融合事件循环:twisted.internet.task与事件驱动的高级应用
发布时间: 2024-10-13 23:49:25 阅读量: 20 订阅数: 23 
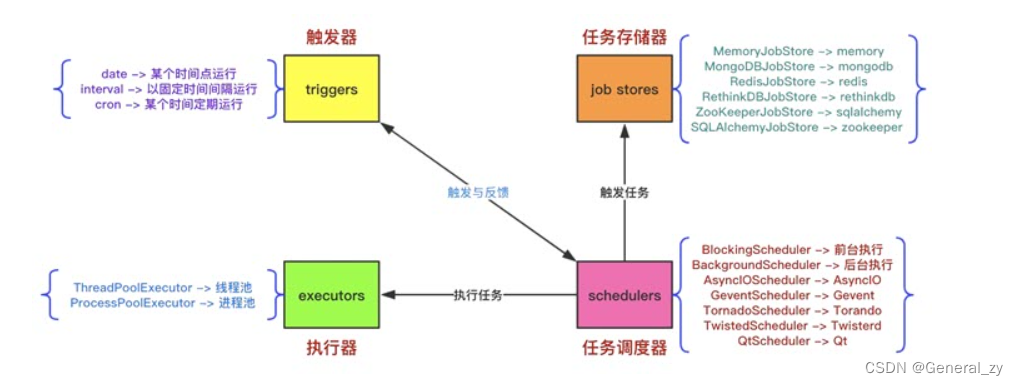
# 1. 事件驱动编程模型概述
事件驱动编程是一种重要的编程范式,它以事件为核心,通过监听和响应事件来驱动程序的执行。这种模式特别适用于需要处理大量并发操作的场景,如网络编程、图形用户界面(GUI)开发等。
## 事件驱动编程的核心概念
在事件驱动模型中,程序的流程不是由函数调用顺序决定的,而是由外部事件的发生来推动的。当一个事件发生时,程序会执行相应的事件处理函数,进行必要的操作。
### 事件循环基础
事件循环是事件驱动编程的核心机制。它负责监听事件的发生,并将事件分发给相应的事件处理函数。事件循环通常会持续运行,直到程序被停止或者遇到无法处理的错误。
### 事件驱动的优势
事件驱动编程模型的优势在于它的异步特性和高效的资源利用。由于事件处理函数可以在不同的线程中并发执行,因此它能够有效地处理并发事件,提高程序的响应速度和吞吐量。
# 2. Twisted框架简介
Twisted是一个事件驱动的网络编程框架,它为Python编程语言提供了一个强大的基础设施,用于构建网络应用和并发程序。本章节将深入探讨Twisted框架的核心概念、安装与配置以及基本组件。
## 2.1 Twisted框架的核心概念
### 2.1.1 事件循环基础
事件驱动编程模型的核心是事件循环(event loop),它负责监听和处理各种事件,如网络I/O事件、定时器事件等。Twisted框架使用单线程的事件循环来处理并发操作,这种设计使得编写复杂的并发程序变得更加简单。
在Twisted中,事件循环是由reactor对象来维护的。reactor负责监听各种事件源,并在事件发生时调用相应的事件处理函数。下面是一个简单的示例代码,展示了如何使用Twisted的reactor对象来处理一个定时器事件:
```python
from twisted.internet import reactor
def print_number(number):
print(number)
reactor.stop()
reactor.callLater(5, print_number, 1) # 5秒后调用print_number函数
reactor.run() # 启动事件循环
```
在这个例子中,`callLater`方法用于在指定的时间后执行一个回调函数。这里的`print_number`函数将在5秒后被调用,并且事件循环随后停止。
### 2.1.2 Deferred对象的工作原理
在Twisted中,Deferred对象是处理异步操作的一种机制。它是一个封装了回调函数和错误处理的对象,用于在异步操作完成时调用正确的回调函数。
Deferred对象的工作流程如下:
1. 创建一个Deferred对象。
2. 注册回调函数,这些函数将在异步操作成功完成时被调用。
3. 注册错误处理函数,这些函数将在异步操作失败时被调用。
4. 调用Deferred对象的`callback`方法来通知操作成功完成。
5. 调用Deferred对象的`errback`方法来通知操作失败。
下面是一个使用Deferred对象处理网络请求的例子:
```python
from twisted.internet import reactor, defer
from twisted.web.client import get
def got_response(response):
print(response.code)
deferred.callback(response)
def got_err(error):
print(error)
deferred.errback(error)
deferred = defer.Deferred()
url = "***"
d = get(url)
d.addCallback(got_response)
d.addErrback(got_err)
reactor.run()
```
在这个例子中,我们使用Twisted的`get`方法来发起一个HTTP GET请求。我们注册了`got_response`和`got_err`函数分别处理成功和失败的情况。当请求完成时,我们调用`deferred.callback(response)`或`deferred.errback(error)`来通知Deferred对象。
## 2.2 Twisted框架的安装与配置
### 2.2.1 安装Twisted环境
安装Twisted框架可以通过Python的包管理工具pip来完成。在命令行中运行以下命令即可安装Twisted:
```bash
pip install twisted
```
安装完成后,你可以通过Python解释器来验证Twisted是否安装成功:
```python
from twisted.internet import reactor
print(reactor)
```
如果安装成功,上述代码将输出Twisted的reactor对象的信息。
### 2.2.2 配置开发环境和调试工具
配置Twisted的开发环境通常包括安装一些常用的开发和调试工具,如代码编辑器、IDE以及Twisted专用的调试工具。Twisted社区推荐使用以下工具:
- **文本编辑器/IDE**: Visual Studio Code、PyCharm、Sublime Text等。
- **版本控制系统**: Git。
- **虚拟环境**: virtualenv或conda。
- **调试工具**: pdb、twistd、trial等。
例如,使用Python的虚拟环境工具virtualenv可以创建一个隔离的环境来安装和运行Twisted:
```bash
virtualenv twisted_env
source twisted_env/bin/activate
pip install twisted
```
激活虚拟环境后,你可以在这个环境中运行Twisted应用,而不会影响到系统中的其他Python项目。
## 2.3 Twisted框架的基本组件
### 2.3.1 reactor对象的使用
reactor是Twisted框架的核心组件,它负责维护事件循环,并提供了一系列的API来注册事件监听器和处理回调函数。在实际应用中,我们通常不需要直接操作reactor对象,而是通过Twisted提供的各种协议和传输机制来实现网络通信。
reactor的主要功能包括:
- 监听网络事件。
- 处理定时器事件。
- 管理资源,如文件描述符。
- 启动和停止事件循环。
下面是一个使用reactor监听网络事件的例子:
```python
from twisted.internet import reactor
def print_data(data):
print(data)
def print_error(error):
print(error)
reactor.listenTCP(8000, myProtocol()) # 监听8000端口
reactor.run()
```
在这个例子中,我们创建了一个自定义的协议`myProtocol`(这里没有展示具体实现),并使用`listenTCP`方法来监听8000端口。当有新的连接到来时,reactor会自动处理并调用`print_data`函数。
### 2.3.2 协议和传输机制
Twisted提供了丰富的协议和传输机制来支持不同类型的网络通信。这些协议和传输机制都遵循异步编程模型,使得开发者可以轻松地构建高性能的网络应用。
Twisted的主要协议包括:
- **客户端协议**: `twisted.internet.protocol.ClientFactory`用于创建客户端连接。
- **服务器协议**: `twisted.internet.protocol.Factory`用于创建服务器监听。
- **SSL/TLS支持**: `twisted.internet.ssl`提供了SSL/TLS的加密支持。
传输机制方面,Twisted支持TCP和UDP等标准传输协议,并提供了一些高级传输特性,如非阻塞I/O、慢速客户端处理等。
以下是一个简单的TCP服务器示例:
```python
from twisted.internet import reactor
from twisted.internet.protocol import Factory
from twisted.protocols.basic import StreamServerProtocol
class EchoStreamServerProtocol(StreamServerProtocol):
def connectionMade(self):
print("Connection from:", self.transport.getPeer())
def connectionLost(self, reason):
print("Connection lost:", reason)
def dataReceived(self, data):
self.transport.write(data)
self.transport.loseConnection()
factory = Factory()
factory.protocol = EchoStreamServerProtocol
reactor.listenTCP(1234, factory)
reactor.run()
```
在这个TCP服务器示例中,我们定义了一个`EchoStreamServerProtocol`类,它继承自`StreamServerProtocol`。每当有新连接到来时,`connectionMade`方法会被调用。数据接收通过`dataReceived`方法处理,并将接收到的数据回写给客户端,然后关闭连接。
以上内容仅是对Twisted框架的简介,接下来的章节将进一步深入探讨Twisted.internet.task模块以及事件驱动在实际应用中的高级应用。
# 3. Twisted.internet.task模块深入
## 3.1 Task模块的基本用法
### 3.1.1 延迟执行与周期任务
在Twisted框架中,`Task`模块提供了延迟执行任务(deferred execution)和周期任务(periodic tasks)的功能。这些功能是通过`Deferred`对象和定时器实现的,允许开发者以非阻塞的方式执行延迟调用或重复调用。
延迟执行是通过`deferLater`函数实现的,它接受三个参数:延迟时间(以秒为单位)、反应器(reactor)和回调函数。回调函数将在指定的延迟时间后执行。例如,以下代码段展示了如何延迟10秒后执行一个函数:
```python
from twisted.internet import reactor
from twisted.internet.task import deferLater
def callback():
print("延迟执行完成")
deferred = deferLater(reactor, 10, callback)
```
周期任务则是通过`callLater`函数实现的,它同样接受两个参数:延迟时间和回调函数。但是,回调函数将重复执行,直到它返回`None`或被取消。例如,以下代码段展示了如何每3秒执行一次函数:
```python
from twisted.internet import reactor
from twisted.internet.task import callLater
def periodic_task():
print("周期任务执行")
# 第一次执行延迟1秒,之后每3秒执行一次
callLater(1, periodic_task)
callLater(3, periodic_task)
# 为了在周期任务执行时反应器仍在运行,我们启动反应器
reactor.run()
```
### 3.1.2 任务调度的实践案例
任务调度在实际应用中非常有用,比如定时检查某些条件、定时更新状态、定时执行清理工作等。下面是一个实际案例,展示了如何使用`Task`模块来定期检查一个文件的状态,并在文件内容发生变化时执行特定的操作。
```python
from twisted.internet import reactor
from twisted.internet.task import callLater
import time
def check_file_change():
# 假设check_file_change是一个检查文件状态的函数
# 如果文件发生变化,则打印一条消息
file_content = get_file_content() # 这是一个假设的函数
if file_content != last_content:
print("文件已更改")
last_content = file_content
return True # 返回True表示继续执行周期任务
def start_periodic_task():
global last_content
last_content = get_file_content() # 获取初始文件内容
callLater(5, start_periodic_task) # 每5秒检查一次文件状态
get_file_content = lambda: "content" # 假设的获取文件内容的函数
start_periodic_task() # 启动周期任务
reactor.run()
```
## 3.2 高级时间控制技巧
### 3.2.1 时间延迟的精确度
在使用`Task`模块进行时间延迟操作时,精确度是一个重要的考量因素。Twisted框架的反应器是基于时间片轮转调度的,这意味着延迟的执行可能会有微小的偏差。然而,这种偏差通常对于大多数应用来说是可以接受的。
如果需要更精确的控制延迟时间,可以使用`callLater`的返回值`callId`来取消已经安排的延迟任务。以下是一个示例:
```python
from twisted.internet import reactor
from twisted.inter
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏深入探讨了 Python 库 twisted.internet.task 模块,提供了一系列全面的指南,涵盖了任务调度、定时器、Deferred 对象、循环任务、自定义调度策略、错误处理、事件循环集成、性能优化、任务依赖管理和最佳实践。通过源码剖析、使用指南、实践案例和进阶教程,本专栏旨在帮助开发者掌握 twisted.internet.task 的核心概念和高级技巧,从而构建高效、可扩展且健壮的异步应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
硬件优化秘籍:MV88芯片性能提升的10大策略

# 摘要
MV88芯片作为高性能计算平台的核心,面临诸多性能挑战。本文首先介绍了MV88芯片的基本架构及其性能挑战,随后深入探讨了硬件优化的理论基础,包括硬件优化的目标与意义、性能评估方法以及理论模型。在硬件性能提升方面,本文详述了电路设计、制造工艺改进和热管理等关键技术实践。软件协同优
【ANSYS Q3D Extractor 速成指南】:零基础开启电磁场分析之旅

# 摘要
本文全面介绍了ANSYS Q3D Extractor软件的使用,包括其简介、安装、基础操作、理论基础以及在实际项目中的应用。首先,我们讨论了软件的界面布局、功能模块、建立模型、网格划分和执行分析等基础操作。接着,
【南邮软件工程课程设计】:揭开教务系统构思与挑战的神秘面纱
# 摘要
教务系统作为高校信息化建设的重要组成部分,其设计与实现直接影响到教学管理的效率与质量。本文首先介绍了教务系统设计的概念框架,随后深入分析了核心功能,包括学生信息管理、课程与选课系统以及成绩管理系统的具体实现细节。在第三章中,本文讨论了教务系统的设计实践,包括数据库设计、系统架构的选择和安全性与可靠性设计。文章第四章探讨了教务系统在实际应用中面临的挑战,并提出了相应的解决方案。最后,通过
搭建与维护Maven仓库:中央与私有仓库的专家级指南

# 摘要
本文全面概述了Maven仓库的运作机制及其在软件构建过程中的重要性。通过探讨中央仓库的管理方式和私有仓库的搭建配置,本文为读者提供了深入理解和应用Maven仓库的实用指南。此外,本文着重分析了仓库管理的高级实践,讨论了仓库的安全性和备份策略,并提供了性能调优与故障排除的详细策略。文章旨在帮助开发团队更高效地管理软件依赖,确保构建过程的稳定性和安全性,同时
S57与S52标准深度对比:行业选择策略与关键差异
# 摘要
随着通信技术的发展,S57与S52标准在相关行业的应用变得尤为重要。本文首先概述了S57与S52标准的基本框架和行业背景,随后探讨了选择行业标准的策略,包括市场背景和技术兼容性等关键因素。在深度对比分析中,文章着重考察了两种标准在结构、性能、效率以及实施维护方面的差异。进一步,本文分析了这些关键差异对行业应用、产品开发以及最终用户的具体影响,并提出了实践中的策略建议。最后,通过案例研究,本文总结了行业选择策略的实际应用,并对未来的发展趋势进行了展望,同时指出了本研究的局限性和未来方向。
# 关键字
S57标准;S52标准;行业选择策略;技术兼容性;性能与效率;实施与维护
参考资源
Ubuntu文件系统揭秘:深度剖析Qt文件覆盖的根本原因

# 摘要
本文旨在深入探讨Ubuntu文件系统和Qt框架文件操作的交互作用,尤其是文件覆盖问题。首先,本文对Ubuntu文件系统进行概述,并阐述了Linux文件系统原理
家谱二叉树层次遍历:快速定位直系亲属的秘诀
/i.s3.glbimg.com/v1/AUTH_da025474c0c44edd99332dddb09cabe8/internal_photos/bs/2022/l/u/6Tw8o3QeeTFC5P5BArBA/pele-sete-filhos.jpg)
# 摘要
家谱二叉树作为一种重要的数据结构,在信息管理和遗传学研究中具有广泛应用。本文全
【DNAMAN高级应用】:8个技巧优化PCR条件,减少非特异性扩增
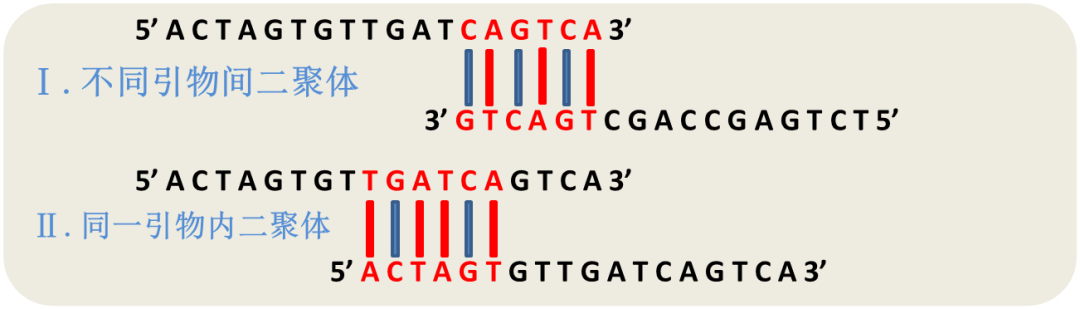
# 摘要
本文旨在介绍DNAman软件在PCR技术中的应用,并探讨优化PCR反应条件的理论基础与实验技巧。通过分析PCR的原理、关键要素、特异性影响因素,以及温度梯度、引物设计和模板质量的重要性,我们提出了一套理论策略来优化PCR条件。接着,本文展示了如何使用DNAman软件通过模拟实验进行PCR条件的优化,并讨论了如何分析PCR结果以微调参数。高级技巧部分详细介绍了减少非特异性扩增的方法,包括特殊
固体氧化物燃料电池性能测试标准与方法指南

# 摘要
本文综述了固体氧化物燃料电池的基本理论和技术,重点介绍了性能测试的基本理论与技术,并详述了实验室规模测试和现场应用性能评估的方法。通过对固体氧化物燃料电池的工作原理和材料特性的探讨,以及对国际标准的分析,本文揭示了关键性能参数如输出功率、能量效率和寿命的测试方法,并考虑了环境与负载对性能的影响。现场应用性能评估部分涵盖了准备工作、性能与环境适应性测试以及长期运行稳定性分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )