MySQL连接优化秘籍:减少连接时间,提升响应速度
发布时间: 2024-07-27 14:21:13 阅读量: 54 订阅数: 48 

MySQL优化之连接优化

# 1. MySQL连接优化概述
MySQL连接优化是提升数据库性能和稳定性的关键技术,通过优化连接过程,可以有效减少连接开销,提高并发处理能力。本章将对MySQL连接优化进行概述,介绍其重要性、优化目标和优化策略。
### 1.1 优化重要性
MySQL连接优化对于数据库性能至关重要,主要体现在以下几个方面:
- **降低连接开销:**优化连接过程可以减少每次连接建立和释放所消耗的资源,从而提升数据库整体性能。
- **提高并发能力:**通过优化连接池配置,可以增加数据库的并发处理能力,满足高并发场景下的访问需求。
- **提升稳定性:**优化连接参数和策略可以提高数据库连接的稳定性,减少连接中断和重连次数,确保数据库服务的可靠性。
# 2. MySQL连接优化理论基础
### 2.1 MySQL连接过程分析
#### 2.1.1 客户端与服务器端交互流程
MySQL连接过程涉及客户端和服务器端之间的交互,具体流程如下:
1. **客户端初始化连接:**客户端应用程序通过调用MySQL库函数,建立与MySQL服务器的连接。
2. **服务器端验证连接:**服务器端收到连接请求后,验证客户端的身份和权限。
3. **会话建立:**验证通过后,服务器端为客户端创建一个会话,并分配必要的资源。
4. **查询执行:**客户端向服务器端发送查询请求,服务器端执行查询并返回结果。
5. **连接关闭:**当客户端完成查询或不再需要连接时,客户端发送关闭连接请求,服务器端释放相关资源。
#### 2.1.2 连接池机制和原理
连接池是一种缓存机制,用于管理预先建立的数据库连接。它通过以下步骤工作:
1. **初始化连接池:**应用程序创建连接池,并指定池的大小和最大连接数。
2. **获取连接:**当应用程序需要与数据库交互时,它从连接池中获取一个可用连接。
3. **使用连接:**应用程序使用连接执行查询或其他操作。
4. **释放连接:**当应用程序完成操作后,它将连接释放回连接池。
5. **连接池维护:**连接池定期检查空闲连接,并根据需要创建或销毁连接以维持池的大小。
### 2.2 MySQL连接优化参数
#### 2.2.1 连接超时和重连机制
**连接超时:**指定客户端等待服务器响应的最大时间,超时后连接将自动关闭。
**重连机制:**当连接超时或断开时,客户端会自动尝试重新连接到服务器。
#### 2.2.2 连接池大小和最大连接数
**连接池大小:**指定连接池中同时可用的连接数。
**最大连接数:**指定服务器端允许的最大同时连接数。
### 2.3 MySQL连接优化策略
#### 2.3.1 连接复用与连接池配置
**连接复用:**使用连接池管理连接,避免频繁创建和销毁连接。
**连接池配置:**根据业务需求和服务器资源,合理设置连接池大小和最大连接数。
#### 2.3.2 连接参数优化
**连接超时:**根据网络环境和服务器响应时间,适当调整连接超时时间。
**重连机制:**根据业务需求,配置重连间隔和重连次数。
# 3. MySQL连接优化实践技巧
### 3.1 MySQL连接池配置实践
#### 3.1.1 连接池初始化和参数设置
**代码块:**
```java
// 初始化连接池
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/test");
config.setUsername("root");
config.setPassword("123456");
config.addDataSourceProperty("cachePrepStmts", "true");
config.addDataSourceProperty("prepStmtCacheSize", "250");
config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");
config.setMaximumPoolSize(10);
config.setMinimumIdle(5);
// 创建连接池
HikariDataSource ds = new HikariDataSource(config);
```
**逻辑分析:**
* `HikariConfig` 类用于配置连接池。
* `setJdbcUrl` 方法设置数据库连接 URL。
* `setUsername` 和 `setPassword` 方法设置数据库用户名和密码。
* `addDataSourceProperty` 方法设置连接池属性。
* `cachePrepStmts` 属性启用预编译语句缓存。
* `prepStmtCacheSize` 属性设置预编译语句缓存大小。
* `prepStmtCacheSqlLimit` 属性设置预编译语句缓存中 SQL 语句的最大长度。
* `setMaximumPoolSize` 方法设置连接池最大连接数。
* `setMinimumIdle` 方法设置连接池最小空闲连接数。
* `HikariDataSource` 类创建连接池。
#### 3.1.2 连接池监控和管理
**代码块:**
```java
// 监控连接池状态
HikariPoolMXBean poolMXBean = ManagementFactory.newPlatformMXBeanProxy(
ManagementFactory.getPlatformMBeanServer(),
"com.zaxxer.hikari:type=HikariPool",
HikariPoolMXBean.class
);
// 获取连接池信息
System.out.println("连接池最大连接数:" + poolMXBean.getMaxPoolSize());
System.out.println("连接池最小空闲连接数:" + poolMXBean.getMinIdle());
System.out.println("连接池当前连接数:" + poolMXBean.getActiveConnections());
System.out.println("连接池空闲连接数:" + poolMXBean.getIdleConnections());
```
**逻辑分析:**
* `ManagementFactory.newPlatformMXBeanProxy` 方法获取连接池的 JMX 管理 Bean。
* `getMaxPoolSize` 方法获取连接池最大连接数。
* `getMinIdle` 方法获取连接池最小空闲连接数。
* `getActiveConnections` 方法获取连接池当前连接数。
* `getIdleConnections` 方法获取连接池空闲连接数。
### 3.2 MySQL连接参数优化实践
#### 3.2.1 连接超时和重连机制配置
**代码块:**
```java
// 设置连接超时时间
DriverManager.setLoginTimeout(10);
// 设置重连尝试次数
DriverManager.setRetriesAllDown(3);
```
**逻辑分析:**
* `setLoginTimeout` 方法设置连接超时时间,单位为秒。
* `setRetriesAllDown` 方法设置重连尝试次数。
#### 3.2.2 连接池大小和最大连接数调整
**代码块:**
```java
// 设置连接池大小
db.setPoolSize(20);
// 设置最大连接数
db.setMaxPoolSize(50);
```
**逻辑分析:**
* `setPoolSize` 方法设置连接池大小。
* `setMaxPoolSize` 方法设置最大连接数。
### 3.3 MySQL连接优化综合案例
#### 3.3.1 问题分析和优化方案制定
**问题分析:**
* 连接频繁断开。
* 连接池溢出。
* 连接超时。
**优化方案:**
* **连接频繁断开:**
* 检查网络连接稳定性。
* 调整连接超时时间。
* 使用连接重试机制。
* **连接池溢出:**
* 调整连接池大小和最大连接数。
* 监控连接池状态,及时调整参数。
* **连接超时:**
* 调整连接超时时间。
* 检查数据库服务器负载情况。
#### 3.3.2 优化方案实施和效果验证
**优化方案实施:**
* 调整连接超时时间为 30 秒。
* 使用连接重试机制,重试次数为 3。
* 将连接池大小调整为 20,最大连接数调整为 50。
* 定期监控连接池状态。
**效果验证:**
* 连接频繁断开问题得到解决。
* 连接池溢出问题消失。
* 连接超时问题得到缓解。
# 4. MySQL连接优化进阶技术
### 4.1 MySQL连接负载均衡
#### 4.1.1 负载均衡原理和实现方式
负载均衡是一种将网络流量分配到多个服务器上的技术,以提高整体性能和可用性。在MySQL中,负载均衡可以用于将客户端连接分布到多个数据库服务器上,从而减少单个服务器上的负载。
实现MySQL负载均衡有两种主要方式:
- **软件负载均衡器:**如HAProxy、Nginx等,它们运行在操作系统上,充当客户端和数据库服务器之间的代理。
- **硬件负载均衡器:**如F5、Citrix等,它们是专门的硬件设备,提供更高级别的负载均衡功能。
#### 4.1.2 MySQL主从复制与负载均衡
MySQL主从复制可以与负载均衡结合使用,以进一步提高性能和可用性。在主从复制中,一个主数据库服务器将数据复制到一个或多个从数据库服务器上。客户端可以连接到任何从服务器,从而将负载分散到多个服务器上。
### 4.2 MySQL连接加密和安全
#### 4.2.1 MySQL连接加密协议
MySQL支持多种连接加密协议,以保护客户端和服务器之间的通信。这些协议包括:
- **SSL/TLS:**使用公钥加密和数字证书来加密连接。
- **Kerberos:**一种基于票据的认证协议,用于在网络上安全地验证用户。
#### 4.2.2 MySQL连接安全配置
除了使用加密协议外,还可以通过以下方式配置MySQL连接以提高安全性:
- **使用强密码:**为MySQL用户设置强密码,避免使用弱密码或默认密码。
- **限制访问权限:**只授予用户必要的权限,以最小化潜在的安全风险。
- **启用审计日志:**记录用户连接和操作,以进行安全分析和故障排除。
### 代码示例
**使用HAProxy进行MySQL负载均衡**
```
frontend mysql
bind *:3306
mode tcp
default_server backend
backend backend
server db1 192.168.1.10:3306
server db2 192.168.1.11:3306
```
**使用SSL/TLS加密MySQL连接**
```
mysql -u root -p --ssl-mode=REQUIRED
```
### 表格示例
| 负载均衡器类型 | 优点 | 缺点 |
|---|---|---|
| 软件负载均衡器 | 易于配置和管理 | 性能可能低于硬件负载均衡器 |
| 硬件负载均衡器 | 性能更高 | 配置和管理更复杂 |
### Mermaid流程图示例
```mermaid
graph LR
subgraph MySQL 主从复制
A[主数据库] --> B[从数据库]
B[从数据库] --> C[从数据库]
end
subgraph 负载均衡
D[客户端] --> E[负载均衡器]
E[负载均衡器] --> F[数据库服务器1]
E[负载均衡器] --> G[数据库服务器2]
end
```
# 5. MySQL连接优化最佳实践
### 5.1 MySQL连接优化原则
#### 5.1.1 性能优先,稳定可靠
* 优先考虑性能优化,在满足性能要求的前提下,保证连接的稳定性和可靠性。
* 避免过度优化,过度的优化可能导致系统复杂度增加,反而影响性能和稳定性。
#### 5.1.2 监控和调整,持续优化
* 定期监控连接池状态、连接数、连接时间等指标,及时发现问题并进行调整。
* 根据业务需求和系统负载的变化,动态调整连接池参数和连接优化策略。
### 5.2 MySQL连接优化常见问题解答
#### 5.2.1 连接频繁断开问题
* 检查网络连接是否稳定,是否存在丢包或延迟。
* 调整连接超时时间,适当增加重连次数。
* 检查连接池配置,确保连接池大小和最大连接数合理。
#### 5.2.2 连接池溢出问题
* 调整连接池大小,增加最大连接数。
* 检查业务逻辑中是否存在连接泄漏,及时释放不再使用的连接。
* 考虑使用连接泄漏检测工具,及时发现并解决连接泄漏问题。
#### 5.2.3 连接超时问题
* 调整连接超时时间,根据业务需求和网络环境合理设置。
* 检查数据库服务器负载,避免因服务器负载过高导致连接超时。
* 优化连接池配置,减少连接获取和释放的开销。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 数据库连接的方方面面,从初学者的连接指南到高级的连接优化和故障排除。专栏内容涵盖了连接池的原理、优化和管理,以及连接异常处理、监控和性能优化等主题。通过阅读本专栏,开发者可以全面了解 MySQL 数据库连接,掌握优化连接性能、提升响应速度和确保数据库稳定运行的技巧。专栏还提供了针对不同应用场景的连接池自定义和扩展指南,帮助开发者应对高并发和复杂需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ES7210-TDM级联深入剖析】:掌握技术原理与工作流程,轻松设置与故障排除

# 摘要
本文旨在系统介绍TDM级联技术,并以ES7210设备为例,详细分析其在TDM级联中的应用。文章首先概述了TDM级联技术的基本概念和ES7210设备的相关信息,进而深入探讨了TDM级联的原理、配置、工作流程以及高级管理技巧。通过深入配置与管理章节,本文提供了多项高级配置技巧和安全策略,确保级联链路的稳定性和安全性。最后,文章结合实际案例,总结了故障排除和性能优化的实用
社区与互动:快看漫画、腾讯动漫与哔哩哔哩漫画的社区建设与用户参与度深度对比
# 摘要
本文围绕现代漫画平台社区建设及其对用户参与度影响展开研究,分别对快看漫画、腾讯动漫和哔哩哔哩漫画三个平台的社区构建策略、用户互动机制以及社区文化进行了深入分析。通过评估各自社区功能设计理念、用户活跃度、社区运营实践、社区特点和社区互动文化等因素,揭示了不同平台在促进用户参与度和社区互动方面的策略与成效。此外,综合对比三平台的社区建设模式和用户参与度影响因素,本文提出了关于漫画平
平衡成本与激励:报酬要素等级点数公式在财务管理中的角色

# 摘要
本文探讨了成本与激励平衡的艺术,着重分析了报酬要素等级点数公式的理论基础及其实践应用。通过财务管理的激励理论,解析了激励模型与组织行为的关系,继而深入阐述了等级点数公式的定义、历史发展、组成要素及其数学原理。实践应用章节讨论了薪酬体系的设计与实施、薪酬结构的评估与优化,以及等级点数公式的具体案例应用。面对当前应用中出现的挑战,文章提出了未来趋势预测,并在案例研究与实证分析章节中进行了国内外企业薪酬
【R语言数据可视化进阶】:Muma包与ggplot2的高效结合秘籍
# 摘要
随着大数据时代的到来,数据可视化变得越来越重要。本文首先介绍了R语言数据可视化的理论基础,并详细阐述了Muma包的核心功能及其在数据可视化中的应用,包括数据处理和高级图表绘制。接着,本文探讨了ggplot2包的绘图机制,性能优化技巧,并分析了如何通过个性化定制来提升图形的美学效果。为了展示实际应用,本文进一步讨论了Muma与g
【云计算中的同花顺公式】:部署与管理,迈向自动化交易
# 摘要
本文全面探讨了云计算与自动化交易系统之间的关系,重点分析了同花顺公式的理论基础、部署实践、以及在自动化交易系统管理中的应用。文章首先介绍了云计算和自动化交易的基础概念,随后深入研究了同花顺公式的定义、语言特点、语法结构,并探讨了它在云端的部署优势及其性能优化。接着,本文详细描述了同花顺公式的部署过程、监控和维护策略,以及如何在自动化交易系统中构建和实现交易策略。此外,文章还分析了数据分析与决策支持、风险控制与合规性管理。在高级应用方面,
【Origin自动化操作】:一键批量导入ASCII文件数据,提高工作效率
# 摘要
本文旨在介绍Origin软件在自动化数据处理方面的应用,通过详细解析ASCII文件格式以及Origin软件的功能,阐述了自动化操作的实现步骤和高级技巧。文中首先概述了Origin的自动化操作,紧接着探讨了自动化实现的理论基础和准备工作,包括环境配置和数据集准备。第三章详细介绍了Origin的基本操作流程、脚本编写、调试和测试方法
【存储系统深度对比】:内存与硬盘技术革新,优化策略全解析

# 摘要
随着信息技术的快速发展,存储系统在现代计算机架构中扮演着至关重要的角色。本文对存储系统的关键指标进行了概述,并详细探讨了内存技术的演变及其优化策略。本文回顾了内存技术的发展历程,重点分析了内存性能的提升方法,包括架构优化、访问速度增强和虚拟内存管理。同时,本文对硬盘存储技术进行了革新与挑战的探讨,从历史演进到当前的技术突破,再到性能与耐用性的提升策略。此外,文章还对存储系统的性能进行了深
【广和通4G模块多连接管理】:AT指令在处理多会话中的应用
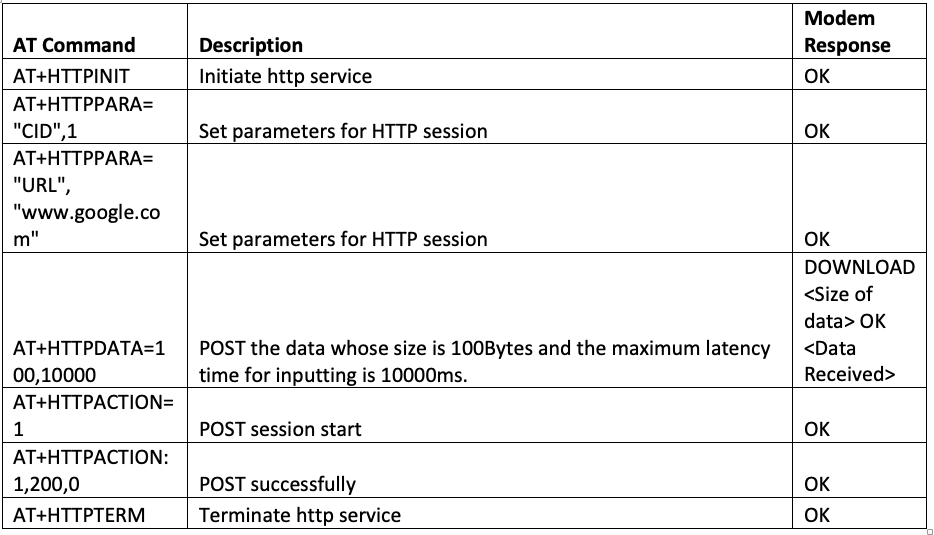
# 摘要
本文深入探讨了AT指令在广和通4G模块中的应用,以及在多连接管理环境下的性能优化。首先,介绍了AT指令的基础知识,包括基础指令的使用方法和高级指令的管理功能,并详细解析了错误诊断与调试技巧。其次,阐述了多连接管理的理论基础,以及AT指令在多连接建立和维护中的应用。接着,介绍了性能优化的基本原理,包括系统资源分配、连接效
【移动打印系统CPCL编程攻略】:打造高效稳定打印环境的20大策略

# 摘要
本文首先概述了移动打印系统CPCL的概念及其语言基础,详细介绍了CPCL的标签、元素、数据处理和打印逻辑控制等关键技术点。其次,文章深入探讨了CPCL在实践应用中的模板设计、打印任务管理以及移动设备与打印机的交互方式。此外,本文还提出了构建高效稳定打印环境的策略,包括系统优化、打印安全机制和高级打印功能的实现。最后,通过行业应用案例分析,本文总结了
AP6521固件升级中的备份与恢复:如何防止意外和数据丢失
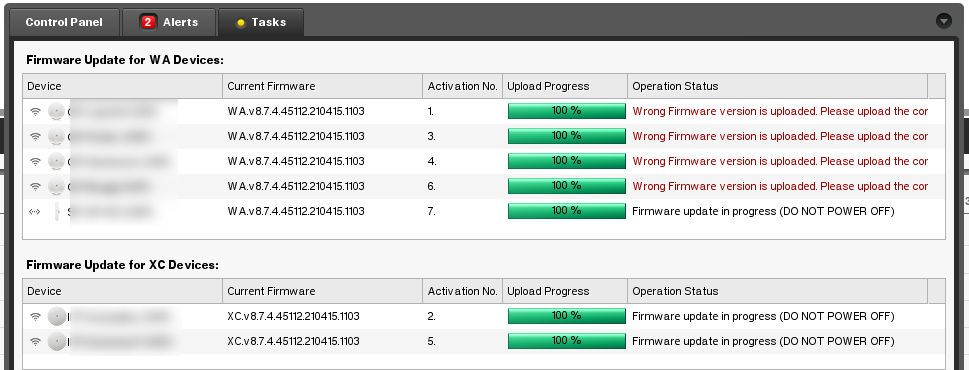
# 摘要
本文全面探讨了固件升级过程中的数据安全问题,强调了数据备份的重要性。首先,从理论上分析了备份的定义、目的和分类,并讨论了备份策略的选择和最佳实践。接着,通过具体的固件升级场景,提出了一套详细的备份计划制定方法以及各种备份
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )