C++中std::atomic与编译器优化:如何防止意外的编译器优化
发布时间: 2024-10-20 15:17:01 阅读量: 2 订阅数: 3 

# 1. C++内存模型与原子操作基础
在多线程编程的世界中,内存模型和原子操作是构建可靠并发程序的基础。本章将介绍C++中内存模型的核心概念和原子操作的必要性,同时为后续章节对std::atomic类深入解析和编译器优化的相关讨论奠定基础。
## 1.1 C++中的内存模型概念
C++内存模型定义了多线程程序中变量如何被访问和修改,以及这些访问和修改操作在不同线程之间的可见性。在没有明确同步的情况下,多线程可能会导致竞态条件和数据竞争,造成程序行为不稳定。理解内存模型是保证并发程序正确性的关键。
## 1.2 原子操作的必要性
原子操作保证了操作的不可分割性,即在执行过程中不会被其他线程中断。它们是实现线程间同步和通信的重要工具。在C++中,原子操作能够确保即使在多线程环境下,相关操作的执行对其他线程而言也是不可见的。
## 1.3 内存顺序的指定
当涉及到原子操作时,内存顺序(memory order)是一个必须考虑的因素。通过指定内存顺序,程序员可以精确控制操作的执行顺序和线程间可见性,从而保证程序的正确执行。在C++中,这通常涉及到诸如顺序一致性、获取(acquire)和释放(release)等内存顺序选项。
```cpp
// 示例代码:原子操作示例
#include <atomic>
std::atomic<int> atomic_var(0);
void thread_function() {
atomic_var.fetch_add(1, std::memory_order_relaxed); // 原子增加操作,指定内存顺序为relaxed
}
int main() {
std::thread t1(thread_function);
std::thread t2(thread_function);
t1.join();
t2.join();
// 确保所有操作完成后的变量值
assert(atomic_var == 2);
}
```
在上述代码示例中,我们使用了`std::atomic`类模板来创建一个原子变量,并通过`fetch_add`方法执行原子增加操作。这里我们指定了`std::memory_order_relaxed`内存顺序,表示我们不关心操作的具体执行顺序,只关心最终的结果。然而,在更复杂的情况下,内存顺序的选择需要更加谨慎,以避免潜在的数据竞争问题。
# 2. std::atomic类的深入解析
### 2.1 std::atomic类模板的特性与功能
#### 2.1.1 原子操作的类型和适用性
在C++中,`std::atomic`类提供了一系列原子操作,它们用于实现无锁的线程安全编程模式。原子操作保证了在多线程环境中,对单个操作的执行是不可分割的,这在并发环境下至关重要。
类型上,`std::atomic`可以是整型、指针类型,甚至一些自定义类型,只要这些类型满足了原子操作的要求,例如`std::atomic<int>`、`std::atomic<bool>`等。其适用性表现在对内存位置的单个读或写操作,以及一些基本操作如加一、减一等。
下面是一个简单的使用`std::atomic<int>`的示例代码,展示如何安全地进行原子增操作:
```cpp
#include <atomic>
#include <iostream>
std::atomic<int> atomicCounter(0);
void incrementCounter() {
atomicCounter.fetch_add(1, std::memory_order_relaxed);
}
int main() {
std::cout << "Initial counter: " << atomicCounter << std::endl;
incrementCounter();
std::cout << "Counter after increment: " << atomicCounter << std::endl;
return 0;
}
```
这段代码中`fetch_add`方法执行了原子的加一操作,`std::memory_order_relaxed`指定了操作的内存顺序,表明了对于内存的操作不需要严格的顺序约束。
#### 2.1.2 原子操作的内存顺序选项
在C++中,内存顺序选项定义了原子操作对内存的可见性和顺序性的影响。`std::atomic`类提供了一系列枚举值来指定内存顺序,包括:
- `std::memory_order_relaxed`:松散顺序,不要求执行顺序,但保证了操作的原子性。
- `std::memory_order_consume`、`std::memory_order_acquire`:要求后续的读写操作不能被重排序到当前原子操作之前。
- `std::memory_order_release`、`std::memory_order_acq_rel`、`std::memory_order_seq_cst`:要求之前的读写操作不能被重排序到当前原子操作之后。
选择合适的内存顺序选项对于保证多线程程序的正确性和性能至关重要。不正确的内存顺序可能导致未定义行为和数据竞争。
### 2.2 原子操作与C++标准库
#### 2.2.1 原子操作与线程库的交互
C++11标准库中引入了线程库`<thread>`,它与`std::atomic`类紧密集成,以提供线程安全的并发操作。例如,线程之间的同步可以通过原子标志来实现,如下所示:
```cpp
#include <thread>
#include <atomic>
#include <iostream>
std::atomic<bool> ready(false);
int sharedResource = 0;
void producer() {
sharedResource = 42; // 生产一个值
ready.store(true, std::memory_order_release); // 标记资源已就绪
}
void consumer() {
while (!ready.load(std::memory_order_acquire)); // 等待资源就绪
std::cout << "Resource value: " << sharedResource << std::endl; // 使用资源
}
int main() {
std::thread producerThread(producer);
std::thread consumerThread(consumer);
producerThread.join();
consumerThread.join();
return 0;
}
```
在这个例子中,`ready`是一个`std::atomic<bool>`,用来表示资源`sharedResource`是否已经准备好。`store`和`load`方法分别使用`std::memory_order_release`和`std::memory_order_acquire`来保证生产和消费操作的正确顺序。
#### 2.2.2 原子类型在同步与通信中的应用
原子类型不仅用于简单的同步,还可以在多线程间进行更复杂的通信。原子类型可以实现信号量、互斥锁、条件变量等同步机制的基本功能。
例如,可以使用`std::atomic_flag`来构建一个简单的信号量,控制对共享资源的访问:
```cpp
#include <atomic>
#include <thread>
#include <iostream>
std::atomic_flag lock = ATOMIC_FLAG_INIT;
void func(int n) {
while (lock.test_and_set(std::memory_order_acquire)) {
// Do nothing. Wait for the lock to be released.
}
// Critical section.
std::cout << "Critical section - " << n << std::endl;
lock.clear(std::memory_order_release); // 释放锁,允许其他线程进入
}
int main() {
std::thread t1(func, 1);
std::thread t2(func, 2);
t1.join();
t2.join();
return 0;
}
```
在这个例子中,`lock.clear`和`lock.test_and_set`是两个原子操作,它们配合使用实现了一个简单的自旋锁。
### 2.3 高级原子操作
#### 2.3.1 比较和交换操作
比较和交换(Compare-And-Swap, CAS)是一个重要的原子操作,它将原子变量与预期值进行比较,如果相等则更新为新值。这个操作在无锁编程中非常有用。
以下是一个使用`std::atomic`的CAS操作的示例:
```cpp
#include <atomic>
#include <iostream>
std::atomic<int> atomicValue(0);
void casExample(int expectedValue, int newValue) {
while (!***pare_exchange_weak(expectedValue, newValue)) {
// 如果CAS失败,则expectedValue会更新为atomicValue的当前值
}
}
int main() {
casExample(0, 1);
std::cout << "Updated value: " << atomicValue << std::endl;
return 0;
}
```
`compare_exchange_weak`方法会执行CAS操作,如果`atomicValue`的当前值与`expectedValue`相等,就将其更新为`newValue`。如果CAS操作失败,`expectedValue`会被更新为`atomicValue`当前的值,这允许重试操作。
#### 2.3.2 原子标志和信号量
原子标志通常用于表示某个状态或条件,例如一个线程是否完成工作。而原子信号量则可以用于限制对共享资源的访问,如下例所

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
内存泄漏无处藏身:C++动态数组的RAII和智能指针应用

# 1. C++动态数组的管理难题
动态数组是C++中常用的数据结构,尤其在需要处理不确定数量元素的情况下。然而,管理动态数组并非易事,特别是在内存管理和生命周期控制方面,开发者经常会遇到内存泄漏和资源竞争等问题。本章我们将分析这些管理难题,并且探讨解决方案。
## 1.1 动态数组管理的挑战
在C++中,动态数组通常通过指针和new/delete操作符来创建和销毁。虽然这一过程简单明了,但它将内存管理
【C++内存泄漏案例分析】:真实世界内存问题的深入剖析
# 1. C++内存管理基础
C++是一种高性能的编程语言,它为开发者提供了几乎与硬件直接交互的能力。然而,这种强大功能也带来了内存管理的责任。在深入探讨如何有效地管理内存以避免泄漏之前,我们需要了解内存管理的基础。
## 内存分配与释放
在C++中,内存分配通常通过`new`关键字进行,而释放则通过`delete`关键字
C# MVC中的异步编程:提升Web应用响应速度的秘诀
# 1. 异步编程在Web应用中的重要性
在现代的Web应用开发中,异步编程已经成为提高性能和用户体验的关键。当用户访问Web应用时,他们期望获得快速且一致的响应。同步编程模式在面对高并发的请求时可能会导致服务器资源的浪费,因为它们通常占用线程直到任务完成,这限制了应用处理其他请求的能力。
与同步编程相比,异步编程允许应用在等待一个长期操作完成(如数据库查询或文件I/O操作)时不阻塞执行流。这使线程可以被释放并用于其他任务,从而提高服务器的总体吞吐量。
此外,异步编程可显著减少服务器响应时间,这是因为它通过非阻塞方式管理I/O密集型操作,使得应用能够更快地完成任务。而且,现代Web框架如
高级路由秘籍:C# Web API自定义路由与参数处理技巧
# 1. C# Web API自定义路由概述
在构建基于C#的Web API应用程序时,自定义路由是实现灵活且可扩展的URL结构的关键。路由不仅涉及到如何将HTTP请求映射到对应的控制器和操作方法,还涉及到如何传递参数、如何设计可维护的URL模式等多个方面。在本章中,我们将深入探讨C# Web API自定义路由的基本概念和重要性,为后续章节中深入的技术细节和最佳实践打下坚实的基础。
## 1.1 路由的定义与作用
在Web API开发中,路由是决定客户端请求如何被处理的一组规则。它负责将客户端的请求URL映射到服务器端的控制器动作(Action)。自定义路由允许开发者根据应用程序的需求,
Go语言并发控制案例研究:sync包在微服务架构中的应用
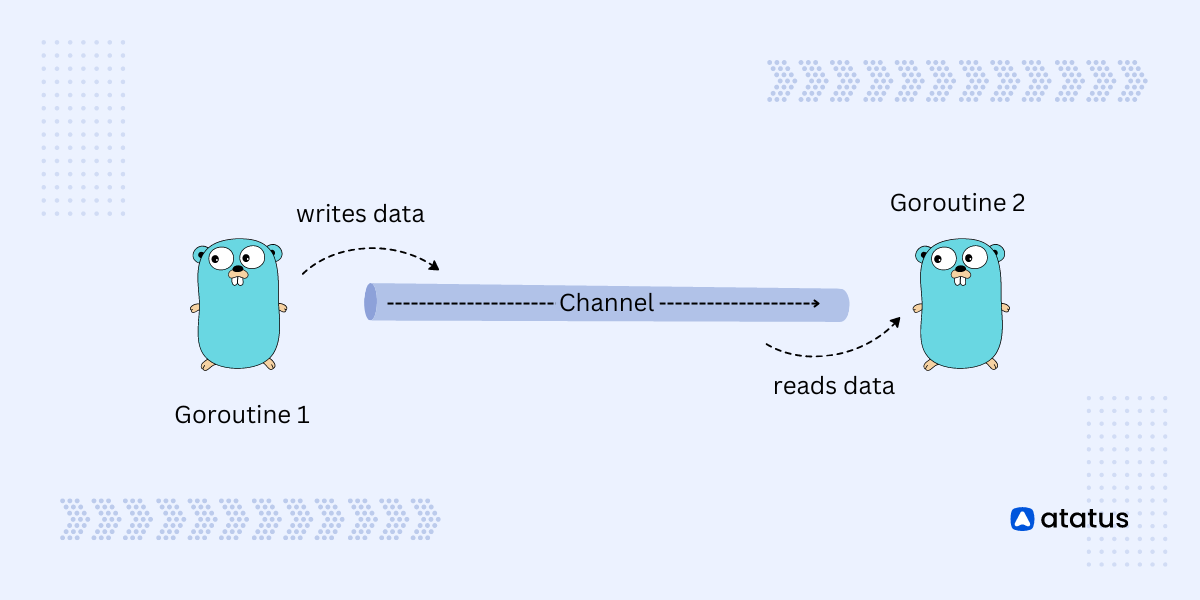
# 1. Go语言并发控制概述
Go语言自诞生起就被设计为支持并发的编程语言,其并发控制机制是构建高效、可靠应用的关键。本章将带领读者初步了解Go语言并发控制的基础知识,包括并发与并行的区别,以及Go语言中的并发模型——goroutines和channels。
## 1.1 Go语言并发模型简介
在Go语言中,goroutines提供了轻量级线程的概念,允许开发者以极小的
【Maven项目模块化管理】:模块化设计与多模块构建
# 1. Maven项目模块化设计概述
## 1.1 项目模块化的重要性
项目模块化设计是现代软件工程中的核心概念之一,它将复杂的项目拆分成可独立开发、测试和部署的模块。通过模块化,不仅可以提升代码的可维护性和重用性,还能有效隔离各个模块之间的依赖,简化项目的管理。
## 1.2 Maven在模块化中的作用
Maven是一个广泛使用的项目管理和自动化构建工具,它通过项目对象
【Go文件I_O并发控制】:os包管理并发读写的最佳实践
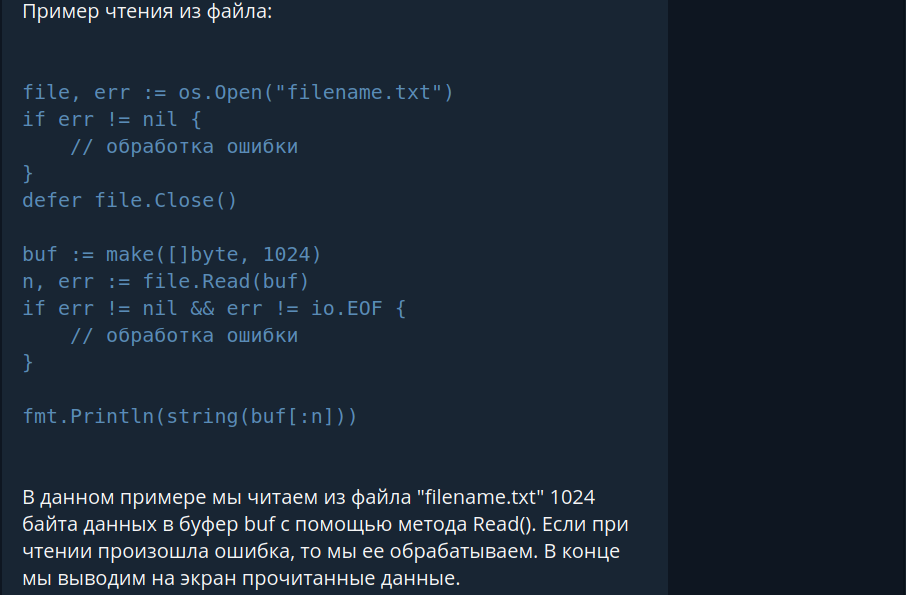
# 1. Go语言I/O并发控制基础
## Go语言的并发模型
Go语言的并发模型以goroutine为核心,goroutine类似于轻量级的线程,由Go运行时进行调度。goroutine的使用非常简单,只需要在函数调用前加上关键字`go`,即可并发执行该函数。
## I/O操作的并发控制
在进行I/
【SignalR实时通信秘籍】:C#开发者的终极指南(2023年版)

# 1. SignalR实时通信概述
SignalR 是一个在 *** 开发中广泛使用的库,它极大地简化了服务器和客户端之间的实时通信。它为开发者提供了一种简便的方法来实现双向通信,无需深入了解底层协议的复杂性。
在本章中,我们将概述 SignalR 的核心功能,包括其如何实现服务器与客户
SLF4J日志过滤与格式化:打造清晰且有用的日志信息

# 1. SLF4J日志框架概述
SLF4J(Simple Logging Facade for Java)是Java社区中广泛使用的一种日志门面框架。它不是一个完整的日志实现,而是一个提供日志API的接口,真正的日志实现则依赖于绑定的后端日志系统,如Logback
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )