数据挖掘基础:常见数据挖掘算法与应用场景
发布时间: 2024-03-03 21:09:35 阅读量: 101 订阅数: 25 

数据挖掘课程:Python实现推荐系统的协同过滤算法
# 1. 数据挖掘简介
数据挖掘是从大量的数据中发现之前未知的信息、关系、模式等内容的过程。通过运用统计学、人工智能、机器学习等技术,对大量数据进行分析挖掘,从中获取有价值的信息。
## 1.1 数据挖掘概述
数据挖掘是一门跨学科的综合性技术,它涉及到数据库技术、机器学习、模式识别、统计学等多个领域的知识。数据挖掘的过程包括数据的清洗、数据的集成、数据的选择、数据变换和数据挖掘模式的评价等步骤。
## 1.2 数据挖掘的重要性
随着互联网、物联网等技术的发展,数据量呈指数级增长,如何从这些海量数据中获取有用信息成为了重要问题。数据挖掘可以帮助人们从这些数据中找到隐藏的模式、建立起预测模型,为决策提供依据。
## 1.3 数据挖掘的应用领域
数据挖掘广泛应用于市场营销、金融风险管理、医学诊断、生产控制、网络故障诊断等诸多领域。通过对大量数据的分析,可以为这些领域提供有力的决策支持。
以上是数据挖掘简介的内容,接下来将详细介绍数据挖掘算法概览。
# 2. 数据挖掘算法概览
数据挖掘算法主要分为监督学习算法和无监督学习算法两大类,下面将介绍各类算法的基本概念以及常见的算法实例。
### 2.1 监督学习算法
在监督学习中,算法通过使用带有标签的训练集来进行学习。监督学习算法可以用于回归和分类任务。
#### 2.1.1 决策树
决策树是一种常见的监督学习算法,通过构建树状结构来对数据进行分类或回归。它通过一系列的规则来对数据进行分类,每个节点代表一个特征属性,每个分支代表一个特征值,最终的叶子节点代表预测结果。
```python
# 决策树分类示例代码
from sklearn import tree
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
clf.predict([[2., 2.]])
```
**代码说明:** 上述代码使用Python中的`scikit-learn`库实现了一个简单的决策树分类器,通过训练样本`X`和标签`y`进行学习,并对新数据`[2, 2]`进行预测。
#### 2.1.2 逻辑回归
逻辑回归是一种广泛应用于分类问题的监督学习算法,它通过线性回归模型与逻辑函数结合,将结果映射到0和1之间,用于二分类问题。
```java
// 逻辑回归分类示例代码
import org.apache.spark.ml.classification.LogisticRegression;
LogisticRegression lr = new LogisticRegression();
LogisticRegressionModel model = lr.fit(trainingData);
model.transform(testData);
```
**代码说明:** 上述示例使用Java中的Apache Spark机器学习库实现了逻辑回归分类器,通过训练数据`trainingData`拟合模型,并对测试数据`testData`进行分类预测。
#### 2.1.3 支持向量机
支持向量机(SVM)是一种强大的监督学习算法,适用于分类和回归任务。SVM通过寻找最优超平面来实现数据的分类,并能处理高维数据集,具有较好的泛化能力。
```go
// 支持向量机分类示例代码
import "github.com/sjwhitworth/golearn/svm"
clf := svm.NewSVM(svm.LIBSVM)
clf.Fit(trainData)
clf.Predict(testData)
```
**代码说明:** 上述演示使用Go语言中的`golearn`库实现了支持向量机分类器,通过训练数据`trainData`拟合模型,并对测试数据`testData`进行分类预测。
### 2.2 无监督学习算法
无监督学习算法不使用带有标签的训练集,而是通过数据自身的特征进行学习和模式发现。
#### 2.2.1 K均值聚类
K均值聚类是一种常见的无监督学习算法,通过将数据点分配到K个簇中,使得每个数据点与所属簇的中心最近。
```javascript
// K均值聚类示例代码
const kmeans = require('kmeans-js');
const clusters = kmeans(dataset, k);
```
**代码说明:** 以上示例使用JavaScript中的`kmeans-js`库实现K均值聚类算法,对数据集`dataset`进行聚类,分为`k`个簇。
#### 2.2.2 关联规则
关联规则是一种发现数据之间关联关系的无监督学习技术,常用于市场篮分析等领域,发现频繁出现的物品组合。
```python
# 关联规则挖掘示例代码
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_r
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《信息技术基础》专栏深入探讨了信息技术领域的基础知识和核心概念。在文章《数据结构与算法基础:常见数据结构与算法导论》中,读者将学习到各种常见数据结构的原理和应用,以及算法设计与分析的基本方法。另外,专栏还涵盖了《程序设计范式:面向对象编程与函数式编程》,介绍了面向对象编程和函数式编程的概念及其优缺点,帮助读者理解不同编程范式的运用场景。而在《数据挖掘基础:常见数据挖掘算法与应用场景》一文中,读者将了解常见数据挖掘算法的原理及其在实际应用中的场景,为读者提供了深入学习数据挖掘领域的基础。通过本专栏的内容,读者将建立起对信息技术基础的全面认识,为进一步深入学习和应用信息技术打下坚实基础。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PX4飞行控制深度解析】:ECL EKF2算法全攻略及故障诊断
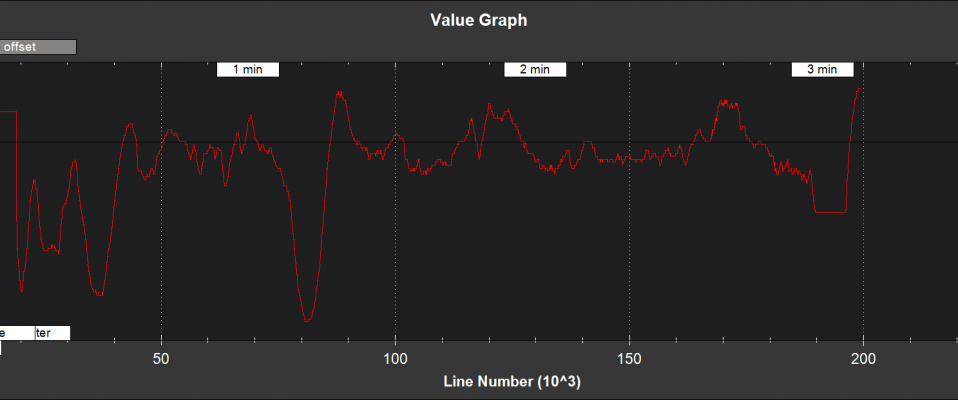
# 摘要
本文对PX4飞行控制系统中的ECL EKF2算法进行了全面的探讨。首先,介绍了EKF2算法的基本原理和数学模型,包括核心滤波器的架构和工作流程。接着,讨论了EKF2在传感器融合技术中的应用,以及在飞行不同阶段对算法配置与调试的重要性。文章还分析了EKF2算法在实际应用中可能遇到的故障诊断问题,并提供了相应的优化策略和性能提升方法。最后,探讨了EKF2算法与人工智能结合的前景、在新平台上的适应性优化,以及社区和开
【电子元件检验工具:精准度与可靠性的保证】:行业专家亲授实用技巧
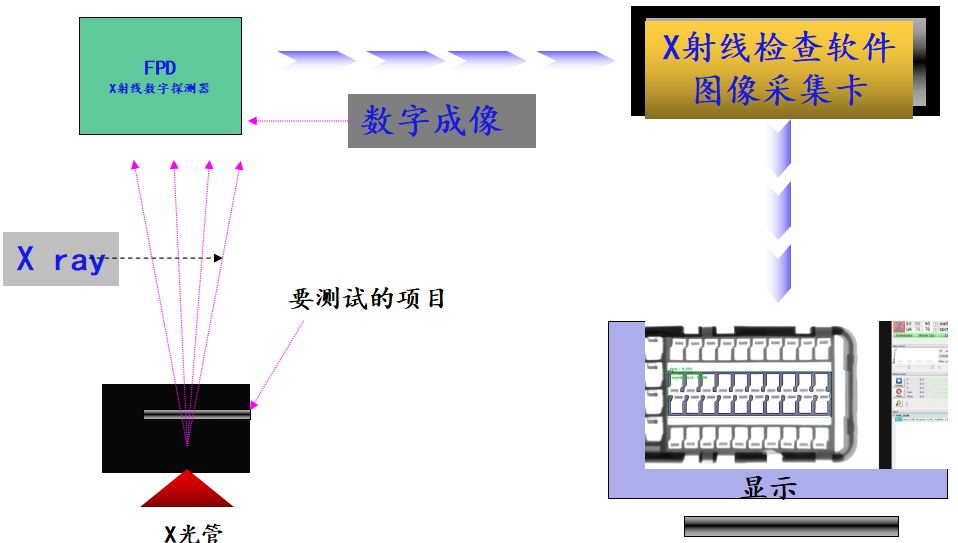
# 摘要
电子元件的检验在现代电子制造过程中扮演着至关重要的角色,确保了产品质量与性能的可靠性。本文系统地探讨了电子元件检验工具的重要性、基础理论、实践应用、精准度提升以及维护管理,并展望了未来技术的发展趋势。文章详细分析了电子元件检验的基本原则、参数性能指标、检验流程与标准,并提供了手动与自动化检测工具的实践操作指导。同时,重点阐述了校准、精确度提
Next.js状态管理:Redux到React Query的升级之路

# 摘要
本文全面探讨了Next.js应用中状态管理的不同方法,重点比较了Redux和React Query这两种技术的实践应用、迁移策略以及对项目性能的影响。通过详细分析Next.js状态管理的理论基础、实践案例,以及从Redux向React Query迁移的过程,本文为开发者提供了一套详细的升级和优化指南。同时,文章还预测了状态管理技术的未来趋势,并提出了最
【802.3BS-2017物理层详解】:如何应对高速以太网的新要求

# 摘要
随着互联网技术的快速发展,高速以太网成为现代网络通信的重要基础。本文对IEEE 802.3BS-2017标准进行了全面的概述,探讨了高速以太网物理层的理论基础、技术要求、硬件实现以及测试与验证。通过对物理层关键技术的解析,包括信号编码技术、传输介质、通道模型等,本文进一步分析了新标准下高速以太网的速率和距离要求,信号完整性与链路稳定性,并讨论了功耗和环境适应性问题。文章还介绍了802.3
【CD4046锁相环实战指南】:90度移相电路构建的最佳实践(快速入门)

# 摘要
本文对CD4046锁相环的基础原理、关键参数设计、仿真分析、实物搭建调试以及90度移相电路的应用实例进行了系统研究。首先介绍了锁相环的基本原理,随后详细探讨了影响其性能的关键参数和设计要点,包括相位噪声、锁定范围及VCO特性。此外,文章还涉及了如何利用仿真软件进行锁相环和90度移相电路的测试与分析。第四章阐述了CD
数据表分析入门:以YC1026为例,学习实用的分析方法

# 摘要
随着数据的日益增长,数据分析变得至关重要。本文首先强调数据表分析的重要性及其广泛应用,然后介绍了数据表的基础知识和YC1026数据集的特性。接下来,文章深入探讨数据清洗与预处理的技巧,包括处理缺失值和异常值,以及数据标准化和归一化的方法。第四章讨论了数据探索性分析方法,如描述性统计分析、数据分布可视化和相关性分析。第五章介绍了高级数据表分析技术,包括高级SQL查询
Linux进程管理精讲:实战解读100道笔试题,提升作业控制能力
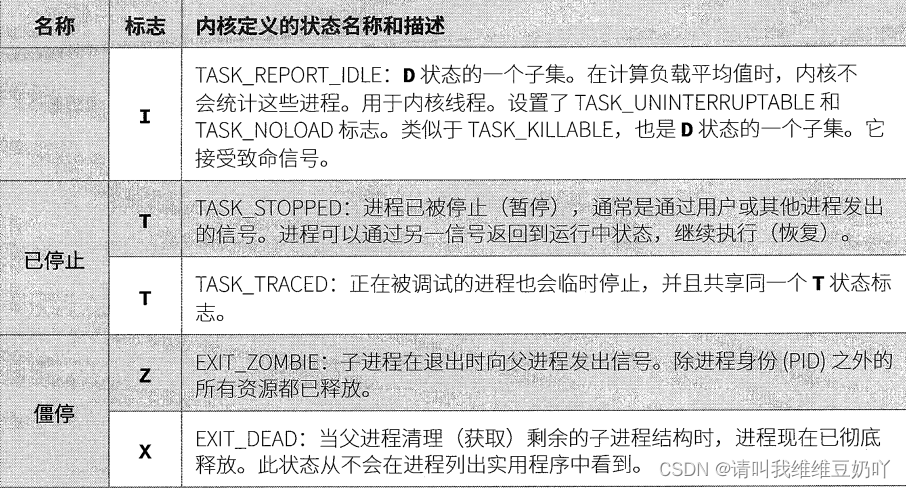
# 摘要
Linux进程管理是操作系统核心功能之一,对于系统性能和稳定性至关重要。本文全面概述了Linux进程管理的基本概念、生命周期、状态管理、优先级调整、调度策略、进程通信与同步机制以及资源监控与管理。通过深入探讨进程创建、终止、控制和优先级分配,本文揭示了进程管理在Linux系统中的核心作用。同时,文章也强调了系统资源监控和限制的工具与技巧,以及进程间通信与同步的实现,为系统管理员和开
STM32F767IGT6外设扩展指南:硬件技巧助你增添新功能
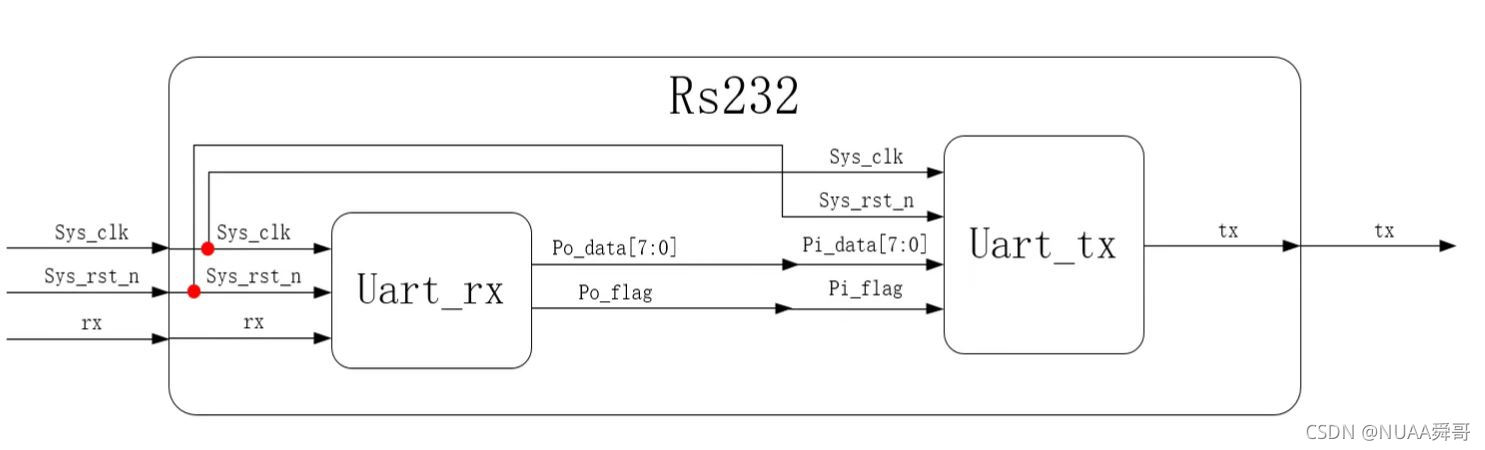
# 摘要
本文全面介绍了STM32F767IGT6微控制器的硬件特点、外设扩展基础、电路设计技巧、软件驱动编程以及高级应用与性
【精密定位解决方案】:日鼎伺服驱动器DHE应用案例与技术要点

# 摘要
本文详细介绍了精密定位技术的概览,并深入探讨了日鼎伺服驱动器DHE的基本概念、技术参数、应用案例以及技术要点。首先,对精密定位技术进行了综述,随后详细解析了日鼎伺服驱动器DHE的工作原理、技术参数以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )