C语言数据结构简介与应用
发布时间: 2024-03-31 13:30:17 阅读量: 62 订阅数: 21 

数据结构简介-C语言版
# 1. C语言基础回顾
- 1.1 C语言概述
- 1.2 数据类型与变量
- 1.3 控制流程
- 1.4 函数与指针
- 1.5 头文件与预处理器
- 1.6 内存管理
# 2. 数据结构概述
数据结构是计算机科学中非常重要的基础概念之一。它是指数据对象以及数据对象之间的关系,通常用来组织和存储数据,以便更高效地访问和修改数据。数据结构的设计和选择直接影响着算法和程序的性能。
#### 2.1 什么是数据结构
数据结构是指数据对象在计算机中的组织方式,主要包括两个方面:数据的逻辑结构(数据元素之间的关系)和数据的存储结构(数据在计算机中的表示方式)。
#### 2.2 数据结构的分类
数据结构可以分为线性结构和非线性结构两大类。线性结构中的数据元素之间存在一对一的关系,而非线性结构中的数据元素之间存在一对多或多对多的关系。具体的数据结构类型包括数组、链表、栈、队列、树、图等。
#### 2.3 线性结构
线性结构是最简单也是最常用的数据结构之一,包括数组、链表、栈和队列。其中,数组是一组相同类型的元素按照一定顺序排列而成的数据集合;链表是由若干节点组成的数据结构,每个节点包含数据和指向下一个节点的指针;栈是一种后进先出(LIFO)的数据结构;队列是一种先进先出(FIFO)的数据结构。
#### 2.4 非线性结构
非线性结构包括树和图两种数据结构。树是一种层次结构,包括根节点、分支和叶子节点;图是由节点和连接节点的边组成的数据结构,常用于描述各种事物之间的关系。
#### 2.5 数据结构的选择原则
在实际应用中,选择合适的数据结构是至关重要的。一般来说,应根据问题的特点和数据操作的需求来选择合适的数据结构。要考虑数据的增删改查操作、空间复杂度和时间复杂度等因素,以及数据结构的实现难度和效率等因素。
数据结构概述章节介绍了数据结构的基本概念、分类和选择原则,为后续章节的具体数据结构内容奠定了基础。
# 3. 基本数据结构
### 3.1 数组
在数据结构中,数组是一种线性结构,它是由相同数据类型的元素按顺序排列组合而成的数据集合。数组的特点是大小固定,可以通过索引来访问元素。
#### 代码示例
```python
# 创建一个整型数组
arr = [1, 2, 3, 4, 5]
# 访问数组元素
print(arr[0]) # 输出第一个元素
print(arr[2]) # 输出第三个元素
# 修改数组元素
arr[1] = 10 # 将第二个元素改为10
print(arr)
```
#### 代码总结
以上代码展示了如何创建、访问和修改数组元素的基本操作。
#### 结果说明
- 输出第一个元素为1
- 输出第三个元素为3
- 修改第二个元素为10后,数组变为[1, 10, 3, 4, 5]
### 3.2 链表
链表是一种常见的数据结构,由节点组成,每个节点包含数据项和指向下一个节点的指针。链表可以动态地分配内存,不需要连续的存储空间。
#### 代码示例
```java
// 定义链表节点
class Node {
int data;
Node next;
public Node(int data) {
this.data = data;
this.next = null;
}
}
// 创建链表并添加节点
Node head = new Node(1);
head.next = new Node(2);
head.next.next = new Node(3);
// 遍历链表并输出节点值
Node current = head;
while (current != null) {
System.out.println(current.data);
current = current.next;
}
```
#### 代码总结
以上代码演示了如何创建一个简单的链表,并遍历输出节点的值。
#### 结果说明
输出结果为:
```
1
2
3
```
### 3.3 栈与队列
栈和队列是两种常见的数据结构,有着不同的特点和应用场景。栈遵循先进后出(FILO)的原则,而队列遵循先进先出(FIFO)的原则。
#### 代码示例
```javascript
// 栈的实现
let stack = [];
stack.push(1);
stack.push(2);
stack.push(3);
console.log(stack.pop()); // 输出3
console.log(stack.pop()); // 输出2
// 队列的实现
let queue = [];
queue.push(1);
queue.push(2);
queue.push(3);
console.log(queue.shift()); // 输出1
console.log(queue.shift()); // 输出2
```
#### 代码总结
以上代码展示了如何使用数组实现栈和队列的基本操作。
#### 结果说明
栈的输出结果为:
```
3
2
```
队列的输出结果为:
```
1
2
```
# 4. 高级数据结构
#### 4.1 树
树(Tree)是一种非线性数据结构,由节点和边组成。树结构包含了一个根节点以及若干子树,子树也是一个树。树结构中常见的概念包括根节点、父节点、子节点、叶子节点、深度、高度等。树结构可以分为无序树、有序树、二叉树等多种类型。
在计算机科学中,树结构应用广泛,比如文件系统、HTML文档对象模型(DOM)等都使用了树结构进行组织。树结构的实现可以通过链表、数组等方式进行。
#### 4.2 图
图(Graph)是一种包含节点(顶点)和边的数据结构,用于模拟事物之间的关系。图结构可以分为有向图和无向图,根据是否有方向性区分。在图中,节点之间的关系可以用边来表示,边可以是有权重的。
图在现实生活中也有很多应用,比如社交网络关系、网络拓扑结构等。图的实现通常包括邻接矩阵、邻接表等方式。
#### 4.3 堆与优先队列
堆(Heap)是一种特殊的树结构,分为最大堆和最小堆。堆常用于实现优先队列,保证队列中元素的优先级顺序。在堆中,父节点的值总是大于/小于子节点的值,这样可以方便进行插入和删除操作。
优先队列(Priority Queue)是一种数据结构,可以按照元素的优先级取出元素。堆可以作为实现优先队列的一种方式。
#### 4.4 散列表
散列表(Hash Table)是一种利用哈希函数实现的数据结构,可以实现快速的插入、查找和删除操作。散列表将键映射到值,通过哈希函数计算键在表中的位置。
散列表在实际应用中被广泛使用,比如用于实现字典、缓存等功能。解决哈希冲突、设计合适的哈希函数是散列表实现的关键。
<details>
<summary>展示代码示例</summary>
```python
# Python实现散列表
class HashTable:
def __init__(self):
self.size = 10
self.data = [None] * self.size
def _hash_function(self, key):
return hash(key) % self.size
def add(self, key, value):
index = self._hash_function(key)
self.data[index] = value
def get(self, key):
index = self._hash_function(key)
return self.data[index]
# 使用散列表
hash_table = HashTable()
hash_table.add("name", "Alice")
hash_table.add("age", 25)
print(hash_table.get("name")) # 输出:Alice
print(hash_table.get("age")) # 输出:25
```
</details>
在这一章中,我们介绍了树、图、堆与优先队列、散列表这几种高级数据结构,它们在实际应用中扮演着重要的角色,希望读者能够深入理解它们的概念和实现原理。
**总结:** 高级数据结构的学习可以帮助我们更好地组织和管理数据,在解决实际问题时提供了更多的选择和思路。
# 5. 数据结构的应用
数据结构是计算机科学的重要基础,不仅在理论研究中扮演着重要的角色,也在实际应用中发挥着关键作用。本章将介绍数据结构在实际应用中的几个重要方面。
#### 5.1 排序算法及其在数据结构中的应用
排序算法是数据处理中最基本、最常用的算法之一。通过不同的排序算法,可以对数据进行升序或降序排列,提高检索效率。在数据结构中,常常会结合各种排序算法来实现对数据的管理与优化。
```python
# 以Python实现冒泡排序算法
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
arr = [64, 34, 25, 12, 22, 11, 90]
sorted_arr = bubble_sort(arr)
print("Sorted array:", sorted_arr)
```
*代码总结:* 冒泡排序算法通过比较相邻元素的大小,逐步将最大(小)元素移到最后(前),达到排序的目的。
*结果说明:* 经过冒泡排序后,输出已排序的数组。
#### 5.2 查找算法
查找算法是在数据集合中查找特定元素的算法。常见的查找算法有线性查找、二分查找等,它们在不同数据结构中有着各自的应用场景。
```java
// 以Java实现二分查找
public static int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
int[] arr = {11, 22, 34, 64, 90};
int target = 34;
int result = binarySearch(arr, target);
System.out.println("Index of target: " + result);
```
*代码总结:* 二分查找算法通过不断将查找范围缩小一半的方式,在有序数组中查找目标值。
*结果说明:* 经过二分查找后,输出目标值在数组中的索引位置。
#### 5.3 图算法
图是一种重要的非线性数据结构,图算法涉及到图的遍历、最短路径、最小生成树等。在网络拓扑分析、社交网络分析等领域,图算法有着广泛的应用。
```go
// 以Go实现深度优先搜索(DFS)算法
func dfs(graph map[int][]int, visited map[int]bool, node int) {
visited[node] = true
fmt.Printf("%d ", node)
for _, neighbor := range graph[node] {
if !visited[neighbor] {
dfs(graph, visited, neighbor)
}
}
}
graph := map[int][]int{
0: {1, 2},
1: {0, 3, 4},
2: {0, 5},
3: {1},
4: {1, 5},
5: {2, 4},
}
visited := make(map[int]bool)
fmt.Print("DFS traversal: ")
dfs(graph, visited, 0)
```
*代码总结:* 深度优先搜索是一种图算法,通过递归的方式沿着图的某一分支不断探索,直到达到最深处,然后回溯。
*结果说明:* 经过深度优先搜索后,输出图的遍历结果。
#### 5.4 操作系统中的数据结构应用
操作系统中需要对进程、文件系统、内存等资源进行管理,数据结构在操作系统中有着广泛的应用。例如,进程调度算法中的队列结构、文件系统中的树结构等都是数据结构的应用。
通过对数据结构的应用,我们可以更高效地组织和管理数据,提高算法的效率,实现更加优秀的软件系统。
# 6. C语言实现数据结构案例
本章将介绍如何利用C语言实现各种数据结构案例,包括数组、链表、栈与队列、二叉树、散列表等。每个案例都会包含详细的代码示例、注释、代码总结以及结果说明,帮助读者更好地理解和掌握数据结构的实现原理和方法。让我们一起深入学习吧!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏深入探讨了C语言在学生成绩计算中的应用,涵盖了从基础语法入门到数据结构应用的全面内容。文章逐一介绍了C语言的基础知识,包括变量与数据类型详解、运算符与表达式解析、条件语句if-else、循环语句while与for等等。此外,还详细讲解了C语言中数组的定义与应用、函数的定义与调用、指针的初探与应用、结构体的定义与应用等内容,同时涉及到文件操作、内存管理、模块化编程、递归算法、排序算法、查找算法、字符串操作等进阶主题。通过阅读本专栏,读者可以系统地学习C语言的相关知识,并将其运用到实际的成绩计算项目中,帮助读者在学术和职业中取得更好的成就。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
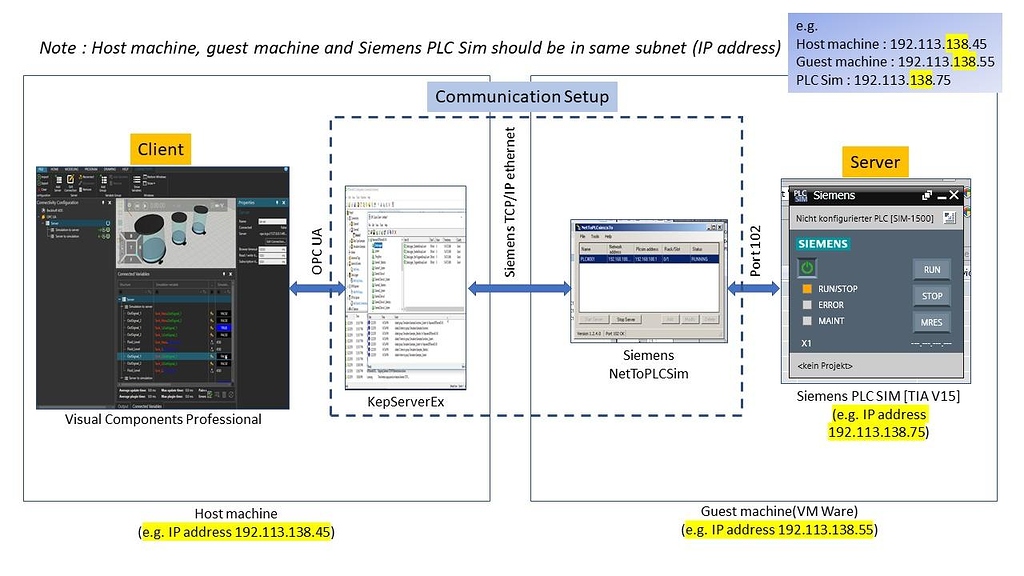
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )