【R语言数据包探索之旅】:基础使用与最佳实践
发布时间: 2024-11-04 17:35:17 阅读量: 20 订阅数: 28 

量化分析-R语言工具数据包:part 1

# 1. R语言数据包的基本概念与安装
## 1.1 R语言数据包简介
R语言是统计分析和数据科学领域中广泛使用的编程语言,其中数据包(Package)是R语言生态系统的核心。数据包是R的扩展,它包含了一系列函数、数据集和文档,便于用户进行特定的统计分析和图形展示。了解数据包的基本概念对于在R中进行高效的工作至关重要。
## 1.2 数据包的安装方法
在R中安装数据包非常简单,用户只需要使用`install.packages()`函数,并提供数据包的名称。例如,要安装名为`ggplot2`的可视化数据包,只需运行以下命令:
```R
install.packages("ggplot2")
```
安装完成后,可以通过`library()`或`require()`函数加载数据包,以便立即使用其中的函数和数据集。
## 1.3 数据包的管理
管理已安装的数据包也很重要,特别是更新和移除不再需要的数据包。可以使用`update.packages()`函数来更新所有或特定的数据包。移除数据包时,只需指定要移除的数据包名称调用`remove.packages()`函数即可。
```R
# 更新特定数据包
update.packages("ggplot2")
# 移除数据包
remove.packages("ggplot2")
```
接下来的章节,我们将深入探讨数据包的结构和函数使用,以及如何在实践中高效运用数据包。
# 2. R语言数据包的结构与函数使用
在R语言中,数据包(package)是扩展语言功能、增加新功能的重要方式。它们包含了数据集、函数、文档等元素,允许用户在不同场景下进行数据分析、图形表示和报告生成等。本章将深入探讨数据包的结构特点、函数的使用,以及实用案例分析。
## 2.1 数据包的结构解析
### 2.1.1 查看数据包信息
R语言提供了诸多函数来获取数据包的相关信息。最常用的函数是`library()`,用于加载数据包,而`installed.packages()`可查看已安装的所有数据包。对于特定数据包的信息,如版本、依赖等,可以使用`packageDescription()`函数进行查询。
```r
# 查看已经安装的数据包
installed_packages <- installed.packages()
print(installed_packages)
# 获取特定数据包的描述信息
package_info <- packageDescription("ggplot2")
print(package_info)
```
### 2.1.2 数据包内部结构的层次
了解数据包内部结构可以帮助我们更有效地使用其中的功能。数据包通常包括以下内容:
- **元数据**:如版本号、作者、许可证等。
- **函数**:数据包主要功能的实现。
- **数据集**:提供的示例数据集。
- **文档**:帮助用户理解如何使用数据包的文档。
- **扩展**:可能包含的额外脚本或文件。
通过`list.files()`函数可以查看特定数据包包含的文件列表。
```r
# 查看数据包内部的文件列表
files_in_package <- list.files(path = system.file(package = "ggplot2"), full.names = TRUE)
print(files_in_package)
```
## 2.2 数据包中的函数
### 2.2.1 函数的基本语法
函数是数据包的核心部分,它们执行特定的任务或算法。R语言中的函数调用语法通常为`function_name(argument1, argument2)`。
```r
# 使用ggplot2包中的qplot函数进行数据可视化
library(ggplot2)
qplot(mpg, wt, data = mtcars, geom = c("point", "smooth"))
```
### 2.2.2 函数参数的传递和默认值
R语言函数支持命名参数和位置参数两种方式传递。位置参数是按照函数定义时的参数位置顺序传递,而命名参数则指明参数名称来传递,这增加了代码的可读性。
```r
# 位置参数传递方式
result1 <- sum(1, 2, 3)
# 命名参数传递方式
result2 <- sum(x = 1, y = 2, z = 3)
```
函数通常会有一些预设的默认参数值,允许用户在调用时不提供某些参数。
### 2.2.3 函数返回值的处理
函数可以返回不同类型的数据,如向量、列表、数据框等。了解函数的返回值类型对于后续的数据处理和分析至关重要。
```r
# 获取数据集mtcars的行数和列数
dim(mtcars)
```
## 2.3 实用案例分析
### 2.3.1 数据包内置数据集的应用
许多R语言的数据包都包含了内置数据集,这些数据集是学习数据包功能的极佳起点。
```r
# 查看ggplot2包内建的数据集
data(package = "ggplot2")
data(mpg, package = "ggplot2") # 加载内置数据集mpg
str(mpg) # 查看数据集结构
```
### 2.3.2 数据包函数在数据分析中的运用
函数与数据集结合可以进行高效的数据分析。以下是一个实际的数据分析案例,使用了`dplyr`包中的函数来对数据集进行操作。
```r
# 使用dplyr包对mtcars数据集进行分析
library(dplyr)
mtcars %>%
filter(cyl == 4) %>%
group_by(am) %>%
summarise(mean mpg = mean(mpg))
```
在本章中,我们介绍了如何查看和理解数据包信息、结构层次,以及如何使用其中的函数进行数据分析。下一章,我们将继续深入探讨数据包的高级功能与实践技巧。
# 3. 数据包的高级功能与实践技巧
在掌握了R语言数据包的安装、结构和函数使用之后,我们可以进一步探讨数据包的高级功能与实践技巧。本章节将深入分析条件筛选与数据清洗技术、数据可视化的实践方法,以及统计模型和机器学习的基本概念和应用。
## 条件筛选与数据清洗
条件筛选是数据分析过程中的关键步骤,它帮助我们根据特定条件提取数据集中的相关信息。数据清洗则是确保数据质量,为后续分析提供准确、完整数据的重要过程。
### 条件筛选的函数应用
在R中,条件筛选通常使用 `subset()` 函数或 `dplyr` 包中的 `filter()` 函数。下面的代码展示了如何使用这些函数对数据集 `mtcars` 进行条件筛选。
```r
# 使用 subset 函数筛选数据
subset_mtcars <- subset(mtcars, mpg > 20)
# 使用 dplyr 包的 filter 函数
library(dplyr)
filter_mtcars <- filter(mtcars, mpg > 20)
```
参数说明:
- `mpg > 20`:这是条件表达式,选择 `mpg`(每加仑英里数)大于20的行。
- `subset()` 函数返回一个数据框,包含满足条件的数据。
- `filter()` 函数同样返回一个数据框,但它是 `dplyr` 包中的一个管道操作符,可以与其他 `dplyr` 函数链式操作。
### 数据清洗技术的集成
数据清洗包括处理缺失值、异常值、重复数据和数据类型转换等。R语言提供了丰富的方法和函数来应对这些挑战。例如,使用 `na.omit()` 函数来删除数据中的所有行,其中含有至少一个缺失值。
```r
# 处理数据中的缺失值
clean_mtcars <- na.omit(mtcars)
```
此外,可以使用 `dplyr` 包中的 `mutate()` 函数进行数据类型转换,或者使用 `summarise()` 函数计算数据的摘要统计量。
## 数据可视化实践
数据可视化是将数据转换为图形表示,以便更直观地理解数据的分布、趋势和关系。R语言提供了多个强大的可视化包,如 `ggplot2`,它基于“图形语法”,可以帮助我们创建高质量的图形。
### 常用的可视化包介绍
`ggplot2` 是R中最流行的可视化包之一,它的设计灵感来源于Wilkinson的“图形语法”理念。该包提供了一个灵活而强大的系统,用于创建各种统计图形。
```r
# 安装并加载 ggplot2 包
install.packages("ggplot2")
library(ggplot2)
# 使用 ggplot2 绘制散点图
ggplot(mtcars, aes(x=wt, y=mpg)) +
geom_point()
```
参数说明:
- `aes(x=wt, y=mpg)`:映射变量到美学属性(x轴是车的重量,y轴是每加仑英里数)。
- `geom_point()`:指定绘制点图,即数据点的图形表示。
### 实际数据集的图形化展示
接下来,我们将使用 `mtcars` 数据集来绘制一个散点图矩阵,这是一个展示数据集中变量间关系的有用方法。
```r
# 加载 GGally 包,它扩展了 ggplot2 的功能
library(GGally)
ggpairs(mtcars)
```
`ggpairs()` 函数会生成一个散点图矩阵,其中对角线上的图形表示各个变量的分布,非对角线上的图形则展示了变量间的相关关系。
## 统计模型与机器学习
统计模型和机器学习技术是数据分析和数据科学中的核心部分,它们可以帮助我们从数据中提取信息、预测未来趋势和分类数据。
### 基础统计模型的构建与应用
在R中,我们可以使用内置的统计模型函数构建简单的线性回归模型。
```r
# 建立线性回归模型
fit <- lm(mpg ~ wt + hp, data = mtcars)
summary(fit)
```
参数说明:
- `mpg ~ wt + hp`:指定了模型公式,即 `mpg` 作为响应变量,`wt`(重量)和 `hp`(马力)作为预测变量。
- `lm()`:表示进行线性回归建模。
- `summary()`:输出模型的详细摘要信息,包括系数估计、R平方值、F统计量等。
### 机器学习包的集成与应用
R语言有多个机器学习包,如 `caret`、`randomForest`、`xgboost` 等,它们可以用来构建复杂的预测模型。
```r
# 安装并加载 caret 包
install.packages("caret")
library(caret)
# 使用 caret 包进行交叉验证的随机森林模型训练
set.seed(123) # 设置随机数种子以便结果可复现
train_control <- trainControl(method = "cv", number = 10)
rf_fit <- train(mpg ~ ., data = mtcars, method = "rf", trControl = train_control)
```
参数说明:
- `trainControl()`:设置交叉验证的参数。
- `method = "cv"`:交叉验证方法,`number = 10` 表示进行10折交叉验证。
- `rf`:随机森林方法,一种集成学习方法。
通过上述步骤,我们不仅能够利用R语言构建和应用统计模型,还能集成和应用机器学习技术,这为数据分析提供了强大的工具和方法论。
# 4. 数据包的自定义与优化
在本章中,我们将深入了解如何创建和优化R语言的自定义数据包。我们将探讨数据包的目录结构、编写规范、测试方法、维护流程,以及性能优化和调试技巧。
## 4.1 创建自定义数据包
自定义数据包是扩展R语言功能的一种强大方式,允许开发者将相关函数和数据集中在一个包中,方便分享和重用。
### 4.1.1 数据包的目录结构与创建步骤
一个标准的R数据包具有特定的目录结构,包括但不限于`R/`目录存放R脚本,`data/`存放数据集,`man/`存放函数文档,以及`DESCRIPTION`和`NAMESPACE`文件。
1. **`R/`目录**:存放所有的R函数文件。
2. **`data/`目录**:存放数据包中包含的数据集,这些数据集可以是R数据对象。
3. **`man/`目录**:存放每个公共函数的文档,通常是.Rd文件。
4. **`DESCRIPTION`文件**:提供数据包的元信息,如名称、版本、作者、依赖等。
5. **`NAMESPACE`文件**:定义数据包的命名空间,说明数据包提供的函数和外部依赖。
创建一个数据包通常涉及以下步骤:
1. 使用`usethis`包中的`create_package`函数创建基本结构。
2. 在`DESCRIPTION`文件中填写必要的元数据。
3. 创建函数并将其保存在`R/`目录下。
4. 编写函数文档并保存在`man/`目录下。
5. 在`NAMESPACE`文件中声明导出的函数。
6. 使用`devtools`包中的`load_all`函数测试数据包。
### 4.1.2 函数文档的编写与规范
函数文档是数据包用户获取帮助的重要渠道。编写高质量的文档需要遵循一定的规范,R语言通常使用`.Rd`文件格式。
一个典型的.Rd文件包含以下部分:
- **标题**:描述文档的函数名称。
- **描述**:对函数功能的简短描述。
- **用法**:函数的语法和所有参数。
- **参数**:每个参数的描述。
- **值**:函数返回值的描述。
- **详细信息**:函数的额外信息。
- **示例**:如何使用该函数。
- **参见**:相关函数或文档的参考。
编写.Rd文件时,使用`roxygen2`注释风格可以自动生成文档,并允许在函数代码旁直接添加注释,然后转换成.Rd文件。
## 4.2 数据包的测试与维护
为了确保数据包的稳定性和可靠性,编写单元测试和进行版本管理是必不可少的步骤。
### 4.2.* 单元测试的实施方法
单元测试是确保单个代码单元正确性的自动化测试过程。在R中,可以使用`testthat`包来实施单元测试。
单元测试通常包含以下步骤:
1. 在`tests/`目录下创建测试文件。
2. 在每个测试文件中,使用`test_that`函数编写测试用例。
3. 测试用例中应包含期望输出和实际输出的对比。
4. 使用`devtools::test()`函数执行所有测试。
### 4.2.2 数据包版本管理与发布
版本控制是管理数据包开发过程的生命周期的关键。`devtools`包提供了发布到CRAN的工具链,而`usethis`包则提供了管理版本的工具。
发布到CRAN的流程大致如下:
1. 确保数据包满足CRAN的发布要求。
2. 更新版本号在`DESCRIPTION`文件中。
3. 检查并更新文档。
4. 使用`devtools::check()`进行全面检查。
5. 上传到CRAN。
版本管理流程包括:
1. 使用`usethis::use_version()`设置版本号。
2. 使用`git`进行版本控制。
3. 使用`usethis::use_github()`链接到GitHub进行协作。
## 4.3 性能优化与调试
随着数据包的增长,优化性能和调试问题变得至关重要。
### 4.3.1 代码效率的分析与优化
性能优化首先需要识别性能瓶颈。`profvis`包是进行性能分析的有用工具,它可以可视化代码的执行时间。
性能优化技巧包括:
1. 使用`Rprof`或`profvis`分析代码性能。
2. 优化循环和条件语句。
3. 利用R的向量化操作减少循环。
4. 考虑使用编译型语言编写的包,如`Rcpp`。
### 4.3.2 调试技巧与问题定位
调试是开发过程中不可或缺的一部分。`browser()`函数可以在代码中设置断点,`traceback()`用于获取错误发生时的调用堆栈。
一些有效的调试技巧包括:
1. 使用`browser()`在代码中设置断点。
2. 使用` traceback()`查看错误发生时的调用堆栈。
3. 利用`print()`和`str()`函数输出中间变量状态。
4. 使用`debug()`函数跟踪函数调用。
5. 利用`debugonce()`进行一次性调试。
通过本章节的介绍,我们了解了如何从头开始创建一个R语言数据包,包括编写函数文档、单元测试、版本管理、性能优化和调试技巧。这些技能对于任何希望在R社区中发布自己工作的开发者来说都是必不可少的。
# 5. R语言数据包的社区与协作
## 5.1 数据包的社区资源
### 5.1.1 CRAN与Bioconductor的介绍
CRAN(Comprehensive R Archive Network)是R语言的官方包仓库,包含了成千上万个经过审核的扩展包,覆盖统计分析、图形展示、机器学习等诸多领域。由于严格的提交和维护标准,CRAN保证了其包的质量和稳定性。此外,Bioconductor是专注于生物信息学的R包仓库,它提供了大量专业工具,帮助研究者分析生物数据,如基因组数据、微阵列数据等。
在社区中,用户可以通过CRAN或Bioconductor的网站检索、下载和安装R包。每个包通常都包含详尽的文档、用户手册以及一个或多个演示示例。这些文档通过R的`help()`函数或在RStudio的帮助面板中可以直接访问,有助于用户了解包的功能和使用方法。
### 5.1.2 社区支持与问题解答的途径
社区支持是学习和使用R语言中不可或缺的部分。除了官方包仓库外,R社区拥有活跃的邮件列表、论坛、Stack Overflow上的R标签等平台,供用户提问、分享知识和解决问题。
邮件列表和论坛多用于讨论特定R包的使用技巧、故障排除以及新功能的反馈。通过订阅特定的邮件列表,可以实时获得相关包的更新和讨论。在Stack Overflow上,用户通过提出问题和回答问题,贡献他们的知识和经验,同时,其他用户也能从中受益。这些途径形成了一种互助互利的氛围,使得R社区持续壮大。
## 5.2 数据包的协作开发
### 5.2.1 版本控制工具在协作中的应用
版本控制工具如Git在R包的协作开发中扮演着重要角色。Git允许开发者跟踪代码的历史变更,可以回滚到之前的版本,同时便于多人协作开发,不会产生代码冲突。R包开发中,通常会在GitHub、GitLab或Bitbucket等平台上创建仓库(repository)来存放代码,并利用这些平台的Pull Request机制来管理协作。
开发者在自己的本地环境中创建分支(branch)来开发新功能或修复错误,开发完成后,通过Pull Request请求将变更合并回主分支。这种方式不仅能保持主分支的稳定,还能促进团队成员间的代码审核和讨论,提高代码质量。
### 5.2.2 开源协作的流程与最佳实践
开源协作的流程通常包括项目规划、开发、测试和部署几个阶段。项目规划阶段,通过Issues功能来记录需求、任务或缺陷,并分配给相应的开发者。开发阶段,开发者在本地环境中独立开发,并定期与远程仓库同步,以减少合并冲突的风险。
测试阶段,自动化测试变得尤为重要,常用的测试工具有`testthat`包,它能够执行单元测试,确保R包中的函数按预期工作。部署阶段,R包可以使用`devtools`包中的`install_github()`函数来安装GitHub上的开发版本,以便测试新功能或进行反馈。
最佳实践包括编写清晰的文档、遵循编码标准、编写测试用例以及定期发布版本。文档应详细记录每个函数的用法和参数说明,编码标准有助于提高代码的可读性和一致性,测试用例则保证了代码的稳定性。版本发布时,应遵循语义化版本控制规则(如MAJOR.MINOR.PATCH),并向社区明确新版本中变更的内容。
## 5.3 社区贡献与个人品牌建设
### 5.3.1 社区贡献的方式与技巧
在R社区进行贡献,可以采用多种方式,例如:
1. **提交反馈和建议**:使用Issues功能提交使用过程中遇到的问题和改进建议。
2. **编写文档和教程**:为一些流行或新颖的包撰写入门指南、高级应用教程等,帮助其他用户更好地理解和使用。
3. **参与讨论和回答问题**:在R社区提供的各种交流平台上积极参与讨论,为其他用户遇到的问题提供解决方案。
贡献时应遵循以下技巧:
- **积极互动**:在讨论和回答问题时,提供清晰、详细的解答,并且保持礼貌和专业。
- **持续学习**:时刻关注R语言及相关技术的最新发展,及时更新自己的知识库。
- **遵守社区规则**:每个社区都有其规则和指南,作为社区成员,应自觉遵守。
### 5.3.2 打造个人品牌与影响力
在R社区建立个人品牌,可以增加个人影响力,为职业生涯带来正面影响。以下是一些有效的方法:
- **活跃于社交媒体和博客**:撰写关于R语言的博客文章,分享R语言相关的经验和见解,在Twitter、LinkedIn等社交媒体上分享R相关的内容,吸引关注。
- **参加并组织活动**:参与R会议、研讨会,甚至可以组织本地的R用户组会议,与同行交流。
- **贡献高质量的R包**:开发和维护优秀的R包,持续优化其功能和性能,使之成为社区中不可或缺的资源。
通过上述方法,不仅可以为R社区做出贡献,也有助于提升个人的编程和解决问题的能力,从而在技术领域建立良好的声誉。随着个人品牌的逐步建立,可能会有更多的机会与他人合作,甚至可能成为开源项目的领导者。
# 6. 未来展望与跨学科应用
## 6.1 R语言与大数据技术的融合
随着大数据时代的到来,R语言作为数据分析和统计计算的强有力工具,其与大数据技术的融合变得越来越重要。R语言与Hadoop、Spark等技术的集成,为处理大规模数据集提供了前所未有的能力和灵活性。
### 6.1.1 与Hadoop、Spark等技术的集成
R语言可以通过多种方式与Hadoop和Spark集成。例如,R的Hadoop插件可以提供与HDFS交互和MapReduce编程的能力。R通过Rhadoop包可以直接与Hadoop集群进行通信,执行分布式计算任务。同样,Apache Spark也为R提供了接口,R用户可以通过SparkR包来利用Spark的内存计算优势,处理大规模数据集。
### 6.1.2 大数据环境下的R语言应用案例
在实际应用中,R语言在大数据环境下展示了其强大的分析能力。比如,金融机构使用R与Hadoop结合进行大规模信用评分模型的构建和验证。此外,在社交媒体分析中,R语言被用来分析海量的用户行为数据,帮助企业理解市场趋势并作出数据驱动的决策。
## 6.2 R语言在不同领域的应用趋势
R语言不仅仅局限于传统的统计分析领域,它在多个行业和学科中都有广泛的应用。
### 6.2.1 生物信息学领域的应用
在生物信息学领域,R语言被用来处理和分析基因表达数据、遗传变异数据以及其他生物大数据。通过Bioconductor项目,R语言提供了一系列专门用于生物数据分析的包。研究人员利用这些包来执行基因序列分析、高通量测序数据的处理等任务。
### 6.2.2 金融分析与经济模型的应用
R语言在金融领域同样大放异彩。它不仅用于风险管理、投资组合优化等金融分析任务,还在宏观经济模型、时间序列分析和高频交易等领域有所应用。R语言的多款扩展包,如`xts`、`zoo`、`quantmod`等,为金融分析师提供了强大的工具集,用于构建复杂的金融模型和进行市场分析。
## 6.3 持续学习与技能提升
在技术发展日新月异的今天,持续学习成为IT从业者的必修课。R语言也不例外,它需要我们不断地学习新技术和方法,以适应行业的发展。
### 6.3.1 推荐的学习资源与课程
对于希望提升R语言技能的专业人士来说,互联网上有大量的资源可供利用。包括Coursera、edX等在线教育平台提供的R语言课程,以及R官方社区(***)和Stack Overflow等论坛上的专业知识分享都是很好的学习途径。此外,各类R语言书籍和电子教程也能够帮助学习者掌握最新的R语言知识。
### 6.3.2 社区贡献与个人品牌建设
在R社区的贡献不仅可以帮助他人,也能增强个人在行业内的影响力。通过提交R语言的代码补丁、为开源项目做贡献或在GitHub上分享自己的R语言项目,都可以建立个人品牌。此外,撰写博客、参加研讨会和会议,甚至出版书籍,都是提高个人专业形象的有效方式。
通过本章的探讨,我们看到R语言的未来充满了无限可能。它在跨学科应用中扮演着越来越重要的角色,随着技术的发展和行业需求的变化,R语言将继续展现出强大的生命力和应用价值。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 R 语言数据包的方方面面,从安装和更新技巧到高级数据处理功能。它涵盖了数据清洗、探索性分析、统计分析、编程实践、性能优化、安全性、并行计算、网络分析、金融数据分析、生物信息学和时间序列分析等主题。通过案例研究、策略和技巧分享,本专栏旨在帮助 R 用户充分利用数据包,提升数据处理效率和分析能力。此外,它还关注数据包的安全性,提供处理安全漏洞的指导。本专栏是 R 语言数据包使用和集成的全面指南,适合各个技能水平的用户。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
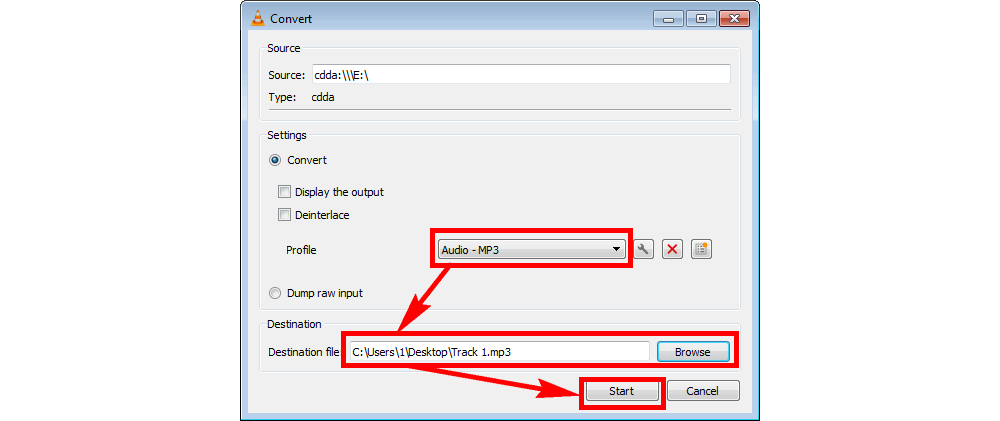
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
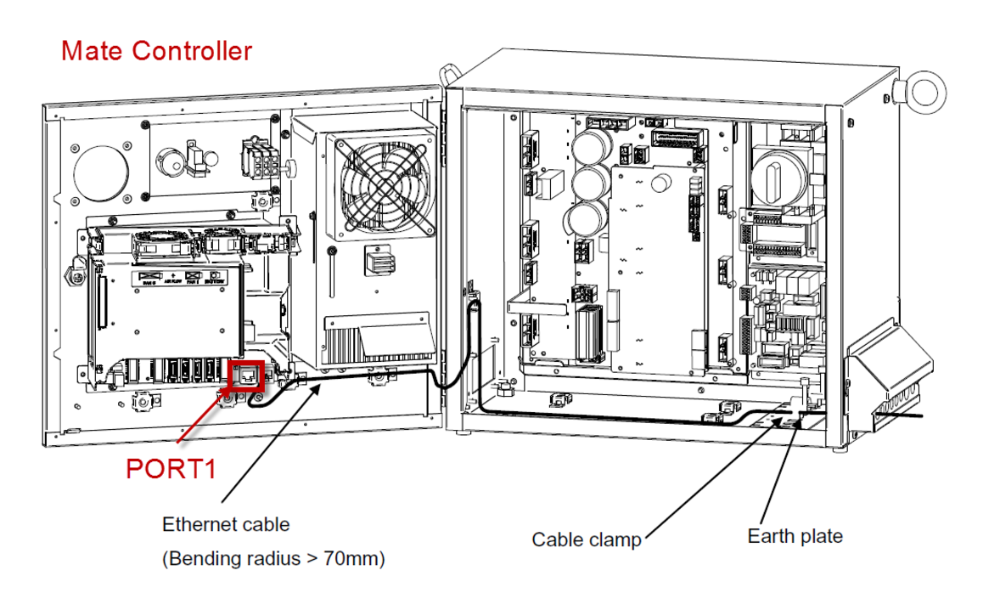
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
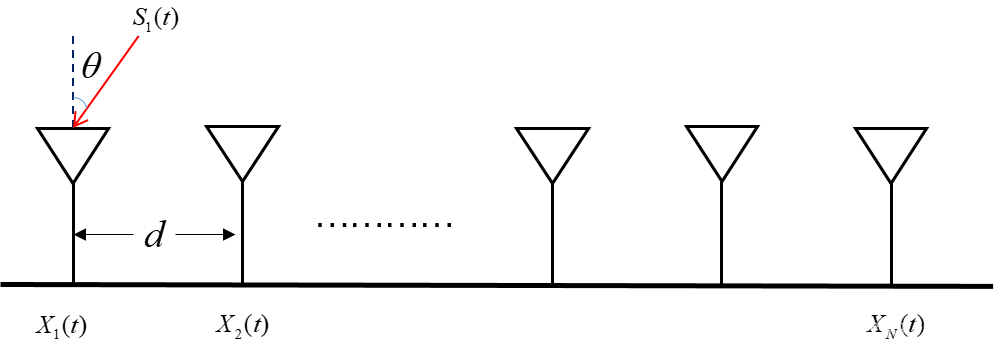
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
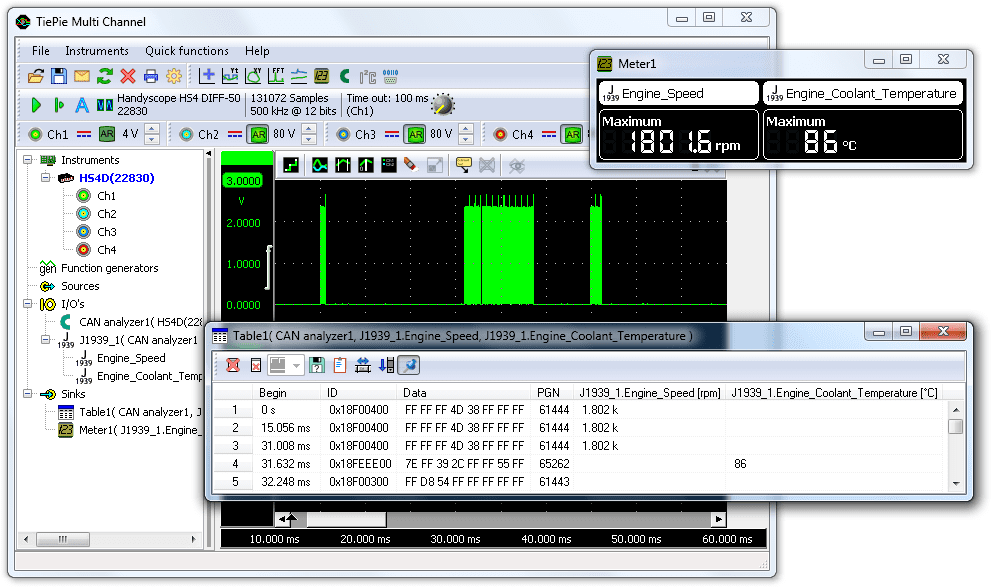
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )