机器学习快速入门到精通:Python应用实战指南
发布时间: 2024-12-07 01:30:20 阅读量: 10 订阅数: 15 

JAVA 学习成长路线:从入门到精通的技术成长分享.docx
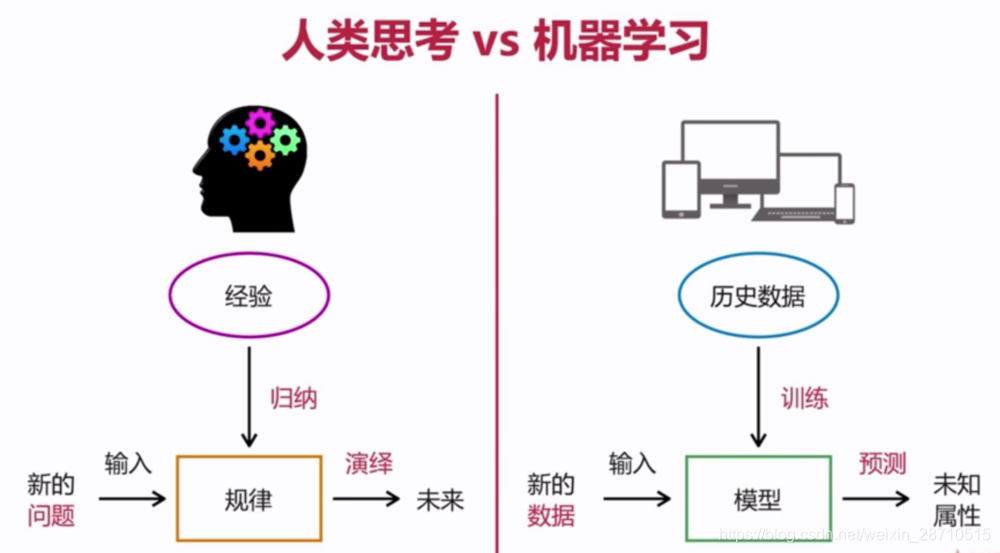
# 1. 机器学习简介与Python基础
## 1.1 机器学习概述
### 1.1.1 机器学习的定义与重要性
机器学习(Machine Learning, ML)是一种使计算机系统无需明确编程就能根据经验自动改进的技术。它侧重于开发能够从数据中学习并做出决策或预测的算法。随着大数据的兴起,机器学习的重要性日益凸显,它已广泛应用于搜索引擎、推荐系统、自然语言处理等多个领域。
### 1.1.2 机器学习的分类:监督式、无监督式、强化学习
机器学习算法主要分为三大类:
- **监督式学习(Supervised Learning)**:通过标注好的训练数据集进行学习,预测未知数据标签。
- **无监督式学习(Unsupervised Learning)**:未标注数据集处理,通常用于发现数据中的模式。
- **强化学习(Reinforcement Learning)**:通过奖励与惩罚机制,指导计算机在特定环境中进行决策。
### 1.1.3 机器学习的应用领域与未来趋势
机器学习的应用领域涵盖了金融科技、医疗健康、自动驾驶等各个方面,未来趋势包括自动化机器学习、边缘计算以及解释性AI等。
## 1.2 Python在机器学习中的地位
### 1.2.1 Python的编程特点与优势
Python因其简洁、易读性强以及拥有丰富的第三方库,被广泛应用于机器学习领域。Python简洁的语法使得编程者能够快速地实现算法和数据处理。同时,由于其解释性和动态类型系统,Python具有很高的开发效率和灵活性。
### 1.2.2 必备的Python库:NumPy、Pandas、Matplotlib
在进行机器学习项目时,有三个不可或缺的Python库:
- **NumPy**:用于高效的数值计算。
- **Pandas**:提供易用的数据结构和数据分析工具。
- **Matplotlib**:用于生成高质量的静态、动画和交互式可视化图表。
### 1.2.3 机器学习库:scikit-learn、TensorFlow、Keras
对于机器学习任务,以下库是必须要熟悉的:
- **scikit-learn**:提供简单而强大的工具用于数据挖掘和数据分析。
- **TensorFlow**:由Google开发的开源机器学习框架,适合于大规模的机器学习项目。
- **Keras**:基于TensorFlow之上的高级API,用于快速搭建和试验神经网络。
在接下来的章节中,我们将深入探讨机器学习的各个方面,并且实践如何使用Python及其库来解决实际问题。
# 2. 数据预处理与特征工程
### 2.1 数据清洗与处理
在机器学习项目中,数据是基础。数据清洗与处理是确保模型性能和准确性的关键步骤,需要在特征工程之前完成。它涉及一系列的操作,包括数据清洗、处理缺失值、异常值检测和处理,以及数据标准化和归一化。
#### 2.1.1 缺失值处理
数据集中的缺失值可能是由于数据收集、录入错误或某些记录不完整所导致的。不恰当的处理缺失值可能导致模型性能下降,因此需要仔细处理。常见的方法包括删除含有缺失值的记录、使用均值或中位数填充,或者使用更复杂的方法如模型预测来填充。
例如,使用Python的Pandas库可以这样处理缺失值:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
# 读取数据集
df = pd.read_csv('dataset.csv')
# 初始化Imputer对象,用均值填充数值型数据的缺失值
imputer = SimpleImputer(strategy='mean')
# 假设只处理特定的列,如 'feature1' 和 'feature2'
features = ['feature1', 'feature2']
df[features] = imputer.fit_transform(df[features])
# 处理后的数据
print(df)
```
在使用均值填充之前,应考虑是否合理,因为均值可能受到异常值的影响,或者在分布不均的数据集上表现不佳。中位数填充对异常值更为稳健,尤其是当数据呈现偏态分布时。
#### 2.1.2 异常值检测与处理
异常值是那些与数据集中其它数据显著不同的数据点。它们可能是数据收集错误的结果,也可能是真实数据的反映。异常值可能会对模型产生负面影响,因此需要检测和处理。
异常值的检测可以使用统计方法,例如基于标准差的方法、箱形图、Z分数、IQR(四分位数间距)等。处理异常值的方法包括删除含有异常值的记录、将异常值替换为统计量(如均值、中位数等),或者使用更先进的算法来处理。
```python
# 使用IQR方法检测并处理异常值
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
# 定义异常值
outliers = (df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))
# 可选择删除异常值或替换为某个统计量
# 删除异常值
df_cleaned = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]
# 或者用中位数替换
for feature in outliers.columns:
median_value = df[feature].median()
df[feature] = df[feature].mask(outliers[feature], median_value)
```
#### 2.1.3 数据标准化与归一化
数据标准化和归一化是将数据按比例缩放,使之落入一个小的特定区间。标准差归一化(Standardization)和最小-最大归一化(Normalization)是最常见的方法。
标准差归一化后,数据将拥有零均值和单位方差,使用以下公式:
\[ z = \frac{(x - \mu)}{\sigma} \]
最小-最大归一化将数据缩放到 [0, 1] 区间内:
\[ x_{norm} = \frac{(x - x_{min})}{(x_{max} - x_{min})} \]
使用Python代码进行数据标准化:
```python
from sklearn.preprocessing import StandardScaler
# 选择数值型特征列
numerical_features = ['feature1', 'feature2']
scaler = StandardScaler()
# 进行标准化
df[numerical_features] = scaler.fit_transform(df[numerical_features])
# 查看标准化后的数据
print(df[numerical_features])
```
归一化可以使用 `MinMaxScaler` 实现:
```python
from sklearn.preprocessing import MinMaxScaler
# 初始化归一化对象
min_max_scaler = MinMaxScaler()
# 进行归一化
df[numerical_features] = min_max_scaler.fit_transform(df[numerical_features])
# 查看归一化后的数据
print(df[numerical_features])
```
归一化和标准化能够使不同量级的特征在同一量级上比较,有助于提高模型性能,尤其是在距离计算敏感的算法中,如K近邻(KNN)和SVM。
### 2.2 特征选择与构造
特征选择是从当前特征中选择一部分特征子集的过程,它旨在减少特征的维度,同时保持数据集中包含的信息量。特征选择有助于提升模型性能,减少训练时间,并降低过拟合的风险。
#### 2.2.1 过滤法、包装法、嵌入法
- **过滤法(Filter Methods)**:基于数据本身的统计测试来选择特征,例如卡方检验、互信息、方差分析等。
- **包装法(Wrapper Methods)**:基于模型的表现来选择特征,例如递归特征消除(RFE)、前向选择和后向消除。
- **嵌入法(Embedded Methods)**:在训练过程中集成特征选择和模型训练,例如使用L1正则化进行特征选择。
例如,使用`SelectKBest`方法,根据卡方检验来选择特征:
```python
from sklearn.feature_selection import SelectKBest, chi2
# 假设 'target' 是目标变量列
X_new = SelectKBest(chi2, k=5).fit_transform(df.drop('target', axis=1), df['target'])
# 查看选定的特征
print(X_new)
```
另外,使用递归特征消除(RFE)的例子:
```python
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
# 选择一个模型
estimator = RandomForestClassifier(n_estimators=10, random_state=42)
# 递归特征消除
selector = RFE(estimator, n_features_to_select=5, step=1)
selector = selector.fit(df.drop('target', axis=1), df['target'])
# 查看选定的特征
selected_columns = df.drop('target', axis=1).columns[selector.support_]
print(selected_columns)
```
特征选择的目的是获得一组有代表性的特征,有助于提高模型的准确率和解释性。
#### 2.2.2 特征构造技巧与实践
特征构造是根据已有特征生成新特征的过程。它涉及领域知识的利用和数据处理技巧,如多项式特征、交互特征、特征交叉等。
例如,创建特征的多项式组合:
```python
from sklearn.preprocessing import PolynomialFeatures
# 初始化多项式特征生成器
poly = PolynomialFeatures(degree=2, include_bias=False)
# 生成多项式特征
X_poly = poly.fit_transform(df.drop('target', axis=1))
# 查看新生成的特征
feature_names = poly.get_feature_names(df.drop('target', axis=1).columns)
print(X_poly, feature_names)
```
特征构造能够有效地增强模型的表现能力,但需要注意保持模型的泛化能力,避免过拟合。
### 2.3 数据集划分与交叉验证
在机器学习中,将数据划分为训练集和测试集是评估模型性能的常用方法。同时,为了更好地利用数据并减少模型评估的方差,交叉验证是一种强大的技术。
#### 2.3.1 训练集与测试集的划

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 在科学计算领域的广泛应用。从 NumPy 的基础框架到 Pandas 的数据分析技巧,再到 Matplotlib 的图表绘制能力,专栏涵盖了 Python 科学计算工具箱中的核心技术。此外,它还探讨了 SciPy 进阶工具箱、SymPy 符号计算以及在生物信息学、航空航天、高能物理、统计学、信号处理和图像处理等领域的应用。通过深入浅出的讲解和丰富的示例,本专栏为读者提供了全面的指南,帮助他们掌握 Python 科学计算的强大功能,并将其应用于各种科学和工程领域。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IT6801FN深度解析】:一文掌握手册中的20个核心技术要点

参考资源链接:[IT6801FN 数据手册:MHL2.1/HDMI1.4 接收器技术规格](https://wenku.csdn.net/doc
【电机控制实践】:DCS系统中电机启停原理图深度解读
参考资源链接:[DCS系统电机启停原理图.pdf](https://wenku.csdn.net/doc/646330c45928463033bd8df4?spm=1055.2635.3001.10343)
# 1. DCS系统概述与电机控制基础
## 1.1 DCS系统简介
分布式控制系统(DCS)是一种集成了数据采集、监控、控制和信息管理功
Win7_Win8系统Prolific USB-to-Serial适配器故障快速诊断与修复大全:专家级指南

参考资源链接:[Win7/Win8系统解决Prolific USB-to-Serial Comm Port驱动问题](https://wenku.csdn.net/doc/4zdddhvupp?spm=1055.2635.3001.10343)
# 1. Prolific USB-to-Serial适配器故障概述
在当今数字化时代,Prolific USB-to-Seria
iSecure Center 日志管理技巧:追踪与分析的高效方法
参考资源链接:[海康iSecure Center运行管理手册:部署、监控与维护详解](https://wenku.csdn.net/doc/2ibbrt393x?spm=1055.2635.3001.10343)
# 1. 日志管理的重要性和基础
## 1.1 日志管理的重要性
日志记录了系统运行的详细轨迹,对于故障诊断、性能监控、安全审计和
SSD1309性能优化指南

参考资源链接:[SSD1309: 128x64 OLED驱动控制器技术数据](https://wenku.csdn.net/doc/6412b6efbe7fbd1778d48805?spm=1055.2635.3001.10343)
# 1. SSD1309显示技术简介
SSD1309是一款广泛应用于小型显示设备中的单色OLED驱动芯片,由上海世强先进科技有限公司生产。它支持多种分辨率、拥有灵活的接口配置,并且通过I2C或S
Rational Rose顺序图性能优化:10分钟掌握最佳实践
参考资源链接:[Rational Rose顺序图建模详细教程:创建、修改与删除](https://wenku.csdn.net/doc/6412b4d0be7fbd1778d40ea9?spm=1055.2635.3001.10343)
# 1. Rational Rose顺序图简介与性能问题
## 1.1 Rational Rose工具的介绍
Rational Rose是IBM推出
无线快充技术革新:IP5328与无线充电的完美融合
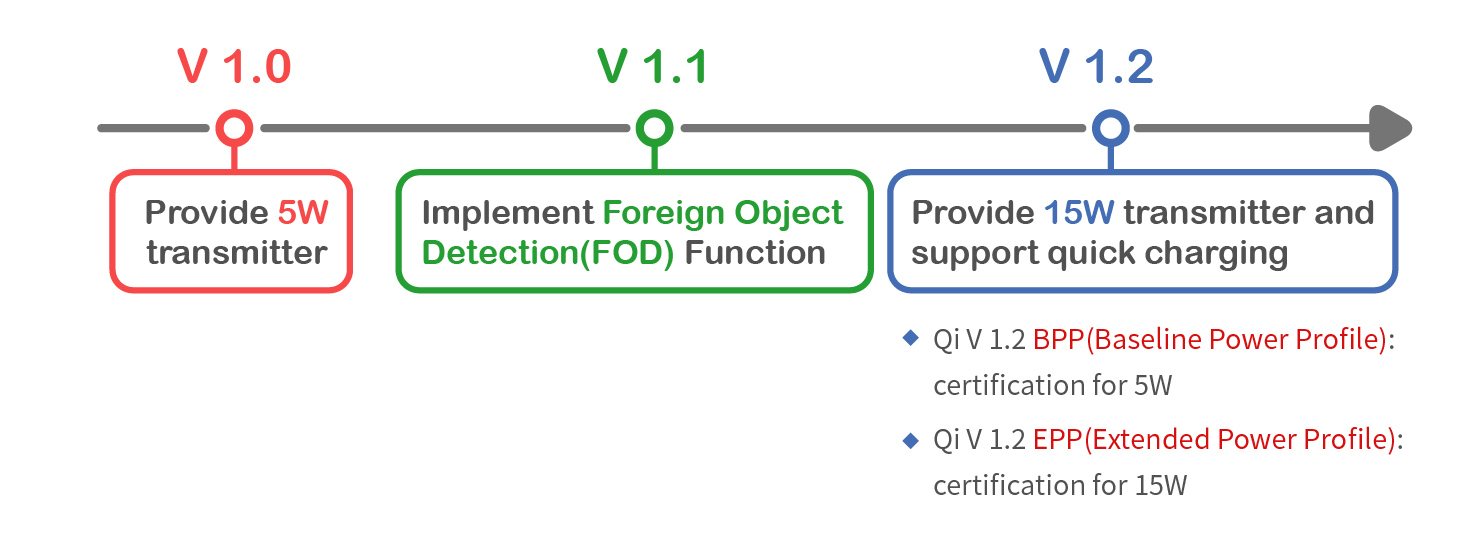
参考资源链接:[IP5328移动电源SOC:全能快充协议集成,支持PD3.0](https://wenku.csdn.net/doc/16d8bvpj05?spm=1055.2635.3001.10343)
# 1. 无线快充技术概述
无线快充技术的兴起,改变了人们为电子设备充电的习惯,使得充电变得更加便捷和高效。这种技
【AI引擎高级功能开发】:Prompt指令扩展的实践与策略
参考资源链接:[掌握ChatGPT Prompt艺术:全场景写作指南](https://wenku.csdn.net/doc/2b23iz0of6?spm=1055.2635.3001.10343)
# 1. AI引擎与Prompt指令概述
在当前的IT和人工智能领域,AI引擎与Prompt指令已经成为提升自然语言处理能力的重要工具。AI引擎作为核心的技术驱动,其功能的发挥往往依赖于高效、准确的Prompt指令。通过使用这些指令,AI引擎能够更好地理解和执行用户的查询、请求和任务,从而展现出强大的功能和灵活性。
AI引擎与Prompt指令的结合,不仅加速了人工智能的普及,也推动了智能技术在
【汇川H5U Modbus TCP性能提升】:高级技巧与优化策略
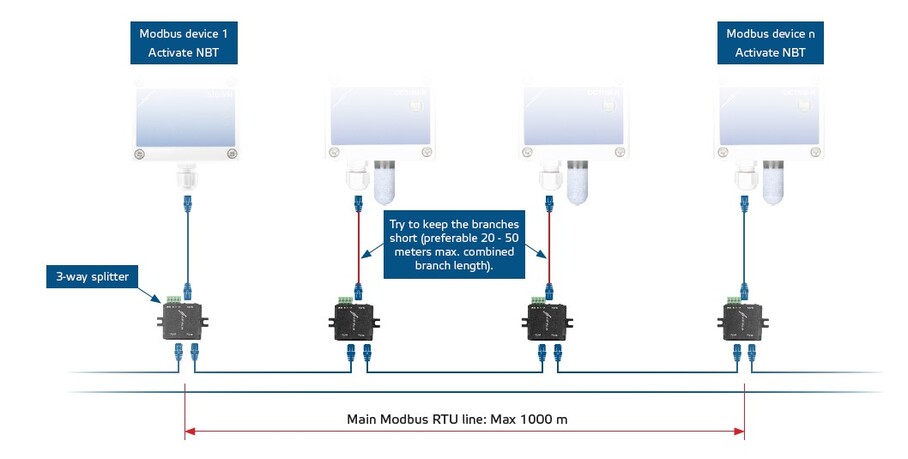
参考资源链接:[汇川H5U系列控制器Modbus通讯协议详解](https://wenku.csdn.net/doc/4bnw6asnhs?spm=1055.2635.3001.10343)
# 1. Modbus TCP协议概述
Modbus TCP协议作为工业通信领域广泛采纳的开放式标准,它在自动化控制和监视系统中扮演着至关重要的角色。本章首先将简要回顾Mod
【TFT-OLED速度革命】:提升响应速度的驱动电路改进策略

参考资源链接:[TFT-OLED像素单元与驱动电路:新型显示技术的关键](https://wenku.csdn.net/doc/645e54535
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )