【Go语言JSON处理秘籍】:从入门到精通的20个实用技巧
发布时间: 2024-10-19 23:08:06 阅读量: 15 订阅数: 12 
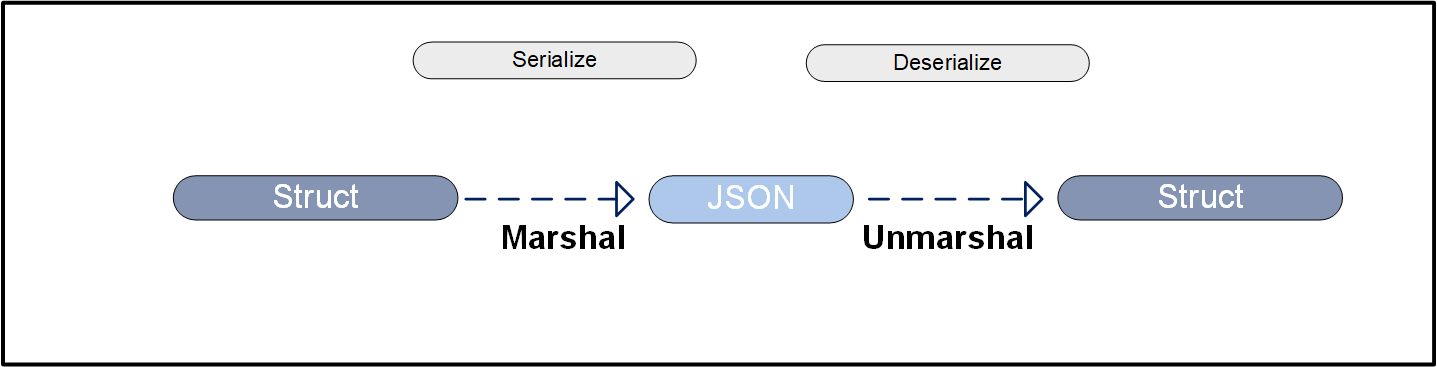
# 1. Go语言与JSON的基本概念
## 1.1 Go语言简介
Go语言(又称Golang)是由Google开发的一种静态类型、编译型语言,具有高效的性能与简洁的语法。它适合用来编写服务器端程序,因其快速、简洁、安全,常被用于微服务架构中。Go语言在处理并发方面表现出色,内置的goroutines和channels机制,让并发编程变得简单高效。
## 1.2 JSON概述
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。JSON基于JavaScript的数组和对象表示法,并且在多数编程语言中都有现成的解析器。它在Web应用中广泛用于客户端与服务器之间的数据传输。
## 1.3 Go语言与JSON的关联
Go语言标准库中的`encoding/json`包为处理JSON提供了完备的支持,包括解析JSON数据到Go语言数据结构,以及将Go数据结构编码为JSON格式。本章将详细探讨Go语言如何处理JSON数据,从基本的解析和生成开始,进而深入高级技术,如流式处理、自定义类型序列化和性能优化等。
# 2. 解析与生成JSON数据
### 2.1 Go语言中的JSON解析基础
#### 2.1.1 json包解析JSON数据
Go语言的`encoding/json`包提供了一套标准的方式来解析和生成JSON数据。当我们从外部源(如HTTP请求或文件)接收到JSON格式的数据时,我们可以利用Go的json包来轻松地将其转换成对应的Go语言数据结构。
```go
import (
"encoding/json"
"fmt"
"log"
)
func main() {
var data = []byte(`{"name":"John", "age":30, "city":"New York"}`)
var dat map[string]interface{}
err := json.Unmarshal(data, &dat)
if err != nil {
log.Fatalf("JSON unmarshaling failed: %s", err)
}
fmt.Printf("%#v\n", dat)
}
```
在这段代码中,`json.Unmarshal`函数接受一个JSON编码的数据切片(`[]byte`类型)以及一个指向目标变量的指针,目标变量是一个空接口`interface{}`类型,这意味着它可以接受任何类型的值。由于我们不知道JSON对象的具体结构,所以使用`map[string]interface{}`来动态接收数据,这个类型可以存储任意类型值的键值对。
如果解析成功,`dat`变量将包含解析后的数据,我们可以按照键值对的方式访问数据。
#### 2.1.2 结构体标签与JSON键映射
在Go中,我们经常使用结构体(`struct`)来表示复杂的数据类型。为了将结构体与JSON进行互操作,Go提供了一种机制来映射结构体字段和JSON对象的键。
```go
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
City string `json:"city"`
}
func main() {
var data = []byte(`{"name":"John", "age":30, "city":"New York"}`)
var person Person
err := json.Unmarshal(data, &person)
if err != nil {
log.Fatalf("JSON unmarshaling failed: %s", err)
}
fmt.Printf("%#v\n", person)
}
```
在上面的代码段中,`Person`结构体通过结构体标签(即反引号内的内容)明确指定了每个字段对应的JSON键。如此一来,`json.Unmarshal`可以直接根据这些标签将JSON数据解码到结构体的字段中。这种映射关系非常直观,有助于在维护代码时保持JSON字段与结构体字段同步。
### 2.2 JSON数据的生成与格式化
#### 2.2.1 使用结构体生成JSON
将Go语言的数据结构转换成JSON格式,可以使用`json.Marshal`函数。下面的示例将展示如何将一个结构体编码为JSON格式的字节切片。
```go
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
City string `json:"city"`
}
func main() {
person := Person{Name: "John", Age: 30, City: "New York"}
data, err := json.Marshal(person)
if err != nil {
log.Fatalf("JSON marshaling failed: %s", err)
}
fmt.Println(string(data))
}
```
在这个示例中,`Person`实例被编码为一个JSON字符串。输出结果将是`{"name":"John","age":30,"city":"New York"}`。`json.Marshal`会返回一个`[]byte`类型的数据切片,我们使用`string`函数将其转换为字符串以便查看结果。
#### 2.2.2 自定义JSON序列化输出
Go允许我们通过实现`json.Marshaler`接口来自定义类型的具体JSON序列化行为。这样,我们可以控制结构体中数据的格式化输出。
```go
type Person struct {
Name string
Age int
City string
}
func (p Person) MarshalJSON() ([]byte, error) {
return json.Marshal(struct {
Firstname string `json:"firstname"`
Surname string `json:"surname"`
Age int `json:"age"`
City string `json:"city"`
}{p.Name, p.Name, p.Age, p.City})
}
func main() {
person := Person{Name: "John", Age: 30, City: "New York"}
data, err := json.Marshal(person)
if err != nil {
log.Fatalf("JSON marshaling failed: %s", err)
}
fmt.Println(string(data))
}
```
在这个示例中,`Person`类型实现了`MarshalJSON`方法。它创建了一个匿名结构体,并在该方法中显式地指定了要序列化的字段。这允许我们改变JSON输出中的键名称,或者重新组织数据结构的序列化过程。
### 2.3 高级解析技术与技巧
#### 2.3.1 处理嵌套结构和切片
当解析的JSON结构包含嵌套的结构体或者切片时,我们可以直接在结构体中声明相应的嵌套类型或切片类型,而无需做额外的处理。
```go
type Address struct {
City string `json:"city"`
Country string `json:"country"`
}
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Address []Address `json:"address"`
}
func main() {
var data = []byte(`{"name":"John", "age":30, "address":[{"city":"New York", "country":"USA"}]}`)
var person Person
err := json.Unmarshal(data, &person)
if err != nil {
log.Fatalf("JSON unmarshaling failed: %s", err)
}
fmt.Printf("%#v\n", person)
}
```
在上面的例子中,`Person`类型包含一个切片`[]Address`,其中`Address`是一个结构体。当`json.Unmarshal`被调用时,它会自动将JSON数组中的每一个对象解析为`Address`结构体实例,并将切片存储在`person.Address`中。
#### 2.3.2 解析JSON到interface{}类型
在某些情况下,我们可能不知道要处理的JSON数据的具体结构。此时可以使用`interface{}`来接收解析后的数据。
```go
var data = []byte(`["John", 30, {"city":"New York", "country":"USA"}]`)
var slice []interface{}
err := json.Unmarshal(data, &slice)
if err != nil {
log.Fatalf("JSON unmarshaling failed: %s", err)
}
fmt.Printf("%#v\n", slice)
```
在这段代码中,`slice`是一个空接口切片,`json.Unmarshal`能够正确地将JSON数组中的每个元素转换为相应的Go类型,比如字符串、整数和map。
```mermaid
sequenceDiagram
participant U as Unmarshal
participant S as []byte
participant I as interface{}
U->>S: Parse JSON data
S->>I: Convert to interface{}
I-->>U: Return unmarshaled data
```
这段代码展示了通过`interface{}`类型处理未知结构JSON数据的一个简单流程。这个技术在处理不规则JSON数据或者在编译阶段不确定数据结构时特别有用。然而,使用`interface{}`可能会牺牲编译时类型检查的好处,因此在实际开发中推荐使用具体类型结构体或自定义的`MarshalJSON`方法来控制序列化和反序列化的过程。
# 3. JSON数据的错误处理与测试
## 3.1 JSON解析中的错误处理
### 错误类型及其判断方法
在Go语言中处理JSON数据时,常见的错误类型包括但不限于语法错误、数据类型不匹配错误、结构体字段缺失或多余错误等。具体来说,当JSON结构与Go语言中的结构体不匹配时,如缺少必要的字段或存在多余未映射的字段,解析过程将会失败。
错误判断方法通常涉及到对`*json.SyntaxError`、`*json.UnmarshalTypeError`或`json.InvalidUnmarshalError`等类型的直接判断,或者捕获更广泛的错误类型`error`来确定错误的具体原因。在实际应用中,一种高效的方法是利用第三方库如`go-cmp`来进行深度比较,以区分具体是哪种类型的错误。
### 高效的错误处理策略
在处理JSON解析错误时,首先应该考虑的是避免在解析过程中将错误直接暴露给外部用户,防止敏感信息泄露。其次,应当详细记录错误信息,便于开发人员调试。下面的代码块展示了如何定义一个错误处理函数,该函数详细记录错误信息并返回一个通用的错误响应:
```go
func handleJSONError(err error) error {
// 记录错误日志,根据实际情况可以记录到日志文件或者监控系统中
log.Printf("Failed to parse JSON: %v", err)
// 返回一个通用的错误响应给客户端
return errors.New("internal server error")
}
// 使用示例
func myJSONHandler() {
var data map[string]interface{}
err := json.Unmarshal(jsonData, &data)
if err != nil {
// 处理特定错误类型
switch err := err.(type) {
case *json.SyntaxError:
// JSON语法错误处理逻辑
case *json.UnmarshalTypeError:
// 类型不匹配错误处理逻辑
default:
// 其他错误处理逻辑
err = handleJSONError(err)
}
}
// 正常的数据处理逻辑
}
```
## 3.2 JSON数据的测试技巧
### 单元测试与表驱动测试
单元测试是保证代码质量的重要手段,Go语言提供了内置的测试框架,可以用于编写和运行测试用例。在处理JSON数据时,单元测试尤其重要,因为它们可以确保数据的序列化和反序列化逻辑正确无误。表驱动测试是一种常见的测试技巧,它使用数据表来组织测试用例,使测试代码的结构更加清晰,便于维护。
```go
// 表驱动测试示例
func TestUnmarshalJSON(t *testing.T) {
tests := []struct {
name string
jsonData string
want interface{}
wantErr bool
}{
{
name: "valid json",
jsonData: `{"name": "John", "age": 30}`,
want: map[string]interface{}{
"name": "John",
"age": 30,
},
wantErr: false,
},
// 更多测试用例...
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
var got map[string]interface{}
err := json.Unmarshal([]byte(tt.jsonData), &got)
if (err != nil) != tt.wantErr {
t.Errorf("UnmarshalJSON() error = %v, wantErr %v", err, tt.wantErr)
return
}
if !reflect.DeepEqual(got, tt.want) {
t.Errorf("UnmarshalJSON() = %v, want %v", got, tt.want)
}
})
}
}
```
### 使用Go的测试框架进行测试
Go语言的测试框架简单易用,它允许我们直接编写测试函数,并使用`go test`命令来执行测试。在编写测试时,需要遵循一些约定:测试函数的命名必须以`Test`开头,接受一个指向`*testing.T`的指针作为参数,通过调用该类型的`Error`、`Errorf`、`Fail`等方法来报告测试失败。
为了提高测试的覆盖度和效果,应当编写覆盖各种可能情况的测试用例,例如处理空值、特殊字符、嵌套对象和数组等。测试不仅仅是验证功能的正确性,还包括检查性能和资源使用,确保代码在各种条件下都是高效和稳定的。
## 3.3 测试数据的生成与模拟
### 生成随机或复杂JSON数据
在进行单元测试时,经常需要生成随机或复杂的数据以模拟各种可能的使用场景。使用工具包如`***/google/uuid`生成唯一的标识符,或者使用`math/rand`库生成随机数和随机字符串来构造测试数据是常见方法。
```go
// 生成随机字符串的示例
func randomString(n int) string {
const letters = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
rand.Seed(time.Now().UnixNano())
b := make([]byte, n)
for i := range b {
b[i] = letters[rand.Intn(len(letters))]
}
return string(b)
}
// 使用示例
func generateRandomJSONData() string {
randomKey := randomString(10)
randomValue := randomString(15)
randomJSON := fmt.Sprintf(`{"key": "%s", "value": "%s"}`, randomKey, randomValue)
return randomJSON
}
```
### 使用mock数据进行测试
模拟数据(Mock Data)允许开发者在不依赖外部服务的情况下测试应用逻辑。通过模拟外部依赖的响应和行为,开发者可以专注于测试核心业务逻辑。在Go中,可以使用`***/golang/mock`等库来创建模拟对象并定义其行为。
```go
// 使用mock库来模拟JSON数据的示例
type MockJSONService struct {
mock.Mock
}
func (m *MockJSONService) Parse(input string) (map[string]interface{}, error) {
args := m.Called(input)
return args.Get(0).(map[string]interface{}), args.Error(1)
}
// 在测试中使用mock
func TestMockService(t *testing.T) {
mockService := new(MockJSONService)
// 预设期望调用和返回结果
mockService.On("Parse", mock.AnythingOfType("string")).Return(
map[string]interface{}{"key": "value"},
nil,
)
result, err := mockService.Parse(`{"key":"value"}`)
if err != nil {
t.Errorf("Unexpected error: %s", err)
}
if result["key"] != "value" {
t.Errorf("Mock Parse result does not match expected value")
}
}
```
通过上述方法和工具的运用,开发者可以为处理JSON数据的Go程序创建全面而有效的测试策略。这不仅提高了代码的可靠性,也保障了应用的健壮性,从而在生产环境中提供更高质量的服务。
# 4. 高级JSON处理技术
## 4.1 流式解析与编码
### 4.1.1 使用Decoder和Encoder
在处理大型的JSON数据文件时,内存效率和解析速度变得至关重要。Go语言的`encoding/json`包提供的`Decoder`和`Encoder`类型允许我们以流的方式对JSON数据进行解析和编码,这样可以显著地减少内存的使用,同时保持处理的高效性。
`Decoder`类型可以帮助我们将数据从`io.Reader`(比如文件或者网络连接)中逐步解析成Go语言的数据结构,而`Encoder`则可以将Go语言的数据结构编码成JSON格式,并逐步写入到`io.Writer`中。
下面是一个使用`Decoder`和`Encoder`的示例代码,展示如何处理大型文件:
```go
package main
import (
"bufio"
"encoding/json"
"fmt"
"log"
"os"
)
type MyData struct {
Name string `json:"name"`
Age int `json:"age"`
Country string `json:"country"`
}
func main() {
// 打开JSON文件
file, err := os.Open("large_dataset.json")
if err != nil {
log.Fatalf("Error opening ***", err)
}
defer file.Close()
// 创建Decoder
decoder := json.NewDecoder(bufio.NewReader(file))
// 循环解析JSON对象
for {
var data MyData
err = decoder.Decode(&data)
if err == io.EOF {
break // 到达文件末尾
}
if err != nil {
log.Fatalf("Error decoding data: %s", err)
}
// 处理解析后的数据
fmt.Printf("Name: %s, Age: %d, Country: %s\n", data.Name, data.Age, data.Country)
}
}
```
在上述代码中,我们首先打开一个名为`large_dataset.json`的文件,然后创建了一个`Decoder`实例用于逐步解析JSON数据。`bufio.NewReader`提供了一个带缓冲的读取器,这有助于在处理大数据时减少`io`操作的次数。然后我们进入一个循环,使用`Decode`方法将文件中的JSON对象逐个读取到`MyData`结构体中,并输出相关信息。
### 4.1.2 处理大JSON文件和流式数据
处理大JSON文件时,我们可能会遇到大字段或者嵌套结构复杂导致的问题。流式处理不需要一次性将整个JSON文档加载到内存中,因此可以有效地应对这些问题。以下是一些处理大JSON文件时需要注意的点:
- 使用`Decoder`的`Token`方法逐个读取JSON的标记,这对于调试流式处理过程或者跳过不需要的字段很有帮助。
- 由于JSON文件可能非常大,必须考虑内存使用和性能。使用`Decoder`和`Encoder`可以最小化内存占用,同时允许并行处理。
- 如果你的应用场景需要读取数据然后进行一些计算,考虑使用`Decoder`逐个处理JSON对象,这样可以边读取边处理,而不是等待整个数据流完成。
- 使用`Decoder`的`SetResolveReference`方法可以解决JSON对象中的引用解析问题。这对于处理具有重复引用的复杂JSON结构特别有用。
```go
// 示例:使用Decoder的Token方法来读取和打印JSON结构
func printTokens(decoder *json.Decoder) error {
for {
token, err := decoder.Token()
if err != nil {
return err
}
// 打印不同的JSON标记类型
switch token := token.(type) {
case string:
fmt.Printf("String: %s\n", token)
case float64:
fmt.Printf("Number: %f\n", token)
case bool:
fmt.Printf("Boolean: %t\n", token)
case nil:
fmt.Println("Null")
default:
fmt.Println("Other")
}
}
}
```
## 4.2 自定义类型与JSON序列化
### 4.2.1 定义类型别名与自定义序列化方法
Go语言中,有时标准的JSON序列化和反序列化行为可能不满足特定需求。这时,我们可以定义新的类型别名并为这些类型编写自定义的序列化方法。
通过实现`json.Marshaler`和`json.Unmarshaler`接口,我们可以控制如何将自定义类型转换为JSON格式以及如何从JSON格式解析回自定义类型。
让我们以一个简单的例子来说明如何定义类型别名和实现自定义序列化方法:
```go
package main
import (
"encoding/json"
"fmt"
)
// 定义一个Point结构体
type Point struct {
X, Y int
}
// 定义PointAlias是Point的别名,但可以有自定义的序列化行为
type PointAlias Point
// 实现自定义的MarshalJSON方法
func (p PointAlias) MarshalJSON() ([]byte, error) {
// 创建一个仅包含X和Y的map
aux := map[string]int{
"X": p.X,
"Y": p.Y,
}
return json.Marshal(aux)
}
func main() {
// 创建PointAlias实例
pa := PointAlias{X: 1, Y: 2}
// 使用json.Marshal序列化自定义类型
b, err := json.Marshal(pa)
if err != nil {
panic(err)
}
fmt.Println(string(b)) // 输出:{"X":1,"Y":2}
}
```
在上述代码中,我们首先定义了一个简单的`Point`结构体,然后创建了它的别名`PointAlias`。我们为`PointAlias`类型实现了`MarshalJSON`方法,它使得序列化行为与`Point`类型有所不同。当调用`json.Marshal`来序列化`PointAlias`类型的实例时,实际上调用的是`PointAlias`实现的`MarshalJSON`方法,这允许我们自定义序列化逻辑,例如,将其序列化为包含"X"和"Y"键的JSON对象。
### 4.2.2 合并字段和使用指针的序列化技巧
在JSON序列化过程中,有时我们希望合并字段或者使用指针来改变默认的序列化行为。通过实现`json.Marshaler`接口和`json.Unmarshaler`接口,我们可以对结构体字段进行更细粒度的控制。
例如,假设我们有一个`User`结构体,它包含`FirstName`和`LastName`字段,我们希望在序列化时将这两个字段合并为一个`FullName`字段。
```go
package main
import (
"encoding/json"
"fmt"
)
type User struct {
FirstName string
LastName string
}
// 实现自定义的MarshalJSON方法
func (u *User) MarshalJSON() ([]byte, error) {
fullName := struct {
FullName string `json:"fullName"`
}{
FullName: fmt.Sprintf("%s %s", u.FirstName, u.LastName),
}
return json.Marshal(fullName)
}
func main() {
user := &User{FirstName: "John", LastName: "Doe"}
// 使用json.Marshal序列化User实例
b, err := json.Marshal(user)
if err != nil {
panic(err)
}
fmt.Println(string(b)) // 输出:{"fullName":"John Doe"}
}
```
在上面的代码中,我们为`User`结构体的指针类型实现了一个自定义的`MarshalJSON`方法,它创建了一个包含`FullName`字段的匿名结构体,并使用`fmt.Sprintf`来格式化姓名。在调用`json.Marshal`时,该方法会被触发,并按照我们定义的方式进行序列化。
合并字段也可以应用于嵌套结构,通过在嵌套结构上实现`MarshalJSON`方法来改变其序列化行为,从而在父结构体序列化时影响输出。
## 4.3 高级错误处理与数据验证
### 4.3.1 验证JSON数据的有效性
在JSON数据处理过程中,验证数据的有效性是一个重要的步骤。在Go中,我们可以使用`json.Unmarshal`进行基本的解析,并通过检查解析后的结构体的字段来执行验证。但是,对于更复杂的验证需求,比如对日期格式、特定值范围的检查,我们可以使用第三方库如`go-validator`或者实现自定义的验证逻辑。
一个常见的验证需求是对JSON数据中的某些字段施加限制,例如年龄字段不能超过某个值。我们可以通过定义一个`Validate`函数来实现此目的,该函数可以被绑定到结构体类型上,以实现验证逻辑。
```go
package main
import (
"encoding/json"
"fmt"
)
type User struct {
Name string `json:"name"`
Age int `json:"age"`
Country string `json:"country"`
}
// 实现自定义的 Validate 方法
func (u *User) Validate() error {
if u.Age < 0 || u.Age > 100 {
return fmt.Errorf("invalid age %d", u.Age)
}
return nil
}
func main() {
// 假设JSON字符串为
data := `{"name":"Alice", "age": 101, "country":"Wonderland"}`
// 解析JSON
var user User
if err := json.Unmarshal([]byte(data), &user); err != nil {
fmt.Println("Error unmarshaling JSON:", err)
return
}
// 验证User
if err := user.Validate(); err != nil {
fmt.Println("User validation error:", err)
return
}
fmt.Println("User is valid")
}
```
在上述代码中,我们定义了一个`User`结构体并为其添加了一个`Validate`方法。在`main`函数中,我们首先使用`json.Unmarshal`解析了JSON数据,然后调用了`user.Validate()`来检查`Age`字段是否在合理范围内。
### 4.3.2 处理结构化错误信息
在处理JSON数据时,结构化的错误信息能够提供更详细的错误上下文,这有助于快速定位问题并给出清晰的错误提示。
使用`json.Unmarshal`时,若遇到错误,它会返回一个实现了错误接口的实例。如果需要返回更详细的错误信息,我们可以创建自定义的错误类型,并实现错误接口。
```go
package main
import (
"encoding/json"
"fmt"
"errors"
)
type ValidationError struct {
Field string
Error error
}
func (ve *ValidationError) Error() string {
return fmt.Sprintf("Validation error on field '%s': %s", ve.Field, ve.Error)
}
type User struct {
Name string `json:"name"`
Age int `json:"age"`
}
func main() {
data := []byte(`{"name":"John", "age":"not-a-number"}`)
var user User
if err := json.Unmarshal(data, &user); err != nil {
var syntaxError *json.SyntaxError
if errors.As(err, &syntaxError) {
fmt.Println("JSON syntax error:", syntaxError.Offset)
} else {
var ve *ValidationError
if errors.As(err, &ve) {
fmt.Println(ve)
} else {
fmt.Println("Unmarshal error:", err)
}
}
return
}
fmt.Println("User:", user)
}
```
在上述代码中,我们定义了一个`ValidationError`结构体,它包装了一个错误信息,并指明了哪个字段出现了问题。在`main`函数中,如果`Unmarshal`失败,我们检查错误是否可以被断言为`ValidationError`,从而提供更有用的反馈信息。
通过以上方式,我们可以对JSON数据进行更加精确和详尽的错误处理。这样的处理方式有助于开发者在开发过程中更加容易地找到和修正错误,同时在最终用户遇到问题时提供更明确的错误提示。
# 5. 综合应用与性能优化
## 5.1 Go语言中JSON的实际应用案例
### 5.1.1 构建RESTful API的JSON处理
构建RESTful API是Web开发中的一项核心任务,而JSON作为前后端交互的主要数据格式,其处理效率直接影响到API的性能和用户体验。在Go语言中,我们可以使用标准库`net/http`来构建RESTful API,并结合`encoding/json`来处理JSON数据。
以下是一个简单的例子,展示如何在Go语言中创建一个RESTful API,并返回JSON格式的响应数据:
```go
package main
import (
"encoding/json"
"log"
"net/http"
)
type Response struct {
Message string `json:"message"`
}
func handler(w http.ResponseWriter, r *http.Request) {
resp := Response{Message: "Hello, World!"}
jsonResp, err := json.Marshal(resp)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.Write(jsonResp)
}
func main() {
http.HandleFunc("/", handler)
log.Fatal(http.ListenAndServe(":8080", nil))
}
```
在这个例子中,我们定义了一个`Response`结构体,使用`json`标签指定JSON键。`handler`函数处理HTTP请求,将`Response`实例序列化为JSON格式,并写入到HTTP响应中。
### 5.1.2 处理Web前端与Go后端的数据交互
在Web应用中,前端页面常常需要与后端进行数据交互。Go语言编写的后端服务能够高效地处理JSON格式的请求和响应。为了处理前端传来的JSON数据,我们可以使用`http.Request`的`Body`来读取请求体,并利用`json.Unmarshal`进行反序列化。
下面的代码段展示了如何接收前端发送的JSON数据,并将其转换为Go语言中的结构体:
```go
func createResourceHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodPost {
http.Error(w, "Only POST method is supported", http.StatusMethodNotAllowed)
return
}
var resourceData Resource
if err := json.NewDecoder(r.Body).Decode(&resourceData); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
// 处理resourceData...
w.WriteHeader(http.StatusCreated)
}
```
在这个处理函数中,我们首先检查请求方法是否为POST。然后,使用`json.Decoder`读取请求体并将其解码为`Resource`类型的实例。处理完数据后,通常会返回一个合适的HTTP状态码。
## 5.2 性能优化策略
### 5.2.1 减少内存分配与重用
在处理大量数据或高性能要求的场景中,减少内存分配对于提升性能至关重要。在Go中,我们可以通过以下策略来减少内存分配:
- 使用缓冲区和预分配大小的切片。
- 重用对象而不是频繁地创建和销毁。
- 使用`sync.Pool`来缓存和复用对象,减少垃圾回收压力。
```go
var bufferPool = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func processLargeData(data []byte) error {
buf := bufferPool.Get().(*bytes.Buffer)
defer bufferPool.Put(buf)
buf.Reset()
buf.Write(data)
// 处理buf...
return nil
}
```
在这个例子中,我们使用`sync.Pool`来获取和重用`bytes.Buffer`对象,避免每次处理数据时都创建新的缓冲区。
### 5.2.2 并行处理JSON数据与Goroutines使用
为了充分利用现代多核处理器,Go语言提供了并发原语,如`goroutines`和`channels`,允许开发者编写高效的并发代码。并行处理JSON数据可以通过并发读取、解析和处理多个数据文件或数据流来实现。
```go
func processJSONDataConcurrently(files []string) {
var wg sync.WaitGroup
for _, *** {
wg.Add(1)
go func(f string) {
defer wg.Done()
// 打开文件并并行处理文件中的JSON数据
}(file)
}
wg.Wait()
}
```
这段代码演示了如何并发处理一系列JSON文件。每个文件的处理在独立的goroutine中进行,`sync.WaitGroup`确保所有处理都完成后程序才继续执行。
## 5.3 框架与工具的辅助应用
### 5.3.1 使用JSON处理库如GJSON和JSON-Marshaller
Go社区提供了许多第三方库来简化和加速JSON数据的处理。例如,`GJSON`提供了一种快速查找JSON的路径的方式,而`JSON-Marshaller`提供了更为灵活的序列化和反序列化功能。
使用这些库可以减少代码量,提升开发效率,同时也可以在处理复杂的JSON结构时提高性能。
```go
// 使用GJSON快速访问JSON字段
import "***/tidwall/gjson"
data := `{"name":"John", "age":30}`
age := gjson.Get(data, "age")
fmt.Println(age.Int())
```
上面的代码展示了如何使用`GJSON`快速获取JSON数据中的年龄信息。
### 5.3.2 开发辅助工具进行调试与监控
调试和监控是确保应用程序稳定运行的关键环节。在Go的JSON处理中,可以开发一些辅助工具来帮助开发人员进行调试和监控。
例如,可以编写一个工具来生成一个简单的Web界面,允许用户输入JSON数据,并立即看到处理结果。此外,可以集成日志记录和性能分析工具,以监控JSON处理流程中的性能瓶颈。
```go
// 一个简单的日志记录和性能监控示例
log.Println("Start processing JSON data")
start := time.Now()
// 这里是JSON处理代码...
duration := time.Since(start)
log.Printf("Finished processing in %v", duration)
```
以上代码段展示了如何在Go程序中添加日志记录和性能监控,有助于开发者在JSON处理流程中追踪性能问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏全面深入地探讨了 Go 语言中的 JSON 处理,从入门级技巧到高级策略。它涵盖了以下关键主题:
* JSON 处理的最佳实践,确保安全和高效的数据处理
* JSON 与 XML 数据之间的互操作性,实现无缝转换
* 构建 RESTful API 的 JSON 处理案例研究
* 创建可复用编解码器的技巧,简化 JSON 解析和序列化
* 与数据库交互的高效 JSON 序列化实践
* 嵌套对象和 null 值处理的深入理解
* 编写健壮的 JSON 编解码器,提高代码可靠性
通过深入的解释、代码示例和实践技巧,本专栏为 Go 开发人员提供了全面指南,帮助他们掌握 JSON 处理,并将其应用于各种应用程序中。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
支持向量机在语音识别中的应用:挑战与机遇并存的研究前沿

# 1. 支持向量机(SVM)基础
支持向量机(SVM)是一种广泛用于分类和回归分析的监督学习算法,尤其在解决非线性问题上表现出色。SVM通过寻找最优超平面将不同类别的数据有效分开,其核心在于最大化不同类别之间的间隔(即“间隔最大化”)。这种策略不仅减少了模型的泛化误差,还提高了模型对未知数据的预测能力。SVM的另一个重要概念是核函数,通过核函数可以将低维空间线性不可分的数据映射到高维空间,使得原本难以处理的问题变得易于
神经网络硬件加速秘技:GPU与TPU的最佳实践与优化

# 1. 神经网络硬件加速概述
## 1.1 硬件加速背景
随着深度学习技术的快速发展,神经网络模型变得越来越复杂,计算需求显著增长。传统的通用CPU已经难以满足大规模神经网络的计算需求,这促使了
从GANs到CGANs:条件生成对抗网络的原理与应用全面解析
.jpg)
# 1. 生成对抗网络(GANs)基础
生成对抗网络(GANs)是深度学习领域中的一项突破性技术,由Ian Goodfellow在2014年提出。它由两个模型组成:生成器(Generator)和判别器(Discriminator),通过相互竞争来提升性能。生成器负责创造出逼真的数据样本,判别器则尝试区分真实数据和生成的数据。
## 1.1 GANs的工作原理
细粒度图像分类挑战:CNN的最新研究动态与实践案例

# 1. 细粒度图像分类的概念与重要性
随着深度学习技术的快速发展,细粒度图像分类在计算机视觉领域扮演着越来越重要的角色。细粒度图像分类,是指对具有细微差异的图像进行准确分类的技术。这类问题在现实世界中无处不在,比如对不同种类的鸟、植物、车辆等进行识别。这种技术的应用不仅提升了图像处理的精度,也为生物多样性
RNN可视化工具:揭秘内部工作机制的全新视角

# 1. RNN可视化工具简介
在本章中,我们将初步探索循环神经网络(RNN)可视化工具的核心概念以及它们在机器学习领域中的重要性。可视化工具通过将复杂的数据和算法流程转化为直观的图表或动画,使得研究者和开发者能够更容易理解模型内部的工作机制,从而对模型进行调整、优化以及故障排除。
## 1.1 RNN可视化的目的和重要性
可视化作为数据科学中的一种强
市场营销的未来:随机森林助力客户细分与需求精准预测

# 1. 市场营销的演变与未来趋势
市场营销作为推动产品和服务销售的关键驱动力,其演变历程与技术进步紧密相连。从早期的单向传播,到互联网时代的双向互动,再到如今的个性化和智能化营销,市场营销的每一次革新都伴随着工具、平台和算法的进化。
## 1.1 市场营销的历史沿
K-近邻算法多标签分类:专家解析难点与解决策略!

# 1. K-近邻算法概述
K-近邻算法(K-Nearest Neighbors, KNN)是一种基本的分类与回归方法。本章将介绍KNN算法的基本概念、工作原理以及它在机器学习领域中的应用。
## 1.1 算法原理
KNN算法的核心思想非常简单。在分类问题中,它根据最近的K个邻居的数据类别来进行判断,即“多数投票原则”。在回归问题中,则通过计算K个邻居的平均
LSTM在语音识别中的应用突破:创新与技术趋势

# 1. LSTM技术概述
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),它能够学习长期依赖信息。不同于标准的RNN结构,LSTM引入了复杂的“门”结构来控制信息的流动,这允许网络有效地“记住”和“遗忘”信息,解决了传统RNN面临的长期依赖问题。
## 1
【决策树到AdaBoost】:一步步深入集成学习的核心原理
# 1. 集成学习概述
集成学习(Ensemble Learning)是机器学习领域中的一个重要分支,旨在通过组合多个学习器来提高预测的准确性和鲁棒性。集成学习的基本思想是“三个臭皮匠,顶个诸葛亮”,通过集合多个模型的智慧来解决
XGBoost时间序列分析:预测模型构建与案例剖析
# 1. 时间序列分析与预测模型概述
在当今数据驱动的世界中,时间序列分析成为了一个重要领域,它通过分析数据点随时间变化的模式来预测未来的趋势。时间序列预测模型作为其中的核心部分,因其在市场预测、需求计划和风险管理等领域的广泛应用而显得尤为重要。本章将简单介绍时间序列分析与预测模型的基础知识,包括其定义、重要性及基本工作流程,为读者理解后续章节内容打下坚实基础。
# 2. XGB
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )