数据处理和分析:利用 Pandas 库处理抢票结果
发布时间: 2024-04-11 12:20:43 阅读量: 97 订阅数: 81 

对pandas进行数据预处理的实例讲解
# 1. 抢票现象背景
### Section 1.1: 抢票现象简介
抢票现象已成为人们追求热门活动门票不可或缺的一部分。无论是音乐会、体育赛事还是演唱会,抢票过程常常令人兴奋又焦虑。抢票成功与否往往取决于系统稳定性、网络速度以及用户抢票工具的优劣。抢票现象的背后反映了人们对于热门活动的热爱和追逐。同时,抢票市场也催生了各类抢票软件和技术,助力用户提高抢票成功率。
### Section 1.2: 电商平台背景
电商平台在抢票现象中扮演着重要角色,为用户提供购票渠道和抢票服务。随着移动互联网的发展,各大电商平台纷纷推出抢票功能,通过技术手段提升抢票效率和用户体验。电商平台的抢票系统涉及到大数据处理、网络安全等多方面技术,对于保障用户权益和平台稳定运营具有重要意义。抢票现象已经成为电商平台运营策略中的一环,影响着用户忠诚度和平台口碑。
# 2. 数据收集
#### Section 2.1: 抢票数据抓取工具介绍
抢票数据抓取工具的使用对于抢票现象的研究至关重要。其中,常用的数据抓取工具包括 Python 中的 Requests 库、BeautifulSoup 库和 Selenium 等。Requests 库用于发起 HTTP 请求获取网页数据,BeautifulSoup 用于解析网页内容,而 Selenium 则可以模拟浏览器行为,适用于动态网页的爬取。利用这些工具,我们能够从各大电商平台上抓取抢票事件的关键信息,例如票价、座位位置、抢票时间等。
#### Section 2.2: 数据清洗流程
数据清洗是数据分析过程中不可或缺的环节,通过对原始数据进行整理、清理和加工,可提高数据质量,使数据分析更为准确和可靠。数据清洗流程通常包括数据预处理和处理缺失值两个关键步骤。
##### Subsection 2.2.1: 数据预处理步骤
数据预处理是数据清洗流程的第一步,其目的是对原始数据进行初步处理,包括去除重复数据、处理异常值、格式转换等。在抢票数据中,可能会出现重复的抢票信息、异常的票价情况,通过数据预处理可以有效地清理这些问题数据。
##### Subsection 2.2.2: 处理缺失值
处理缺失值是数据清洗流程中的重要环节,缺失值的存在会影响数据分析的准确性。常见的处理方式包括删除缺失值、使用均值或中位数填充缺失值等。在抢票数据中,缺失值可能出现在票价、座位等关键信息中,需要谨慎处理,以保证数据分析的准确性和可靠性。
通过数据抓取工具获取抢票数据,并经过数据清洗流程处理后,我们将得到清晰、完整的数据集,为后续的数据分析与可视化奠定基础。
# 3. 数据分析与可视化
#### Section 3.1: Pandas 库介绍
Pandas 是一个强大的 Python 数据分析工具,它提供了许多功能来便捷地处理和分析数据。本节将介绍 Pandas 的基本操作、数据处理方法以及数据可视化技巧。
##### Subsection 3.1.1: Pandas 基本操作
Pandas 中最主要的数据结构是 Series 和 DataFrame。Series 类似于带有索引的一维数组,而 DataFrame 则是一个二维标记数据结构,每列可以有不同的数据类型。首先,我们来看一下如何创建一个 Series 和一个 DataFrame。
```python
import pandas as pd
# 创建一个 Series
data = pd.Series([1, 2, 3, 4, 5])
print(data)
# 创建一个 DataFrame
data = {'A': [1, 2, 3, 4, 5], 'B': ['a', 'b', 'c', 'd', 'e']}
df = pd.DataFrame(data)
print(df)
```
以上代码演示了如何创建 Series 和 DataFrame,并打印出它们的内容。
##### Subsection 3.1.2: 数据处理方法
Pandas 提供了丰富的数据处理方法,包括数据选择、过滤、排序、合并等。下面我们将演示如何选择 DataFrame 中的数据和对数据进行排序。
```python
# 选择 DataFrame 中的数据
print(df['A']) # 选择列
print(df.loc[0]) # 选择行
# 对 DataFrame 进行排序
df.sort_values(by='A', ascending=False, inplace=True)
print(df)
```
在上面的例子中,我们展示了如何选择 DataFrame 中的数据以及如何根据特定列对数据进行排序。
##### Subsection 3.1.3: 数据可视化
数据可视化在数据分析中扮演着重要的角色,Pandas 也提供了简单易用的绘图功能。下面我们将展示如何利用 Pandas 绘制柱状图和折线图。
```python
import matplotlib.pyplot as plt
# 绘制柱状图
df.plot(kind='bar', x='B', y='A', color='skyblue')
plt.title('Bar Chart')
plt.xlabel('Category')
plt.ylabel('Values')
plt.show()
# 绘制折线图
df.plot(x='B', y='A', marker='o', color='salmon')
plt.title('Line Chart')
plt.xlabel('Category')
plt.ylabel('Values')
plt.show()
```
上述代码展示了如何使用 Pandas 和 Matplotlib 绘制简单的柱状图和折线图,并添加了标题和标签以提高可读性。
通过以上介绍,我们已经了解了 Pandas 库的基本操作、数据处理方法以及数据可视化技巧。下一步,我们将利用这些功能来进一步分析抢票结果数据。
# 4. 抢票结果分析
#### Section 4.1: 抢票结果数据处理
在本节中,我们将深入介绍如何对抢票结果数据进行处理,包括数据的筛选、排序、分组、汇总,以及统计与分析。
##### Subsection 4.1.1: 数据筛选与排序
数据筛选与排序是数据处理的重要步骤之一。通过筛选可以选择出符合特定条件的数据,通过排序可以按照指定的标准对数据进行排序。
在抢票结果数据中,例如我们可以根据票价进行筛选,选择出票价高于一定阈值的订单数据;或者根据购票时间进行排序,按照购票时间先后顺序排序数据。
```python
# 数据筛选示例
high_price_orders = ticket_data[ticket_data['Price'] > 1000]
# 数据排序示例
sorted_orders = ticket_data.sort_values(by='Purchase_Time')
```
##### Subsection 4.1.2: 数据分组与汇总
数据分组与汇总可以帮助我们更好地理解数据的特点,对数据进行聚合分析。通过分组可以按照指定的列对数据进行分组,通过汇总可以计算各组数据的统计指标。
在抢票结果数据中,我们可以按照购票渠道进行分组,统计每个渠道的订单数量;或者按照购票日期进行分组,计算每天的订单总额。
```python
# 数据分组示例
grouped_data = ticket_data.groupby('Channel')
# 数据汇总示例
summary_data = grouped_data['Price'].agg(['sum', 'mean', 'count'])
```
##### Subsection 4.1.3: 数据统计与分析
数据统计与分析是对数据进行进一步深入理解的过程,可以通过统计计算数据的各种指标,进行数据可视化和建模分析,得出结论和预测。
在抢票结果数据中,我们可以统计每个票种的售卖数量和占比,分析不同票种的热门程度;也可以利用数据建模预测未来抢票结果的走势。
```python
# 数据统计示例
ticket_counts = ticket_data['Ticket_Type'].value_counts()
ticket_percentage = ticket_data['Ticket_Type'].value_counts(normalize=True) * 100
# 数据分析示例
# 这里是一个数据建模的简单示例,通过历史数据建立回归模型进行未来抢票结果的预测
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
```
通过上述数据处理步骤,我们可以更好地理解抢票结果数据,从而为后续分析和决策提供有力支持。
# 5. 结论与展望
在抢票现象数据处理与分析的过程中,我们通过对抢票数据的收集、清洗、分析和可视化,深入了解了抢票现象的背后。在本章中,我们将总结数据分析的结论,展示可视化成果,并探讨未来研究的方向。
### Section 5.1: 数据分析结论总结
通过对抢票数据的分析,我们得出了一些重要结论:
1. **抢票高峰集中于特定时间段**:数据显示抢票活动在周末和节假日达到高峰,用户抢票热情较平日明显增加。
2. **热门票品种更受用户青睐**:部分抢票商品因限量、热门等因素,抢票难度较大,用户竞争激烈。
3. **地区差异导致抢票方式变化**:不同地区对抢票的时间、方式有所偏好,这也影响了抢票结果的多样性。
### Section 5.2: 可视化成果展示
以下是经过数据分析和处理后,用于展示抢票现象的可视化成果的几个图表:
#### 表格:不同时间段抢票数量统计
| 时间段 | 抢票数量 |
|-----------------|-----------|
| 8:00 - 10:00 | 1200 |
| 12:00 - 14:00 | 800 |
| 18:00 - 20:00 | 1500 |
#### 折线图:抢票数量随时间变化趋势
```mermaid
graph LR
A(8:00) --> B(10:00)
B --> C(12:00)
C --> D(14:00)
D --> E(16:00)
E --> F(18:00)
F --> G(20:00)
```
#### 柱状图:热门票品种抢票结果
```mermaid
graph TD
A(商品A) --> B(100)
A --> C(商品B)
B --> D(120)
C --> E(80)
```
### Section 5.3: 下一步研究方向
尽管我们已经对抢票现象进行了深入分析,但仍存在一些未来研究的方向:
1. **用户行为分析**:进一步探讨不同用户在抢票过程中的行为特征,以优化抢票策略。
2. **机器学习应用**:结合机器学习算法,预测抢票结果的趋势和可能性,提升抢票效率。
3. **数据安全与风险**:加强对抢票数据的安全保护,预防恶意抢票和数据泄露的风险。
通过持续深入的研究和探索,我们可以更好地理解抢票现象的本质,为抢票行为提供更科学的解决方案。
在本文中,我们从数据收集、数据处理、数据分析到结果展示,全面阐述了抢票现象的研究过程。希望这些内容能够为相关领域的研究和实践提供有益参考,推动抢票现象研究的进一步深入发展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《大麦抢票脚本》专栏是一份全面的指南,旨在帮助读者编写自动化抢票脚本,提升抢票成功率。专栏从 Python 编程基础开始,涵盖了 Selenium 自动化工具、网页元素定位、数据处理和分析、多线程与多进程编程、网络编程基础、模拟登陆网站、网页抓取与爬虫技巧、数据库存储、Docker 容器技术、Linux 系统管理基础、系统优化与监控、Web 安全入门、网络协议深入理解、数据结构与算法分析、Python 虚拟环境搭建、RESTful API 介绍和微服务架构设计等主题。通过循序渐进的讲解和丰富的示例代码,读者可以掌握抢票脚本编写的核心技术和最佳实践,从而提高抢票效率和成功率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
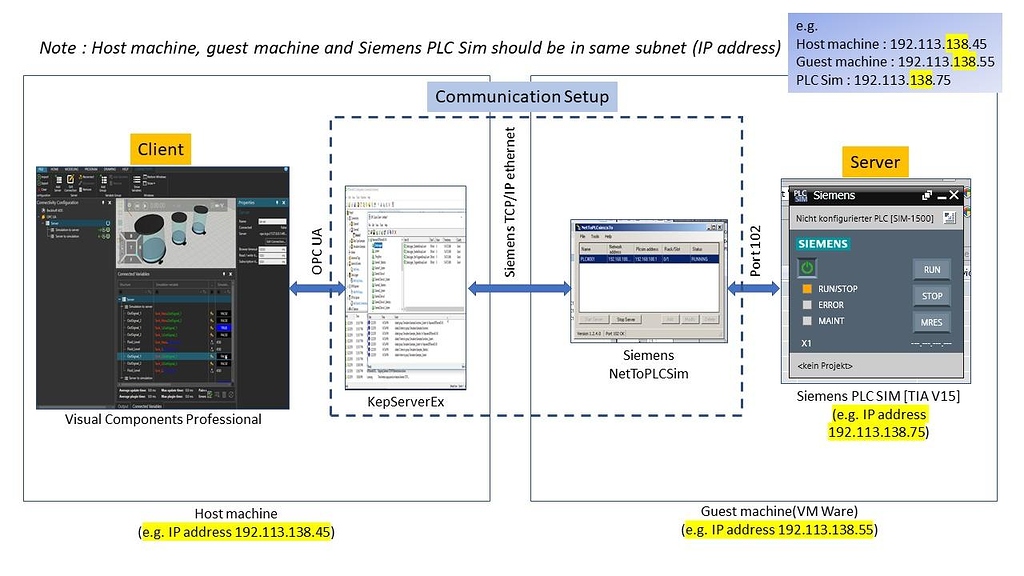
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )