Mechanize内部机制大揭秘:网络请求的幕后原理
发布时间: 2024-10-05 22:04:31 阅读量: 17 订阅数: 22 

# 1. Mechanize简介与网络请求概述
在本章,我们将介绍Mechanize这个强大的库,它允许用户模拟浏览器的行为进行网页操作。Mechanize主要应用于自动化网页交互,尤其在网络爬虫和自动化测试领域中十分受欢迎。我们将从Mechanize的简介开始,简要概述它的工作原理,然后介绍网络请求的基础知识,为后续章节中深入探讨Mechanize的高级功能和实际应用打下坚实的基础。
接下来,我们会了解到Mechanize的基本功能,比如如何发起网页请求、获取响应内容以及模拟表单提交等。为了进一步理解网络请求,我们还会介绍HTTP协议的基本概念,这将帮助我们更好地理解Mechanize如何与服务器进行通信。本章的目标是为读者提供一个关于Mechanize和网络请求的概览,并为后续章节深入探讨其工作原理、优化技巧和案例实践做好铺垫。
## 1.1 Mechanize简介
Mechanize是一个在Ruby编程语言中广泛使用的库,它提供了一种方便的方式来进行复杂的网页交互。通过Mechanize,开发者可以模拟用户的行为,比如点击链接、填写表单以及抓取网页内容等。Mechanize特别适用于需要进行大量网页数据交互的自动化任务,如网络爬虫、自动化测试和Web数据采集等。
## 1.2 网络请求基础
网络请求是客户端与服务器之间的通信方式,是互联网应用的基石。在Mechanize中,所有操作都始于一个网络请求。Mechanize使用HTTP(超文本传输协议)来发送请求并接收响应。HTTP协议是无状态的,这意味着服务器不会保留任何关于客户端请求的状态信息。为了维护会话状态,Mechanize提供了对Cookies的支持,使得能够在多个请求之间保持登录状态或其它会话数据。
通过Mechanize库,可以很容易地构建出包含各种HTTP头部的请求,并通过提供的方法来处理来自服务器的响应。例如,Mechanize可以设置请求头,如User-Agent来模拟不同类型的浏览器,或者是接受压缩的响应以减少数据传输量等。Mechanize还能够处理重定向,遵循HTTP和HTTPS之间的链接跳转,并且可以通过设置代理来访问那些可能限制直接连接的网站。
# 2. Mechanize工作原理深度剖析
在第二章中,我们将深入探讨Mechanize的工作原理,揭示其背后的架构设计、HTTP协议交互方式以及网络连接的管理策略。理解这些核心概念,对于有效地使用Mechanize和提升网络爬虫效率至关重要。
## 2.1 Mechanize的架构设计
### 2.1.1 Mechanize的内部组件解析
Mechanize作为一个网络爬虫库,其架构设计允许用户以类似浏览器的方式与网页交互。Mechanize的内部组件主要包括用户代理(User Agent)管理器、Cookie管理器、会话(Session)管理器、请求(Request)和响应(Response)处理器等。
每个组件都有特定的职责,如用户代理管理器负责维护和发送HTTP请求头中的User-Agent字段;Cookie管理器负责处理网站返回的Set-Cookie响应头,并在后续的请求中附带相应的Cookie信息;会话管理器维护连接状态,保持用户登录状态等。
通过这些组件的协同工作,Mechanize能够模拟真实用户的网络行为,从而在进行网页数据抓取和分析时,表现得更像是一个正常用户而非机器人。
### 2.1.2 请求与响应的处理流程
Mechanize的请求与响应处理流程遵循典型的HTTP协议交互模式。当用户通过Mechanize发出请求时,请求首先会经过用户代理管理器进行User-Agent信息的添加,然后请求会被发送至服务器。
服务器响应后,响应数据包首先由Mechanize的响应处理器进行解析。响应处理器负责解析HTTP头信息,包括状态码、内容类型、内容长度等,并提取出实际的响应内容,如HTML、JSON或XML数据。然后将这些内容传递给相应的解析器进行进一步的数据提取和分析。
请求和响应处理流程的设计,使得Mechanize用户可以更专注于数据抓取的逻辑,而不必深入细节处理HTTP通信的具体实现。
```python
# 示例代码块:Mechanize发起请求并获取响应
from mechanize import Browser
br = Browser()
response = br.open('***')
# 代码逻辑解读
# 首先创建了一个Browser对象,这是Mechanize中用于模拟浏览器行为的核心对象。
# 使用br.open方法发起对指定URL的GET请求。该方法内部实现了完整的请求和响应处理流程。
# 返回的response对象包含了HTTP响应的所有信息,例如响应头和响应体。
```
## 2.2 HTTP协议与Mechanize的交互方式
### 2.2.1 HTTP请求的构建
Mechanize构建HTTP请求的过程涉及多个组件的协同。用户通过简单的方法调用(如`.open(url)`),Mechanize会自动构建一个符合HTTP规范的请求消息。在这个过程中,Mechanize会添加必要的请求头,如Host、Accept、Accept-Encoding等。
请求消息的构建不仅限于头部信息,还可能包括表单数据、文件上传等。Mechanize提供了友好的API来支持这些操作,如通过`form`方法填写表单数据并提交。
```python
# 示例代码块:Mechanize填写并提交表单
from mechanize import Browser
br = Browser()
br.open('***')
br.form['username'] = 'user123'
br.form['password'] = 'mypassword'
response = br.submit()
# 代码逻辑解读
# 打开一个登录页面,并定位到登录表单。
# 填写表单中的用户名和密码字段。
# 使用br.submit()方法提交表单,Mechanize会构建带有必要信息的HTTP POST请求。
```
### 2.2.2 HTTP响应的解析
在Mechanize获取到HTTP响应后,响应处理器会按照标准的HTTP协议规范解析响应头和响应体。响应头中包含了响应的状态码、内容类型、内容长度等关键信息。响应体通常是请求资源的内容,如HTML文档、JSON或XML数据。
Mechanize提供了强大的解析功能,能够解析HTML文档并允许用户以DOM树的方式操作网页元素。例如,使用Mechanize可以方便地导航、查找或修改网页内的元素。
### 2.2.3 请求头和响应头的管理
请求头和响应头的管理是Mechanize与HTTP协议交互的重要组成部分。Mechanize允许用户自定义请求头,通过设置请求头可以模拟特定类型的浏览器访问、处理缓存策略、管理内容编码等。
同时,Mechanize还提供了获取和处理响应头的能力。响应头中可能包含重要的信息,如重定向地址、字符集编码、Cookie等,Mechanize能够让用户轻松访问这些信息并作出相应处理。
## 2.3 网络连接的管理
### 2.3.1 连接池的工作机制
Mechanize在网络连接管理方面使用了连接池技术。连接池是预先创建并维护一定数量的服务器连接,这样可以避免为每个HTTP请求建立新连接的开销。连接池中可用的连接被复用,从而提高网络请求的效率。
Mechanize通过连接池机制实现了对网络连接的高效管理,减少了连接的建立和关闭时间,特别是在高并发请求的场景中,能够显著提高性能。
### 2.3.2 SSL/TLS加密通信的实现
Mechanize支持SSL/TLS加密通信,即通过HTTPS协议与服务器进行安全的数据传输。Mechanize内部集成了对SSL/TLS握手、证书验证等加密通信关键步骤的支持,保障了用户数据传输的安全性。
在SSL/TLS握手过程中,Mechanize会验证服务器的SSL证书,确保通信双方身份的合法性。此外,Mechanize还会使用会话密钥进行加密通信,从而防止敏感数据在传输过程中被窃取或篡改。
### 2.3.3 连接复用与重用策略
连接复用与重用策略是提高网络爬虫效率的关键。Mechanize通过维护一个活跃的连接池来实现这一策略,池中的每个连接都是一个已经建立的TCP连接。
在连接复用中,Mechanize会尽可能重用池中的连接来处理新的请求。这不仅减少了连接建立的延迟,还减少了资源消耗,因为维护一个活动连接比频繁建立和销毁连接要高效得多。
```mermaid
graph LR
A[发起请求] --> B{检查连接池}
B -->|找到可用连接| C[复用现有连接]
B -->|无可用连接| D[创建新连接]
C --> E[发送请求]
D --> E
E --> F[接收响应]
F --> G{响应是否有效}
G -->|是| H[将连接返回连接池]
G -->|否| I[关闭连接]
H --> J[结束]
I --> J
```
在上述流程图中,Mechanize在处理请求时首先检查连接池中是否有可用的连接。如果有,就直接复用这些连接;如果没有,才会创建新的连接。发送请求后,Mechanize根据响应的有效性决定是将连接放回连接池还是关闭连接。
通过以上章节的讲解,我们可以看到Mechanize在工作原理上的深度剖析,包括其架构设计、与HTTP协议的交互方式以及网络连接的管理策略。这些高级概念的理解有助于我们更好地利用Mechanize执行复杂的网络爬虫任务,并且提升程序的效率和稳定性。在下一章节,我们将探讨Mechanize在实战中的技巧应用,以及如何通过这些技巧来抓取网页数据、处理表单提交和优化性能。
# 3. Mechanize的网络爬虫实战技巧
随着互联网信息的指数级增长,网络爬虫已经成为了数据采集、处理与分析的重要手段。Mechanize作为一个功能强大的网络爬虫库,为Python开发者提供了友好的API来模拟浏览器行为,获取网页内容。本章节将深入探讨Mechanize在网络爬虫领域的实战技巧。
## 3.1 网页数据抓取与解析
### 3.1.1 HTML内容的解析方法
网页数据抓取的基石是对HTML内容的解析。Mechanize提供了简单直观的方式来访问和处理网页元素。使用`mechanize.Browser`对象,开发者可以加载网页,并通过`link`、`form`等方法来获取特定的元素。
```python
import mechanize
br = mechanize.Browser()
br.open('***')
# 获取页面中的第一个链接
link = br.links()[0]
print(link.text, link.url)
```
在上述代码中,我们首先创建了一个`Browser`对象,然后使用`open`方法加载了目标网页。通过`links`方法,我们可以获取页面中所有的链接对象,并通过索引访问特定链接。`link.text`和`link.url`分别提供了链接的文本内容和URL地址。
### 3.1.2 JSON和XML数据的处理
随着Web API的普及,JSON和XML成为了网络数据交换的主要格式。Mechanize支持解析和处理这两种数据格式。
对于JSON数据,Python的内置`json`模块提供了简单有效的处理方法。通过Mechanize获取的数据可以轻松地转换为Python对象。
```python
import json
# 假设从某个API获取到了JSON数据
json_data = '{"name": "John", "age": 30}'
data = json.loads(json_data)
print(data['name'], data['age'])
```
对于XML数据,可以使用`xml.etree.ElementTree`模块。Mechanize能够处理那些被网页动态加载的内容,如AJAX调用返回的XML数据。
```python
import xml.etree.ElementTree as ET
# 假设从某个API获取到了XML数据
xml_data = '<user><name>John</name><age>30</age></user>'
root = ET.fromstring(xml_data)
name = root.find('name').text
age = roo
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python Mechanize 库,一个功能强大的网络抓取和自动化工具。它涵盖了从基础到高级的各种主题,包括表单提交、会话管理、错误处理、网络数据处理和定制用户代理字符串。通过深入的教程、示例和技巧,本专栏旨在帮助开发人员充分利用 Mechanize 库,轻松应对复杂的网络交互,自动化测试流程,并有效处理网络数据。无论你是 Python 新手还是经验丰富的开发人员,本专栏都将为你提供宝贵的见解和实用的指南,帮助你提升你的网络自动化技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ggpubr包在金融数据分析中的应用:图形与统计的完美结合

# 1. ggpubr包与金融数据分析简介
在金融市场中,数据是决策制定的核心。ggpubr包是R语言中一个功能强大的绘图工具包,它在金融数据分析领域中提供了一系列直观的图形展示选项,使得金融数据的分析和解释变得更加高效和富有洞察力。
本章节将简要介绍ggpubr包的基本功能,以及它在金融数据分析中的作
【R语言qplot深度解析】:图表元素自定义,探索绘图细节的艺术(附专家级建议)

# 1. R语言qplot简介和基础使用
## qplot简介
`qplot` 是 R 语言中 `ggplot2` 包的一个简单绘图接口,它允许用户快速生成多种图形。`qplot`(快速绘图)是为那些喜欢使用传统的基础 R 图形函数,但又想体验 `ggplot2` 绘图能力的用户设
R语言中的数据可视化工具包:plotly深度解析,专家级教程

# 1. plotly简介和安装
Plotly是一个开源的数据可视化库,被广泛用于创建高质量的图表和交互式数据可视化。它支持多种编程语言,如Python、R、MATLAB等,而且可以用来构建静态图表、动画以及交互式的网络图形。
## 1.1 plotly简介
Plotly最吸引人的特性之一
文本挖掘中的词频分析:rwordmap包的应用实例与高级技巧

# 1. 文本挖掘与词频分析的基础概念
在当今的信息时代,文本数据的爆炸性增长使得理解和分析这些数据变得至关重要。文本挖掘是一种从非结构化文本中提取有用信息的技术,它涉及到语言学、统计学以及计算技术的融合应用。文本挖掘的核心任务之一是词频分析,这是一种对文本中词汇出现频率进行统计的方法,旨在识别文本中最常见的单词和短语。
词频分析的目的不仅在于揭
ggthemes包热图制作全攻略:从基因表达到市场分析的图表创建秘诀
# 1. ggthemes包概述和安装配置
## 1.1 ggthemes包简介
ggthemes包是R语言中一个非常强大的可视化扩展包,它提供了多种主题和图表风格,使得基于ggplot2的图表更为美观和具有专业的视觉效果。ggthemes包包含了一系列预设的样式,可以迅速地应用到散点图、线图、柱状图等不同的图表类型中,让数据分析师和数据可视化专家能够快速产出高质量的图表。
## 1.2 安装和加载ggthemes包
为了使用ggthemes包,首先需要在R环境中安装该包。可以使用以下R语言命令进行安装:
```R
install.packages("ggthemes")
```
R语言动态图形:使用aplpack包创建动画图表的技巧
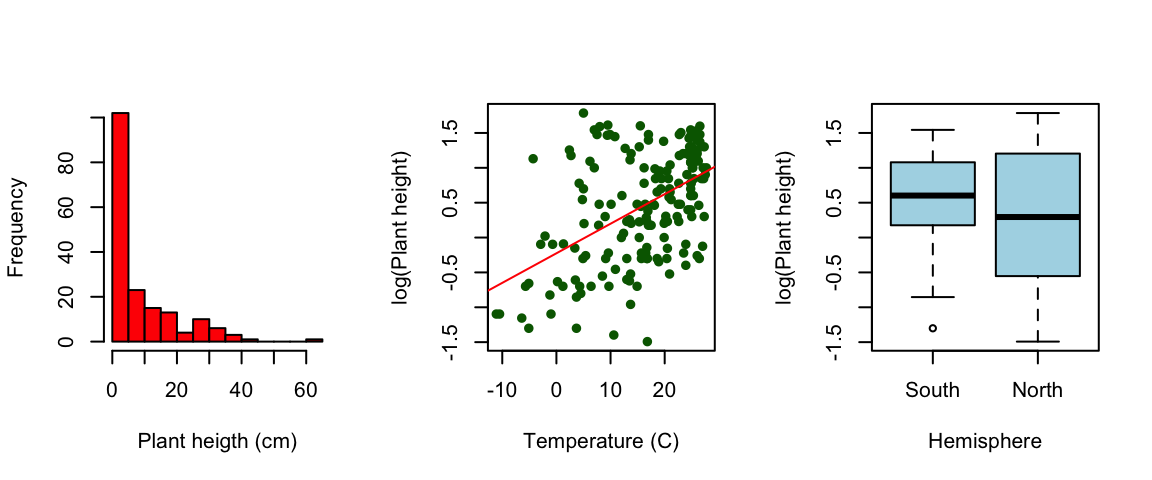
# 1. R语言动态图形简介
## 1.1 动态图形在数据分析中的重要性
在数据分析与可视化中,动态图形提供了一种强大的方式来探索和理解数据。它们能够帮助分析师和决策者更好地追踪数据随时间的变化,以及观察不同变量之间的动态关系。R语言,作为一种流行的统计计算和图形表示语言,提供了丰富的包和函数来创建动态图形,其中apl
【lattice包与其他R包集成】:数据可视化工作流的终极打造指南

# 1. 数据可视化与R语言概述
数据可视化是将复杂的数据集通过图形化的方式展示出来,以便人们可以直观地理解数据背后的信息。R语言,作为一种强大的统计编程语言,因其出色的图表绘制能力而在数据科学领域广受欢迎。本章节旨在概述R语言在数据可视化中的应用,并为接下来章节中对特定可视化工具包的深入探讨打下基础。
在数据科学项目中,可视化通
ggmap包在R语言中的应用:定制地图样式的终极教程

# 1. ggmap包基础介绍
`ggmap` 是一个在 R 语言环境中广泛使用的包,它通过结合 `ggplot2` 和地图数据源(例如 Google Maps 和 OpenStreetMap)来创建强大的地图可视化。ggmap 包简化了地图数据的获取、绘图及修改过程,极大地丰富了 R 语言在地理空间数据分析
数据可视化的艺术:ggtech包在行业报告中的极致应用
# 1. 数据可视化的基础知识
在数据科学领域,数据可视化是不可或缺的组成部分,它使得复杂的数据集得以通过图形化的方式展现出来,为分析和理解数据提供了直观的途径。本章将带你进入数据可视化的世界,概述其核心概念,帮助你建立扎实的理论基础。
## 1.1 数据可视化的定义和目的
数据可视化是一个将数据转化为图形元素(例如点、线、面积)的过程
【R语言数据包googleVis性能优化】:提升数据可视化效率的必学技巧
# 1. R语言与googleVis简介
在当今的数据科学领域,R语言已成为分析和可视化数据的强大工具之一。它以其丰富的包资源和灵活性,在统计计算与图形表示上具有显著优势。随着技术的发展,R语言社区不断地扩展其功能,其中之一便是googleVis包。googleVis包允许R用户直接利用Google Char
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )