【Go语言JSON互操作性】:探索JSON与XML数据转换的深度实践
发布时间: 2024-10-19 23:25:22 阅读量: 17 订阅数: 12 
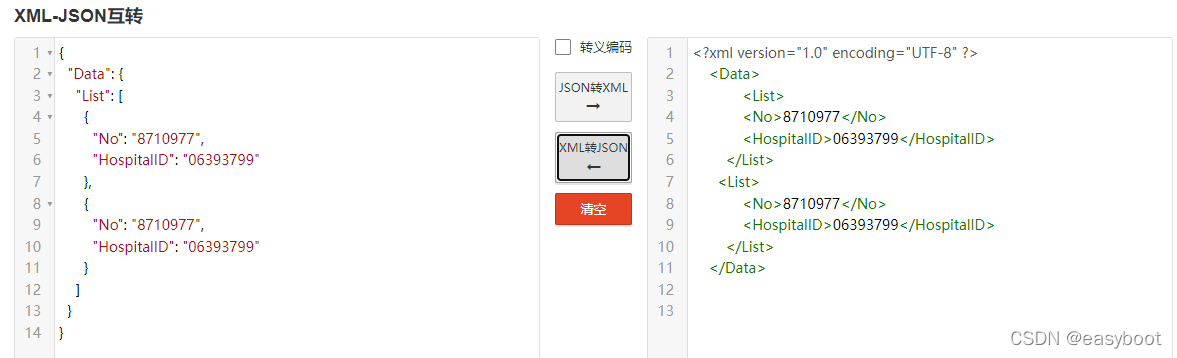
# 1. Go语言与JSON概述
Go语言,作为云计算和微服务时代的一个重要工具,其语言设计简洁高效,对JSON的支持也尤为出色。JSON,即JavaScript Object Notation,是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。本章将介绍Go语言与JSON的基本概念,并探讨它们之间如何相互作用和转换。
JSON在Web开发中被广泛用于前后端之间的数据传输,而Go语言提供了强大的标准库支持,让开发者能够轻松地编码和解码JSON数据。我们将从Go语言如何处理JSON数据开始,逐步深入到JSON数据模型的基础,以及如何在Go中通过结构体实现JSON数据的序列化与反序列化。
简单来说,本章旨在让读者了解Go与JSON的基础,为后续章节学习结构体与JSON的映射以及数据处理技巧打下坚实的基础。在接下来的章节中,我们将深入探讨如何在Go语言中将复杂的数据结构编码为JSON,以及如何将JSON数据解析为Go语言中的结构体,进而实现复杂的数据处理和转换技巧。
# 2. JSON数据模型与结构体映射
## 2.1 JSON数据模型基础
### 2.1.1 JSON数据类型解析
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript的一个子集,但是JSON是独立于语言的文本格式。在JSON中,数据模型包含了以下几种类型:
- **对象(Object)**:以大括号`{}`表示,包含一系列的键值对。键(Key)由双引号`""`包围,而值(Value)可以是字符串、数字、布尔值、null、数组或另一个对象。
- **数组(Array)**:以中括号`[]`表示,包含有序的元素列表,元素可以是任意类型。
- **字符串(String)**:由双引号`""`包围的字符序列,可以包含特殊字符,如转义字符`\`。
- **数值(Number)**:包含整数和浮点数(科学记数法),不包含分数或八进制、十六进制。
- **布尔值(Boolean)**:真(true)或假(false)。
- **null**:表示空值或无值。
### 2.1.2 JSON数据结构理解
在理解JSON数据结构时,重点在于理解对象和数组这两种复合类型。对象可以看作是一个字典或映射,而数组则是一个有序的列表。在JSON中,这两个复合类型的嵌套使用非常常见,可以构建出复杂的数据结构。
理解JSON结构的关键点在于:
- **层级性**:JSON结构通常是层级化的,对象可以嵌套对象,数组可以包含数组,形成了多层的数据结构。
- **键值对**:对象由一系列键值对构成,这种键值对结构是JSON解析和生成的基础。
- **数据类型灵活**:JSON支持多种数据类型的组合,可以灵活地表示复杂的数据关系。
## 2.2 Go语言中的结构体与JSON转换
### 2.2.1 结构体定义与标签使用
Go语言中的结构体(Struct)类型是创建复杂类型数据的基础,与JSON中对象的概念有很强的对应关系。在Go中,定义结构体需要使用`type`关键字,然后指定名称和字段。
```go
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Address string `json:"address"`
}
```
在上面的例子中,`Person`结构体有三个字段:`Name`、`Age`和`Address`。通过在字段后使用反引号(`)并定义一个`json`标签,可以指定当使用`encoding/json`包对`Person`类型的实例进行JSON编码或解码时,对应的JSON字段名称。
### 2.2.2 编码与解码过程剖析
Go语言的`encoding/json`包提供了对JSON数据进行编码(将Go对象转换为JSON)和解码(将JSON转换为Go对象)的功能。编码过程通常包括将一个Go结构体实例转换为JSON格式的字节切片,而解码过程则是相反的操作。
```go
import (
"encoding/json"
"fmt"
)
func main() {
person := Person{Name: "John Doe", Age: 30, Address: "123 Baker St"}
// 编码过程
jsonData, err := json.Marshal(person)
if err != nil {
fmt.Println("JSON marshaling failed:", err)
return
}
fmt.Println(string(jsonData))
// 假设从某处获得了JSON数据
jsonStr := `{"name": "John Doe", "age": 30, "address": "123 Baker St"}`
var decodedPerson Person
// 解码过程
err = json.Unmarshal([]byte(jsonStr), &decodedPerson)
if err != nil {
fmt.Println("JSON unmarshaling failed:", err)
return
}
fmt.Println(decodedPerson.Name)
}
```
在这个例子中,`json.Marshal`函数用于将`Person`结构体编码为JSON,而`json.Unmarshal`函数用于将JSON字符串解码为`Person`结构体。
### 2.2.3 处理嵌套结构体与JSON
嵌套结构体与JSON的转换更为复杂,但是Go语言的`encoding/json`包提供了很好的支持。当一个结构体字段本身是另一个结构体时,该字段会以嵌套对象的形式出现在JSON中。
```go
type Address struct {
Street string `json:"street"`
City string `json:"city"`
}
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Address Address `json:"address"`
}
// 假设addressJSON是地址信息的JSON字符串
var addressJSON = `{"street": "123 Baker St", "city": "London"}`
var address Address
err := json.Unmarshal([]byte(addressJSON), &address)
if err != nil {
log.Fatal(err)
}
// 现在address包含了反序列化的地址信息
```
处理嵌套结构体时,只需确保结构体定义正确,并在解码过程中使用正确的类型即可。每个嵌套的结构体都将转换为JSON中的一个对象。
在本章节中,我们深入探讨了JSON数据模型的基础知识,以及Go语言结构体与JSON数据之间的映射机制,包括结构体的定义、编码解码过程以及嵌套结构体的处理。以上内容为读者打下了坚实的基础,以理解和掌握Go语言在处理JSON数据方面的关键技术和策略。接下来的章节,将进一步介绍JSON数据处理实战技巧,涉及高级用法和实际应用案例。
# 3. ```
# 第三章:JSON数据处理实战技巧
## 3.1 JSON数据序列化与反序列化的高级用法
### 自定义序列化与反序列化规则
Go语言标准库中的`encoding/json`包提供了强大的JSON处理能力,但在某些特殊情况下,标准的序列化和反序列化功能可能不足以满足需求。自定义序列化与反序列化的规则成为了进阶开发者必须掌握的技能。
自定义序列化规则允许开发者在将Go语言的结构体转换为JSON字符串时,对结构体成员的处理施加更多的控制。例如,当需要忽略某个字段,或者需要对字段进行特定的格式转换时,可以使用`json.Marshaler`接口或者结构体字段的`json.MarshalJSON`方法来实现。
```go
type CustomTime time.Time
func (ct *CustomTime) MarshalJSON() ([]byte, error) {
// 自定义时间格式
st := time.Time(*ct).Format("2006-01-02 15:04:05")
return json.Marshal(st)
}
```
在上面的代码中,`CustomTime`类型实现了`MarshalJSON`方法,自定义了时间的序列化格式。类似地,也可以实现`UnmarshalJSON`方法来自定义反序列化的行为。
### 大数据量的JSON处理技巧
在处理大规模数据时,常见的挑战包括内存的使用和处理速度。Go语言提供了一些机制来帮助我们优化这类处理。
为了避免一次性将整个JSON文件加载到内存,可以利用`json.Decoder`来边读取边解析JSON数据。
```go
func processLargeJSON(r io.Reader) error {
decoder := json.NewDecoder(r)
for decoder.More() {
var v interface{}
if err := decoder.Decode(&v); err != nil {
return err
}
// 处理每个解析出来的JSON对象
}
return nil
}
```
上面的代码展示了如何逐个对象处理大型JSON数据流,从而减少内存消耗。另外,使用`io.LimitedReader`可以限制解码器读取的字节数,防止内存溢出。
## 3.2 JSON数据校验与验证
### 校验JSON数据结构的正确性
在接收到JSON数据后,第一步往往是验证其结构是否符合预期。这可以确保后续的处理逻辑不会因为非法的输入数据而出错。
JSON Schema 是一种验证JSON数据结构的规范,可以指定JSON数据必须遵循的结构、数据类型等。Go语言中可以使用第三方库如`gojsonschema`来进行JSON Schema校验。
```go
import jsonschema "***/alecthomas/jsonschema"
func validateSchema(data []byte, schema []byte) (*jsonschema.Result, error) {
result := &jsonschema.Result{}
err := jsonschema.ValidateBytes(result, data, schema)
return result, err
}
```
上面的代码利用`jsonschema`库校验数据与预定义的JSON Schema。
### 验证JSON数据与结构体映射的准确性
在将JSON数据映射到Go语言结构体后,一个常见的需求是校验映射是否准确无误。这可以通过比较结构体和JSON中的字段来完成。
```go
func validateMapping(data []byte, v interface{}) error {
expectedType := reflect.TypeOf(v).Elem()
for i := 0; i < expectedType.NumField(); i++ {
field := expectedType.Field(i)
// 使用反射获取结构体字段的值和标签
}
// 实现更复杂的映射校验逻辑
return nil
}
```
上述代码仅提供一个框架,具体实现需要根据结构体的定义来编写。
### 校验JSON数据结构的正确性
在处理JSON数据时,经常需要验证数据的结构是否符合预期。这可以通过定义JSON Schema
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地探讨了 Go 语言中的 JSON 处理,从入门级技巧到高级策略。它涵盖了以下关键主题:
* JSON 处理的最佳实践,确保安全和高效的数据处理
* JSON 与 XML 数据之间的互操作性,实现无缝转换
* 构建 RESTful API 的 JSON 处理案例研究
* 创建可复用编解码器的技巧,简化 JSON 解析和序列化
* 与数据库交互的高效 JSON 序列化实践
* 嵌套对象和 null 值处理的深入理解
* 编写健壮的 JSON 编解码器,提高代码可靠性
通过深入的解释、代码示例和实践技巧,本专栏为 Go 开发人员提供了全面指南,帮助他们掌握 JSON 处理,并将其应用于各种应用程序中。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
支持向量机在语音识别中的应用:挑战与机遇并存的研究前沿

# 1. 支持向量机(SVM)基础
支持向量机(SVM)是一种广泛用于分类和回归分析的监督学习算法,尤其在解决非线性问题上表现出色。SVM通过寻找最优超平面将不同类别的数据有效分开,其核心在于最大化不同类别之间的间隔(即“间隔最大化”)。这种策略不仅减少了模型的泛化误差,还提高了模型对未知数据的预测能力。SVM的另一个重要概念是核函数,通过核函数可以将低维空间线性不可分的数据映射到高维空间,使得原本难以处理的问题变得易于
从GANs到CGANs:条件生成对抗网络的原理与应用全面解析
.jpg)
# 1. 生成对抗网络(GANs)基础
生成对抗网络(GANs)是深度学习领域中的一项突破性技术,由Ian Goodfellow在2014年提出。它由两个模型组成:生成器(Generator)和判别器(Discriminator),通过相互竞争来提升性能。生成器负责创造出逼真的数据样本,判别器则尝试区分真实数据和生成的数据。
## 1.1 GANs的工作原理
神经网络硬件加速秘技:GPU与TPU的最佳实践与优化

# 1. 神经网络硬件加速概述
## 1.1 硬件加速背景
随着深度学习技术的快速发展,神经网络模型变得越来越复杂,计算需求显著增长。传统的通用CPU已经难以满足大规模神经网络的计算需求,这促使了
K-近邻算法多标签分类:专家解析难点与解决策略!

# 1. K-近邻算法概述
K-近邻算法(K-Nearest Neighbors, KNN)是一种基本的分类与回归方法。本章将介绍KNN算法的基本概念、工作原理以及它在机器学习领域中的应用。
## 1.1 算法原理
KNN算法的核心思想非常简单。在分类问题中,它根据最近的K个邻居的数据类别来进行判断,即“多数投票原则”。在回归问题中,则通过计算K个邻居的平均
市场营销的未来:随机森林助力客户细分与需求精准预测

# 1. 市场营销的演变与未来趋势
市场营销作为推动产品和服务销售的关键驱动力,其演变历程与技术进步紧密相连。从早期的单向传播,到互联网时代的双向互动,再到如今的个性化和智能化营销,市场营销的每一次革新都伴随着工具、平台和算法的进化。
## 1.1 市场营销的历史沿
RNN可视化工具:揭秘内部工作机制的全新视角

# 1. RNN可视化工具简介
在本章中,我们将初步探索循环神经网络(RNN)可视化工具的核心概念以及它们在机器学习领域中的重要性。可视化工具通过将复杂的数据和算法流程转化为直观的图表或动画,使得研究者和开发者能够更容易理解模型内部的工作机制,从而对模型进行调整、优化以及故障排除。
## 1.1 RNN可视化的目的和重要性
可视化作为数据科学中的一种强
【提升模型选择】:梯度提升与AdaBoost比较,做出明智决策
# 1. 梯度提升与AdaBoost算法概述
机器学习领域中,集成学习算法是提高预测性能的重要手段之一。梯度提升(Gradient Boosting)和AdaBoost是两种广泛使用的集成学习算法,它们通过结合多个弱学习器来构建强大的预测模型。在本章中,我们将简要介绍这两种算法的基础概念和区别,为后续章节的深入分析和实践应用奠定基础。
## 1.1 梯度提升算法概述
梯度提升是一种优化技术,它通过迭代地添加弱学习器,并专注于之前学习器预测错误的地方,以此来提升整体模型的性能。该算法的核心是将损失函数的负梯度作为目标函数,通过优化目标函数得到下一个弱学习器的权重和参数。
## 1.2 A
细粒度图像分类挑战:CNN的最新研究动态与实践案例

# 1. 细粒度图像分类的概念与重要性
随着深度学习技术的快速发展,细粒度图像分类在计算机视觉领域扮演着越来越重要的角色。细粒度图像分类,是指对具有细微差异的图像进行准确分类的技术。这类问题在现实世界中无处不在,比如对不同种类的鸟、植物、车辆等进行识别。这种技术的应用不仅提升了图像处理的精度,也为生物多样性
XGBoost时间序列分析:预测模型构建与案例剖析
# 1. 时间序列分析与预测模型概述
在当今数据驱动的世界中,时间序列分析成为了一个重要领域,它通过分析数据点随时间变化的模式来预测未来的趋势。时间序列预测模型作为其中的核心部分,因其在市场预测、需求计划和风险管理等领域的广泛应用而显得尤为重要。本章将简单介绍时间序列分析与预测模型的基础知识,包括其定义、重要性及基本工作流程,为读者理解后续章节内容打下坚实基础。
# 2. XGB
LSTM在语音识别中的应用突破:创新与技术趋势

# 1. LSTM技术概述
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),它能够学习长期依赖信息。不同于标准的RNN结构,LSTM引入了复杂的“门”结构来控制信息的流动,这允许网络有效地“记住”和“遗忘”信息,解决了传统RNN面临的长期依赖问题。
## 1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )