【数据并行与任务并行】:深入GPGPU编程模型的精髓
发布时间: 2024-12-17 02:37:55 阅读量: 3 订阅数: 2 

通用图形处理器设计GPGPU编程模型与架构原理.pptx

参考资源链接:[GPGPU编程模型与架构解析:CUDA、OpenCL及应用](https://wenku.csdn.net/doc/5pe6wpvw55?spm=1055.2635.3001.10343)
# 1. 数据并行与任务并行的基本概念
## 1.1 数据并行基础
数据并行指的是将数据集分割成多个子集,然后在多个处理单元上同时执行相同的操作。这种方式特别适合于可扩展性强的计算任务,例如大规模矩阵运算、图像渲染或数据挖掘。理解数据并行对于优化现代多核处理器和图形处理器(GPU)的性能至关重要。
## 1.2 任务并行基础
任务并行是将不同的计算任务分配给多个处理器同时执行,每个处理器执行不同的操作。这种并行模式允许我们处理具有复杂依赖关系的任务,或者那些相互独立的任务,可以显著减少程序的总执行时间。在实现任务并行时,合理地设计任务的划分和同步机制是关键。
## 1.3 数据并行与任务并行的比较
虽然数据并行和任务并行都可以用来提升程序的性能,但它们在实现方式和适用场景上存在差异。数据并行强调的是“数据”级别的并行,适合于批量处理相同计算任务的场景。而任务并行更多关注的是“任务”级别的并行,适用于处理相互独立或有不同计算路径的任务。理解并合理运用这两种并行方式,是高效并行编程的基础。
# 2. GPGPU编程模型详解
## 2.1 GPGPU的架构和工作原理
### 2.1.1 GPU架构的组成
GPU,即图形处理器,最初被设计用来加速计算机图形渲染,其架构优化了图形操作的并行计算能力。现代的GPU架构由多个关键组件构成,包括:
- Streaming Multiprocessors (SMs):负责执行并行任务的处理单元,能够同时处理多个线程。
- CUDA Cores:每个SM包含多个CUDA核心,每个核心都能执行简单的算术逻辑运算。
- Shared Memory:位于每个SM内部,用来在同一个线程块中的线程间进行数据共享。
- Global Memory:大容量的内存空间,可供所有SM访问,但访问延迟高。
- Constant Memory:专门用于存储不变数据,对于所有线程可见,访问速度较快。
- Texture Memory:用于优化2D数据访问的内存,具有缓存特性。
为了更好地理解GPU的架构,下面展示了一个简化的GPU内存层次结构图:
```mermaid
graph LR
A[GPU Core] -->|访问| B[Shared Memory]
A -->|访问| C[Global Memory]
A -->|访问| D[Constant Memory]
A -->|访问| E[Texture Memory]
```
### 2.1.2 GPU与CPU的协同工作模式
在GPGPU编程模型中,GPU与CPU的协同工作模式是实现数据和任务并行的关键。CPU(Central Processing Unit)擅长处理复杂逻辑和串行任务,而GPU则负责数据密集型的并行计算。
在协同工作模式中,CPU首先负责初始化任务并调用GPU执行并行计算。CPU将数据和执行指令传递给GPU,GPU进行处理后,将结果返回给CPU。该过程可以概括为以下步骤:
1. **数据传输**:CPU将数据从系统内存复制到GPU的全局内存中。
2. **内核函数调用**:CPU通过API(如CUDA中的`cudaMalloc`, `cudaMemcpy`, `cudaLaunchKernel`)将任务指令发送到GPU执行。
3. **执行并行操作**:GPU并行处理数据,并将结果存储在全局内存中。
4. **数据回传**:处理完成后,GPU将结果数据传回CPU。
5. **结果处理**:CPU接收结果并进行后续的串行处理或输出。
## 2.2 数据并行的实现机制
### 2.2.1 核函数(Kernel)的定义和执行
在GPGPU编程中,核函数(Kernel)是指在GPU上并行执行的函数。核函数由CPU启动,并在GPU上由成千上万的线程并行执行。
定义一个核函数非常简单,只需在函数定义前加上`__global__`关键字。例如:
```c++
__global__ void add(int *a, int *b, int *c, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
```
在上述核函数中,`add`操作被分布在所有线程上执行,`threadIdx`、`blockIdx`和`blockDim`这些内置变量用于确定当前线程的索引。
### 2.2.2 内存管理与数据传输
在CUDA编程模型中,内存管理是高效利用GPU资源的关键。GPU提供了多种内存类型,例如全局内存、共享内存和常量内存。正确地使用这些内存类型,可以显著提升程序的性能。
全局内存是GPU中最大的内存区域,所有线程都可以访问。但由于其全局访问性质,访问速度通常较慢。共享内存则是位于每个SM中的小型高速内存区域,可供同一个线程块的所有线程访问,因此使用共享内存可以极大地减少内存访问延迟。
数据传输是GPU计算中不可或缺的步骤。在执行任何核函数之前,CPU需要将数据从系统内存传输到GPU的内存中。CUDA提供了一套API用于实现这一过程:
```c++
cudaMalloc((void**)&d_a, size);
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
```
上述代码演示了如何为GPU内存分配空间并复制数据。`cudaMalloc`负责分配内存,`cudaMemcpy`负责数据传输。
## 2.3 任务并行的实现机制
### 2.3.1 流(Stream)和事件(Event)的概念
在GPGPU编程中,流和事件是实现任务并行的两个重要概念。流是一种指定操作执行顺序的机制,允许开发者组织任务以并行或顺序的方式执行。事件则用于控制流之间的同步点。
流允许核函数在GPU上并发执行。每个核函数调用可以指定一个流参数,这样就可以在同一个GPU上同时处理多个任务。例如:
```c++
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
add<<<numBlocks, blockSize, 0, stream1>>>(a_d, b_d, c_d, N);
add<<<numBlocks, blockSize, 0, stream2>>>(d_d, e_d, f_d, N);
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
```
在上述代码中,两个`add`操作在不同的流中并发执行。
### 2.3.2 异步操作与任务调度
异步操作是任务并行中的另一个重要概念。GPU能够执行异步操作,意味着CPU可以继续执行后续任务,而不需要等待GPU完成当前任务。这大大提高了整个系统的效率。
异步操作主要通过流来实现。在CUDA中,可以使用`cudaMemcpyAsync`函数来实现异步内存复制,使用`cudaLaunchKernel`函数来异步启动核函数。
任务调度指的是在GPU资源有限的情况下,合理地安排任务执行顺序,以充分利用GPU的计算资源。例如,可以使用事件来确保某些任务在其他任务完成后才开始执行。
```c++
cudaEvent_t event1, event2;
cudaEventCreate(&event1);
cudaEventCreate(&event2);
cudaEventRecord(event1, stream1);
cudaStreamWaitEvent(stream2, event1, 0); // stream2等待stream1中的event1事件完成
cudaEventRecord(event2, stream2);
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
cudaEventDestroy(event1);
cudaEventDestroy(event2);
```
通过上述代码,我们可以让`stream2`中的任务在`stream1`中的任务完成后才开始执行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
逻辑设计的艺术精髓:数字设计原理与实践第四版全面解读
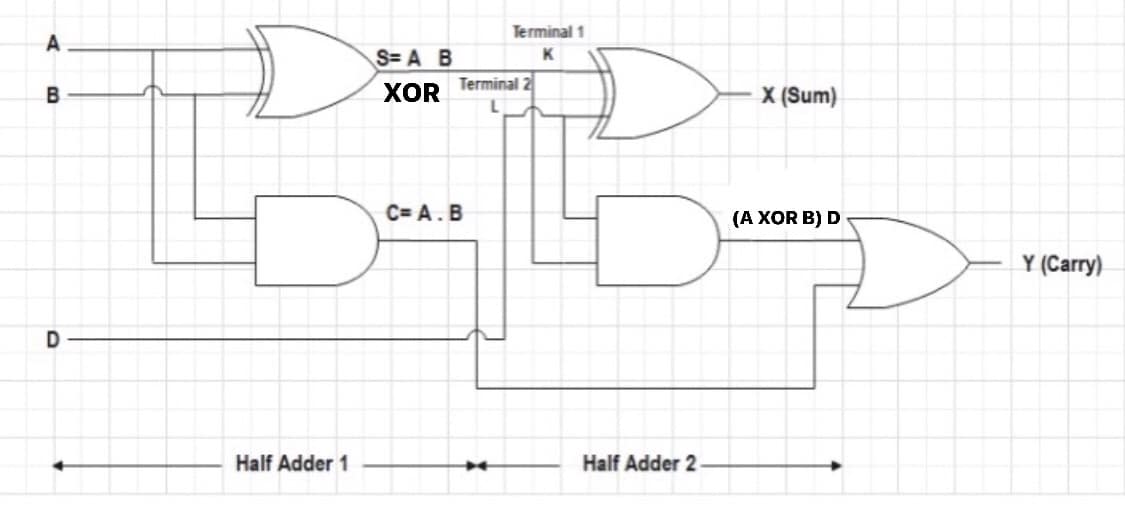
参考资源链接:[John F.Wakerly《数字设计原理与实践》第四版课后答案解析:逻辑图与数制转换](https://wenku.csdn.net/doc/1qxugirwra?spm=1055.2635.3001.10343)
# 1. 数字设计的基本概念与原理
## 理解数字系统设计
在数字设计领域,理解基本概念
TSPL2指令集入门指南:初学者必须掌握的8大基础知识与实践技巧

参考资源链接:[TSPL2指令集详解:TSC条码打印机编程指南](https://wenku.csdn.net/doc/5h3qbbyzq2?spm=1055.2635.3001.10343)
# 1. TSPL2指令集概述
## 1.1 简介与重要性
TSPL2指令集是针对特定硬件平台设计的一套指令集架构,它定义了一系列的操作码(opcode)以及每种操作码的寻址模式、操
构建高效电池通信网络:BMS通讯协议V2.07实战篇(权威教程)
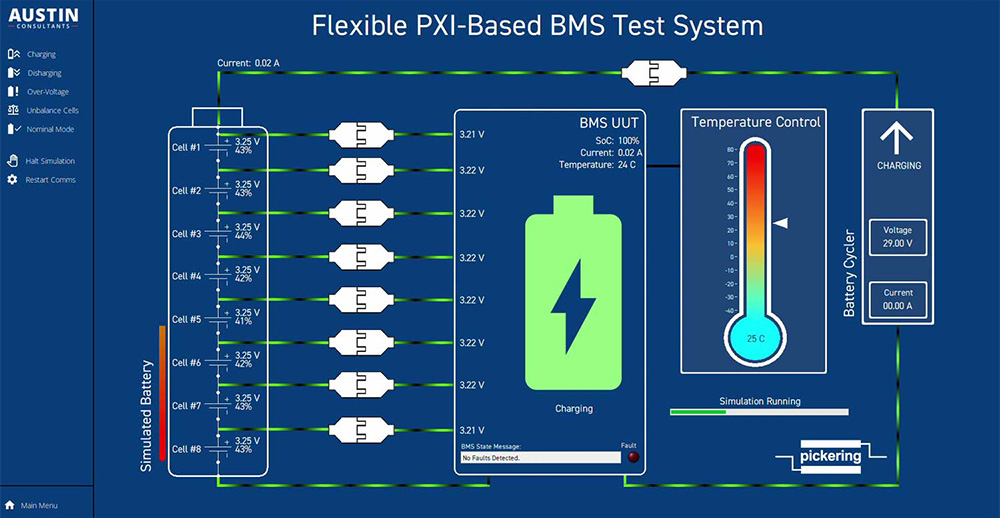
参考资源链接:[沃特玛BMS通讯协议V2.07详解](https://wenku.csdn.net/doc/oofsi3m9yc?spm=1055.2635.3001.10343)
# 1. BMS通讯协议V2.07概述
BMS通讯协议V2.07,作为电池管理系统(Battery Management System)的核心,负责电池模块间的信息交换和数据共享。本章节将概述该协议的主要特点,以及其在现代电池管理系
二手交易平台的7大需求分析秘诀:从用户需求到功能框架的全面解读
参考资源链接:[校园二手交易网站需求规格说明书](https://wenku.csdn.net/doc/2v1uyiaeu5?spm=1055.2635.3001.10343)
# 1. 二手交易平台的市场定位与用户需求
在当下互联网市场中,二手交易平台如雨后春笋般兴起,其具有独特的市场定位和用户需求。首先,从市场定位来看,这些平台通常聚焦于商品的循环利用,满足用户对
【内存管理与指针】:C语言动态内存分配的艺术,彻底解决内存碎片

参考资源链接:[C语言指针详细讲解ppt课件](https://wenku.csdn.net/doc/64a2190750e8173efdca92c4?spm=1055.2635.3001.10343)
# 1. 内存管理和指针的基础知识
## 内存管理的简述
在计算机科学中,内存管理是指对计算机内存资源的分配和回收的过程。有效的内存管理对于保证程序的稳定性和效率至关重
GC2083硬件稳定性保障:兼容性问题全面剖析

参考资源链接:[GC2083CSP: 1/3.02'' 2Mega CMOS Image Sensor 数据手册](https://wenku.csdn.net/do
【Mathematica模式匹配】:深入理解变量替换与函数映射机制

参考资源链接:[Mathematica教程:变量替换与基本操作](https://wenku.csdn.net/doc/41bu50ed0y?spm=1055.2635.3001.10343)
# 1. Mathematica的模式匹配简介
在现代编程实践中,模式匹配已经成为一种强大的工具,用于解决各种问题,从简单的字符串处理到复杂的图形模式识别。Mathematic
【PFC电感参数计算速成】:从理论到应用,一步到位掌握核心技巧

参考资源链接:[Boost PFC电感计算详解:连续模式、临界模式与断续模式](https://wenku.csdn.net/doc/790zbqm1tz?spm=1055.2635.3001.10343)
# 1. PFC电
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )