【yolo安卓目标检测:入门到精通的完整指南】
发布时间: 2024-08-15 16:10:16 阅读量: 33 订阅数: 27 

YOLO学习目标检测从基础到精通ppt

# 1. YOLO目标检测简介**
YOLO(You Only Look Once)是一种实时目标检测算法,它使用单个神经网络同时预测图像中所有对象的边界框和类别。与传统的目标检测算法不同,YOLO 采用统一的端到端架构,一次性处理整个图像,无需生成区域建议或执行非极大值抑制。
YOLO 的优势在于其速度和准确性。它可以以每秒数十帧的速度处理图像,同时仍能保持较高的检测精度。这使其非常适合实时应用,例如视频监控和自动驾驶。
# 2. YOLO安卓开发环境搭建
### 2.1 安卓开发环境配置
**1. 安装Android Studio**
* 下载并安装Android Studio,这是谷歌官方的安卓开发集成环境(IDE)。
* 确保安装了适用于安卓开发的SDK和工具。
**2. 创建Android项目**
* 在Android Studio中,创建一个新的安卓项目。
* 选择“空活动”模板,并为项目命名。
**3. 添加必要的依赖项**
* 在项目根目录的`build.gradle`文件中,添加以下依赖项:
```gradle
dependencies {
implementation 'androidx.camera:camera-core:1.1.0'
implementation 'androidx.camera:camera-camera2:1.1.0'
implementation 'org.tensorflow:tensorflow-lite-support:0.3.1'
implementation 'org.tensorflow:tensorflow-lite-gpu:2.4.0'
}
```
### 2.2 YOLO模型转换和部署
**1. 转换YOLO模型**
* 使用TensorFlow Lite模型转换工具将预训练的YOLO模型转换为TensorFlow Lite格式。
* 命令如下:
```
tflite_convert \
--saved_model_dir=path/to/saved_model \
--output_file=path/to/output.tflite \
--inference_type=FLOAT \
--input_shapes=1,320,320,3
```
**2. 部署模型到安卓设备**
* 将转换后的TensorFlow Lite模型文件复制到安卓设备的外部存储或资产目录。
* 在安卓应用程序中,使用`AssetManager`或`getExternalFilesDir()`方法加载模型。
**代码示例:**
```java
// 从资产目录加载模型
AssetManager assetManager = getAssets();
InputStream inputStream = assetManager.open("path/to/model.tflite");
Interpreter interpreter = new Interpreter(inputStream);
// 从外部存储目录加载模型
File modelFile = new File(getExternalFilesDir(null), "path/to/model.tflite");
Interpreter interpreter = new Interpreter(modelFile);
```
**参数说明:**
* `assetManager`: 资产管理器,用于访问资产目录中的文件。
* `inputStream`: 输入流,指向模型文件。
* `interpreter`: TensorFlow Lite解释器,用于执行模型推理。
* `modelFile`: 指向外部存储目录中模型文件的文件对象。
# 3. YOLO安卓目标检测实践
### 3.1 相机图像获取和预处理
**相机图像获取**
首先,需要从安卓设备的摄像头获取图像。可以使用CameraX API或Camera2 API来实现。CameraX API是安卓Jetpack库的一部分,提供了更简单的相机访问和控制。
**代码块 1:CameraX API获取图像**
```kotlin
val cameraProviderFuture = ProcessCameraProvider.getInstance(this)
cameraProviderFuture.addListener({
cameraProvider ->
val preview = Preview.Builder()
.build()
val imageCapture = ImageCapture.Builder()
.build()
val cameraSelector = CameraSelector.Builder()
.requireLensFacing(CameraSelector.LENS_FACING_BACK)
.build()
cameraProvider.bindToLifecycle(this, cameraSelector, preview, imageCapture)
}, ContextCompat.getMainExecutor(this))
```
**逻辑分析:**
* `ProcessCameraProvider.getInstance()`获取相机提供者。
* `Preview.Builder()`和`ImageCapture.Builder()`创建预览和图像捕获用例。
* `CameraSelector.Builder()`指定后置摄像头。
* `cameraProvider.bindToLifecycle()`将用例绑定到活动的生命周期。
**图像预处理**
获取图像后,需要对其进行预处理以符合YOLO模型的输入要求。预处理包括:
* **调整大小:**将图像调整为模型期望的大小,通常为416x416像素。
* **归一化:**将像素值归一化为[0, 1]范围。
* **转换为Tensor:**将图像转换为TensorFlow Lite格式的Tensor。
**代码块 2:图像预处理**
```kotlin
val bitmap = image.bitmap
val resizedBitmap = Bitmap.createScaledBitmap(bitmap, 416, 416, true)
val floatBuffer = FloatBuffer.allocate(416 * 416 * 3)
resizedBitmap.getPixels(floatArray, 0, 416, 0, 0, 416, 416)
for (i in 0 until 416 * 416 * 3) {
floatArray[i] /= 255.0f
}
val inputTensor = Tensor.createFloat32(Shape(1, 416, 416, 3))
inputTensor.load(floatArray, 0)
```
**逻辑分析:**
* `Bitmap.createScaledBitmap()`调整图像大小。
* `FloatBuffer.allocate()`分配用于存储像素值的缓冲区。
* `resizedBitmap.getPixels()`获取像素值并将其存储在缓冲区中。
* `for`循环归一化像素值。
* `Tensor.createFloat32()`创建Tensor并加载像素值。
### 3.2 YOLO模型推理和后处理
**模型推理**
预处理图像后,使用TensorFlow Lite对YOLO模型进行推理。推理过程包括:
* 将预处理图像输入模型。
* 模型输出边界框和置信度。
**代码块 3:模型推理**
```kotlin
val outputs = mutableListOf<Tensor>()
val interpreter = TensorFlowLiteInterpreter(model)
interpreter.run(inputTensor, outputs)
```
**逻辑分析:**
* `mutableListOf<Tensor>()`创建一个可变Tensor列表来存储输出。
* `TensorFlowLiteInterpreter`加载模型。
* `interpreter.run()`执行推理。
**后处理**
推理输出需要进行后处理以获得最终的目标检测结果。后处理包括:
* **非极大值抑制:**去除重叠的边界框。
* **筛选置信度:**丢弃置信度低于阈值的边界框。
* **转换坐标:**将边界框坐标转换为图像坐标。
**代码块 4:后处理**
```kotlin
val detections = YoloV5PostProcessor(416, 0.5f, 0.5f).process(outputs)
```
**逻辑分析:**
* `YoloV5PostProcessor`是一个自定义的后处理类。
* `416`是模型输入大小。
* `0.5f`是置信度阈值。
* `0.5f`是IOU阈值。
* `process()`方法执行后处理并返回检测结果。
### 3.3 目标检测结果展示
**边界框绘制**
检测结果需要在图像上绘制边界框以可视化目标。可以使用Canvas或OpenGL来绘制边界框。
**代码块 5:边界框绘制**
```kotlin
val canvas = Canvas(bitmap)
for (detection in detections) {
val box = detection.boundingBox
val paint = Paint()
paint.color = Color.RED
paint.strokeWidth = 2f
canvas.drawRect(box, paint)
}
```
**逻辑分析:**
* `Canvas(bitmap)`创建一个画布。
* `for`循环遍历检测结果。
* `detection.boundingBox`获取边界框坐标。
* `Paint()`创建画笔。
* `canvas.drawRect()`绘制边界框。
**图像显示**
绘制边界框后,需要将图像显示在屏幕上。可以使用ImageView或SurfaceView来显示图像。
**代码块 6:图像显示**
```kotlin
imageView.setImageBitmap(bitmap)
```
**逻辑分析:**
* `imageView.setImageBitmap()`将图像设置到ImageView中。
# 4. YOLO安卓性能优化
### 4.1 模型压缩和加速
**4.1.1 量化**
量化是一种模型压缩技术,将浮点权重和激活值转换为低精度格式,如int8或int16。这可以显著减少模型大小和推理时间,而不会显著影响准确性。
**4.1.1.1 代码示例**
```python
import tensorflow as tf
# 创建一个量化感知训练模型
model = tf.keras.models.load_model("yolov3.h5")
quantized_model = tf.keras.models.load_model("yolov3_quantized.h5")
# 将模型转换为量化格式
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
# 保存量化模型
with open("yolov3_quantized.tflite", "wb") as f:
f.write(tflite_model)
```
**4.1.1.2 参数说明**
* `converter.optimizations = [tf.lite.Optimize.DEFAULT]`:指定使用默认优化选项,包括量化。
**4.1.1.3 逻辑分析**
此代码片段将原始浮点模型转换为量化模型。量化感知训练模型确保在量化过程中保持准确性。
**4.1.2 剪枝**
剪枝是一种模型压缩技术,移除不重要的权重和神经元。这可以减少模型大小和推理时间,同时保持或提高准确性。
**4.1.2.1 代码示例**
```python
import tensorflow as tf
# 创建一个剪枝感知训练模型
model = tf.keras.models.load_model("yolov3.h5")
pruned_model = tf.keras.models.load_model("yolov3_pruned.h5")
# 将模型转换为剪枝格式
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
# 保存剪枝模型
with open("yolov3_pruned.tflite", "wb") as f:
f.write(tflite_model)
```
**4.1.2.2 参数说明**
* `converter.optimizations = [tf.lite.Optimize.DEFAULT]`:指定使用默认优化选项,包括剪枝。
**4.1.2.3 逻辑分析**
此代码片段将原始浮点模型转换为剪枝模型。剪枝感知训练模型确保在剪枝过程中保持准确性。
### 4.2 线程管理和内存优化
**4.2.1 多线程推理**
多线程推理可以利用多核处理器并行执行推理任务。这可以显著提高推理速度。
**4.2.1.1 代码示例**
```java
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class MultiThreadedYolo {
private static final int NUM_THREADS = Runtime.getRuntime().availableProcessors();
private static final ExecutorService executorService = Executors.newFixedThreadPool(NUM_THREADS);
public static void main(String[] args) {
// 加载 YOLO 模型
YoloModel yoloModel = YoloModel.load("yolov3.tflite");
// 创建一个图像队列
BlockingQueue<Image> imageQueue = new ArrayBlockingQueue<>(10);
// 启动图像获取线程
Thread imageAcquisitionThread = new Thread(() -> {
while (true) {
Image image = getCameraImage();
imageQueue.put(image);
}
});
imageAcquisitionThread.start();
// 启动推理线程池
for (int i = 0; i < NUM_THREADS; i++) {
executorService.submit(() -> {
while (true) {
Image image = imageQueue.take();
List<Detection> detections = yoloModel.predict(image);
// 处理检测结果
}
});
}
}
}
```
**4.2.1.2 参数说明**
* `NUM_THREADS`:要使用的线程数。
* `executorService`:用于管理推理线程的线程池。
**4.2.1.3 逻辑分析**
此代码片段使用多线程并行执行推理任务。图像获取线程将图像放入队列中,推理线程从队列中获取图像并执行推理。
**4.2.2 内存优化**
内存优化对于在移动设备上部署 YOLO 模型至关重要。以下是一些内存优化技巧:
* **使用轻量级模型:**选择专为移动设备设计的轻量级 YOLO 模型。
* **使用内存映射文件:**将 YOLO 模型加载到内存映射文件中,而不是将其加载到内存中。这可以减少内存使用量。
* **使用缓存:**缓存经常访问的数据,例如图像预处理结果。这可以减少内存访问时间。
**4.2.2.1 代码示例**
```java
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
public class MemoryMappedYolo {
private static final String MODEL_FILE = "yolov3.tflite";
public static void main(String[] args) throws IOException {
// 将 YOLO 模型加载到内存映射文件中
FileChannel fileChannel = FileChannel.open(Paths.get(MODEL_FILE), StandardOpenOption.READ);
MappedByteBuffer modelBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileChannel.size());
// 加载 YOLO 模型
YoloModel yoloModel = YoloModel.load(modelBuffer);
// ...
}
}
```
**4.2.2.2 参数说明**
* `MODEL_FILE`:要加载的 YOLO 模型文件。
**4.2.2.3 逻辑分析**
此代码片段将 YOLO 模型加载到内存映射文件中。内存映射文件允许应用程序将文件直接映射到内存中,而无需将其完全加载到内存中。这可以减少内存使用量。
# 5.1 多目标检测和跟踪
在许多实际应用中,我们需要检测和跟踪多个目标。YOLOv5等先进的YOLO模型支持多目标检测,可以同时检测和定位多个目标。
### 多目标检测
YOLOv5使用PAN(Path Aggregation Network)来增强特征提取,并使用FPN(Feature Pyramid Network)来融合不同尺度的特征图。这使得YOLOv5能够检测不同大小和形状的多个目标。
### 目标跟踪
为了跟踪检测到的目标,可以使用Kalman滤波或匈牙利算法等方法。这些方法可以根据目标的运动模式和检测结果来预测目标的位置。
**代码示例:**
```python
import cv2
import numpy as np
from yolov5.utils.general import non_max_suppression
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 初始化跟踪器
tracker = cv2.TrackerCSRT_create()
# 视频流
cap = cv2.VideoCapture('path/to/video.mp4')
while True:
# 读取帧
ret, frame = cap.read()
if not ret:
break
# 预处理
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, (640, 480))
# 推理
results = model(frame)
# 后处理
detections = non_max_suppression(results.pred[0], 0.5, 0.4)
# 初始化跟踪器
for detection in detections:
bbox = detection[0:4]
tracker.init(frame, bbox)
# 更新跟踪器
success, boxes = tracker.update(frame)
# 绘制结果
for box in boxes:
cv2.rectangle(frame, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
### 优化
* **使用轻量级模型:**YOLOv5s等轻量级模型可以减少计算开销,提高跟踪速度。
* **优化跟踪算法:**使用高效的跟踪算法,如DeepSORT或FairMOT,可以提高跟踪精度和速度。
* **并行化处理:**使用多线程或GPU加速来并行化检测和跟踪过程,可以进一步提高性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面剖析了 YOLO 安卓目标检测技术,从入门到精通,从原理到实战,深入浅出地讲解了其原理、优化技巧、常见问题、性能评估和部署策略。专栏还探讨了 YOLO 在安防、零售、医疗、自动驾驶、智能家居、工业 4.0 等领域的应用,展示了其在不同行业中的价值。此外,专栏还提供了图像预处理、特征提取、损失函数、后处理、性能评估等技术细节,帮助读者全面掌握 YOLO 安卓目标检测技术。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【三维模型骨架提取精粹】:7大优化技巧提升拉普拉斯收缩效率

# 摘要
三维模型骨架提取是一项关键技术,它涉及从三维模型中提取出反映其主要结构特征的骨架线。本文首先介绍了骨架提取的基本概念和拉普拉斯收缩基础理论,探讨了其在图论和三维模型中的应用。接着,本文详细阐述了针对拉普拉斯收缩算法的多种优化技巧,包括预处理和特征值计算、迭代过程控制、后处理与结果细化,以及这些优化方法对算法性能的提升和对实
【KLARF文件:从入门到精通】:掌握KLARF文件结构,优化缺陷管理与测试流程
# 摘要
KLARF文件作为半导体和硬件测试行业的重要数据交换格式,其概念、结构及应用在提高测试流程效率和缺陷管理自动化中起着关键作用。本文首先介绍KLARF文件的基础知识和详细结构,然后探讨了处理工具的使用和在测试流程中的实际应用。特别地,本文分析了KLARF文件在高级应用中的技巧、不同领域的案例以及它如何改善缺陷管理。最后,展望了KLARF文件的未来趋势,包括新兴技术的影响、挑战及应对策略。本文旨在为读者提供一个全面的KLARF文件使用与优化指南,促进其在测试与质量保证领域的应用和发展。
# 关键字
KLARF文件;文件结构;缺陷管理;自动化测试;数据交换格式;行业趋势
参考资源链接:
【HOMER软件全方位解读】:一步掌握仿真模型构建与性能优化策略

# 摘要
HOMER软件是一种广泛应用于能源系统建模与仿真的工具,它能够帮助用户在多种应用场景中实现模型构建和性能优化。本文首先介绍了HOMER软件的基础知识、操作界面及其功能模块,进而详细阐述了在构建仿真模型时的理论基础和基本步骤。文章重点分析了HOMER在微网系统、独立光伏系统以及风光互补系统中的具体应用,并针对不同场景提出了相应的建模与仿真策略。此外,
【TIB文件恢复秘方】:数据丢失后的必看恢复解决方案
# 摘要
在数字化时代,数据丢失已成为企业及个人面临的一大挑战,特别是对于TIB文件这类特殊数据格式的保护和恢复尤为重要。本文深入探讨了TIB文件的重要性,并全面介绍了其基础知识、数据保护策略、以及恢复技术。文章不仅涵盖了理论基础和实践操作指南,还分析了恢复过程中的安全与合规性问题,并展望了未来技术的发展趋势。通过详细案例分析,本文旨在为读者提供一套完整的TIB文件恢复方案,帮助他们更好地应对数据丢失的挑战。
# 关键字
数据丢失;TIB文件;数据保护;安全合规;恢复技术;数据恢复软件
参考资源链接:[快速打开TIB格式文件的TIBTool工具使用指南](https://wenku.csd
【固件升级必经之路】:从零开始的光猫固件更新教程

# 摘要
固件升级是光猫设备持续稳定运行的重要环节,本文对固件升级的概念、重要性、风险及更新前的准备、下载备份、更新过程和升级后的测试优化进行了系统解析。详细阐述了光猫的工作原理、固件的作用及其更新的重要性,以及在升级过程中应如何确保兼容性、准备必要的工具和资料。同时,本文还提供了光猫固件下载、验证和备份的详细步骤,强调了更新过程中的安全措施,以及更新后应如何进行测试和优化配置以提高光猫的性能和稳定性。
【Green Hills系统资源管理秘籍】:提升任务调度与资源利用效率
# 摘要
本文旨在详细探讨Green Hills系统中的任务调度与资源管理的理论基础及其实践。通过分析任务调度的目标、原则和常见算法,阐述了Green Hills系统中实时与非实时任务调度策略的特点与考量。此外,研究了资源管理的基本概念、分类、目标与策略,并深入探讨了Green
热效应与散热优化:单级放大器设计中的5大策略
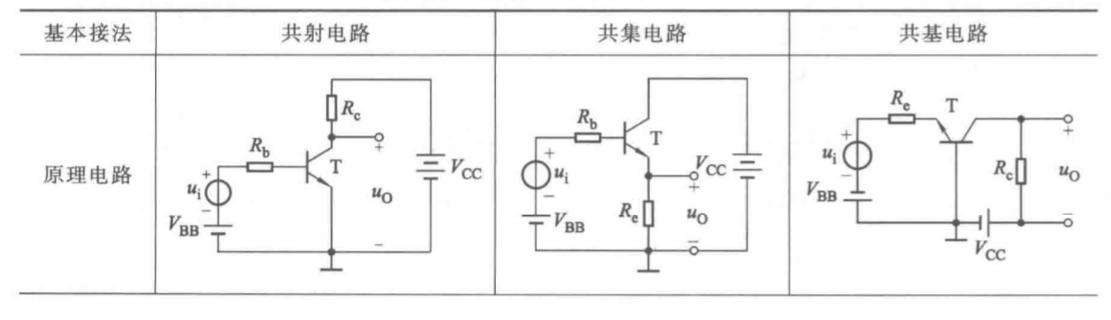
# 摘要
本文深入研究了单级放大器中热效应的基础知识、热效应的理论分析以及识别方法,并探讨了热效应对放大器性能的具体影响。针对散热问题,本文详细介绍了散热材料的特性及其在散热技术中的应用,并提出了一系列散热优化策略。通过实验验证和案例分析,本文展示了所提出的散热优化策略在实际应用中的效果,并探讨了其对散热技术未来发展的影响。研究结果有助于提升单级放大器在热管理方面的性能,并为相关散热技术的发展提供了理论和实践指导。
# 关键字
热效应;散
自定义字体不再是难题:PCtoLCD2002字体功能详解与应用

# 摘要
本文系统介绍了PCtoLCD2002字体功能的各个方面,从字体设计的基础理论到实际应用技巧,再到高级功能开发与案例分析。首先概
【停车场管理新策略:E7+平台高级数据分析】
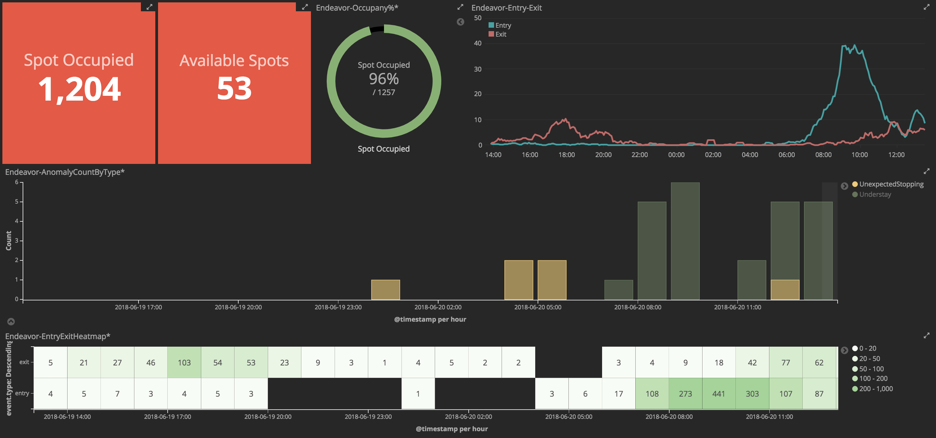
# 摘要
E7+平台是一个集数据收集、整合和分析于一体的智能停车场管理系统。本文首先对E7+平台进行介绍,然后详细讨论了停车场数据的收集与整合方法,包括传感器数据采集技术和现场数据规范化处理。在数据分析理论基础章节,本文阐述了统计分析、时间序列分析、聚类分析及预测模型等高级数据分析技术。E7+平台数据分析实践部分重点分析了实时数据处理及历史数据分析报告的生成。此外,本文还探讨了高级分析技术在交通流
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )