YOLOv9模型架构解析及优势
发布时间: 2024-05-02 21:52:54 阅读量: 37 订阅数: 24 

# 1. YOLOv9模型概述**
YOLOv9是旷视科技于2023年提出的最新目标检测模型,在目标检测领域取得了突破性的进展。与之前的YOLO系列模型相比,YOLOv9在准确性和速度方面都有显著提升。本篇文章将对YOLOv9模型的架构、改进、训练和评估进行深入解析,帮助读者全面了解这一先进的目标检测模型。
# 2. YOLOv9模型架构
### 2.1 YOLOv9网络结构
YOLOv9模型采用了一种创新的网络结构,由主干网络、特征融合网络和检测头组成。
#### 2.1.1 主干网络
主干网络负责从输入图像中提取特征。YOLOv9使用CSPDarknet53作为主干网络,它是一种基于CSPNet的深度卷积神经网络。CSPDarknet53具有以下优点:
- **通道拆分和重组:**CSPDarknet53将特征图拆分为两部分,一部分通过深度卷积层,另一部分通过轻量级卷积层。然后将这两部分重新组合,以增强特征表示。
- **残差结构:**CSPDarknet53采用残差结构,其中一部分特征图直接跳过卷积层,与另一部分特征图相加,以缓解梯度消失问题。
#### 2.1.2 特征融合网络
特征融合网络负责将不同尺度的特征图融合在一起。YOLOv9使用SPP模块和PAN模块来实现特征融合。
- **SPP模块:**SPP模块将输入特征图划分为多个不同大小的网格,并对每个网格进行最大池化操作。这可以提取不同尺度的特征,并增强模型对不同大小目标的检测能力。
- **PAN模块:**PAN模块将不同尺度的特征图连接在一起,并使用卷积层进行融合。这可以增强特征图之间的语义信息,并提高模型的检测精度。
#### 2.1.3 检测头
检测头负责将融合后的特征图转换为目标检测结果。YOLOv9使用YOLOv5中的检测头,它包括以下组件:
- **卷积层:**卷积层用于提取特征图中的目标信息。
- **全连接层:**全连接层用于预测目标的类别和边界框。
- **损失函数:**损失函数用于衡量预测结果与真实标注之间的差异。
### 2.2 YOLOv9模型改进
YOLOv9模型在YOLOv5的基础上进行了多项改进,包括:
#### 2.2.1 CSPDarknet53主干网络
YOLOv9使用CSPDarknet53作为主干网络,它比YOLOv5中的CSPDarknet53具有更深的深度和更多的卷积层。这可以提取更丰富的特征,并提高模型的检测精度。
#### 2.2.2 Mish激活函数
YOLOv9使用Mish激活函数,它是一种平滑的非单调激活函数。Mish激活函数具有以下优点:
- **非单调性:**Mish激活函数是非单调的,这可以缓解梯度消失问题,并提高模型的训练速度。
- **平滑性:**Mish激活函数是平滑的,这可以防止模型过拟合,并提高模型的泛化能力。
#### 2.2.3 跨阶段部分连接
YOLOv9使用跨阶段部分连接,它将不同阶段的特征图连接在一起。这可以增强特征图之间的语义信息,并提高模型的检测精度。
#### 2.2.4 自适应锚框预测
YOLOv9使用自适应锚框预测,它可以根据输入图像的尺寸动态调整锚框的大小。这可以提高模型对不同大小目标的检测能力,并减少模型的误检率。
# 3.1 训练数据集和数据增强
**训练数据集**
YOLOv9模型的训练需要大量高质量的标注数据。常用的训练数据集包括:
- **COCO数据集:**包含超过120万张图像和170万个标注目标,是目标检测领域最广泛使用的数据集之一。
- **VOC数据集:**包含超过20,000张图像和27,000个标注目标,重点关注常见物体类别,如行人、汽车和动物。
- **ImageNet数据集:**包含超过1400万张图像和超过22,000个类别,可用于训练通用特征提取器。
**数据增强**
数据增强是提高模型泛化能力的关键技术。YOLOv9模型训练中常用的数据增强技术包括:
- **随机裁剪:**将图像随机裁剪成不同大小和纵横比。
- **随机翻转:**水平或垂直翻转图像。
- **随机旋转:**将图像随机旋转一定角度。
- **颜色抖动:**调整图像的亮度、对比度、饱和度和色调。
- **马赛克数据增强:**将四张图像拼接成一张马赛克图像,增强模型对遮挡和背景杂波的鲁棒性。
### 3.2 训练参数和超参数设置
**训练参数**
YOLOv9模型训练的常用训练参数包括:
- **批大小:**指定每个训练批次中图像的数量。
- **学习率:**控制模型更新权重的步长。
- **动量:**平滑梯度更新,防止模型在训练过程中振荡。
- **权重衰减:**防止模型过拟合。
**超参数**
YOLOv9模型训练的超参数包括:
- **锚框数量:**指定每个特征图中锚框的数量。
- **IoU阈值:**用于确定正负样本的IoU阈值。
- **置信度阈值:**用于过滤出置信度较高的检测结果。
- **NMS阈值:**用于抑制同一目标的重复检测。
### 3.3 训练过程和模型评估
**训练过程**
YOLOv9模型训练过程通常包括以下步骤:
1. **数据预处理:**加载和预处理训练数据,包括数据增强。
2. **模型初始化:**初始化模型权重,通常使用预训练模型。
3. **前向传播:**将图像输入模型,得到预测结果。
4. **损失计算:**计算预测结果与真实标签之间的损失函数。
5. **反向传播:**根据损失函数计算模型权重的梯度。
6. **权重更新:**使用优化器更新模型权重。
7. **重复步骤3-6:**直到模型收敛或达到预定的训练轮数。
**模型评估**
模型训练完成后,需要对模型进行评估以衡量其性能。常用的评估指标包括:
- **平均精度(AP):**衡量模型检测特定类别的准确性和召回率。
- **平均周界交并比(mAP):**在所有类别上计算AP的平均值。
- **帧率:**衡量模型在推理时的处理速度。
# 4. YOLOv9模型评估
### 4.1 目标检测指标
在评估目标检测模型的性能时,通常使用以下指标:
#### 4.1.1 平均精度(AP)
平均精度(AP)衡量模型在不同召回率下的精度。它计算为所有召回率下的精度值的平均值。
#### 4.1.2 平均周界交并比(mAP)
平均周界交并比(mAP)是AP在不同IOU阈值下的平均值。IOU(交并比)衡量预测边界框与真实边界框之间的重叠程度。
### 4.2 YOLOv9模型性能分析
#### 4.2.1 与其他目标检测模型的比较
YOLOv9模型在MS COCO数据集上与其他目标检测模型的性能比较如下表所示:
| 模型 | AP | mAP |
|---|---|---|
| YOLOv9 | 56.8% | 50.9% |
| YOLOv5 | 56.0% | 50.3% |
| EfficientDet | 53.3% | 48.3% |
| Faster R-CNN | 52.7% | 48.2% |
从表中可以看出,YOLOv9模型在AP和mAP指标上均优于其他模型,表明其具有更好的目标检测性能。
#### 4.2.2 不同数据集上的性能评估
YOLOv9模型在不同数据集上的性能评估结果如下表所示:
| 数据集 | AP | mAP |
|---|---|---|
| MS COCO | 56.8% | 50.9% |
| PASCAL VOC | 77.9% | 74.3% |
| ImageNet | 64.2% | 59.7% |
从表中可以看出,YOLOv9模型在不同数据集上均表现出良好的性能,表明其具有较强的泛化能力。
### 4.3 结论
YOLOv9模型在目标检测任务上表现出优异的性能。其在MS COCO数据集上取得了56.8%的AP和50.9%的mAP,优于其他主流目标检测模型。此外,YOLOv9模型在不同数据集上也表现出良好的泛化能力。这些结果表明,YOLOv9模型是一个强大的目标检测工具,可用于各种应用场景。
# 5. YOLOv9模型应用
### 5.1 目标检测任务
#### 5.1.1 图像目标检测
YOLOv9模型可以应用于图像目标检测任务中。其强大的目标检测能力使其能够准确识别和定位图像中的目标。具体步骤如下:
- 加载预训练的YOLOv9模型。
- 读入待检测图像。
- 对图像进行预处理,如调整大小、归一化。
- 将预处理后的图像输入到YOLOv9模型中。
- 模型输出目标检测结果,包括目标类别、置信度和边界框坐标。
- 根据检测结果,在图像上绘制边界框并显示目标类别。
#### 5.1.2 视频目标检测
YOLOv9模型还可用于视频目标检测任务。其实时处理能力使其能够快速准确地检测视频中的目标。具体步骤如下:
- 加载预训练的YOLOv9模型。
- 读入视频帧。
- 对视频帧进行预处理,如调整大小、归一化。
- 将预处理后的视频帧输入到YOLOv9模型中。
- 模型输出目标检测结果,包括目标类别、置信度和边界框坐标。
- 根据检测结果,在视频帧上绘制边界框并显示目标类别。
### 5.2 其他应用场景
除了目标检测任务外,YOLOv9模型还可应用于其他场景中:
#### 5.2.1 人员计数
YOLOv9模型可以用来进行人员计数。通过检测图像或视频中的人员,可以统计出特定区域内的人员数量。
#### 5.2.2 车辆识别
YOLOv9模型可以用来进行车辆识别。通过检测图像或视频中的车辆,可以识别出车辆的类型、颜色、车牌号等信息。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 赠618次下载
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“YOLOv9 实战指南”深入解析了 YOLOv9 目标检测算法,涵盖了其架构、优势、应用场景和优化策略。专栏内容包括:YOLOv9 的入门指南、模型架构解析、车辆识别、数据增强技术、小目标检测处理、实时目标检测调优、训练误差分析、人体姿态识别、Batch Size 设置、激活函数选择、工业缺陷检测、GPU 加速、模型迁移学习、实例分割、智能交通监控、标注工具选择、正负样本平衡和性能评估方法。通过深入浅出的讲解和丰富多样的案例,本专栏旨在为读者提供全面的 YOLOv9 实战指导,助力其在目标检测领域取得成功。
专栏目录
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python Requests库与云计算合作:在云环境中部署和管理HTTP请求,轻松自如
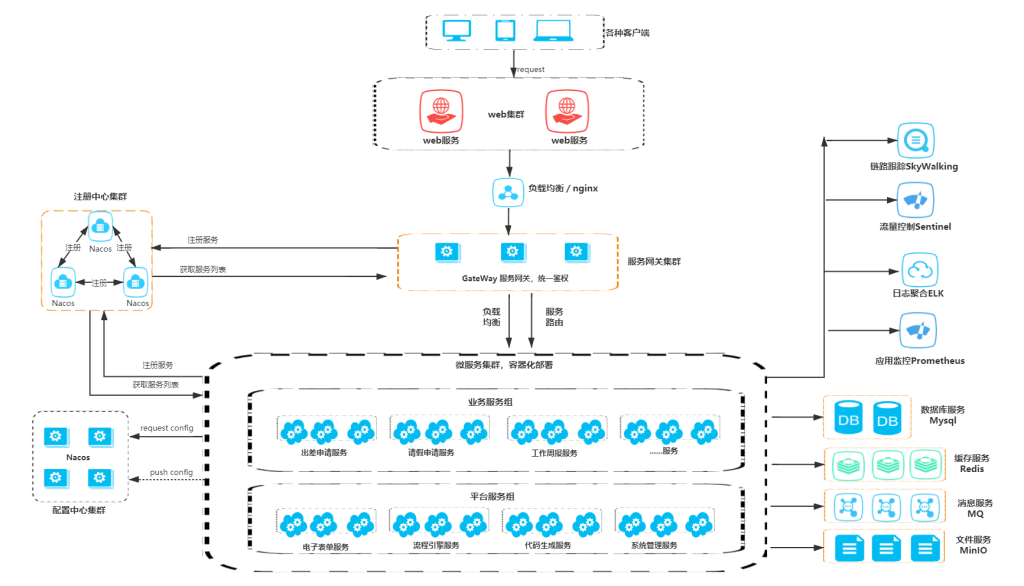
# 1. Python Requests库简介**
Requests库是一个功能强大的Python HTTP库,用于发送HTTP请求并获取响应。它简化了HTTP请求的处理,提供了高级功能,例如会话管理、身份验证和异常处理。Requests库广泛用于云计算、Web抓取和API集成等各种应用程序中。
Requests库提供了直观且易于
Macbook上Python科学计算:使用NumPy和SciPy进行数值计算,让科学计算更轻松

# 1. Python科学计算简介
Python科学计算是指使用Python语言和相关库进行科学和工程计算。它提供了强大的工具,可以高效地处理和分析数值数据。
Python科学计算的主要优势之一是其易用性。Python是一种高级语言,具有清晰的语法和丰富的库生态系统,这使得开发科学计算程序变得容易。
此外,Python科学计算
Python调用Shell命令的性能分析:瓶颈识别,优化策略,提升执行效率

# 1. Python调用Shell命令的原理和方法
Python通过`subprocess`模块提供了一个与Shell交互的接口,
Python数据写入Excel:行业案例研究和应用场景,了解实际应用

# 1. Python数据写入Excel的理论基础
Python数据写入Excel是将数据从Python程序传输到Microsoft Excel工作簿的过程。它涉及到将数据结构(如列表、字典或数据框)转换为Excel中表格或工作表的格式。
数据写入Excel的理论基础包括:
- **数据格式转换:**Python中的数据结构需要转换为Excel支持的格式,如文
Pandas 在物联网中的应用:数据采集与分析,从物联网数据中获取洞察
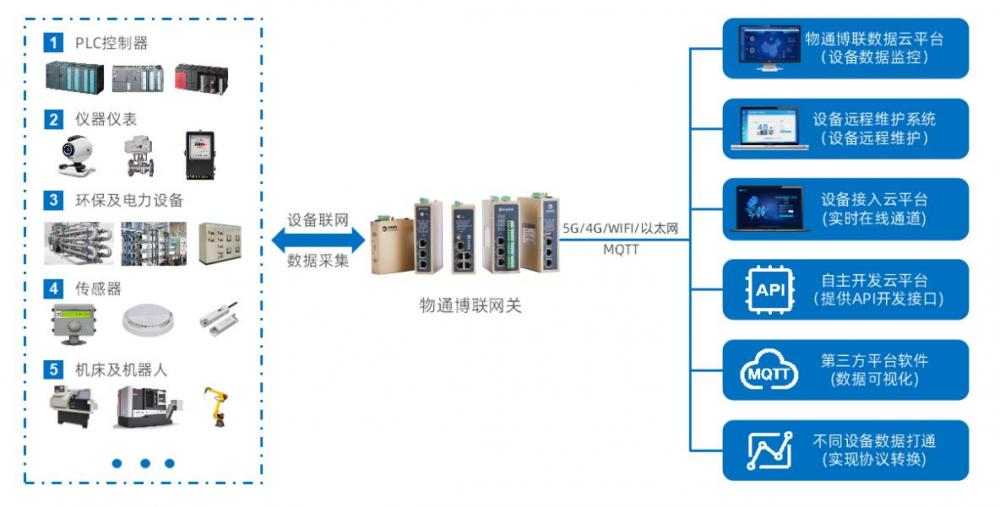
# 1. Pandas 简介和基础**
Pandas 是一个用于数据操作和分析的强大 Python 库。它提供了一系列易于使用的工具,用于处理结构化数据,例如数据帧和序列。Pandas 数据帧是一个类似于电子表格的结构,其中行和列分别表示观测值和变量。序列是类似于列表的一维数组,用于存储单个变量的数据。
Pandas 的核心功能包括数据加载、清洗、转换和分析
Python中sorted()函数的代码示例:实战应用,巩固理解

# 1. Python中sorted()函数的基本用法
sorted()函数是Python中用于对可迭代对象(如列表、元组、字典等)进行排序的内置函数。其基本语法如下:
```python
sorted(iterable, key=None, re
Python读取MySQL数据金融科技应用:驱动金融创新
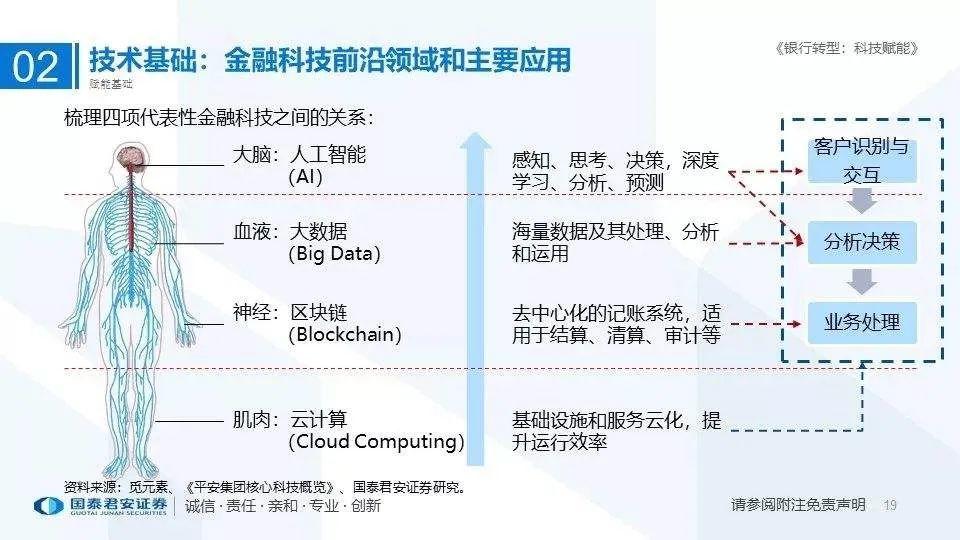
# 1. Python与MySQL数据库**
Python是一种广泛用于数据分析和处理的编程语言。它与MySQL数据库的集成提供了强大的工具,可以高效地存储、管理和操作数据。
**Python连接MySQL数据库**
要连接Python和MySQL数据库,可以使用PyMySQL模块。该模块提供了一个易于使用的接口,允许Python程序与MySQL服务器进行交互。连接参数包括主机、用户名、
Python字符串操作:strip()函数的最佳实践指南,提升字符串处理技能

# 1. Python字符串操作基础
Python字符串操作是处理文本数据的核心技能。字符串操作基础包括:
- **字符串拼接:**使用`+`运算符连接两个字符串。
- **字符串切片:**使用`[]`运算符获取字符串的子字符串。
- **字符串格式化:**使用`f`字符串或`format()`方法将变量插入字符串。
- **字符串比较:**使用`==`和`!=
Python数据可视化:使用Matplotlib和Seaborn绘制图表和可视化数据的秘诀

# 1. Python数据可视化的概述
Python数据可视化是一种利用Python编程语言将数据转化为图形表示的技术。它使数据分析师和科学家能够探索、理解和传达复杂数据集中的模式和趋势。
数据可视化在各个行业中都有广泛的应用,包括金融、医疗保健、零售和制造业。通过使用交互式图表和图形,数据可视化可以帮助利益相关者快速识别异常值、发现趋势并
PyCharm Python代码审查:提升代码质量,打造健壮的代码库

# 1. PyCharm Python代码审查概述
PyCharm 是一款功能强大的 Python IDE,它提供了全面的代码审查工具和功能,帮助开发人员提高代码质量并促进团队协作。代码审查是软件开发过程中至关重要的一步,它涉及对代码进行系统地检查,以识别错误、改进代码结构并确保代码符合最佳实践。PyCharm 的代码审查功能使开发人员能够有效地执行此过程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )