网页元素定位技巧:XPath 和 CSS Selector 的应用
发布时间: 2024-04-11 12:18:52 阅读量: 119 订阅数: 77 
# 1. **前言**
在网页开发和自动化测试中,网页元素定位是一项至关重要的技能。通过准确定位页面上的元素,我们能够进行数据抓取、自动化测试、UI 操作等各种操作。良好的网页元素定位技巧不仅可以提高代码的稳定性和可维护性,还能够提升开发和测试效率。
重视网页元素定位技巧的原因在于,精准的定位意味着我们可以更快速地找到目标元素,减少定位错误的概率,提高代码的健壮性。精通 XPath 和 CSS Selector 定位方法能够让我们在面对不同的定位需求时游刃有余。接下来,我们将深入探讨 XPath 和 CSS Selector 定位技巧,帮助读者更好地理解并应用这些技能。
# 2. XPath 定位技巧
XPath 是一种在 XML 文档中定位元素的语言,也常用于定位 HTML 元素。通过 XPath,可以准确定位页面上的特定元素,从而实现数据提取、自动化测试等操作。在网页元素定位中,XPath 是一个非常强大的工具。
#### 2.1 XPath 是什么?
XPath(XML Path Language)是一种用来在 XML 文档中定位节点的语言。在 HTML 文档中,我们也可以使用 XPath 来定位页面元素。XPath 由路径表达式组成,可以通过不同方式来定位元素。
##### 2.1.1 XPath 的基本语法
XPath 的路径表达式由一系列的轴(axis)和节点测试构成,可以通过斜杠(/)进行层级关系的定位。例如,`//div[@class='content']//a` 表示选择 class 为 'content' 的 div 元素内部的所有 a 元素。
##### 2.1.2 XPath 的绝对路径和相对路径
XPath 有两种定位方式:绝对路径和相对路径。绝对路径从文档的根节点开始定位,可以唯一确定一个元素;相对路径从当前节点开始定位,更灵活,适用于页面结构变化较多的场景。
#### 2.2 XPath 定位方法
XPath 定位方法有多种,主要包括使用元素属性定位、使用层级关系定位和使用文本内容定位。
##### 2.2.1 使用元素属性定位
可以通过元素的属性来定位元素,如 id、class、name、type 等。例如,`//input[@id='username']` 可以定位页面上 id 为 'username' 的输入框元素。
##### 2.2.2 使用层级关系定位
通过元素在页面中的层级关系来定位元素,可以使用父子关系、兄弟关系等。例如,`//div[@class='container']//a[1]` 可以定位 class 为 'container' 的第一个子元素 a。
##### 2.2.3 使用文本内容定位
有时候需要根据元素的文本内容来定位元素,可以使用 text() 函数来选择包含特定文本的元素。例如,`//a[text()='Click Here']` 可以定位文本内容为 'Click Here' 的链接元素。
通过这些 XPath 定位方法,我们可以精确地定位页面上的元素,便于后续的操作和处理。XPath 在网页元素定位中有着非常重要的作用,能够提高开发与测试的效率。
```python
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.example.com")
# 使用 XPath 定位元素并进行操作
element = driver.find_element_by_xpath("//input[@id='username']")
element.send_keys("user123")
```
在上面的示例中,我们使用了 XPath 定位方法来定位 id 为 'username' 的输入框元素,并向其发送文本内容。这展示了 XPath 在自动化测试中的应用。
```mermaid
graph LR
A[开始] --> B(条件判断)
B -- 是 --> C{操作元素}
C -- 是 --> D[结束]
B -- 否 --> E[结束]
```
在上面的流程图中,展示了通过条件判断来选择是否操作元素的流程。根据条件是或否,可以选择不同的路径执行操作。
通过深入学习 XPath 定位技巧,我们可以更加灵活准确地定位页面上的元素,适用于不同的场景,提高开发与测试的效率。XPath 在网页元素定位中具有重要的作用,是值得深入研究和掌握的技巧。
# 3. CSS Selector 定位技巧
CSS Selector 是一种常用的网页元素定位方法,通过选择元素的属性来进行定位。在这一章节,我们将深入介绍 CSS Selector 的基本原理以及常用的定位方法。
#### CSS Selector 简介
CSS Selector 是一种通过 CSS 选择器来选择指定 HTML 元素的定位方法。下面将简要介绍 CSS Selector 的基本语法和原理。
##### 什么是 CSS Selector?
CSS Selector 是一种用于选择 DOM 元素的模式,可以根据元素的属性、层级关系等进行定位。
##### CSS Selector 的基本语法
CSS Selector 的基本语法由选择器和声明块组成,选择器用于选择特定的元素,声明块用于指定元素应用的样式。
```css
selector {
property: value;
}
```
#### CSS Selector 定位方法
在实际应用中,我们可以通过不同的 CSS Selector 定位方法来选择页面元素。接下来将介绍常用的定位方式。
##### 使用标签名定位
通过标签名选择元素是 CSS Selector 中最基础的定位方法。例如,选择所有的段落元素:
```css
p {
color: blue;
}
```
##### 使用类名和 id 定位
除了标签名定位,我们还可以通过类名和 id 来定位元素。例如,选择 class 为 "content" 的元素:
```css
.content {
font-size: 16px;
}
```
##### 使用属性选择器定位
CSS Selector 还支持使用属性选择器来定位元素,可以根据元素的属性值来选择元素。例如,选择所有带有 title 属性的元素:
```css
[data-title] {
color: red;
}
```
通过以上介绍,我们了解了 CSS Selector 的基本原理和常用的定位方法。在实际开发中,灵活运用 CSS Selector 可以帮助我们精确定位页面元素,提高定位的准确性和效率。
# 4. XPath 与 CSS Selector 的比较
#### 4.1 性能比较
XPath 与 CSS Selector 在网页元素定位中扮演着重要的角色。它们虽然都能够准确定位元素,但在性能方面却存在一些差异。
##### 4.1.1 XPath 与 CSS Selector 的性能
XPath 由于是通过遍历整个文档树来定位元素,相对于 CSS Selector 的定位速度可能会慢一些。这是因为 XPath 是更加通用的定位方式,会涉及到更多的节点关系,并且在定位时需要对整个文档进行解析和匹配。
```python
# 示例代码:使用 XPath 定位元素
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com")
element = driver.find_element_by_xpath("//input[@id='username']")
```
##### 4.1.2 如何选择合适的定位方式?
在实际应用中,针对不同的场景可以选择适合的定位方式。如果页面结构比较复杂,元素之间存在多层嵌套关系,且需要更精确地定位元素,可以考虑使用 XPath。而如果页面结构相对简单,且元素的 class 或 id 属性具有唯一性,可以优先选择 CSS Selector 来定位元素。
#### 4.2 灵活性比较
XPath 和 CSS Selector 在灵活性上也有所区别,这直接影响了在不同场景下的选择。
##### 4.2.1 XPath 与 CSS Selector 的灵活性
XPath 在定位元素时,可以通过节点的绝对路径或相对路径来定位,相对路径特别适合用于定位相对位置固定的元素。而 CSS Selector 则更加侧重于通过元素的属性或特征来定位,灵活性较强。
```python
# 示例代码:使用 CSS Selector 定位元素
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com")
element = driver.find_element_by_css_selector("input#username")
```
##### 4.2.2 不同场景下的最佳选择
在实际开发和测试中,需要根据具体场景来选择合适的定位方式。若定位目标是处于复杂结构中的元素,建议使用 XPath 进行定位;若需要简单精准地定位元素,可优先考虑使用 CSS Selector。
通过对比性能和灵活性,XPath 和 CSS Selector 在不同情况下展现出各自的优势,为开发人员和测试人员提供了多样化的选择,以更有效地定位网页元素。
# 5. 实战应用及总结
5.1 **实际案例分析**
在实际项目中,经常需要通过网页元素定位技巧进行数据抓取或页面操作。以下是两个案例分析,展示如何使用 XPath 和 CSS Selector 来精确定位页面元素。
- **5.1.1 通过 XPath 定位元素进行数据抓取**
假设我们需要从一个网页上抓取所有产品的价格信息,并将其存储到一个数据结构中。我们可以通过以下 Python 代码实现:
```python
from selenium import webdriver
# 启动浏览器
driver = webdriver.Chrome()
driver.get("https://example.com/products")
# 使用 XPath 定位所有产品价格元素
price_elements = driver.find_elements_by_xpath("//span[@class='price']")
# 提取价格信息并存储
prices = [elem.text for elem in price_elements]
# 打印价格信息
for price in prices:
print(price)
# 关闭浏览器
driver.quit()
```
在上述代码中,`find_elements_by_xpath` 方法通过 XPath 定位所有产品价格元素,然后提取价格信息进行存储和打印输出。
- **5.1.2 使用 CSS Selector 精确定位页面元素**
假设我们需要点击一个特定的按钮来触发某个功能,同时避免误操作其他按钮。我们可以通过以下 JavaScript 代码实现:
```javascript
var button = document.querySelector("button.submit-btn");
button.click();
```
在上述代码中,`querySelector` 方法使用 CSS Selector 定位具有 `submit-btn` 类名的按钮元素,然后触发按钮的点击事件。
### 实际案例总结
以上两个案例展示了在实际项目中如何运用 XPath 和 CSS Selector 定位页面元素。在数据抓取和页面操作中,合理选择定位方法能够提高代码的可读性和稳定性。XPath 适用于复杂结构下的定位,而 CSS Selector 则更便于选取特定样式或属性的元素。
5.2 **知识总结与建议**
在实际项目开发中,良好的网页元素定位技巧是非常重要的。以下是一些建议来帮助您提高定位技巧:
- **5.2.1 如何快速提高网页元素定位技巧?**
- 多练习实战,熟悉各种定位方法的应用场景和特点。
- 学习并掌握常用的 XPath 和 CSS Selector 语法规则,灵活运用。
- 使用调试工具(如 Chrome 开发者工具)来验证和调试定位表达式的准确性。
- **5.2.2 发现问题、解决问题、持续学习的重要性**
- 遇到定位问题时,要善于分析定位失败的原因,并尝试不同的定位方法解决问题。
- 参与社区交流、阅读相关文档和教程,保持对新技术的学习和掌握。
通过不断实践与总结,您将能够成为一个优秀的网页元素定位技术专家,为项目开发和测试工作贡献更多价值。
以上是知识总结与建议部分,希望这些内容能够帮助您更好地掌握网页元素定位技巧,提升工作效率。
### 结语
通过本文深入探讨 XPath 和 CSS Selector 的应用,帮助读者更好地理解和运用网页元素定位技巧,从而提升开发和测试效率。灵活运用不同的定位方法能够解决各种复杂的定位问题,在实践中不断总结经验,持续学习新知识,将使您成为一名技术领域的专家。愿本文对您有所启发和帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《大麦抢票脚本》专栏是一份全面的指南,旨在帮助读者编写自动化抢票脚本,提升抢票成功率。专栏从 Python 编程基础开始,涵盖了 Selenium 自动化工具、网页元素定位、数据处理和分析、多线程与多进程编程、网络编程基础、模拟登陆网站、网页抓取与爬虫技巧、数据库存储、Docker 容器技术、Linux 系统管理基础、系统优化与监控、Web 安全入门、网络协议深入理解、数据结构与算法分析、Python 虚拟环境搭建、RESTful API 介绍和微服务架构设计等主题。通过循序渐进的讲解和丰富的示例代码,读者可以掌握抢票脚本编写的核心技术和最佳实践,从而提高抢票效率和成功率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
脉冲宽度调制(PWM)在负载调制放大器中的应用:实例与技巧

# 1. 脉冲宽度调制(PWM)基础与原理
脉冲宽度调制(PWM)是一种广泛应用于电子学和电力电子学的技术,它通过改变脉冲的宽度来调节负载上的平均电压或功率。PWM技术的核心在于脉冲信号的调制,这涉及到开关器件(如晶体管)的开启与关闭的时间比例,即占空比的调整。在占空比增加的情况下,负载上的平均电压或功率也会相
【Python分布式系统精讲】:理解CAP定理和一致性协议,让你在面试中无往不利

# 1. 分布式系统的基础概念
分布式系统是由多个独立的计算机组成,这些计算机通过网络连接在一起,并共同协作完成任务。在这样的系统中,不存在中心化的控制,而是由多个节点共同工作,每个节点可能运行不同的软件和硬件资源。分布式系统的设计目标通常包括可扩展性、容错性、弹性以及高性能。
分布式系统的难点之一是各个节点之间如何协调一致地工作。
MATLAB机械手仿真并行计算:加速复杂仿真的实用技巧
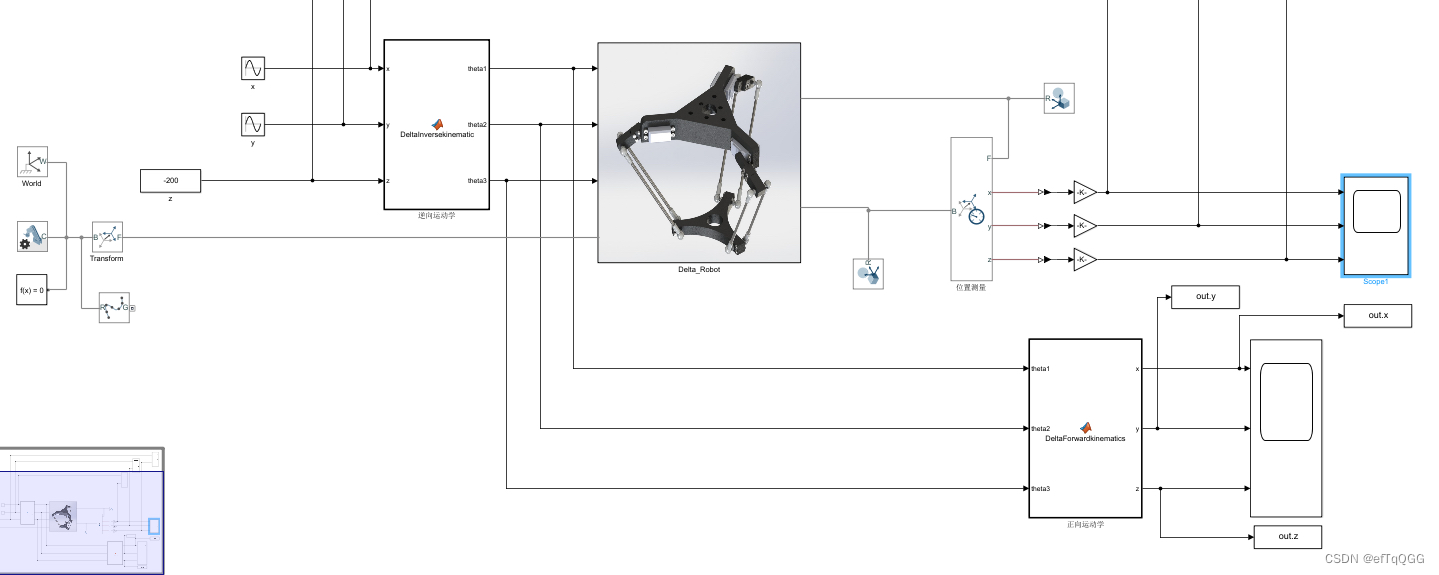
# 1. MATLAB机械手仿真基础
在这一章节中,我们将带领读者进入MATLAB机械手仿真的世界。为了使机械手仿真具有足够的实用性和可行性,我们将从基础开始,逐步深入到复杂的仿真技术中。
首先,我们将介绍机械手仿真的基本概念,包括仿真系统的构建、机械手的动力学模型以及如何使用MATLAB进行模型的参数化和控制。这将为后续章节中将要介绍的并行计算和仿真优化提供坚实的基础。
接下来,我
【趋势分析】:MATLAB与艾伦方差在MEMS陀螺仪噪声分析中的最新应用
# 1. MEMS陀螺仪噪声分析基础
## 1.1 噪声的定义和类型
在本章节,我们将对MEMS陀螺仪噪声进行初步探索。噪声可以被理解为任何影响测量精确度的信号变化,它是MEMS设备性能评估的核心问题之一。MEMS陀螺仪中常见的噪声类型包括白噪声、闪烁噪声和量化噪声等。理解这些噪声的来源和特点,对于提高设备性能至关重要。
数据库备份与恢复:实验中的备份与还原操作详解

# 1. 数据库备份与恢复概述
在信息技术高速发展的今天,数据已成为企业最宝贵的资产之一。为了防止数据丢失或损坏,数据库备份与恢复显得尤为重要。备份是一个预防性过程,它创建了数据的一个或多个副本,以备在原始数据丢失或损坏时可以进行恢复。数据库恢复则是指在发生故障后,将备份的数据重新载入到数据库系统中的过程。本章将为读者提供一个关于
【宠物管理系统权限管理】:基于角色的访问控制(RBAC)深度解析
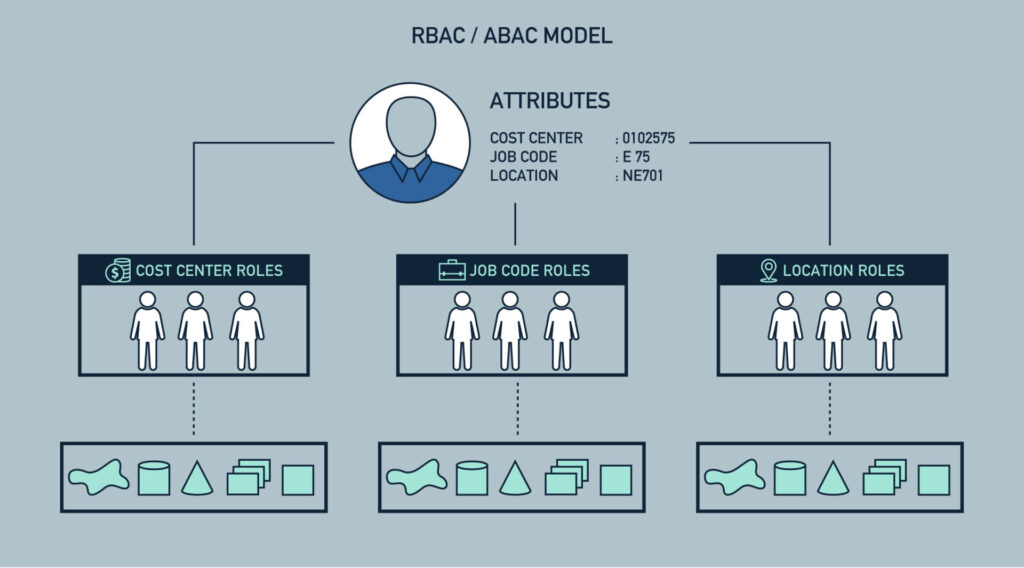
# 1. 基于角色的访问控制(RBAC)概述
在信息技术快速发展的今天,信息安全成为了企业和组织的核心关注点之一。在众多安全措施中,访问控制作为基础环节,保证了数据和系统资源的安全。基于角色的访问控制(Role-Based Access Control, RBAC)是一种广泛
【系统解耦与流量削峰技巧】:腾讯云Python SDK消息队列深度应用

# 1. 系统解耦与流量削峰的基本概念
## 1.1 系统解耦与流量削峰的必要性
在现代IT架构中,随着服务化和模块化的普及,系统间相互依赖关系越发复杂。系统解耦成为确保模块间低耦合、高内聚的关键技术。它不仅可以提升系统的可维护性,还可以增强系统的可用性和可扩展性。与
深入理解模块化编程:MATLAB模块库翻译与应用的核心概念

# 1. 模块化编程的基本原理
在软件工程领域,模块化编程被广泛采纳并视为创建可扩展、可维护软件的关键策略。它允许开发者将复杂系统分解为独立的功能模块,每个模块负责系统的一部分。这样,不仅使得代码的管理更为简单,还能够提高代码的复用性,降低系统整体的复杂度。
## 1.1 模块化编程的概念
模块化编程是将程序分解为独立、可替换的模块的一种编程范式。每个模块都有一组定义好的接口,通过这些接口与其它模块进行交互。这种方法的好处是,开发者可以独立地开发
【集成学习方法】:用MATLAB提高地基沉降预测的准确性

# 1. 集成学习方法概述
集成学习是一种机器学习范式,它通过构建并结合多个学习器来完成学习任务,旨在获得比单一学习器更好的预测性能。集成学习的核心在于组合策略,包括模型的多样性以及预测结果的平均或投票机制。在集成学习中,每个单独的模型被称为基学习器,而组合后的模型称为集成模型。该
【数据不平衡环境下的应用】:CNN-BiLSTM的策略与技巧

# 1. 数据不平衡问题概述
数据不平衡是数据科学和机器学习中一个常见的问题,尤其是在分类任务中。不平衡数据集意味着不同类别在数据集中所占比例相差悬殊,这导致模型在预测时倾向于多数类,从而忽略了少数类的特征,进而降低了模型的泛化能力。
## 1.1 数据不平衡的影响
当一个类别的样本数量远多于其他类别时,分类器可能会偏向于识别多数类,而对少数类的识别
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )