YOLOv8配置文件深度解析:训练参数优化指南
发布时间: 2024-12-11 22:39:19 阅读量: 15 订阅数: 13 

实现SAR回波的BAQ压缩功能

# 1. YOLOv8配置文件概述
YOLOv8作为目前最新一代的实时目标检测算法,它的性能和灵活性在计算机视觉领域得到了广泛认可。本章将对YOLOv8的配置文件进行一个全面的介绍,包括其结构、配置参数的类型及用途,以及配置文件的基本读写操作。我们将深入浅出地探讨配置文件在YOLOv8中的重要性,以及如何根据不同的应用场景对配置文件进行定制化修改。
YOLOv8的配置文件不仅仅是一个参数存储的位置,它更是训练过程与模型结构的蓝图。在开始深入解析网络结构参数前,理解配置文件的基础结构是至关重要的。用户可以通过配置文件设置模型的层数、类别数、锚点大小等,这是实现自定义训练过程的第一步。此外,学习如何编写和修改配置文件将帮助用户更好地理解YOLOv8的工作机制,以及如何调试和优化模型的性能。
接下来的章节,我们将详细分析YOLOv8网络结构的核心参数,并探讨如何通过配置文件对训练过程进行细粒度的控制。通过对每个参数的详细解读,我们可以更有效地应对目标检测任务中的挑战,从而达到更高的准确率和速度平衡。
# 2. YOLOv8网络结构参数详解
## 2.1 基础模型参数
### 2.1.1 神经网络层的配置
YOLOv8中的神经网络层配置是构建模型的基础,它涉及到每一层的类型、大小、激活函数的选择等多个方面。在配置文件中,我们可以看到这样的结构:
```yaml
[net]
batch=64
subdivisions=4
width=608
height=608
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
```
这里的`batch`和`subdivisions`控制批处理的大小和分割次数,进而影响到模型训练时的内存使用和GPU加速。`width`、`height`和`channels`定义了输入数据的尺寸和通道数。超参数如`momentum`和`decay`用于配置优化器,对于收敛速度和模型的泛化能力有直接影响。
### 2.1.2 激活函数的选择
激活函数是神经网络中的核心,它为网络提供了非线性因素,使得网络能够解决更复杂的问题。YOLOv8使用了Leaky ReLU作为默认激活函数,它在正数部分与ReLU相同,但在负数部分有一个小的斜率,防止梯度消失问题。配置文件中通常会有类似如下配置:
```yaml
activation=leaky
leaky_alpha=0.1
```
`leaky_alpha`是Leaky ReLU的超参数,决定了负数部分的斜率。这种激活函数选择对于网络的学习能力至关重要。
## 2.2 训练超参数
### 2.2.1 学习率策略
学习率是影响训练速度和模型性能的关键超参数。在YOLOv8的配置文件中,学习率的设置如下:
```yaml
learning_rate=0.001
burn_in=1000
max_batches=500500
policy=steps
```
这里`burn_in`和`max_batches`定义了学习率的预热和衰减策略,而`policy`定义了学习率随批次变化的具体策略。通过合理安排这些参数,可以显著提升模型在训练过程中的表现。
### 2.2.2 优化器选择与设置
优化器用于更新网络中的权重,常见的优化器有SGD、Adam、RMSprop等。YOLOv8默认使用SGD优化器,其配置可能如下:
```yaml
optimizer=sgd
```
SGD的参数如`momentum`和`weight_decay`则通常在上面提到的`[net]`部分进行设置。调整这些参数可以帮助我们在保持模型准确性的同时,提升训练速度。
### 2.2.3 损失函数的调整
损失函数衡量了模型输出与实际标签之间的差异。在目标检测模型中,损失函数常常由定位误差、置信度误差和类别误差三部分组成。在YOLOv8的配置文件中,损失函数的定义可能如下:
```yaml
loss=mean_squared_error
```
在YOLOv8中,损失函数的调整主要依赖于实验和调优,以适应不同的训练需求和数据集特性。
## 2.3 数据增强技术
### 2.3.1 图像预处理方法
数据增强技术是指通过一系列变换来增加训练集的多样性,提高模型的泛化能力。YOLOv8的数据增强包括以下步骤:
```yaml
preprocess_data augmentation
```
### 2.3.2 数据增强技巧和其对性能的影响
数据增强的具体技巧包括旋转、缩放、剪切、颜色变换等,这些在配置文件中体现如下:
```yaml
augment=flip
flip=0.5
```
这些数据增强技巧可以提升模型的鲁棒性,防止过拟合。通过合理地使用和调整数据增强技术,可以显著提升模型在实际应用中的性能。
```mermaid
flowchart LR
A[数据增强开始]
B[图像预处理]
C[随机变换]
D[应用变换到数据集]
E[结束]
A --> B --> C --> D --> E
```
以上展示了数据增强的一个基本流程,具体配置会根据实际应用需求调整。通过调整如剪切比例、旋转角度等参数,可以实现不同的增强效果,进而对模型性能产生积极影响。
通过本章节的介绍,我们深入探讨了YOLOv8网络结构中的参数设置,包括基础模型参数、训练超参数、数据增强技术等多个方面,为接下来的参数优化实践奠定了理论基础。
# 3. YOLOv8训练参数优化实践
### 3.1 参数调优基础
#### 3.1.1 模型准确率与速度权衡
在深度学习模型训练中,准确率和速度通常是需要权衡的两个方面。对于实时目标检测系统而言,模型的速度尤为重要,因为检测必须在极短的时间内完成。YOLOv8虽

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《YOLOv8的调试与测试方法》专栏深入探讨了YOLOv8模型的调试和测试技术。从性能提升技巧到视觉原理揭秘,再到全面评估流程、数据预处理手册和模型压缩术,专栏提供了全面的指导,帮助读者优化模型性能和解决问题。此外,专栏还涵盖了实时检测解决方案、错误分析手册、配置文件解析、与传统算法的对比以及集成测试攻略,为读者提供了全方位的知识和实践指南,以确保YOLOv8模型在各种场景下的卓越表现。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ROST软件数据可视化技巧:让你的分析结果更加直观动人
:max_bytes(150000):strip_icc()/ScreenShot2019-10-28at1.25.36PM-ab811841a30d4ee5abb2ff63fd001a3b.jpg)
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
RTCM 3.3协议深度剖析:如何构建秒级精准定位系统

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议简介及其在精准定位中的作用
RTCM (Radio Technical Co
提升航空数据传输效率:AFDX网络数据流管理技巧
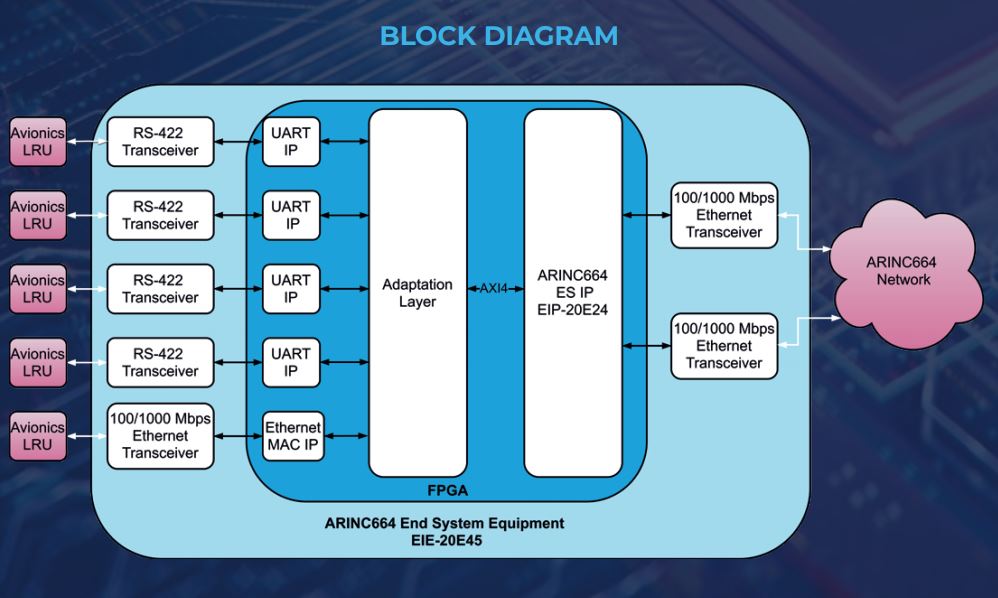
参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. AFDX网络技术概述
## 1.1 AFDX网络技术的起源与应用背景
AFDX (Avionics Full-Duplex Switched Ethernet) 网络技术,是专为航空电子通信设计
软件开发者必读:与MIPI CSI-2对话的驱动开发策略
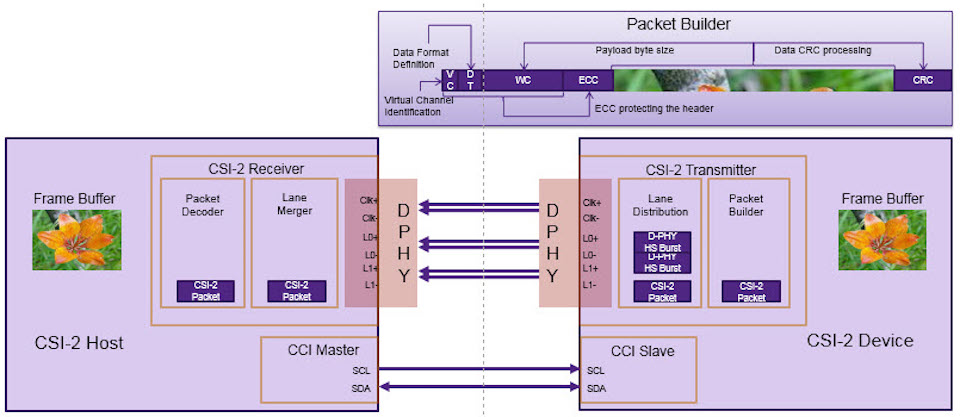
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2协议概述
在当今数字化和移动化的世界里,移动设备图像性能的提升是用户体验的关键部分。为
【PCIe接口新革命】:5.40a版本数据手册揭秘,加速硬件兼容性分析与系统集成
参考资源链接:[2019 Synopsys PCIe Endpoint Databook v5.40a:设计指南与版权须知](https://wenku.csdn.net/doc/3rfmuard3w?spm=1055.2635.3001.10343)
# 1. PCIe接口技术概述
PCIe( Peripheral Component Interconnect Express)是一种高速串行计算机扩展总线标准,被广泛应用于计算机内部连接高速组件。它以点对点连接的方式,能够提供比传统PCI(Peripheral Component Interconnect)总线更高的数据传输率。PCIe的进
ZMODEM协议的高级特性:流控制与错误校正机制的精妙之处

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM协议简介
## 1.1 什么是ZMODEM协议
ZMODEM是一种在串行通信中广泛使用的文件传输协议,它支持二进制数据传输,并可以对数据进行分块处理,确保文件完整无误地传输到目标系统。与早期的XMODEM和YMODEM协
IS903优盘通信协议揭秘:USB通信流程的全面解读

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. USB通信协议概述
USB(通用串行总线)通信协议自从1996年首次推出以来,已经成为个人计算机和其他电子设备中最普遍的接口技术之一。该章节将概述USB通信协议的基础知识,为后续章节深入探讨USB的硬件结构、信号传输和通信流程等主题打
【功能拓展】创维E900 4K机顶盒应用管理:轻松安装与管理指南
参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
在本章中,我们将揭开创维E900 4K机顶盒的神秘面纱,带领读者了解这一强大的多媒体设备的基本信息。我们将从其设计理念讲起,探索它如何为家庭娱乐带来高清画质和智能功能。本章节将为读者提供一个全面的概览,包括硬件配置、操作系统以及它在市场中的定位,为后续章节中关于设置、应用使用和维护等更深入的讨论打下坚实的基础。
创维E900 4K机顶盒采用先
【cx_Oracle数据库管理】:全面覆盖连接、事务、性能与安全性

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle数据库基础介绍
cx_Oracle 是一个
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )