Django ORM调试技巧:深入分析django.db.models.sql.query执行过程,解决常见问题
发布时间: 2024-10-16 14:40:50 阅读量: 31 订阅数: 29 

使用python进行一个猜数字游戏
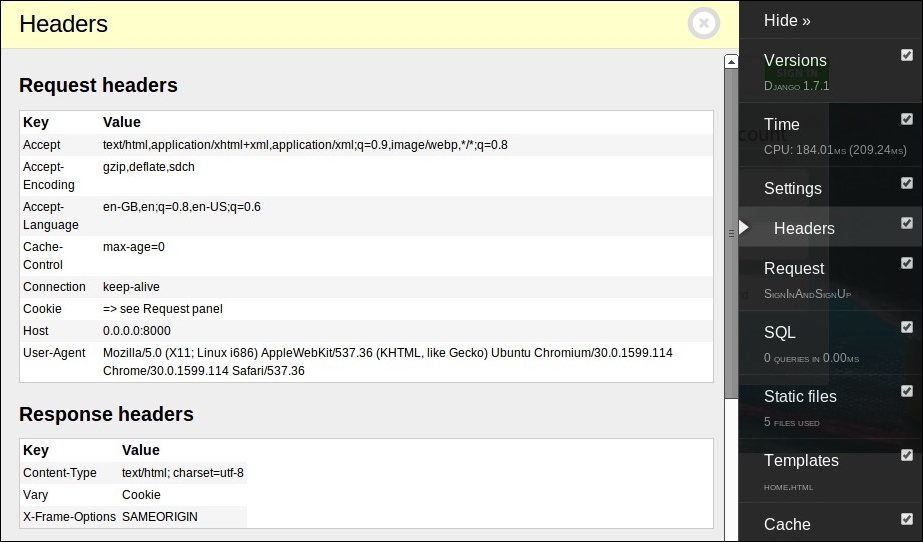
# 1. Django ORM和SQL查询基础
## 1.1 Django ORM简介
Django ORM是Django框架中一个强大的组件,它提供了一种将Python代码映射到数据库操作的方式,无需编写原始SQL代码。通过模型(Models)和查询集(QuerySets),开发者可以实现数据的创建、检索、更新和删除操作。
### 1.1.1 模型与数据库表映射
在Django ORM中,每个模型类对应数据库中的一个表。例如,定义一个简单的博客文章模型:
```python
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
```
这将自动在数据库中创建一个名为`posts_post`的表,其中包含`title`和`content`字段。
### 1.1.2 查询集基础
查询集(QuerySet)是Django ORM中的核心概念,用于从数据库检索记录。例如,获取所有博客文章:
```python
all_posts = Post.objects.all()
```
### 1.1.3 过滤和排序
查询集允许过滤(filtering)和排序(ordering)数据。例如,筛选标题包含"教程"的文章,并按创建时间降序排序:
```python
tutorial_posts = Post.objects.filter(title__contains='教程').order_by('-created_at')
```
通过这些简单的例子,我们可以看到Django ORM如何简化数据库操作,使得开发者能够更专注于业务逻辑的实现。接下来,我们将深入探讨Django ORM如何与SQL查询交互,以及如何构建和优化这些查询。
# 2. 深入理解django.db.models.sql.query
在本章节中,我们将深入探讨 Django ORM 的核心组件 `django.db.models.sql.query`。这个模块负责将 ORM 的高级抽象转换为具体的 SQL 查询,并执行数据库操作。我们将分三个主要部分来讨论:组件解析、优化策略以及实例分析。
## 2.1 django.db.models.sql.query的组件解析
### 2.1.1 Query对象的创建和初始化
`Query` 对象是 Django ORM 的核心之一,它在模型层面上提供了对数据库的操作接口。创建 `Query` 对象通常发生在模型的 Manager 方法中,如 `Model.objects.all()`。这个过程中,Django 会根据模型的元数据(Meta类中的信息)来构建一个初始的 `Query` 对象。
```python
from django.db.models.query import Query
from myapp.models import MyModel
query = Query(MyModel, using='default')
```
在上述代码中,我们手动创建了一个 `Query` 对象。实际上,这个过程是由 Django 的 `ModelManager` 自动完成的。`Query` 对象包含了所有构建 SQL 查询所需的信息,包括表名、字段信息、关联信息等。
### 2.1.2 SQL表达式的构建过程
在 `Query` 对象中,SQL 表达式是通过一个转换过程来构建的。当调用 `QuerySet` 的方法如 `filter()`、`order_by()` 等时,Django 会逐步构建一个树状的表达式结构。这个结构最终会被转换成一个可以执行的 SQL 查询。
```python
query = MyModel.objects.filter(name='John')
```
这个例子中,`filter()` 方法会向 `Query` 对象添加一个过滤条件。在内部,这个方法会创建一个 `Q` 对象,代表 SQL 中的 WHERE 子句。
### 2.1.3 查询执行器(QueryExecutor)的作用
`QueryExecutor` 是 `django.db.models.sql.query` 中的一个内部组件,负责将构建好的 SQL 表达式转换为实际的数据库查询并执行。它使用数据库的后端 API 来编译 SQL 语句,并执行查询。
```***
***piler import SQLCompiler
from django.db import connection
compiler = SQLCompiler(query, connection)
sql, params = compiler.as_sql()
cursor = connection.cursor()
cursor.execute(sql, params)
```
在上述代码中,我们手动执行了编译和查询过程。`SQLCompiler` 将 `Query` 对象编译成 SQL 语句,然后使用数据库连接执行这个语句。
## 2.2 django.db.models.sql.query的优化策略
### 2.2.1 查询缓存机制
Django ORM 提供了一种查询缓存机制,可以避免重复执行相同的查询。这种机制在 `QuerySet` 的 `get()` 和 `iterator()` 方法中表现得尤为明显。
```python
from django.db.models.cache import get_cache
# 获取缓存对象
cache = get_cache('default')
query = MyModel.objects.filter(name='John')
query._result_cache = cache.get(query)
if query._result_cache is None:
results = list(query)
cache.set(query, results)
else:
results = query._result_cache
```
在上述代码中,我们手动实现了查询缓存逻辑。实际上,Django 在执行 `get()` 方法时会自动检查缓存。
### 2.2.2 SQL语句的优化技巧
SQL 语句的优化通常涉及减少不必要的表连接、选择更有效的查询条件和优化排序操作。Django 提供了一些工具和技巧来帮助开发者写出更高效的查询。
```python
# 使用 select_related() 来优化外键查询
related_query = MyModel.objects.select_related('related_model').filter(name='John')
# 使用 defer() 来排除不需要的字段,减少数据传输量
deferred_query = MyModel.objects.defer('field1', 'field2').filter(name='John')
```
在上述代码中,`select_related()` 和 `defer()` 分别用于优化外键查询和减少不必要的字段传输。
### 2.2.3 数据库索引在ORM中的应用
数据库索引可以显著提高查询效率,特别是在涉及大量数据和复杂查询条件的情况下。Django ORM 允许开发者通过 `db_index=True` 参数在模型字段上创建索引。
```python
class MyModel(models.Model):
name = models.CharField(max_length=100, db_index=True)
```
在上述代码中,我们在 `name` 字段上创建了一个数据库索引。Django 会在数据库迁移时自动处理索引的创建。
## 2.3 实例分析django.db.models.sql.query的工作流程
### 2.3.1 从Django ORM到SQL查询的转换过程
从 Django ORM 到 SQL 查询的转换是一个涉及多个组件和步骤的复杂过程。我们可以通过一个简单的例子来分析这个过程。
```python
query = MyModel.objects.filter(name='John').order_by('-id')
```
当执行上述查询时,Django 会逐步构建内部的 `Query` 对象,然后将其编译成 SQL 语句。这个过程涉及 `Query` 对象的创建、过滤条件的添加、排序指令的处理等步骤。
### 2.3.2 查询优化器如何介入
Django 的查询优化器会尝试优化查询树,以减少需要执行的数据库操作。这个过程通常是自动的,开发者可以通过自定义 SQL 来手动优化。
```***
***piler import SQLCompiler
# 获取优化后的查询树
query.get优化后的查询树()
# 手动编译和执行 SQL
compiler = SQLCompiler(query, connection)
sql, params = compiler.as_sql()
cursor.execute(sql, params)
```
在上述代码中,我们手动获取了优化后的查询树,并编译执行了 SQL。在实际使用中,Django 会自动处理这些步骤。
### 2.3.3 真实世界的查询案例分析
在本节中,我们将通过一个真实的查询案例来分析 Django ORM 的工作流程。假设我们有一个电商平台,需要查询某个用户最近的订单。
```python
class Order(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE)
total = models.DecimalField(max_digits=10, decimal_places=2)
created_at = models.DateTimeField(auto_now_add=True)
# 查询代码
user = User.objects.get(username='john_doe')
orders = Order.objects.filter(user=user).order_by('-created_at')[:10]
```
在这个例子中,我们首先查询了用户 `john_doe`,然后根据关联的 `Order` 模型获取了最近的 10 个订单。这个查询涉及到了外键过滤和排序操作,Django ORM 会将其转换为高效的 SQL 查询。
```sql
SELECT "order"."id", "order"."user_id", "order"."total", "order"."created_at"
FROM "order"
WHERE "order"."user_id" = 1
ORDER BY "order"."created_at" DESC
LIMIT 10;
```
在上述 SQL 语句中,我们可以看到 Django ORM 如何将高级查询转换为具体的 SQL 语句。这个过程涉及到了多个组件和优化策略,是 Django ORM 强大的体现。
在本章节中,我们详细探讨了 `django.db.models.sql.query` 的内部工作机制,包括其组件解析、优化策略以及实际案例分析。通过这些深入的理解,开发者可以更好地编写高效和优化的数据库查询代码。
# 3. Django ORM调试技巧
在本章节中,我们将深入探讨Django ORM的调试技巧,这对于开发人员来说是一个非常实用的话题。调试技巧可以帮助我们更好地理解ORM的工作原理,以及如何有效地解决性能问题。我们将分为三个小节来讨论这个话题。
## 3.1 Django ORM日志记录
### 3.1.1 配置日志系统以跟踪ORM操作
在本小节中,我们将介绍如何配置Django的日志系统,以便跟踪ORM的操作。首先,我们需要在Django的设置文件`settings.py`中定义日志配置。Django使用Python的内置日志模

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到我们的专栏,我们将深入探索 Django ORM 中强大的 `django.db.models.sql.query` 模块。本专栏将提供一系列实用技巧和深入教程,帮助你提升数据库操作效率、优化查询、自定义高级查询、自动化代码、调试问题、确保安全性、掌握最佳实践、了解内部调用、诊断错误、使用复杂查询、管理事务、优化缓存、扩展原生 SQL、利用钩子机制、测试代码、管理迁移以及跨数据库操作。通过学习这些内容,你将成为 Django ORM 的熟练使用者,能够自信地处理各种数据库操作任务,并提升你的开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
1stOpt 5.0制造业优化策略:中文手册中的解决方案详解

参考资源链接:[1stOpt 5.0中文使用手册:全面解析与功能指南](https://wenku.csdn.net/doc/n57wf9bj9d?spm=1055.2635.3001.10343)
# 1. 1stOpt 5.0概述与优化基础
## 1.1 1stOpt 5.0的简介
1stOpt是一个先进的通用优化软件,由美国1stOpt LLC公司开发。它能解决各种复
Thermo-calc中文版:预测材料热膨胀行为的精确科学

参考资源链接:[Thermo-Calc中文用户指南:入门与精通](https://wenku.csdn.net/doc/5hpcx03vej?spm=1055.2635.3001.10343)
# 1. Thermo-calc中文版概述
Thermo-calc中文版作为材料科学领域内的重要工具,其核心功能是帮助
DATALOGIC M120扫描枪固件更新指南:确保设备安全与性能的秘诀
参考资源链接:[DATALOGIC得利捷M120扫描枪配置说明V0.2版本20201105.doc](https://wenku.csdn.net/doc/6401acf0cce7214c316edb26?spm=1055.2635.3001.10343)
# 1. DATALOGIC M120扫描枪概述
DATALOGIC M120扫描枪是市场上广泛认可的一款高效、可靠的扫描设备,专为需要高精度数据捕获的应用场景设计。它采用了先进的扫描技术,能够快速识别各种类型的条码,包括1D、2D条码和直接部件标记(DPM)。DATALOGIC M120不仅具备出色的扫描能力,还因其坚固耐用的设计而在各
【代码变更识别术】:深入Source Insight代码比对功能,高效管理代码版本
参考资源链接:[Source Insight 4护眼模式:黑色主题配置](https://wenku.csdn.net/doc/zhzh1hoepv?spm=1055.2635.3001.10343)
# 1. 版本管理与代码比对概述
在现代软件开发中,版本控制与代码比对是确保
DW1000移动应用管理指南:远程控制与管理的利器
参考资源链接:[DW1000用户手册中文版:配置、编程详解](https://wenku.csdn.net/doc/6412b745be7fbd1778d49b3b?spm=1055.2635.3001.10343)
# 1. DW1000移动应用管理概述
## 1.1 DW1000移动应用管理的重要性
在现代企业环境中,移动应用已成为连接用户、服务和数据的
【故障排除】:IntelliJ IDEA中配置Tomcat服务器的常见坑,避免这些坑,让你的开发更加顺滑
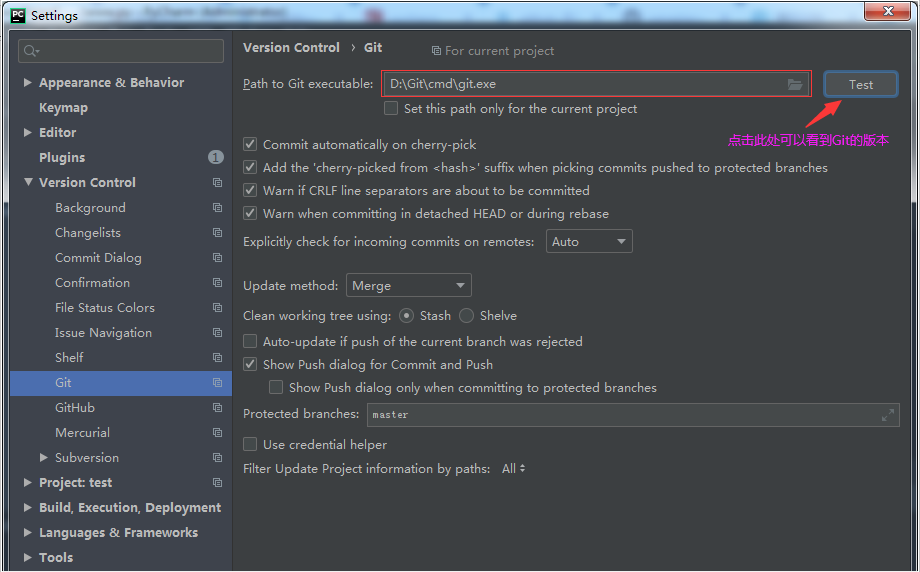
参考资源链接:[IntelliJ IDEA中Tomcat配置未找到问题详解与解决步骤](https://wenku.csdn.net/doc/3y6cdcjogy?spm=1055.2635.3001.10343)
# 1. IntelliJ IDEA与
【ANSYS AUTODYN案例研究】:复杂结构动态响应的剖析

参考资源链接:[ANSYS AUTODYN二次开发实战指南](https://wenku.csdn.net/doc/6412b713be7fbd1778d49019?spm=1055
呼叫记录分析:FreePBX通讯流程优化指南

参考资源链接:[FreePBX中文安装与设置指南](https://wenku.csdn.net/doc/uos8ozn9rh?spm=1055.2635.3001.10343)
# 1. FreePBX呼叫记录分析基础
## 1.1 呼叫记录分析的重要性
呼叫记录分析对于维护和优化企业通信系统是至关重要的。通过细致
KUKA系统软件变量表的数据校验与清洗:确保数据准确性与完整性
参考资源链接:[KUKA机器人系统变量表(8.1-8.4版本):官方详细指南](https://wenku.csdn.net/doc/6412b488be7fbd1778d3fe83?spm=1055.2635.3001.10343)
# 1. KUKA系统
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )