Go语言与GraphQL的迁移故事】:从REST到GraphQL的转变的详细教程
发布时间: 2024-10-22 18:29:31 阅读量: 22 订阅数: 25 
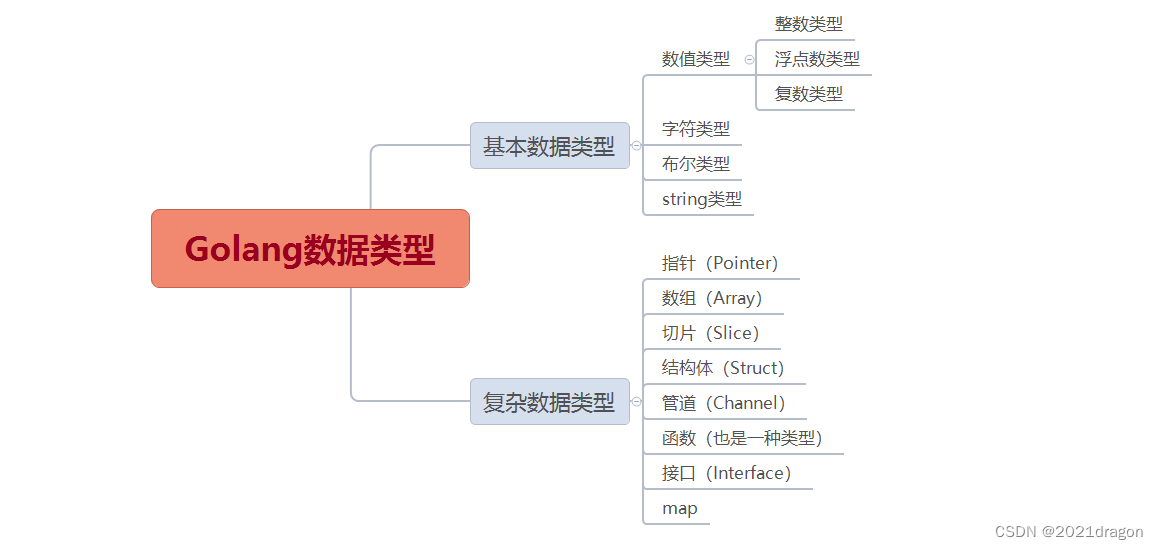
# 1. Go语言与GraphQL简介
Go语言,也称为Golang,是Google开发的一种静态类型、编译型语言,以其简洁的语法、高效的性能和强大的并发处理能力而闻名。近年来,Go语言在API开发和云服务领域表现出了卓越的潜力。
GraphQL是一种用于API的查询语言,由Facebook于2012年推出,并在2015年开源。与传统的REST架构相比,GraphQL允许客户端准确地指定他们所需数据的结构,这样可以减少网络带宽消耗,并且提供了更强的类型系统来提升开发效率。
本章将对Go语言和GraphQL进行基础性介绍,涵盖它们各自的特性、优势以及它们如何能够协同工作,为开发者提供构建高效、可扩展后端服务的新视角。接下来的章节会深入探讨Go语言与GraphQL结合的具体实践,并提供案例研究。
# 2. REST API的挑战与不足
### 2.1 REST API的基本概念和工作原理
REST(Representational State Transfer)API是一种基于HTTP协议的软件架构风格,用于构建web服务。REST的核心概念包括资源、资源的表示、状态的转移以及统一的接口。资源是指网络中的实体或抽象的对象,如文档、图片或单一数据项。资源的表示是指数据在客户端和服务器端之间的交换格式,通常是JSON或XML。状态的转移是指在客户端和服务器之间通过HTTP动词(GET、POST、PUT、DELETE等)进行资源的读取、创建、更新和删除操作。统一的接口意味着使用HTTP标准方法对资源进行操作,以及对资源的查询和过滤都使用标准的HTTP协议。
REST API工作原理基于客户端-服务器模型,客户端发送请求到服务器,服务器返回相应的数据或状态码。数据通常以JSON或XML格式返回,而状态码则告诉客户端请求是否成功,比如200 OK表示请求成功,404 Not Found表示资源未找到。
```json
// 示例:REST API返回的JSON数据
{
"id": "123",
"name": "John Doe",
"email": "john.***"
}
```
### 2.2 REST API的局限性分析
#### 2.2.1 数据过载问题
REST API的一个挑战是数据过载问题。客户端在请求数据时,往往需要从服务器端获取比实际需要更多的信息。这不仅导致了不必要的数据传输,而且增加了客户端处理数据的负担。例如,客户端如果只需要用户的姓名和邮箱,却必须下载包含用户的所有信息的数据集(如用户的所有个人资料、设置等),这就造成了一定程度上的资源浪费和效率低下。
#### 2.2.2 超媒体作为应用状态引擎(HATEOAS)的挑战
HATEOAS是REST架构中一个高级特性,它的理念是使客户端能够通过超链接自行发现API的功能。然而,在实际开发中,HATEOAS的实现较为复杂,难以维护,并且给开发者带来了额外的学习成本。许多开发者和团队在实现REST API时倾向于简化,忽略了HATEOAS,从而失去了REST设计中的一环。
#### 2.2.3 REST与前端需求的不匹配
随着前端框架的发展,前端应用变得越来越动态和复杂,前端开发者希望后端API能够提供更加灵活的数据获取方式。REST API通常需要前端开发者明确地知道他们需要哪些数据,并且每次数据变化都需要新的API调用。这样的固定模式与现代前端应用的需求不匹配,对API的使用造成了限制。
### 2.3 GraphQL的提出背景
#### 2.3.1 GraphQL的起源和发展
GraphQL是由Facebook于2012年开发并开源的一种查询语言。它旨在解决REST API在数据过载和缺乏灵活性方面的问题。Facebook内部的软件工程师希望有一种方式能够更高效地从后端获取数据,并且能够在不增加服务器负载的情况下仅请求必要的数据。
在2015年,Facebook将GraphQL开源,并迅速得到众多技术社区的关注和采用。如今,GraphQL已被广泛应用于各种前端和后端框架中,它不仅限于JavaScript环境,而且可以在多种编程语言中实现。
#### 2.3.2 GraphQL的核心理念和优势
GraphQL的核心理念在于,客户端可以精确地声明它们需要哪些数据,而服务器端则返回精确匹配的响应。这种查询方式极大地提高了数据传输的效率和灵活性。相比于REST API,GraphQL具有以下优势:
- **减少数据过载**:客户端可以避免不必要的数据传输,因为它们只需要请求它们真正需要的数据。
- **高效的数据处理**:由于数据结构是预先定义好的,服务器能够更高效地处理请求,并且可以避免对数据库的多次查询。
- **版本控制的简化**:GraphQL使得API的版本控制变得不必要,因为可以通过修改查询类型来适应新的需求而不是引入新的API端点。
- **强大的类型系统**:GraphQL的类型系统使得文档和工具能够提供更强大的支持,如自动完成和类型检查。
通过这些优势,GraphQL提供了一种更加现代和高效的API解决方案,能够更好地与现代前端应用的需求相匹配。
# 3. Go语言与GraphQL结合的实践
## 3.1 Go语言中实现GraphQL的基础
### 3.1.1 Go语言概述及安装配置
Go语言,也被称为Golang,是由Google开发的一种静态类型、编译型语言,它拥有简洁、快速、安全等特性。Go的设计哲学之一是提供一个简单的语言来简化复杂系统的构建过程,因此,它的语法相对简单,且有着强大的并发处理能力。在服务端开发、云基础设施、微服务架构等领域,Go语言已经成为许多开发者的选择。
要在Go语言环境中使用GraphQL,首先需要确保你已经安装了Go语言。以下是安装Go的步骤:
1. 访问[Go官方下载页面](***。
2. 根据你的操作系统选择合适的安装包下载。
3. 运行下载的安装包并遵循安装向导完成安装。
4. 验证安装是否成功,通过命令行输入 `go version`。
此外,设置Go的环境变量是必须的,这通常包括`GOPATH`和`GOROOT`。`GOPATH`是你开发Go代码的工作区,而`GOROOT`是Go的安装目录。在命令行中设置这两个环境变量如下:
```sh
export GOROOT=/usr/local/go
export GOPATH=$HOME/go
export PATH=$PATH:$GOROOT/bin:$GOPATH/bin
```
### 3.1.2 GraphQL框架选择与集成
选择合适的GraphQL框架对于在Go语言中成功实现GraphQL至关重要。目前,有多个流行的Go语言GraphQL库,如`graphql-go`、`gqlgen`、`graphql-go/graphql`等。根据项目的需要和个人喜好,你可以选择其中之一。以`graphql-go`为例,它是一个简单易用的库,适合快速集成GraphQL到Go应用中。
以下是使用`graphql-go`进行集成的步骤:
1. 通过`go get`命令安装`graphql-go`库:
```**
***/graphql-go/graphql
```
2. 创建一个GraphQL Schema,这将定义你的数据模型和服务的入口点。
```go
package main
import (
"log"
"net/http"
"***/graphql-go/graphql"
)
func main() {
// 定义你的GraphQL schema...
http.HandleFunc("/graphql", func(w http.ResponseWriter, r *http.Request) {
// 处理GraphQL查询...
})
log.Println("Starting server at port 8080")
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}
```
3. 通过编写解析器函数来处理查询,解析器函数将连接你的GraphQL Schema和后端数据源。
请注意,上述代码只是一个框架的起始点。在实践中,你需要根据具体的业务需求定义详细的类型、字段和解析器。
## 3.2 构建GraphQL服务的步骤
### 3.2.1 定义Schema
在Go语言中实现GraphQL服务的首要步骤是定义一个GraphQL Schema,这类似于REST API中的路由定义。GraphQL Schema是整个服务的数据模型和操作定义,它确定了客户端可以请求哪些数据,以及如何通过类型系统对这些数据进行操作。
在Go语言中,你可以使用`graphql-go`库来定义一个简单的GraphQL Schema:
```go
package main
import (
"log"
"net/http"
"***/graphql-go/graphql"
)
var schema, _ = graphql.NewSchema(graphql.SchemaConfig{
Query: graphql.NewObject(graphql.ObjectConfig{
Name: "Query",
Fields: graphql.Fields{
"hello": &graphql.Field{
Type: graphql.String,
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
return "world", nil
},
},
},
}),
})
func main() {
// 与之前相同的HTTP处理代码...
}
```
在此示例中,我们定义了一个查询类型(Query),其中包含一个`hello`字段。`hello`字段在被请求时,总是返回字符串`"world"`。
### 3.2.2 解析器的编写和配置
解析器是GraphQL中最为核心的部分,它负责处理字段的值。每个字段都可以有对应的解析器函数,当客户端查询该字段时,解析器将被调用,从而可以访问数据库、执行计算或返回固定值。
在Go语言中,一个字段的解析器可能看起来是这样的:
```go
func resolveName(p graphql.ResolveParams) (interface{}, error) {
// 假设我们有一个`user`字段在查询参数中
user, ok := p.Source.(map[string]interface{})["user"]
if ok {
// 返回用户的名字
return user.(map[string]interface{})["name"], nil
}
return nil, nil
}
// 在定义Schema时,将resolveName函数关联到对应的字段
NameField := graphql.NewField(graphql.FieldConfig{
Name: "name",
Type: graphql.String,
Resolve: resolveName,
})
```
解析器通常接收一个`graphql.ResolveParams`类型的参数,该参数包含了查询中提供的各种信息,如父对象、字段信息等。解析器需要返回一个值,这个值应与字段类型兼容。
### 3.2.3 高级特性,如分页、过滤和缓存
在实际应用中,为了提升性能和用户体验,我们通常需要引入一些高级特性,比如数据分页、过滤和缓存。这些高级特性可以为客户端提供更好的控制,同时优化后端服务的负载。
#### 分页
在GraphQL中实现分页通常需要在查询中引入额外的参数,如`first`和`after`。以下是一个简单的分页解析器实现的例子:
```go
func resolveUsers(p graphql.ResolveParams) (interface{}, error) {
args :=
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面探讨了 Go 语言中 GraphQL 的方方面面,从入门指南到高级特性和最佳实践。涵盖了构建复杂查询和变更、实现自定义解析器和分页功能、确保安全、集成中间件和插件、设计可扩展的微服务架构、调试技巧、错误处理、数据加载优化、响应缓存、模式设计、权限管理、订阅、云原生集成、测试策略、版本管理和迁移故事。通过深入的教程、专家见解和性能分析,本专栏旨在帮助开发人员充分利用 Go 和 GraphQL 的强大功能,构建高效、安全且可维护的图形 API。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【材料选择专家指南】:如何用最低成本升级漫步者R1000TC北美版音箱
# 摘要
本文旨在深入探讨漫步者R1000TC北美版音箱的升级理论与实践操作指南。首先分析了音箱升级的重要性、音质构成要素,以及如何评估升级对音质的影响。接着介绍了音箱组件工作原理,特别是扬声器单元和分频器的作用及其选择原则。第三章着重于实践操作,提供扬声器单元、分频器和线材的升级步骤与技巧。第四章讨论了升级效果的评估方法,包括使用音频测试软件和主观听感分析。最后,第五章探讨了进阶升级方案,如音频接口和蓝牙模块的扩展,以及个性化定制声音风格的策略。通过本文,读者可以全面了解音箱升级的理论基础、操作技巧以及如何实现个性化的声音定制。
# 关键字
音箱升级;音质提升;扬声器单元;分频器;调音技巧
【PyQt5控件进阶】:日期选择器、列表框和文本编辑器深入使用

# 摘要
PyQt5是一个功能强大的跨平台GUI框架,它提供了丰富的控件用于构建复杂的应用程序。本文从PyQt5的基础回顾和控件概述开始,逐步深入探讨了日期选择器、列表框和文本编辑器等控件的高级应用和技巧。通过对控件属性、方法和信号与槽机制的详细分析,结合具体的实践项目,本文展示了如何实现复杂日期逻辑、动态列表数据管理和高级文本编辑功能。此外,本文还探讨了控件的高级布局和样式设计
MAXHUB后台管理新手速成:界面概览至高级功能,全方位操作教程

# 摘要
MAXHUB后台管理平台作为企业级管理解决方案,为用户提供了一个集成的环境,涵盖了用户界面布局、操作概览、核心管理功能、数据分析与报告,以及高级功能的深度应用。本论文详细介绍了平台的登录、账号管理、系统界面布局和常用工具。进一步探讨了用户与权限管理、内容管理与发布、设备管理与监控的核心功能,以及如何通过数据分析和报告制作提供决策支持。最后,论述了平台的高
深入解析MapSource地图数据管理:存储与检索优化之法
# 摘要
本文对MapSource地图数据管理系统进行了全面的分析与探讨,涵盖了数据存储机制、高效检索技术、数据压缩与缓存策略,以及系统架构设计和安全性考量。通过对地图数据存储原理、格式解析、存储介质选择以及检索算法的比较和优化,本文揭示了提升地图数据管理效率和检索性能的关键技术。同时,文章深入探讨了地图数据压缩与缓存对系统性能的正面影响,以及系统架构在确保数据一致性
【结果与讨论的正确打开方式】:展示发现并分析意义

# 摘要
本文深入探讨了撰写研究论文时结果与讨论的重要性,分析了不同结果呈现技巧对于理解数据和传达研究发现的作用。通过对结果的可视化表达、比较分析以及逻辑结构的组织,本文强调了清晰呈现数据和结论的方法。在讨论部分,提出了如何有效地将讨论与结果相结合、如何拓宽讨论的深度与广度以及如何提炼创新点。文章还对分析方法的科学性、结果分析的深入挖掘以及案例分析的启示进行了评价和解读。最后
药店管理系统全攻略:UML设计到实现的秘籍(含15个实用案例分析)
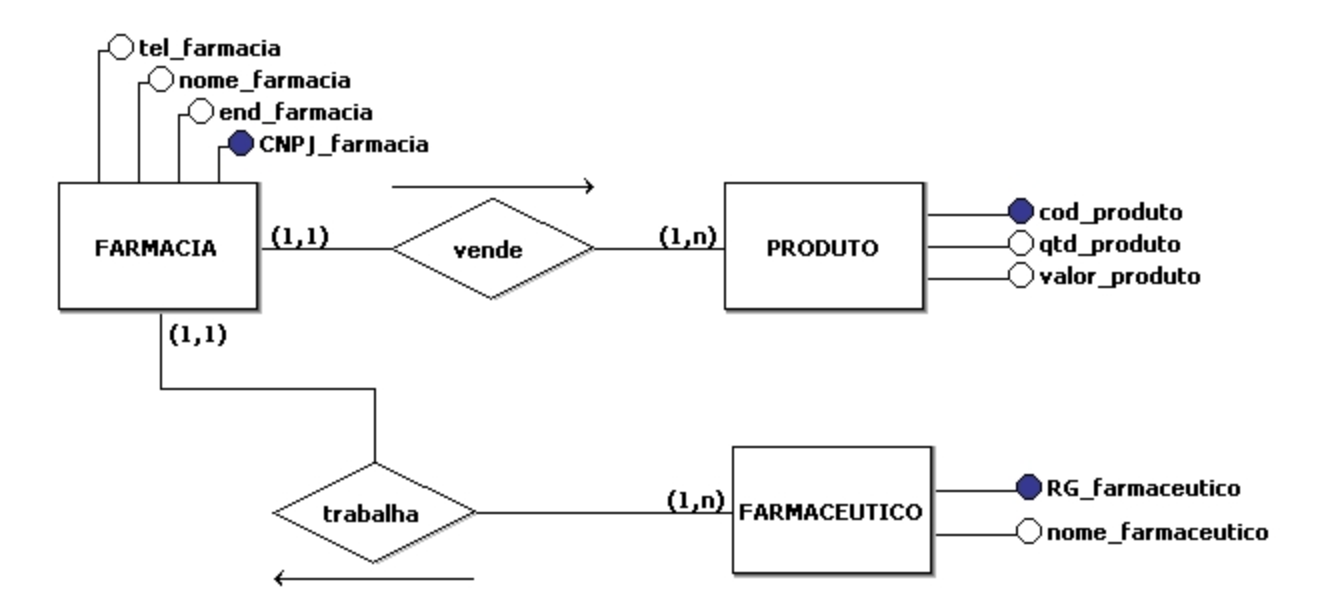
# 摘要
本论文首先概述了药店管理系统的基本结构和功能,接着介绍了UML理论在系统设计中的应用,详细阐述了用例图、类图的设计原则与实践。文章第三章转向系统的开发与实现,涉及开发环境选择、数据库设计、核心功能编码以及系统集成与测试。第四章通过实践案例深入探讨了UML在药店管理系统中的应用,包括序列图、活动图、状态图及组件图的绘制和案例分析。最后,论文对药店管理系统的优化与维护进行了讨论,提
【555定时器全解析】:掌握方波发生器搭建的五大秘籍与实战技巧
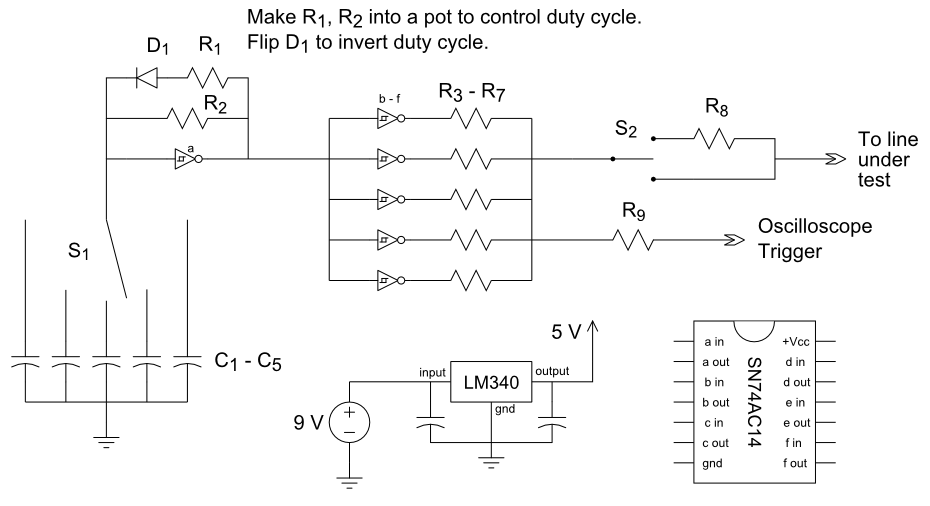
# 摘要
本文详细介绍了555定时器的工作原理、关键参数、电路搭建基础及其在方波发生器、实战应用案例以及高级应用中的具体运用。首先,概述了555定时器的基本功能和工作模式,然后深入探讨了其在方波发生器设计中的应用,包括频率和占空比的控制,以及实际实验技巧。接着,通过多个实战案例,如简易报警器和脉冲发生器的制作,展示了555定时器在日常项目中的多样化运用。最后,分析了555定时器的多用途扩展应用,探讨了其替代技术,
【Allegro Gerber导出深度优化技巧】:提升设计效率与质量的秘诀

# 摘要
本文全面介绍了Allegro Gerber导出技术,阐述了Gerber格式的基础理论,如其历史演化、
Profinet通讯优化:7大策略快速提升1500编码器响应速度
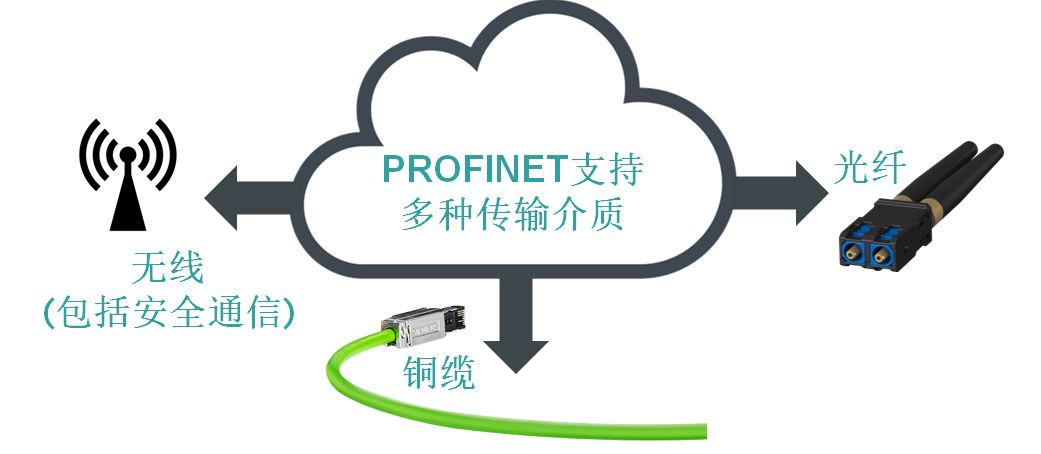
# 摘要
Profinet作为一种工业以太网通讯技术,其通讯性能和编码器的响应速度对工业自动化系统至关重要。本文首先概述了Profinet通讯与编码器响应速度的基础知识,随后深入分析了影响Profinet通讯性能的关键因素,包括网络结构、数据交换模式及编码器配置。通过优化网络和编码器配置,本文提出了一系列提升Profinet通讯性能的实践策略。进一步,本文探讨了利用实时性能监控、网络通讯协议优化以及预
【时间戳转换秘籍】:将S5Time转换为整数的高效算法与陷阱分析

# 摘要
时间戳转换在计算机科学与信息技术领域扮演着重要角色,它涉及到日志分析、系统监控以及跨系统时间同步等多个方面。本文首先介绍了时间戳转换的基本概念和重要性,随后深入探讨了S5Time与整数时间戳的理论基础,包括它们的格式解析、定义以及时间单位对转换算法的影响。本文重点分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )