




网页数据抓取大师:使用urllib.request和正则表达式


python爬虫实例——基于BeautifulSoup与urllib.request
1. 网页数据抓取的基础知识
1.1 什么是网页数据抓取
网页数据抓取是利用计算机程序从互联网上提取信息的过程。这种技术广泛应用于搜索引擎、数据挖掘、市场分析等领域。对于数据科学家和开发人员而言,掌握基本的网页数据抓取技能是必备的。
1.2 网页抓取的工具和技术
常见的网页数据抓取工具有Postman、Fiddler、网络爬虫等。抓取技术主要分为两大类:客户端抓取和服务器端抓取。客户端抓取,例如使用JavaScript库(如Cheerio)直接在浏览器中操作DOM;服务器端抓取,如使用Python的Scrapy框架或urllib库。
1.3 网页抓取的重要性
数据抓取不仅可以帮助我们快速获取大量的信息,还能为商业决策提供数据支撑。但是,这种技术可能会涉及到隐私和版权问题,因此在实施过程中需要谨慎遵循相关法律法规。
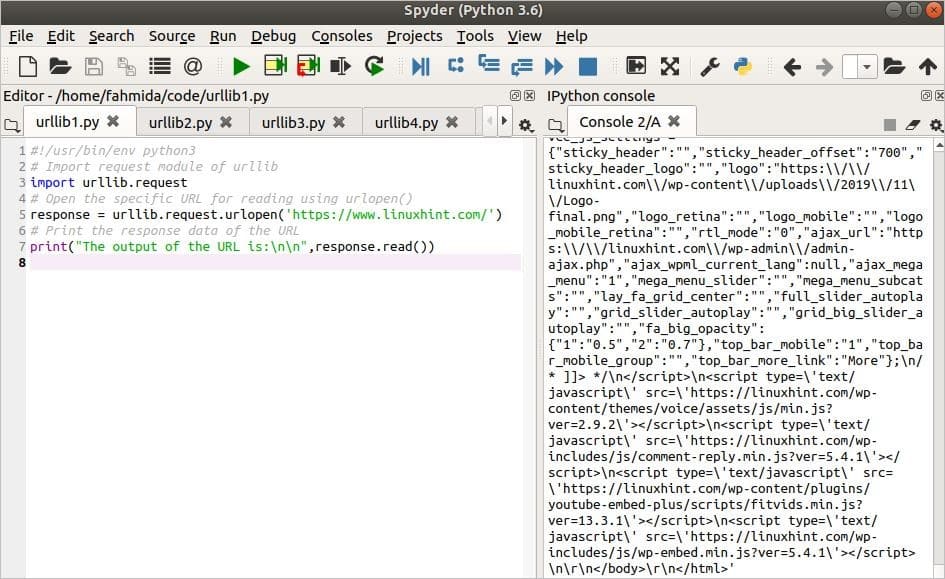
- # 示例:使用urllib.request模块获取网页内容
- import urllib.request
- url = "***"
- response = urllib.request.urlopen(url)
- html_content = response.read()
- print(html_content) # 打印网页内容
上述Python代码块展示了如何使用urllib.request模块获取指定网页的HTML内容。这是网页数据抓取中最基础的操作,是后续更复杂技术的起点。
2. 深入理解urllib.request模块
urllib 是 Python 的标准库之一,它为用户提供了用于操作 URL 的一系列方法,包括 HTTP、FTP、HTTPS 等协议。urllib.request 模块则是 urllib 中用于访问网络资源的一个子模块。本章将深入探讨 urllib.request 模块的使用方法,包括基本使用、高级功能和进阶使用。
2.1 urllib.request模块的基本使用
2.1.1 urllib.request模块的安装和导入
urllib.request 模块是 Python 的内置模块,因此不需要额外安装即可使用。在编写代码前,需要先导入该模块。
- import urllib.request
在 Python 3 中,urllib2 已经被合并到 urllib 中,如果使用 Python 2,则需要使用 urllib2。
2.1.2 使用urllib.request访问网络资源
使用 urllib.request 模块访问网络资源非常简单。首先创建一个 urllib.request.urlopen() 对象,然后通过该对象的 read() 方法读取资源。
- # 打开一个URL链接
- url = '***'
- response = urllib.request.urlopen(url)
- # 读取内容
- html_content = response.read()
- print(html_content)
在使用 urlopen() 方法时,如果需要访问的网站需要 HTTP 认证,可以传入一个 Request 对象。
- from urllib.request import Request
- req = Request(url, data=None, headers={})
- response = urllib.request.urlopen(req)
2.2 urllib.request模块的高级功能
2.2.1 处理网络异常和异常捕获
网络请求可能会因为各种原因失败,例如网络问题、服务器问题等。使用 try-except 语句块可以捕获并处理这些异常。
- try:
- response = urllib.request.urlopen(url)
- html_content = response.read()
- except urllib.error.URLError as e:
- print('访问失败,原因:', e.reason)
- except Exception as e:
- print('发生错误:', e)
2.2.2 自定义HTTP头部信息
有时,用户需要模拟特定的浏览器或者应用来访问网站,这时可以通过自定义 HTTP 头部信息来实现。
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)',
- 'From': '***',
- 'Referer': '***'
- }
- req = Request(url, headers=headers)
- response = urllib.request.urlopen(req)
2.2.3 设置代理和Cookies
在一些特定的网络环境下,需要通过代理服务器访问网络资源,或者需要在请求中携带 Cookies。urllib.request 模块同样支持这些高级功能。
- # 设置代理
- proxy_handler = urllib.request.ProxyHandler({'http': '***'})
- opener = urllib.request.build_opener(proxy_handler)
- urllib.request.install_opener(opener)
- # 添加Cookies
- cookies = urllib.request.HTTPCookieProcessor()
- opener = urllib.request.build_opener(cookies)
- urllib.request.install_opener(opener)
2.3 urllib.request模块的进阶使用
2.3.1 多线程下载和多进程下载
在进行大规模的网络下载时,单线程下载效率较低。使用 Python 的 threading 或 multiprocessing 模块可以实现多线程或多进程下载,大大提升效率。

2.3.2 SSL证书验证和HTTPS连接
HTTPS 连接需要验证 SSL 证书。在 Python 3 中,urlopen 方法默认会验证 SSL 证书。如果需要忽略证书验证(不推荐),可以使用以下方式:
- import ssl
- context = ssl._create_unverified_context()
- response = urllib.request.urlopen(url, context=context)
为了安全性,建议验证所有 SSL 证书,只有在明确知道证书问题的情况下才忽略证书验证。
以上章节详细介绍了 urllib.request 模块的基本使用方法,包括安装、导入、访问网络资源,以及一些高级功能如处理网络异常、自定义 HTTP 头部、设置代理和Cookies。接下来的进阶使用部分,我们探讨了如何利用多线程和多进程进行高效下载,并处理 SSL 证书验证问题。
本章节的内容不仅涵盖了 urllib.request 模块的各个方面,还提供了一些实际的代码示例,帮助读者更好地理解和掌握这些功能。通过本章节的学习,读者应能熟练使用 urllib.request 模块来处理各种网络请求问题,并为实现更复杂的网络爬虫项目打下坚实的基础。
3. 正则表达式在网页抓取中的应用
正则表达式(Regular Expression),简称 regex 或 regexp,是一种用于匹配字符串中字符组合的模式。在网页数据抓取中,正则表达式是提取所需信息的重要工具,它能够高效地识别和处理文本数据。本章将深入探讨正则表达式的基本概念、使用方法以及在网页抓取中的高级技巧。
3.1

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FLUKE_8845A_8846A深度剖析】:揭秘5大高级功能与高效应用策略
【地理信息系统实用指南】:10个技巧助你精通高德地图API
时间序列分析:用R语言进行精准预测与建模的策略
无线网络设计与优化:顶尖专家的理论与实践
快速排序性能提升:在多核CPU环境下实现并行化的【秘诀】
【虚拟网络环境的性能优化】:eNSP结合VirtualBox的最佳实践
【权威指南】:掌握AUTOSAR BSW模块,专家级文档解读
MSP430与HCSR04超声波模块的距离计算优化方法
EPLAN高级功能解锁:【条件化内容】:提升设计质量的创新方法


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )









