构建大数据AI算法框架:专家级指南与最佳实践
发布时间: 2024-09-02 01:26:31 阅读量: 607 订阅数: 93 

大数据开发入门指南:从概念到实践.zip

# 1. 大数据AI算法框架概述
## 1.1 大数据AI算法框架的定义与重要性
大数据AI算法框架是构建在大规模数据处理能力基础之上,结合先进的人工智能算法,以支持复杂数据集的实时分析、决策支持和智能预测等需求。它对于企业来说,不仅能够帮助其在海量数据中发现模式,提取有价值信息,还能够驱动业务增长和创新。
## 1.2 框架的核心组成与功能
一个高效的大数据AI算法框架通常包括数据处理、存储和分析的组件,以及机器学习和深度学习算法的集成。其核心功能覆盖了从原始数据的采集、清洗、整合,到复杂算法模型的训练和部署。通过框架的运用,可以加速从数据到洞察再到行动的转化过程。
## 1.3 框架的发展趋势与应用前景
随着技术的进步,大数据AI算法框架正朝着更高的自动化、更优的性能和更广的应用场景发展。在互联网、金融、零售、医疗健康等行业,它们的应用前景广阔,能够极大提升企业的数据分析能力和决策智能化水平。
# 2. 理论基础与技术选型
在数字化转型的浪潮中,企业和组织越来越依赖于AI算法和大数据技术来提升决策质量、优化流程和创新服务。正确选择适合的技术框架,是构建成功的大数据应用的关键一步。本章节将深入探讨AI算法和大数据的概念,分析框架选择时需要考虑的因素,并介绍架构设计的原则。
## AI算法与大数据概念
AI算法和大数据技术是当今技术革新的两个重要领域,它们的结合为许多行业带来了前所未有的变革。首先,我们将分别了解AI算法的基础和大数据技术的演进。
### AI算法基础
AI算法包括多种技术,比如机器学习、深度学习、自然语言处理等。它们旨在让机器能够执行需要人类智能的任务,如学习、推理、感知、语言理解等。
#### 机器学习算法
机器学习是构建AI系统的核心技术之一,它通过让机器从数据中学习规律,提高预测或决策的准确性。常见的机器学习算法包括线性回归、决策树、支持向量机等。
```python
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
# 创建线性回归模型实例
lr = LinearRegression()
# 创建决策树回归模型实例
dt = DecisionTreeRegressor()
# 创建支持向量回归模型实例
svr = SVR()
# 模型使用和训练逻辑(省略)
# 模型评估逻辑(省略)
```
在上述代码中,我们使用了scikit-learn库来实例化三种不同的机器学习算法。每种算法都有其特点,选择哪种算法取决于数据的特性和问题的性质。
#### 深度学习模型架构
深度学习是机器学习的一个子领域,它使用神经网络来模拟人脑处理信息的方式,以发现数据的复杂结构。深度学习在图像识别、语音识别和自然语言处理等方面取得了巨大成功。
### 大数据技术演进
大数据技术涉及数据的采集、存储、分析和可视化。近年来,从Hadoop到Spark,再到云计算服务,大数据技术不断演进,以处理更大规模和更高复杂性的数据。
#### 分布式计算框架
Hadoop和Spark是分布式计算框架中的佼佼者,它们极大地推动了大数据分析能力的扩展。Hadoop的HDFS和MapReduce是处理大规模数据集的关键技术,而Spark提供了一个快速、通用的计算引擎,支持高效的数据处理。
```mermaid
flowchart LR
subgraph Spark
sparkCore[Spark Core]
sparkSQL[Spark SQL]
sparkStreaming[Spark Streaming]
sparkMLlib[MLlib]
sparkGraphX[GraphX]
end
HDFS --> sparkCore --> sparkSQL --> sparkStreaming --> sparkMLlib --> sparkGraphX --> DataVisualization
```
如图所示,Spark架构具有多个组件,允许执行不同类型的任务。它是一个强大的框架,能够处理实时数据流,进行大规模机器学习,以及图形处理。
## 框架选择的考量因素
选择合适的技术框架对于开发人员和架构师而言至关重要。考虑到性能、扩展性、社区支持和生态系统等多方面因素,才能确保大数据和AI项目的成功。
### 性能与扩展性
选择框架时,性能和扩展性是两个核心考虑点。性能决定了框架处理数据的速度和效率,而扩展性则关乎系统随数据量增长而升级的能力。
#### 性能考量
在选择框架时,需要评估其在各种工作负载下的表现。例如,在数据密集型任务中,对I/O的优化程度、内存使用效率和CPU占用率都是性能评估的关键指标。
```markdown
| 框架 | CPU效率 | 内存使用 | I/O速度 | 适用场景 |
|------|---------|----------|---------|----------|
| Hadoop | 高 | 中 | 低 | 大规模批处理 |
| Spark | 高 | 高 | 中 | 大数据处理和流分析 |
```
表格展示了不同框架在性能方面的比较,这有助于开发者根据项目的实际需求做出选择。
### 社区与商业支持
除了性能外,社区和商业支持也是选择框架的重要因素。一个活跃的社区意味着丰富的资源、工具和插件,能帮助开发者解决开发过程中的问题。
#### 商业支持
商业支持可以为项目的长期发展和稳定性提供保障。选择那些拥有强大商业支持的框架,可以降低由于技术变更或框架不再维护而带来的风险。
### 兼容性与生态系统
一个框架是否能与现有的技术和工具兼容,决定了其是否能在项目中快速部署。同时,一个良好的生态系统能够提供丰富的配套工具和服务,提升开发效率。
#### 技术兼容性
技术兼容性通常涉及到数据格式、API接口和编程语言。例如,一个与Python生态系统良好集成的框架,可能会受到数据科学和机器学习团队的青睐。
## 架构设计原则
构建稳健的大数据平台需要遵循一些基本的设计原则。模块化设计、高可用性和数据安全是三大核心原则,它们确保了平台的稳定运行和长期可持续性。
### 模块化设计
模块化设计允许系统被分解成独立且可替换的组件。这样的设计增强了系统的灵活性和可维护性,便于未来的升级和扩展。
#### 设计模块化的好处
模块化设计不仅仅简化了复杂系统的开发,还有利于资源的优化配置和功能的灵活组合。当单个模块出现故障时,它也便于快速定位和修复问题。
### 高可用与容错性
在大数据系统中,系统故障是不可避免的。因此,设计时必须考虑高可用性和容错性,以确保系统即使在组件故障时也能保持运行。
#### 容错性实现
实现容错性的一种常见方式是使用副本。例如,在分布式文件系统中,数据通常会分布在多个节点上,以确保即使部分节点失败,数据也依然可用。
### 数据安全与隐私保护
随着数据量的不断增长,数据安全和隐私保护变得尤为重要。敏感数据必须得到保护,防止未授权访问和数据泄露。
#### 加密技术的应用
为了保护数据安全,可以在数据存储和传输过程中应用加密技术。此外,访问控制和审计日志也是确保数据安全的重要措施。
在本章中,我们深入了解了AI算法和大数据的基础知识,讨论了框架选择的关键考量因素,并分享了架构设计的一些基本原则。理解这些知识对于在本领域取得成功至关重要,并将为构建高效稳定的大数据平台打下坚实的基础。
# 3. 构建企业级大数据平台
## 3.1 数据存储与管理
### 3.1.1 分布式文件系统
在处理企业级大数据时,分布式文件系统是关键的存储基础。分布式文件系统通过将数据分布在多个存储节点上,能够提供高吞吐量和容错能力。最著名的分布式文件系统之一是Hadoop的HDFS(Hadoop Distributed File System),它能够在成本较低的硬件上构建可靠的存储解决方案。HDFS采用了主从架构,其中NameNode负责管理文件系统的命名空间以及客户端对文件的访问,而DataNode则负责存储实际的数据。
为了达到更高的数据安全性和容错性,HDFS设计了数据副本机制。数据默认被复制三份,分别存储在不同的DataNode上,这使得即使某些节点发生故障,整个系统依然能持续工作。此外,HDFS支持数据的横向扩展,允许在不中断服务的情况下增加存储节点。
### 3.1.2 数据库选型与优化
大数据平台的数据库选型需要考虑数据的类型、访问模式、一致性要求以及可扩展性等因素。传统的关系型数据库在面对海量数据时可能面临性能瓶颈,因此NoSQL数据库应运而生。NoSQL数据库如Cassandra和MongoDB能够提供高可用性和水平扩展的能力。
Cassandra是一个分布式NoSQL数据库,特别适合于处理大量的写操作和查询请求。它提供了一个去中心化的架构,没有单点故障,并且可以通过增加节点来实现线性扩展。Cassandra的列族数据模型非常适合于需要高吞吐量、灵活数据模型的场景。
MongoDB则是一个面向文档的NoSQL数据库,它提供了丰富的查询能力,允许开发者用类似JSON的格式存储、检索数据。MongoDB的动态模式允许开发者在一个文档里存储不同的数据结构,这让应用数据模型的迭代变得更加容易。
数据库性能优化是一个持续的过程,包括但不限于索引优化、查询优化、分片策略等。例如,在MongoDB中,合理使用索引可以显著提升查询速度,但同时需要考虑索引维护对写操作的影响。对于Cassandra,分片策略的选择将直接影响负载均衡和查询性能。
## 3.2 数据处理与分析
### 3.2.1 批处理与实时处理框架
大数据处理框架大致可分为批处理和实时处理两类。批处理框架如Apache Hadoop通过MapReduce编程模型进行数据处理,能够处理PB级别的数据,并且擅长处理复杂的、需要大量计算的任务。Hadoop的MapReduce模型将处理任务分为Map阶段和Reduce阶段,Map阶段对输入数据进行分割,然后并行处理;Reduce阶段对Map阶段的输出结果进行汇总。
实时处理框架则对延迟要求较高,常见的有Apache Storm和Apache Flink。Storm支持微批处理,能够以毫秒级延迟处理数据流,适合实时分析场景。Flink则提供了一种流处理与批处理统一的编程模型,能够在同一个任务中同时进行流处理和批处理,提高了处理的灵活性和效率。
### 3.2.2 数据仓库与OLAP分析
在企业级大数据平台中,数据仓库用于集成和存储来自不同来源的数据,支持决策支持系统(DSS)中的在线分析处理(OLAP)分析。数据仓库系统如Amazon Redshift和Google BigQuery提供了高效率的数据存储与分析能力。
Amazon Redshift是一个完全托管的数据仓库服务,它允许用户通过标准的SQL接口来查询数据。为了提升查询性能,Redshift内部使用了列式存储和并行计算技术,这使得数据仓库能够快速进行大规模的数据分析。
Google BigQuery是另一种流行的分析数据仓库服务,它提供了极高的查询速度和可扩展性。BigQuery通过Dremel查询引擎实现了超大规模数据的快速分析,支持结构化和半结构化数据,并且可以和Google生态系统无缝集成。
在选择合适的数据仓库和OLAP解决方案时,需要评估企业的数据规模、使用模式、预算和集成需求等因素。对于需要快速分析数十PB级别的数据的企业来说,类似BigQuery的云服务可能更合适;而对于需要高度自定义和控制的企业,则可能会倾向于选择像Redshift这样的产品。
## 3.3 平台部署与维护
### 3.3.1 自动化部署工具
随着大数据平台的复杂性不断增加,自动化部署工具变得至关重要。自动化部署可以大幅缩短部署周期,提高部署的可靠性,并且降低因手工操作导致的错误。Apache Ambari是一个面向Hadoop的开源自动化部署工具,它提供了Web界面和RESTful API,使得用户能够轻松安装、管理和监控Hadoop集群。
Ambari通过蓝色/绿色部署(Blue/Green Deployment)模式,可以在不停机的情况下升级Hadoop集群。蓝色代表当前正在运行的服务,绿色代表新版本的服务。升级过程开始时,绿色环境是空的。一旦绿色环境完成配置并准备好接管流量,就可以通过简单的切换将流量从蓝色环境转移到绿色环境。
### 3.3.2 监控与日志管理
监控和日志管理是大数据平台稳定运行的保障。监控系统能够帮助IT运维人员实时了解系统状态,并在出现异常时及时响应。例如,Prometheus是一个开源的监控系统和警报工具,它使用Pull模式来获取数据,并支持复杂的查询语言。
Prometheus能够监控集群中的资源使用情况,如CPU、内存、网络IO等,并且可以对不同类型的指标进行聚合和分析。当监控到的指标超过预设阈值时,Prometheus可以触发警报,并通过邮件、短信或第三方服务通知运维人员。
日志管理则涉及到收集、存储、分析和查询日志数据。ELK栈(Elasticsearch, Logstash, Kibana)是目前较为流行的日志解决方案。Logstash负责日志的收集,可以处理来自不同源的日志数据;Elasticsearch作为搜索引擎,可以对日志数据进行存储和分析;Kibana提供了一个用户友好的界面,用于对日志数据进行可视化。
### 3.3.3 性能调优与故障排除
性能调优是大数据平台维护的一个重要方面。调优过程往往需要根据平台的具体使用情况和性能瓶颈来定制,没有一成不变的调优方案。通常涉及的方面包括资源分配、存储优化、执行计划调整等。例如,在使用Hadoop时,调整MapReduce任务的内存和CPU资源分配,或者针对特定的数据集选择合适的压缩算法,都可能对性能产生显著的影响。
故障排除是大数据平台运维过程中的常见任务。为了提高故障排除的效率,运维人员需要掌握各种诊断工具和方法。例如,Hadoop自带的YARN ResourceManager日志、HDFS NameNode日志和DataNode日志都是重要的故障诊断来源。同时,使用JMX(Java Management Extensions)可以实时监控Java应用的性能和资源使用情况。
故障排除的常见步骤包括确认故障现象、收集日志和监控数据、确定问题范围和定位故障点。比如,如果Hadoop集群的某个任务长时间无进展,运维人员可能首先会检查ResourceManager和NameNode的日志,然后通过网络工具确认各个节点之间的通信状态,最后可能需要深入检查运行任务的节点资源使用情况。
```mermaid
graph LR
A[开始故障排除] --> B[确认故障现象]
B --> C[收集日志和监控数据]
C --> D[确定问题范围]
D --> E[定位故障点]
E --> F[解决故障]
F --> G[验证和监控]
```
故障排除过程是迭代的,解决故障后需要对系统进行充分的验证和监控,确保问题已经被彻底解决,同时也为将来可能发生的类似问题提供经验参考。
# 4. AI算法在大数据中的应用
在现代IT领域中,将AI算法与大数据技术进行深度整合,已经成为推动行业发展的关键因素。第四章将深入探讨AI算法在大数据中的具体应用,揭示如何通过机器学习、深度学习等技术,为企业提供更智能、高效的解决方案。
## 4.1 机器学习算法集成
### 4.1.1 特征工程与数据预处理
在将机器学习算法应用于大数据之前,我们需要对原始数据进行一系列的预处理工作,以便于模型能够更好地从中学习。特征工程是预处理步骤中的核心,它包括对数据进行清洗、归一化、标准化、特征选择和提取等操作。
例如,在处理文本数据时,常常需要进行词干提取、去除停用词、向量化等预处理步骤。而面对数值型数据,可能需要进行缺失值处理、异常值检测和处理、数据离散化等操作。
```python
# 示例代码:使用pandas进行数据预处理
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 加载数据集
df = pd.read_csv('dataset.csv')
# 缺失值处理:用均值填充数值型数据的缺失值
df['numerical_column'] = df['numerical_column'].fillna(df['numerical_column'].mean())
# 异常值检测:使用Z-Score方法识别异常值
from scipy import stats
z_scores = np.abs(stats.zscore(df[['numerical_column']]))
df = df[(z_scores < 3).all(axis=1)]
# 数据标准化
scaler = StandardScaler()
df[['numerical_column']] = scaler.fit_transform(df[['numerical_column']])
# 保存预处理后的数据
df.to_csv('preprocessed_dataset.csv', index=False)
```
在代码块中,我们使用了`pandas`库对数据集进行加载和预处理操作。`StandardScaler`用于标准化数值型特征,以确保它们具有零均值和单位方差,从而加速模型的收敛。
### 4.1.2 常见机器学习模型
在数据预处理完毕之后,下一步就是应用机器学习模型。机器学习模型的种类繁多,包括线性回归、决策树、随机森林、支持向量机等。这些模型各有优劣,适用于不同的数据类型和业务场景。
在选择模型时,我们通常需要考虑数据的特征、数据量的大小、模型的复杂度、计算资源等因素。例如,对于非线性数据集,决策树或随机森林可能会有更佳的表现。
```python
# 示例代码:使用scikit-learn实现简单的线性回归模型
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载数据集
X = df.drop('target_column', axis=1)
y = df['target_column']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 实例化模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
predictions = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
```
在这段代码中,我们利用`scikit-learn`库实现了线性回归模型的训练和预测。通过划分训练集和测试集,我们能够评估模型在未知数据上的性能。
### 4.1.3 模型训练与评估
模型训练和评估是一个循环过程。在完成初步的模型训练之后,我们通常会通过交叉验证和超参数调优来优化模型性能。接着,使用准确率、精确率、召回率、F1分数等指标对模型进行评估。
```python
# 示例代码:使用交叉验证和网格搜索进行模型优化
from sklearn.model_selection import GridSearchCV
# 定义超参数网格
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30]
}
# 实例化随机森林模型
rf = RandomForestClassifier(random_state=42)
# 初始化网格搜索
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1)
# 执行网格搜索
grid_search.fit(X_train, y_train)
# 输出最佳参数组合和分数
print(f'Best parameters: {grid_search.best_params_}')
print(f'Best score: {grid_search.best_score_}')
```
在这段代码中,我们使用了`GridSearchCV`来对随机森林分类器的超参数进行优化。通过五折交叉验证(`cv=5`),我们能够更稳定地评估不同参数组合的性能,并找到表现最优的参数设置。
## 4.2 深度学习框架整合
### 4.2.1 深度学习模型架构
深度学习模型,尤其是卷积神经网络(CNN)和循环神经网络(RNN),在图像识别、语音识别、自然语言处理等领域取得了显著的成功。深度学习模型通常具有更多的层次和参数,使得它们能够学习复杂的非线性关系。
当我们构建深度学习模型时,通常需要使用如TensorFlow或PyTorch这样的高级深度学习框架。这些框架提供了自动求导、优化器、神经网络层等构建模块,极大地简化了模型的实现过程。
### 4.2.2 GPU加速与分布式训练
由于深度学习模型的训练过程非常计算密集,使用GPU进行加速已经成为一种常态。此外,在面对大规模数据集时,分布式训练成为提高效率和扩展性的重要手段。
分布式训练不仅涉及数据的分布式存储和处理,还涉及模型参数的同步更新。在实际应用中,需要考虑到不同设备之间的通信开销和资源管理。
### 4.2.3 模型部署与服务化
一旦深度学习模型经过训练和验证,下一步就是将其部署到生产环境。模型部署需要考虑模型的持久化存储、服务化接口的实现、负载均衡和自动扩展等问题。
使用如TensorFlow Serving、TorchServe等工具,可以方便地将训练好的模型封装成RESTful API或gRPC服务,从而实现模型的快速上线和运维。
## 4.3 实时分析与决策系统
### 4.3.1 流处理技术
在实时分析领域,流处理技术(如Apache Kafka、Apache Flink、Apache Storm等)允许我们对连续输入的数据流进行即时处理。这些技术通常与复杂的事件处理(CEP)相结合,用于检测和响应数据中的模式和异常。
流处理不仅能够提升数据处理的时效性,还可以通过滑动窗口等机制,对数据流中的时间序列进行分析。
### 4.3.2 在线学习与动态调整
在线学习是实时分析中的一个关键概念,它允许模型在接收到新的数据样本时进行即时更新。与传统批处理方法不同,这种方法避免了模型的周期性重训练,从而节省计算资源。
在实践中,实现在线学习通常需要构建支持增量学习的模型结构,或是设计能够持续更新参数的算法。
### 4.3.3 智能决策支持系统
实时分析的最终目的是为了辅助或自动化决策过程。智能决策支持系统(IDSS)融合了数据分析、人工智能和优化算法,能够根据实时数据分析结果给出最优或推荐的决策方案。
在构建IDSS时,需要综合考虑业务规则、决策逻辑、风险评估等因素,以确保决策的准确性和可靠性。
以上为第四章的详细介绍。从机器学习算法的集成到深度学习框架的整合,再到实时分析与决策系统的构建,本章内容旨在为读者提供一个全面的视角,理解AI算法如何与大数据技术相结合,应用于解决实际问题。
# 5. 实践案例分析
## 5.1 案例研究:金融行业的大数据AI应用
### 5.1.1 风险管理与欺诈检测
金融行业是最早采用大数据和AI技术进行风险管理与欺诈检测的领域之一。利用大数据分析,金融机构能够实时监控交易数据,识别异常模式,并预测潜在的欺诈行为。AI算法如随机森林、支持向量机(SVM)和神经网络被广泛应用来构建欺诈检测模型。
为了构建高效的欺诈检测模型,通常需要进行以下步骤:
1. 数据收集:整合多种来源的数据,包括交易记录、用户行为日志和外部数据源。
2. 数据预处理:处理缺失值、异常值、归一化和标准化数据。
3. 特征提取:使用统计分析、时间序列分析等技术提取相关特征。
4. 模型训练:利用历史交易数据训练AI模型。
5. 模型评估与优化:评估模型的准确性、召回率和F1分数等指标,并基于反馈进行优化。
以下是一个简单的Python代码示例,展示了如何使用Scikit-learn库中的随机森林算法来训练一个欺诈检测模型:
```python
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
import pandas as pd
# 加载数据集
data = pd.read_csv('financial_data.csv')
# 特征与标签分离
X = data.drop('is_fraud', axis=1) # 特征数据
y = data['is_fraud'] # 标签数据(1表示欺诈,0表示正常)
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化随机森林分类器
clf = RandomForestClassifier(n_estimators=100)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
predictions = clf.predict(X_test)
# 评估模型
print(classification_report(y_test, predictions))
print("Model Accuracy:", accuracy_score(y_test, predictions))
```
在上述代码中,`RandomForestClassifier`用于创建随机森林分类器实例,`train_test_split`用于分割数据集,`classification_report`和`accuracy_score`用于输出模型的性能指标。这个模型经过训练和评估后,可以用来预测新交易是否属于欺诈。
### 5.1.2 客户画像与行为分析
在风险管理之外,金融行业也利用大数据AI技术对客户进行画像,以更准确地了解客户群体和行为。通过分析客户的交易习惯、投资偏好和信用历史等信息,金融机构能够提供更加个性化的服务,从而提高客户满意度和忠诚度。
构建客户画像的关键步骤包括:
1. 客户数据整合:收集客户的基本信息、交易记录、市场反馈等。
2. 数据清洗与转换:确保数据的质量,包括缺失值处理、数据类型转换和重复数据删除。
3. 客户细分:根据客户的行为特征和价值,使用聚类算法将客户分为不同的群体。
4. 行为分析:运用预测模型分析客户行为趋势。
5. 结果应用:基于客户画像和行为分析结果,设计定制化的营销策略和服务。
下面的Python代码示例展示了如何使用K-means算法进行客户细分:
```python
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 假设已有客户特征数据集
customer_data = pd.read_csv('customer_data.csv')
# 特征选择(示例:年龄、消费频率、平均交易额)
features = customer_data[['age', 'frequency_of_purchase', 'average_transaction_value']]
# 使用K-means算法进行客户细分,这里假设我们希望将客户分为5类
kmeans = KMeans(n_clusters=5, random_state=42)
kmeans.fit(features)
# 将聚类结果添加到原始数据中
customer_data['cluster'] = kmeans.labels_
# 可视化结果
plt.scatter(customer_data['age'], customer_data['frequency_of_purchase'], c=customer_data['cluster'])
plt.title('Customer Segmentation')
plt.xlabel('Age')
plt.ylabel('Frequency of Purchase')
plt.show()
```
在这段代码中,`KMeans`用于创建K-means聚类模型,`fit`用于拟合数据并确定聚类中心,最后通过散点图可视化不同客户群组。通过这种方式,金融机构能够更好地了解其客户群体的特征,并基于这些信息来优化产品和服务。
## 5.2 案例研究:零售行业的智能推荐系统
### 5.2.1 用户行为数据收集与分析
零售行业通过用户的浏览记录、购买历史、点击数据等收集用户行为信息。这些数据的收集与分析,对于提供个性化推荐至关重要。智能推荐系统依赖这些数据来预测用户偏好,从而推荐商品或服务。
### 5.2.2 推荐算法的实现与优化
推荐系统通常采用基于内容的推荐、协同过滤、混合推荐等方法。这里以协同过滤为例,介绍推荐系统的实现和优化过程:
1. 数据处理:清洗和准备用户-物品交互数据。
2. 相似度计算:计算用户之间或物品之间的相似度。
3. 推荐生成:根据相似度计算结果,为用户生成推荐列表。
4. 模型评估:使用交叉验证等方法评估推荐系统的性能。
5. 模型优化:调整推荐算法参数,如学习率、迭代次数等,以提升推荐质量。
下面的Python代码使用了`surprise`库中的`SVD`算法实现协同过滤推荐系统:
```python
from surprise import SVD, Dataset, Reader, accuracy
from surprise.model_selection import train_test_split
# 加载数据集
data = Dataset.load_builtin('ml-100k')
# 分割数据集为训练集和测试集
trainset, testset = train_test_split(data, test_size=0.25)
# 使用SVD算法
algo = SVD()
# 训练模型
algo.fit(trainset)
# 预测测试集
predictions = algo.test(testset)
# 计算和输出 RMSE
accuracy.rmse(predictions)
```
在这个代码中,`SVD`用于创建奇异值分解模型,`train_test_split`用于分割数据集,`accuracy.rmse`用于计算均方根误差(RMSE),评估推荐系统的性能。通过调整SVD算法的参数,可以进一步优化推荐结果的准确性和推荐的质量。
## 5.3 案例研究:医疗健康的数据分析与预测
### 5.3.1 电子健康记录的处理
随着电子健康记录(EHR)的普及,医疗行业正收集着大量的患者健康数据。通过分析这些数据,可以帮助医生更快速准确地诊断疾病,并提供个性化的治疗方案。
### 5.3.2 疾病预测模型的构建
构建疾病预测模型通常涉及以下步骤:
1. 数据获取:整合患者的医疗记录、化验结果和遗传信息。
2. 数据预处理:处理缺失值、异常值、归一化等。
3. 特征选择:根据医疗专家的建议和统计分析确定重要特征。
4. 模型构建:利用机器学习算法构建预测模型。
5. 验证与评估:使用交叉验证、混淆矩阵等技术评估模型准确性。
以下是一个简单的Python代码示例,使用逻辑回归算法构建疾病预测模型:
```python
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
# 假设已有患者的特征数据集和标签数据集
features = pd.read_csv('patient_features.csv')
labels = pd.read_csv('patient_labels.csv')
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.3, random_state=42)
# 初始化逻辑回归模型
lr = LogisticRegression()
# 训练模型
lr.fit(X_train, y_train)
# 预测测试集
predictions = lr.predict(X_test)
# 生成混淆矩阵
cm = confusion_matrix(y_test, predictions)
print("Confusion Matrix:")
print(cm)
```
在这段代码中,`LogisticRegression`用于创建逻辑回归分类器,`train_test_split`用于分割数据集,`confusion_matrix`用于输出模型的混淆矩阵,用以评估模型的分类性能。通过这样的模型,医疗专业人士可以更准确地预测疾病风险,为患者提供更好的治疗方案。
通过这些实践案例,我们看到了大数据AI技术在不同行业中的强大应用潜力。它们不仅能够帮助企业优化内部流程,提升服务质量,还能够带来创新的商业模式和改进的用户体验。
# 6. ```
# 第六章:未来趋势与挑战
随着技术的迅速发展,AI与大数据的融合呈现出前所未有的机遇。这一章我们将探讨AI与大数据未来可能的发展趋势、所面临的挑战以及应对这些挑战的策略。
## 6.1 AI与大数据的融合前景
### 6.1.1 新兴技术的集成
AI和大数据的融合前景广阔,这一领域的新兴技术正不断涌现。例如,云计算和边缘计算的结合,为大规模数据分析提供了灵活的资源分配机制。同时,量子计算、5G网络和物联网技术的发展将极大地促进数据的产生和实时处理能力。此外,区块链技术在确保数据安全和完整性方面具有潜在优势,也可能与AI和大数据产生协同效应。
### 6.1.2 业务模式的创新
AI与大数据的结合也将推动企业业务模式的创新。通过深度学习和自然语言处理等AI技术,企业能够从非结构化数据中提取洞见,为消费者提供更为个性化的产品和服务。同时,AI驱动的预测分析可以改变供应链管理,实现更为高效和动态的库存控制和需求预测。
## 6.2 挑战与应对策略
### 6.2.1 数据质量和隐私问题
尽管大数据与AI的应用前景诱人,但数据质量和隐私保护也是不容忽视的问题。在大数据环境中,数据的准确性和完整性是AI模型性能的关键。因此,确保数据的质量是首先要解决的问题。此外,随着数据的广泛收集和应用,个人隐私保护变得尤为重要。企业必须遵守各种数据保护法规,如欧盟的通用数据保护条例(GDPR),并采取先进的数据脱敏和加密技术来保护用户隐私。
### 6.2.2 法规遵从与伦理考量
除了技术挑战,AI和大数据还涉及到广泛的法规遵从和伦理问题。企业需要关注AI算法可能带来的偏见和歧视问题,确保算法的公平性和透明性。同时,企业还需要遵守相关行业标准和法律法规,确保数据的合法使用和处理。
## 6.3 持续学习与技能提升
### 6.3.1 专业发展路径
对于IT行业的从业者来说,AI与大数据的结合带来了新的职业发展机会。从业者需要不断学习新的技术和工具,如Spark、TensorFlow、Keras等,并理解其在实际业务场景中的应用。除了技术能力,数据分析师还需要增强其业务理解能力,以便更好地从数据中提取有价值的商业洞见。
### 6.3.2 教育培训与认证
为了应对AI和大数据领域不断增长的人才需求,教育机构和专业培训组织正在开发相关课程和认证项目。例如,谷歌、IBM和微软等公司提供了云服务和AI相关的在线课程和认证。参加这些课程和获得认证不仅能够提升个人技能,而且有助于在竞争激烈的就业市场中脱颖而出。
## 总结
本章我们探讨了AI与大数据融合的未来趋势、面临的挑战以及如何在这一领域保持个人技能的竞争力。随着技术的不断进步和应用的不断深入,这将是一个持续学习和适应的过程。我们期待这一领域为我们的社会带来更多的变革和发展。
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了人工智能算法与大数据的融合,重点关注其潜力、应用、优化策略和挑战。文章涵盖了广泛的主题,包括机器学习模型优化、AI算法框架构建、大数据分析挑战、AI驱动的应用案例、数据挖掘法则、大数据背景下的AI算法突破、协同效应和分析技巧、实时大数据处理、性能提升技巧、高维数据分析、深度学习优化、数据隐私保护、伦理考量、非结构化数据处理、精准预测模型、物联网数据流处理、自我学习机制和行业趋势。通过深入分析和专家见解,本专栏为读者提供了对这一变革性领域的全面理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘HID协议:中文版Usage Tables实战演练与深入分析

# 摘要
人类接口设备(HID)协议是用于计算机和人机交互设备间通信的标准协议,广泛应用于键盘、鼠标、游戏控制器等领域。本文首先介绍了HID协议的基本概念和理论基础,深入分析了其架构、组成以及Usage Tables的定义和分类。随后,通过实战演练,本文阐述了如何在设备识别、枚举和自定
【掌握核心】:PJSIP源码深度解读与核心功能调试术

# 摘要
PJSIP是一个广泛使用的开源SIP协议栈,它提供了丰富的功能集和高度可定制的架构,适用于嵌入式系统、移动设备和桌面应用程序。本文首先概述了PJ
【网络稳定性秘籍】:交换机高级配置技巧,揭秘网络稳定的秘诀

# 摘要
交换机作为网络基础设施的核心设备,其基本概念及高级配置技巧对于保障网络稳定性至关重要。本文首先介绍了交换机的基本功能及其在网络稳定性中的重要性,然后深入探讨了交换机的工作原理、VLAN机制以及网络性能指标。通过理论和实践结合的方式,本文展示了如何通过高级配置技巧,例如VLAN与端口聚合配置、安全设置和性能优化来提升网络的可靠性和
Simtrix.simplis仿真模型构建:基础知识与进阶技巧(专业技能揭秘)

# 摘要
本文全面介绍了Simtrix.simplis仿真模型的基础知识、原理、进阶应用和高级技巧与优化。首先,文章详细阐述了Simtrix.simplis仿真环境的设置、电路图绘制和参数配置等基础操作,为读者提供了一个完整的仿真模型建立过程。随后,深入分析了仿真模型的高级功能,包括参数扫描、多域仿真技术、自定义模
【数字电位器电压控制】:精确调节电压的高手指南

# 摘要
数字电位器作为一种可编程的电阻器,近年来在电子工程领域得到了广泛应用。本文首先介绍了数字电位器的基本概念和工作原理,随后通过与传统模拟电位器的对比,凸显其独特优势。在此基础上,文章着重探讨了数字电位器在电压控制应用中的作用,并提供了一系列编程实战的案例。此外,本文还分享了数字电位器的调试与优化技
【通信故障急救】:台达PLC下载时机不符提示的秒杀解决方案

# 摘要
本文全面探讨了通信故障急救的全过程,重点分析了台达PLC在故障诊断中的应用,以及通信时机不符问题的根本原因。通过对通信协议、同步机制、硬件与软件配合的理论解析,提出了一套秒杀解决方案,并通过具体案例验证了其有效性。最终,文章总结了成功案例的经验,并提出了预防措施与未来通信故障处理的发展方向,为通信故障急救提供了理论和实践上的指导。
# 关键字
通信故障;PLC故障诊断;通信协议;同步机制;故障模型
【EMMC协议深度剖析】:工作机制揭秘与数据传输原理解析

# 摘要
本文对EMMC协议进行了全面的概述和深入分析。首先介绍了EMMC协议的基本架构和组件,并探讨了其工作机制,包括不同工作模式和状态转换机制,以及电源管理策略及其对性能的影响。接着,深入分析了EMMC的数据传输原理,错误检测与纠正机制,以及性能优化策略。文中还详细讨论了EMMC协议在嵌入式系统中的应用、故障诊断和调试,以及未来发展趋势。最后,本文对EMMC协议的扩展和安全性、与
【文件哈希一致性秘籍】:揭露Windows与Linux下MD5不匹配的真正根源
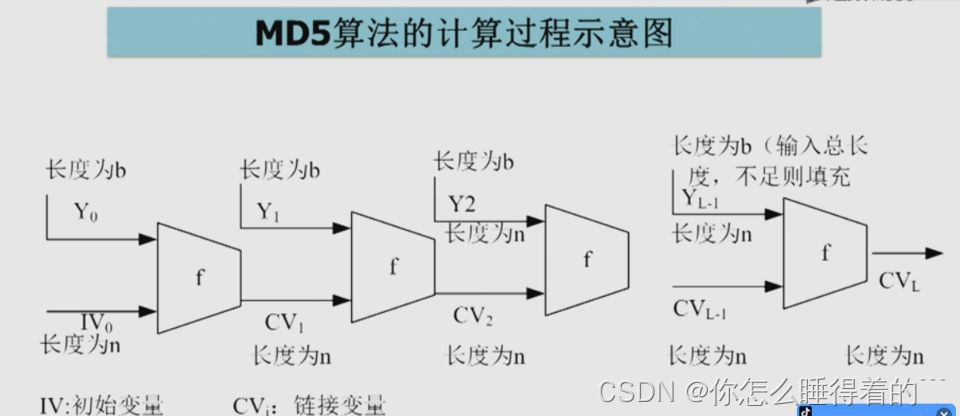
# 摘要
本文首先介绍了哈希一致性与MD5算法的基础知识,随后深入探讨了MD5的工作原理、数学基础和详细步骤。分析了MD5算法的弱点及其安全性问题,并对Windows和Linux文件系统的架构、特性和元数据差异进行了比较。针对MD5不匹配的实践案例,本文提供了原因分析、案例研究和解决方案。最后,探讨了哈希一致性检查工具的种类与选择、构建自动化校验流程的方法,并展望了哈希算法的未
高速数据采集:VISA函数的应用策略与技巧

# 摘要
高速数据采集技术在现代测量、测试和控制领域发挥着至关重要的作用。本文首先介绍了高速数据采集技术的基础概念和概况。随后,深入探讨了VISA(Virtual Instrument Soft
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )