涉及计算字符串中每个字母出现的次数。本节将介绍如何使用Python中的内置函数和第三方库来实现字符串字母个数统计。
### 使用内置函数
Python提供了`collections.Counter`类,它可以方便地统计字符串中字符出现的次数。以下代码演示了如何使用`Counter`统计字符串中每个字母出现的次数:
```python
from collections import Counter
text = "Hello World"
letter_counts = Counter(text)
print(letter_counts)
```
输出:
```
Counter({'l': 3, 'o': 2, 'H': 1, 'e': 1, 'W': 1, 'r': 1, 'd': 1})
```
# 2. Python网络爬虫基础
### 2.1 网络爬虫的原理和架构
**原理**
网络爬虫,又称网络蜘蛛,是一种自动获取网络信息的程序。其原理是模拟浏览器发送HTTP请求,获取服务器响应,解析响应内容,提取所需信息,并根据预定义的规则继续爬取其他页面。
**架构**
一个典型的网络爬虫架构包括以下组件:
- **调度器:**管理爬取队列,决定下一步要爬取的URL。
- **下载器:**发送HTTP请求,获取服务器响应。
- **解析器:**解析响应内容,提取所需信息。
- **存储器:**存储爬取到的数据。
- **处理器:**对爬取到的数据进行进一步处理,如过滤、清洗和分析。
### 2.2 网络爬虫的请求和响应处理
**请求**
网络爬虫发送的HTTP请求通常包含以下信息:
- **URL:**要爬取的页面地址。
- **方法:**请求类型,如GET或POST。
- **头部:**包含有关客户端和请求的其他信息,如User-Agent和Referer。
- **正文:**POST请求中包含的数据。
**响应**
服务器对请求的响应通常包含以下信息:
- **状态码:**表示请求是否成功,如200(成功)或404(未找到)。
- **头部:**包含有关服务器和响应的其他信息,如Content-Type和Content-Length。
- **正文:**爬取到的页面内容。
**处理**
网络爬虫会根据响应状态码决定如何处理响应:
- **200(成功):**解析响应正文,提取所需信息。
- **404(未找到):**记录错误,并从爬取队列中删除该URL。
- **其他状态码:**根据具体情况处理,如重试或跳过该URL。
**代码示例**
以下Python代码演示了如何发送HTTP请求并处理响应:
```python
import requests
# 发送GET请求
response = requests.get("https://example.com")
# 检查状态码
if response.status_code == 200:
# 解析响应内容
html = response.text
# 提取所需信息
title = html.find("title").text
print(title)
else:
# 处理错误
print("Error:", response.status_code)
```
**逻辑分析**
该代码首先发送一个GET请求到指定的URL。如果请求成功(状态码为200),则解析响应内容并提取标题信息。否则,打印错误消息。
# 3.1 网络爬虫的网页解析
#### 3.1.1 HTML和XML解析库
**HTML解析库**
- **BeautifulSoup:**最流行的HTML解析库,提供丰富的解析和操作功能,支持多种解析器(如lxml、html5lib)。
- **lxml:**基于libxml2库,解析速度快,支持XPath和CSS选择器。
- **html5lib:**严格遵循HTML5标准,解析准确度高,但速度较慢。
**XML解析库**
- **xml.etree.ElementTree:**Python标准库提供的XML解析库,简单易用,支持XPath和DOM操作。
- **lxml.etree:**基于libxml2库,解析速度快,支持多种XML格式。
- **defusedxml:**安全增强型XML解析库,防止XML外部实体注入攻击。
**选择解析库的依据**
- **性能:**lxml和html5lib解析速度较快,而BeautifulSoup速度较慢。
- **准确度:**html5lib解析准确度最高,其次是lxml。
- **功能:**BeautifulSoup提供最丰富的功能,lxml支持XPath和CSS选择器。
#### 3.1.2 正则表达式在网页解析中的应用
正则表达式是一种强大的模式匹配语言,可用于从网页中提取特定信息。
**正则表达式语法**
- **字符类:**[]匹配指定字符范围,[^]匹配范围外的字符。
- **量词:**{n}匹配n次,{n,}匹配n次或更多,{n,m}匹配n到m次。
- **分组:**()将正则表达式分组,可用于提取子字符串。
- **转义字符:**\转义特殊字符,如\d匹配数字。
**正则表达式应用示例**
```python
import re
# 提取网页中的所有超链接
links = re.findall(r'<a href="([^"]+)">', html)
# 提取网页中的所有电子邮件地址
emails = re.findall(r'[\w\.-]+@[\w\.-]+', html)
```
**正则表达式注意事项**
- 正则表达式语法复杂,需要熟练掌握。
- 正则表达式匹配效率较低,应尽量避免使用复杂正则表达式。
- 正则表达式可能存在安全隐患,如注入攻击。
# 4. 网络爬虫进阶应用
### 4.1 网络爬虫的并发和分布式
#### 4.1.1 并发爬虫的实现和优化
并发爬虫通过同时处理多个请求来提高爬虫效率。它可以利用多线程或多进程技术来实现。
**多线程并发爬虫**
```python
import threading
import requests
def fetch_url(url):
response = requests.get(url)
return response
def main():
urls = ['url1', 'url2', 'url3']
threads = []
for url in urls:
thread = threading.Thread(target=fetch_url, args=(url,))
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == '__main__':
main()
```
**多进程并发爬虫**
```python
import multiprocessing
import requests
def fetch_url(url):
response = requests.get(url)
return response
def main():
urls = ['url1', 'url2', 'url3']
processes = []
for url in urls:
process = multiprocessing.Process(target=fetch_url, args=(url,))
processes.append(process)
for process in processes:
process.start()
for process in processes:
process.join()
if __name__ == '__main__':
main()
```
**并发爬虫优化**
* **控制并发数量:**过多的并发请求可能会导致服务器超载,因此需要控制并发数量。
* **使用队列:**使用队列来管理待爬取的URL,避免重复爬取。
* **使用代理:**使用代理来避免IP被封禁。
#### 4.1.2 分布式爬虫的架构和设计
分布式爬虫将爬虫任务分配给多个分布式节点,提高爬虫效率和可扩展性。
**分布式爬虫架构**
**分布式爬虫设计**
* **任务调度:**将爬虫任务分配给不同的节点。
* **数据存储:**将爬取的数据存储在分布式存储系统中。
* **节点通信:**使用消息队列或RPC机制进行节点间通信。
### 4.2 网络爬虫的反爬虫策略
#### 4.2.1 常见的反爬虫技术
反爬虫技术旨在阻止爬虫访问网站,常见技术包括:
* **IP封禁:**封禁来自爬虫IP的请求。
* **验证码:**要求用户输入验证码才能访问网站。
* **UserAgent检测:**检测爬虫的UserAgent并拒绝访问。
* **爬虫陷阱:**设置只有爬虫才会触发的链接或内容。
#### 4.2.2 反反爬虫策略和实践
反反爬虫策略旨在绕过反爬虫技术,常见策略包括:
* **使用代理:**使用代理来隐藏爬虫IP。
* **修改UserAgent:**修改爬虫UserAgent以伪装成浏览器。
* **绕过验证码:**使用OCR技术或机器学习来破解验证码。
* **识别爬虫陷阱:**分析网站结构和行为模式,识别并避免爬虫陷阱。
# 5. Python字符串字母个数统计与网络爬虫结合应用
### 5.1 从网络中提取字符串
在网络爬虫应用中,我们可以利用爬虫从网络中提取字符串。以下是一个示例代码,展示如何使用BeautifulSoup库从网页中提取所有文本:
```python
import requests
from bs4 import BeautifulSoup
# 请求网页
url = "https://www.example.com"
response = requests.get(url)
# 解析网页
soup = BeautifulSoup(response.text, "html.parser")
# 提取所有文本
text = soup.get_text()
```
### 5.2 对提取的字符串进行字母个数统计
提取字符串后,我们可以使用Python内置的`collections.Counter`类统计字母个数。以下是一个示例代码:
```python
from collections import Counter
# 统计字母个数
letter_counts = Counter(text)
# 输出字母个数
for letter, count in letter_counts.items():
print(f"{letter}: {count}")
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中统计字符串中字母个数的各种技巧和方法。从基础概念到高级应用,再到性能优化和常见问题解析,本专栏全面涵盖了字符串处理计数的方方面面。
专栏还探索了字符串字母个数统计与其他领域的交叉应用,例如正则表达式、数据结构、自然语言处理、图像处理、网络爬虫、大数据分析、云计算、移动开发、游戏开发、金融科技和医疗保健。通过这些示例,读者可以了解如何在实际开发中有效利用字符串字母个数统计技术。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
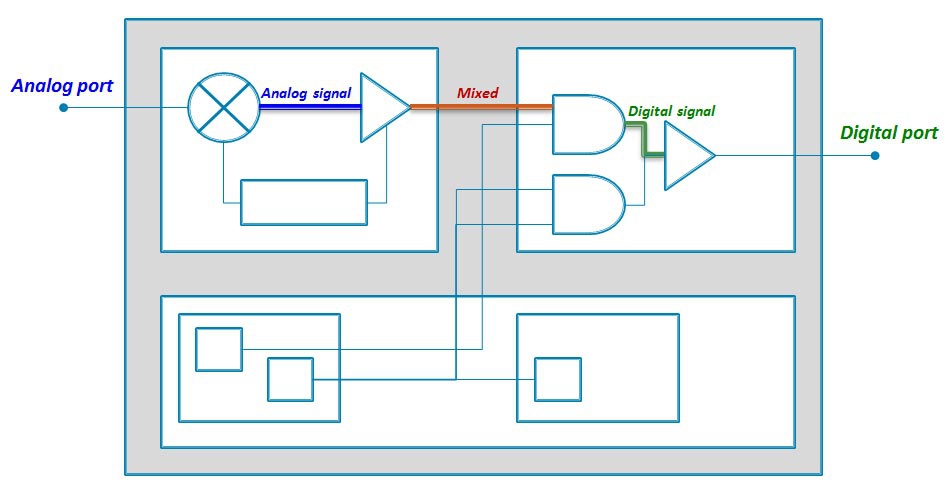
揭秘雷达信号处理:从脉冲到频谱的魔法转换
# 摘要
本文对雷达信号处理技术进行了全面概述,从基础理论到实际应用,再到高级实践及未来展望进行了深入探讨。首先介绍了雷达信号的基本概念、脉冲编码以及时间域分析,然后深入研究了频谱分析在雷达信号处理中的基础理论、实际应用和高级技术。在高级实践方面,本文探讨了雷达信号的采集、预处理、数字化处理以及模拟与仿真的相关技术。最后,文章展望了人工智能、新兴技术对雷达信号处理带来的影响,以及雷达系统未来的发展趋势。本论文旨在为雷
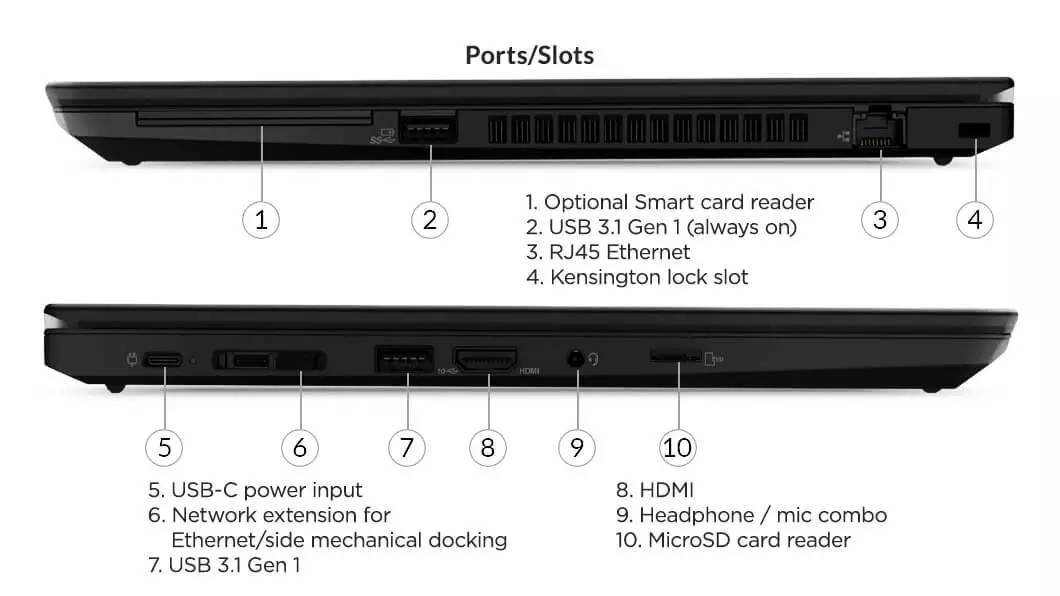
【ThinkPad T480s电路原理图深度解读】:成为硬件维修专家的必备指南
# 摘要
本文对ThinkPad T480s的硬件组成和维修技术进行了全面的分析和介绍。首先,概述了ThinkPad T480s的硬件结构,重点讲解了电路原理图的重要性及其在硬件维修中的应用。随后,详细探讨了电源系统的工作原理,主板电路的逻辑构成,以及显示系统硬件的组成和故障诊断。文章最后针对高级维修技术与工具的应用进行了深入讨论,包括
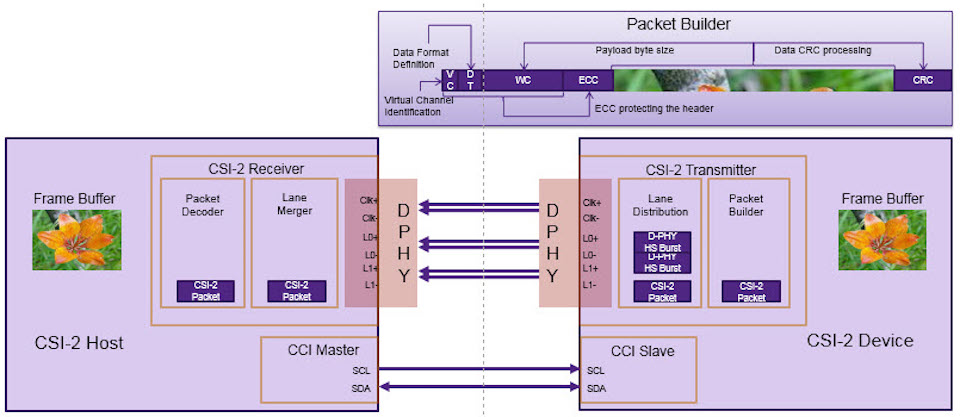
【移动行业处理器接口核心攻略】:MIPI协议全景透视
# 摘要
本文详细介绍了移动行业处理器接口(MIPI)协议的核心价值和技术原理,强调了其在移动设备中应用的重要性和优势。通过对MIPI协议标准架构、技术特点以及兼容性与演进的深入分析,本文展示了MIPI在相机、显示技术以及无线通信等方面的实用性和技术进步。此外,本文还探讨了MIPI协议的测试与调试方法,以及在智能穿戴设备、虚拟现实和增强
【编译器调优攻略】:深入了解STM32工程的编译优化技巧

# 摘要
本文深入探讨了STM32工程优化的各个方面,从编译器调优的理论基础到具体的编译器优化选项,再到STM32平台的特定优化。首先概述了编译器调优和STM32工程优化的理论基础,然后深入到代码层面的优化策略,包括高效编程实践、数据存取优化和预处理器的巧妙使用。接着,文章分析了编译器优化选项的重要性,包括编译器级别和链接器选项的影响,以及如何在构建系统中集成这些优化。最后,文章详
29500-2标准成功案例:组织合规性实践剖析

# 摘要
本文全面阐述了29500-2标准的内涵、合规性概念及其在组织内部策略构建中的应用。文章首先介绍了29500-2标准的框架和实施原则,随后探讨了
S7-1200_S7-1500故障排除宝典:维护与常见问题的解决方案

# 摘要
本文综述了S7-1200/S7-1500 PLC的基础知识和故障诊断技术。首先介绍PLC的硬件结构和功能,重点在于控制器核心组件以及I/O模块和接口类型。接着分析电源和接地问题,探讨其故障原因及解决方案。本文详细讨论了连接与接线故障的诊断方法和常见错误。在软件故障诊断方面,强调了程序错误排查、系统与网络故障处理以及数
无人机精准控制:ICM-42607在定位与姿态调整中的应用指南
# 摘要
无人机精准控制对于飞行安全与任务执行至关重要,但面临诸多挑战。本文首先分析了ICM-42607传感器的技术特点,探讨了其在无人机控制系统中的集成与通信协议。随后,本文深入阐述了定位与姿态调整的理论基础,包括无人机定位技术原理和姿态估计算法。在此基础上,文章详细讨论了ICM-42607在无人机定位与姿态调整中的实际应用,并通
易语言与FPDF库:错误处理与异常管理的黄金法则

# 摘要
易语言作为一门简化的编程语言,其与FPDF库结合使用时,错误处理变得尤为重要。本文旨在深入探讨易语言与FPDF库的错误处理机制,从基础知识、理论与实践,到高级技术、异常管理策略,再到实战演练与未来展望。文章详细介绍了错误和异常的概念、重要性及处理方法,并结合FPDF库的特点,讨论了设计时与运行时的错误类型、自定义与集成第三方的异常处理工具,以及面向对象中的错误处理。此外,本文还强
Linux下EtherCAT主站igh程序同步机制:实现与优化指南
# 摘要
本文首先概述了EtherCAT技术及其同步机制的基本概念,随后详细介绍了在Linux环境下开发EtherCAT主站程序的基础知识,包括协议栈架构和同步机制的角色,以及Linux环境下的实时性强化和软件工具链安装。在此基础上,探讨了同步机制在实际应用中的实现、同步误差的控制与测量,以及同步优化策略。此外,本文还讨论了多任务同步的高级应用、基于时间戳的同步实现、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )