【PyTorch在PyCharm中的最佳实践】
发布时间: 2024-12-04 10:53:01 阅读量: 33 订阅数: 41 

参考资源链接:[Pycharm安装torch失败解决指南:处理WinError 126错误](https://wenku.csdn.net/doc/3g2nwwuq1m?spm=1055.2635.3001.10343)
# 1. PyTorch简介及其在PyCharm中的安装
## 1.1 PyTorch概述
PyTorch是一个开源的机器学习库,由Facebook的人工智能研究团队开发,它在深度学习领域提供了广泛的支持。PyTorch以其动态计算图(也称为定义即运行的方法)而闻名,这使得它在研究和实验中具有很大的灵活性。PyTorch使用Python编程语言,凭借其易用性和高效的计算性能,已经成为了AI研究与应用开发的首选工具之一。
## 1.2 PyTorch在PyCharm中的安装步骤
1. 打开PyCharm,进入`Settings`(或`Preferences`,取决于操作系统),选择`Project: [your_project_name]`下的`Project Interpreter`。
2. 点击右侧的齿轮图标,然后选择`Add`。
3. 在弹出的窗口中选择`PyTorch`,然后根据你的系统环境选择合适的`Package`选项。例如,如果你使用的是CUDA 10.2,那么你应该选择`PyTorch for CUDA 10.2`。
4. 点击`Install Package`开始安装。安装完成后,PyTorch会出现在`Project Interpreter`列表中,现在你就可以在PyCharm中开始使用PyTorch了。
### 示例代码块
安装PyTorch包时,确保选择符合你系统配置的正确版本,如下所示的代码块展示了如何通过Python的pip命令安装PyTorch:
```python
pip install torch torchvision torchaudio
```
在安装过程中,如果遇到任何问题,请参考PyTorch官方网站上针对你的操作系统的安装指南。
# 2. PyTorch基础理论与实践
## 2.1 张量操作和自动微分
### 2.1.1 张量的创建与操作
在深度学习中,张量是数据的基本单位,其操作和管理构成了模型计算的基础。PyTorch中,张量(Tensor)是类似于numpy的多维数组,但它们可以使用GPU进行加速计算。
```python
import torch
# 创建一个张量
tensor = torch.tensor([[1, 2], [3, 4]])
# 张量的形状
print(tensor.shape) # 输出: torch.Size([2, 2])
# 张量的数据类型
print(tensor.dtype) # 输出: torch.int64
# 张量的类型
print(type(tensor)) # 输出: <class 'torch.Tensor'>
```
上述代码创建了一个形状为2x2的整型张量,并展示了如何获取张量的形状、数据类型以及类型。PyTorch提供了广泛的函数和方法来创建张量,例如`torch.zeros()`、`torch.ones()`、`torch.arange()`、`torch.linspace()`等,满足不同场景下的需求。
张量操作是深度学习的核心,包括了张量的切片、扩展、重塑等:
```python
# 张量切片操作
slice_tensor = tensor[:, 1]
print(slice_tensor) # 输出: tensor([2, 4])
# 张量扩展操作
expanded_tensor = tensor.unsqueeze(0)
print(expanded_tensor.shape) # 输出: torch.Size([1, 2, 2])
# 张量重塑操作
reshaped_tensor = tensor.view(4)
print(reshaped_tensor) # 输出: tensor([1, 2, 3, 4])
```
在上述代码中,我们对一个2x2的张量进行了切片、扩展和重塑操作。切片操作选取了第二列的元素,扩展操作增加了一个维度,重塑操作将张量变为了一个长度为4的一维张量。
张量的算术运算也非常关键,包括点积、矩阵乘法、逐元素操作等:
```python
# 矩阵乘法
matrix = torch.randn(2, 3)
product = tensor @ matrix
print(product.shape) # 输出: torch.Size([2, 3])
# 逐元素加法
addition = tensor + 1
print(addition) # 输出: tensor([[2, 3], [4, 5]])
```
这些张量操作为实现深度学习模型提供了强大的工具,是PyTorch实践的基础。
### 2.1.2 自动微分机制
自动微分是深度学习框架的核心特性之一,它使得从算法设计到实际实现变得简洁高效。PyTorch的自动微分机制通过计算图(computational graph)来实现。计算图是一种数据结构,用于表达和存储可微分的计算过程。
PyTorch中的`torch.autograd`模块提供了一个自动微分引擎,为每个计算创建了一个图。这个引擎的核心是`Variable`对象,它是张量的封装,能够跟踪计算历史并支持梯度的自动计算。
```python
# 张量和Variable的创建
x = torch.tensor(1.0, requires_grad=True)
y = torch.tensor(2.0, requires_grad=True)
# 计算操作
z = x * y
# 计算z关于x的梯度
z.backward()
print(x.grad) # 输出: tensor(2.)
```
上述代码中,我们创建了两个需要梯度的张量`x`和`y`,并执行了它们的乘积操作。然后,调用`backward()`方法自动计算了z关于x的梯度,并存储在`x.grad`中。这个简单的例子展示了自动微分的基本使用方式。
在实际应用中,计算图可以非常复杂,包含多层的节点和边。PyTorch能够处理这些复杂的图,并在调用`backward()`时自动执行链式法则计算梯度。这种能力极大地简化了深度学习模型的训练过程,尤其是对于复杂的神经网络结构。
```mermaid
graph LR
A[x] -->|*| B[y]
B -->|*| C[z]
C -->|backward()| D[x.grad]
```
这个mermaid流程图展示了张量`x`、`y`相乘得到`z`,以及如何通过`backward()`方法反向传播计算出`x`的梯度。
自动微分不仅适用于简单的线性操作,它能够支持各种复杂操作,包括条件语句和循环,因此在构建复杂的神经网络时非常有用。
## 2.2 深度学习基础模型
### 2.2.1 线性回归模型
线性回归是最简单的回归模型之一,其目标是根据一个或多个自变量来预测因变量的值。在深度学习中,线性回归可以通过一个简单的神经网络来实现,该网络只有一个输入层、一个线性层和一个输出层。
```python
import torch
from torch import nn
# 输入特征和目标值
x = torch.randn(5, 1)
y = 2 * x + 1 + torch.randn(5, 1)
# 线性回归模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 实例化模型、定义损失函数和优化器
model = LinearRegressionModel()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练过程
epochs = 100
for epoch in range(epochs):
# 前向传播
outputs = model(x)
loss = criterion(outputs, y)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
```
在此代码中,首先定义了一个线性回归模型,它包含一个线性层`nn.Linear(1, 1)`,表示模型只有一个输入特征和一个输出。接着,创建了一个均方误差损失函数`nn.MSELoss()`和一个随机梯度下降优化器`torch.optim.SGD()`。最后,通过训练循环,模型参数通过不断优化来最小化损失函数。
### 2.2.2 神经网络结构
构建神经网络需要使用多个层来处理输入数据。在PyTorch中,可以通过组合`torch.nn`模块中的层来创建复杂的网络结构。最常见的层包括全连接层(`Linear`)、卷积层(`Conv2d`)、循环层(`RNN`、`LSTM`、`GRU`)等。
```python
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.layer1 = nn.Linear(in_features=784, out_features=128)
self.relu = nn.ReLU()
self.layer2 = nn.Linear(in_features=128, out_features=10)
def forward(self, x):
x = x.view(-1, 784) # 将图片展开成一维向量
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
return x
```
在上面的例子中,我们构建了一个简单的多层感知器模型,它包含一个输入层、一个128个神经元的隐藏层和一个10个神经元的输出层。输入层将图像数据展平为一维向量,第一个隐藏层通过`nn.Linear`定义,然后使用`nn.ReLU`作为激活函数。最终,我们得到一个输出层,其输出大小为10,适用于识别10类图像。
通过这种模块化的设计,可以轻松构建出任意复杂的神经网络结构。组合不同的层和激活函数,可以应对各种各样的机器学习任务。
## 2.3 训练过程和优化器
### 2.3.1 损失函数与优化算法
在训练深度学习模型的过程中,损失函数度量了模型预测值和真实值之间的差异。优化算法则是用来更新模型参数以减少损失的过程。选择合适的损失函数和优化算法对于训练效果至关重要。
#### 损失函数
损失函数通常是模型输出和真实标签之间的某种距离度量。对于分类任务,常见的损失函数包括交叉熵损失(`nn.CrossEntropyLoss`);对于回归任务,常见的损失函数包括均方误差损失(`nn.MSELoss`)。
```python
# 交叉熵损失
criterion = nn.CrossEntropyLoss()
# 均方误差损失
criterion = nn.MSELoss()
```
#### 优化算法
PyTorch提供了多种优化器实现,如随机梯度下降(`torch.optim.SGD`)、Adam(`torch.optim.Adam`)等。优化器的核心是更新规则,它决定了模型参数如何根据损失函数的梯度进行调整。
```python
# 随机梯度下降优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# Adam优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
```
在上述代码中,我们展示了如何实例化SGD优化器和Adam优化器,指定了学习率`lr`和其他可能的超参数,如动量`momentum`。
### 2.3.2 模型训练和验证技巧
模型训练过程中,需要对数据集进行迭代处理,通常使用小批量(mini-batch)来提高效率。在这个过程中,关键是要合理选择批量大小和迭代次数(即训练周期或epoch数)。此外,使用验证集来评估模型的泛化能力是非常重要的。
```python
# 将数据集分为训练集和验证集
train_dataset = ...
val_dataset = ...
# 加载数据集
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(dataset=val_dataset, batch_size=64, shuffle=False)
# 训练和验证循环
model.train()
for epoch in range(num_epochs):
for inputs, targets in train_loader:
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Toad for DB2解决方案:10个专业技巧助你成为数据库管理大师
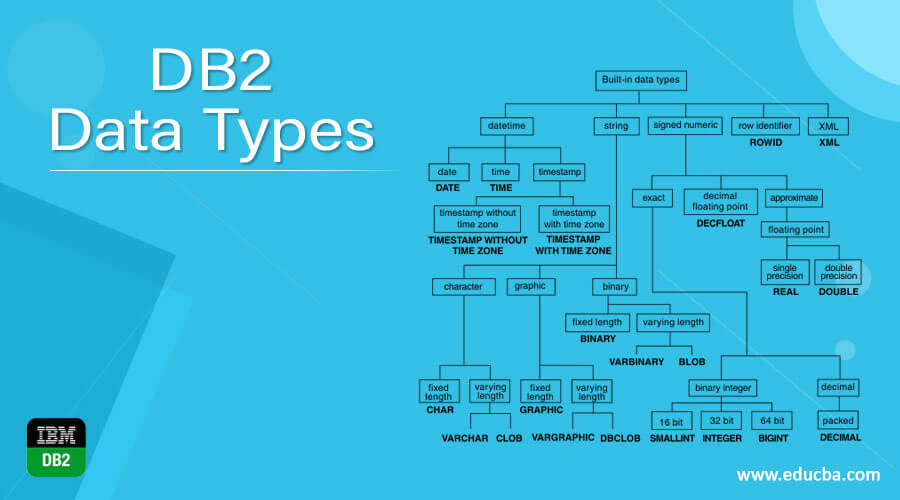
# 摘要
本文全面介绍了Toad for DB2这一强大的数据库管理工具,涵盖了从基础安装配置到高级查询优化、自动化管理以及故障诊断的全方位实践知识。文中详细解析了Toad for DB2的用户界面和工具,数据库对象和安全管理的细节,还包括了SQL编程、性能监控与调优的高级技巧。此外,本文还探讨了如何创建和管理自动化任务,进行脚本调试与错误处理,以及批量数据操作与变更管理。最后,分享了Toa
CAA3D标注技术深度剖析:原理、应用与实战演练
# 摘要
CAA3D标注技术作为一种先进的三维标注方法,正逐渐应用于包括工业设计、虚拟现实和医疗健康等多个领域。本文首先概述了CAA3D标注技术的基本概念及其理论基础,然后详细探讨了其在不同领域的具体应用,如3D模型构建、逆向工程、VR/AR内容开发、医学图像标注等。文章还通过实战演练的方式,介绍了标注
Nginx错误日志分析技巧:快速定位并解决启动失败的秘诀

# 摘要
Nginx作为高性能的HTTP和反向代理服务器,其错误日志是监控、诊断和优化服务器性能的关键资源。本文第一章概述了Nginx错误日志的重要性及其作用。第二章深入解析了错误日志的结构和内容,包括日志级别、时间戳、常见错误类型,以及关键的HTTP状态码和错误代码。第三章讨论
宇龙V4.8数控仿真软件与实际加工对比分析:为什么它是行业的选择?

# 摘要
本文对宇龙V4.8数控仿真软件进行了全面的概述和分析。首先介绍了数控加工的基础理论,包括数控机床工作原理、核心技术及其精度和质量控制。接着深入探讨了宇龙V4.8的理论基础,其中包括仿真工作机制、在数控教学中的应用及优化发展趋势。之后,通过对比分析,探讨了宇龙V4.8与实际数控加工的仿真准确性、安全性和操作便捷性,以及成本效益。文章还通过行业
【TongWeb V8.0新手必备】:7步打造快速响应的Web应用

# 摘要
本文旨在详细介绍TongWeb V8.0的部署、性能优化以及高级功能应用。首先对TongWeb V8.0的基础架构和快速搭建Web应用环境的步骤进行了全面介绍,包括系统兼容性、软件安装、以及安装配置过程。接着,文章深入探讨了Web应用性能优化技巧,涵盖代码优化、资源压缩
【Mann-Whitney Test实战高手】:独立样本分析的终极指南
# 摘要
Mann-Whitney测试是一种非参数统计方法,用于比较两个独立样本的中位数是否存在显著差异。本文首先介绍了Mann-Whitney测试的基本概念和理论基础,包括假设检验、独立样本的定义、测试工作原理及统计量的计算方法。接着,文章详细阐述了Mann-Whitney测试的实践步骤,包括数据的准备、使用不同统计软件进行测试,以及结果的解读和报告撰写。此外,文章还探讨了Mann-Whitney测试的高级应用,如多组比较、非参数效应量的计算以及缺失数据的处理策略。最后,通过案例分析,本文展示了Mann-Whitney测试在实际研究中的应用,并对研究结果进行了解释和讨论。
# 关键字
Ma
【蓝牙通信稳定性研究】:CH9141DS1在复杂环境下的性能揭秘
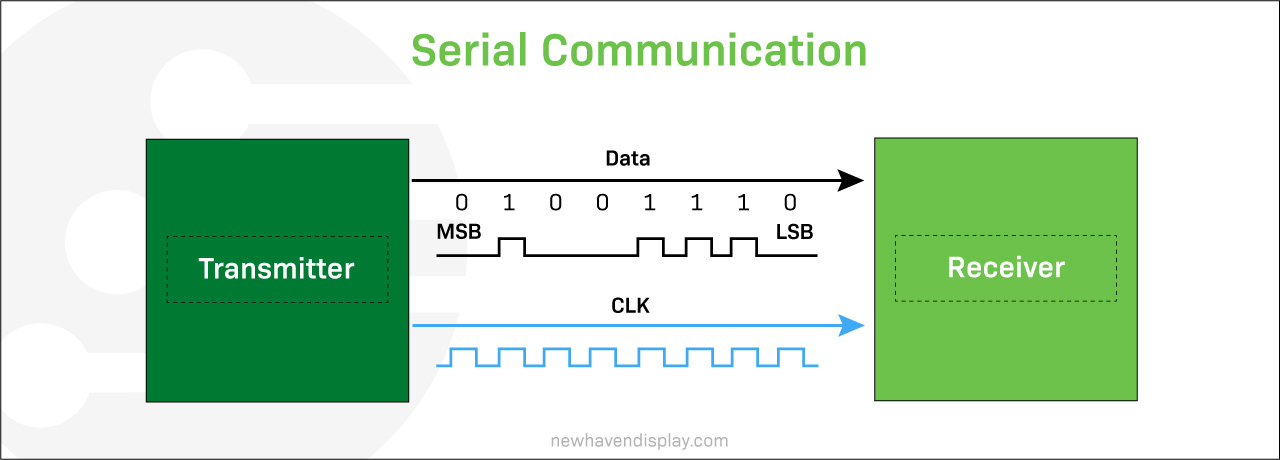
# 摘要
蓝牙通信作为一种无线技术,广泛应用于短距离数据传输中。本文首先概述了蓝牙技术及其标准,重点介绍了CH9141DS1芯片的特点与优势。随后,文章分析了复杂环境下蓝牙通信所面临的挑战,探讨了信号干扰、环境噪声等因素对通信稳定性的影响,并提出了保证连接稳定性和数据传输速率的关键要素。为了验证CH9141D
操作系统课程设计报告:揭秘操作系统设计的9个必备要素与实施细节

# 摘要
本文系统地介绍了操作系统的概念、组成和实践应用,并深入探讨了其安全设计与性能优化的关键技术。通过对系统内核、内存管理、文件系统、多任务处理、设备驱动以及安全机制的分析,本文阐述了操作系统的基本功能和设计要素。同时,针对操作系统安全性的各个方面,包括认证授权
单片机基础编程教程:掌握这5大技能,编程不再是难题

# 摘要
本论文全面介绍了单片机编程的各个方面,从基础硬件和编程语言的概述到高级应用和项目实战技巧的提升。首先,概述了单片机编程的重要性及其硬件基础,包括CPU、存储器、输入/输出端口、外围设备等关键组成部分。接着,深入探讨了汇编语言和C语言在单片机编程中的应用,以及集成开发环境(IDE)和编译烧录工具等编程环境和工具的使用。在实践技巧方面,详细说
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )