深入理解Go中的GraphQL】:手把手教你从零开始构建复杂的查询和变更
发布时间: 2024-10-22 17:31:20 订阅数: 3 
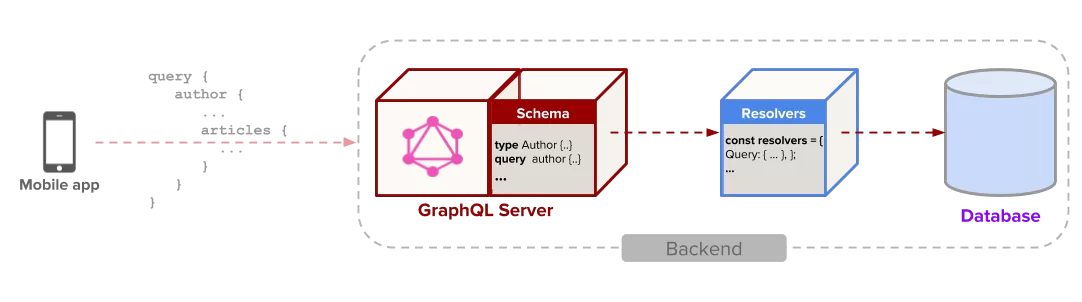
# 1. GraphQL基础概述
GraphQL是一种用于API的查询语言,由Facebook开发并开源。它允许客户端精确地指定所需数据,减少网络负载,提高效率。与传统的REST API相比,GraphQL提供了更好的版本控制,因为客户端不需要依赖特定的URL格式。其核心概念包括类型系统、查询、变更和字段。GraphQL允许构建一个完整的类型系统来描述数据,客户端通过查询来获取所需数据,而变更则用于修改数据。字段是查询中包含的最小数据单元。在第二章我们将详细探讨如何搭建Go语言的开发环境,为构建GraphQL服务奠定基础。
# 2. 搭建Go语言开发环境
## 2.1 Go语言安装与环境配置
### 环境准备
在搭建Go语言开发环境之前,需要确保你的计算机满足以下基本要求:
- 操作系统:支持Windows 7及以上,Mac OS X 10.8及以上,或Linux系统。
- 硬件:建议至少2GB内存和足够的硬盘空间。
### 安装Go
接下来,通过以下步骤在您的计算机上安装Go语言环境:
1. 访问Go语言官方下载页面:[***](***
** 根据你的操作系统选择合适的版本下载。
3. 安装下载的文件。对于Windows和Mac用户,双击安装程序并遵循指示即可。Linux用户需要解压下载的压缩包到指定目录。
### 环境变量配置
安装完Go语言后,需要设置环境变量以便在任何路径下使用`go`命令。以下是配置环境变量的步骤:
#### Windows
- 打开系统属性,选择“高级”标签页。
- 点击“环境变量”按钮。
- 在“系统变量”区域,点击“新建”。
- 变量名设为`GOPATH`,变量值设为你的工作目录路径(例如`C:\go-work`)。
- 在系统变量中找到`Path`变量并编辑,添加`%GOPATH%\bin`到变量值的末尾。
#### Mac/Linux
- 打开终端,编辑你的`~/.bash_profile`(或`~/.zshrc`等,取决于你的shell配置)文件。
- 添加以下内容:
```bash
export GOPATH=$HOME/go-work
export PATH=$PATH:$GOPATH/bin
```
- 保存文件后,运行`source ~/.bash_profile`(或对应的shell配置文件)使更改生效。
### 验证安装
安装和配置完成后,打开新的终端窗口,执行以下命令以验证Go语言是否安装成功:
```bash
go version
```
如果看到类似于`go version go1.18 windows/amd64`(根据你安装的版本和操作系统会有所不同)的输出,则表示Go语言已经成功安装并配置好了。
## 2.2 Go语言基础语法回顾
### 基本类型
Go语言中包含了几种基本数据类型,如整型、浮点型、布尔型和字符串。以下是一些基础的语法示例:
```go
var i int = 10
var f float32 = 3.14
var b bool = true
var s string = "Hello, Go!"
```
### 控制结构
Go语言中的控制结构包括`if`、`switch`和`for`等,它们的语法和其他语言类似,但Go的控制结构不需要小括号,而是使用大括号。
#### if
```go
if a > 10 {
// do something
}
```
#### switch
```go
switch os := runtime.GOOS; os {
case "darwin":
// macOS
case "linux":
// Linux
default:
// other platforms
}
```
#### for
```go
for i := 0; i < 10; i++ {
// do something
}
```
### 函数
Go语言的函数是一等公民,可以被赋值给变量,作为参数传递,或者作为返回值。
```go
func add(a int, b int) int {
return a + b
}
```
## 2.3 Go模块和依赖管理
### 模块介绍
Go模块是一个包含Go包的树形目录结构,并伴随有一个`go.mod`文件,这个文件定义了模块的路径和依赖的特定版本。
### 初始化模块
为了管理依赖关系,首先需要初始化一个Go模块。在你的项目根目录下,运行以下命令:
```***
***/mymodule
```
该命令会创建一个`go.mod`文件,这个文件会记录你的模块名称和依赖项。
### 添加依赖
要添加一个新的依赖项,只需运行:
```***
***/some/module
```
这会将指定的模块添加到你的`go.mod`文件中,并下载到你的`GOPATH`目录下。
### 更新依赖
要更新或降级依赖项,可以使用`-u`标志:
```***
***/some/module
```
这将更新指定的模块到最新版本。若要降级到特定版本,可以指定版本号:
```***
***/some/module@v1.2.3
```
### 查看依赖
运行以下命令,可以查看当前模块的依赖树:
```bash
go mod tidy
go list -m all
```
第一个命令会清理不再需要的依赖项,第二个命令会列出当前模块的依赖项及其版本。
### 运用工具
Go语言提供了一个工具`go mod`,可以用来处理模块相关的各种操作。例如,验证依赖项的完整性:
```bash
go mod verify
```
以上是Go语言开发环境的搭建、基础语法回顾以及模块和依赖管理的介绍,为后续章节中构建GraphQL服务提供了基础环境和工具。接下来,我们将会进入GraphQL服务的设计与实现阶段。
# 3. 构建GraphQL服务
## 3.1 GraphQL服务的设计原则
构建GraphQL服务首先需要理解其设计原则,这不同于传统的REST API设计。GraphQL的核心思想是将客户端需要的数据以一种声明式的方式进行描述,并由服务端精确地返回这些数据。
### 3.1.1 单一数据源
GraphQL鼓励使用单一数据源,这样可以简化客户端与服务端的数据交互。无论后端的数据存储结构如何复杂,都通过GraphQL层进行抽象和封装。
### 3.1.2 客户端指定数据结构
客户端在查询时能够指定所需的数据结构,服务端根据请求返回精准的数据。这样客户端开发者能够清晰地获取需要的数据,同时也减少了网络传输和服务器负载。
### 3.1.3 强类型系统
GraphQL模式是一个强类型的系统,这意味着每个字段都有其类型,类型之间有明确的关联。这个特性在开发过程中提供了自动完成和文档化的支持,也可以在编译时捕获错误。
### 3.1.4 版本无关
通过GraphQL模式,服务端可以清晰地定义和管理API版本。因为API是根据客户端的请求动态解析的,所以几乎不需要通过版本控制API。
## 3.2 实现GraphQL模式(Schema)
在Go中实现GraphQL模式,需要定义类型和字段,并构建类型之间的关系。
### 3.2.1 定义类型和字段
```go
package schema
import "***/graphql-go/graphql"
var PersonType = graphql.NewObject(graphql.ObjectConfig{
Name: "Person",
Fields: graphql.Fields{
"id": &graphql.Field{Type: graphql.Int},
"name": &graphql.Field{Type: graphql.String},
"age": &graphql.Field{Type: graphql.Int},
},
})
```
在此示例代码中,定义了一个名为`Person`的对象类型,它具有三个字段:`id`、`name`和`age`,每个字段都有相应的类型。
### 3.2.2 构建类型之间的关系
构建类型之间的关系,例如,我们可以有一个`Query`类型,其中包含了一个字段,用于获取`Person`类型的数据:
```go
var QueryType = graphql.NewObject(graphql.ObjectConfig{
Name: "Query",
Fields: graphql.Fields{
"person": &graphql.Field{
Type: PersonType,
Args: graphql.FieldConfigArgument{
"id": &graphql.ArgumentConfig{Type: graphql.Int},
},
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
// 此处应该查询数据库并返回相应的Person实例
// 此处使用示例数据替代
if id, ok := p.Args["id"].(int); ok {
return map[string]interface{}{
"id": id,
"name": "John Doe",
"age": 30,
}, nil
}
return nil, nil
},
},
},
})
```
在此代码段中,`Query`类型定义了一个`person`字段,它接受一个`id`参数,并通过`Resolve`函数返回一个`Person`类型的实例。`Resolve`函数是解析器的核心,负责实际的数据检索逻辑。
## 3.3 编写GraphQL解析器(Resolvers)
解析器(Resolvers)是GraphQL中的一个核心概念。它负责执行查询并返回数据。
### 3.3.1 理解解析器的作用
解析器的作用是根据请求的查询和模式(Schema)来构建最终的数据。解析器接收查询、模式中的字段定义以及字段的参数,然后返回与该字段相关联的数据。
### 3.3.2 创建基本的解析器函数
```go
func resolvePerson(p graphql.ResolveParams) (interface{}, error) {
// 假设这里从数据库获取数据
// 为了示例,这里返回一个静态的对象
return map[string]interface{}{
"id": 1,
"name": "Alice",
"age": 25,
}, nil
}
```
在上述代码中,`resolvePerson`函数是一个简单的解析器,它返回一个静态的`Person`对象。在实际的应用中,这里的逻辑应该涉及与数据库的交互以获取动态数据。
### 实现解析器映射
```go
var RootQuery = graphql.ObjectConfig{
Name: "RootQuery",
Fields: graphql.Fields{
"person": &graphql.Field{
Type: PersonType,
Args: graphql.FieldConfigArgument{
"id": &graphql.ArgumentConfig{Type: graphql.Int},
},
Resolve: resolvePerson,
},
},
}
```
在这个映射中,我们定义了`RootQuery`对象,它指定了一个`person`字段。解析器函数`resolvePerson`被关联到这个字段,当查询`person`字段时,就会调用`resolvePerson`函数来获取数据。
通过上述步骤,我们就可以构建一个基本的GraphQL服务。在实际开发中,还需要考虑安全性、性能优化、错误处理等多个方面。在接下来的章节中,我们将深入探讨如何实现复杂查询和变更、优化和测试GraphQL服务。
# 4. 实现复杂查询和变更
## 4.1 构建分页和过滤机制
### 4.1.1 使用connections进行分页
在构建一个具有高性能的GraphQL服务时,分页是一种常见且至关重要的功能。它可以帮助客户端有效地浏览大量数据,而不会因为一次性加载过多数据而导致性能下降。在GraphQL中,我们可以使用连接(connections)模式来实现分页,这是一种类似于GitHub GraphQL API所使用的方法。
连接模式通过定义`PageInfo`类型来提供信息,包括是否有更多的页面,以及如何获取前一页或下一页的数据。`edges`字段包含了节点(node)数据和游标(cursor),后者是一个用于定位特定数据项的唯一标识符。
以下是连接模式的基本示例代码:
```go
type Edge struct {
Cursor string
Node interface{}
}
type PageInfo struct {
HasNextPage bool
HasPreviousPage bool
StartCursor *string
EndCursor *string
}
type Connection struct {
Edges []*Edge
Nodes []interface{}
PageInfo PageInfo
}
```
在解析器(resolvers)中,我们需要实现相应的逻辑来生成带有分页的连接。例如,获取用户列表时,我们可以根据游标来决定哪部分数据应该被包含在当前页面。
### 4.1.2 实现过滤和排序功能
除了分页之外,为了提高数据查询的灵活性,我们还需要提供过滤(filtering)和排序(sorting)功能。在GraphQL模式中,我们可以为每个类型定义自定义字段来处理这些操作。
过滤功能允许客户端指定特定条件来筛选结果。例如,我们可以允许用户按创建时间、状态或其他属性过滤用户数据。这通常通过在查询中添加输入类型来实现,输入类型允许传递多个过滤参数。
排序功能则通过定义排序规则来实现,允许客户端指定返回结果的顺序,如升序或降序。
```graphql
type Query {
users(
filter: UserFilterInput
sortBy: UserSortBy
order: SortOrder
): Connection
}
input UserFilterInput {
name: String
status: UserStatus
}
enum SortOrder {
ASC
DESC
}
enum UserSortBy {
createdAt
updatedAt
}
```
在解析器中,我们需要根据这些输入字段来过滤和排序数据库查询结果。
## 4.2 事务处理与变更管理
### 4.2.1 事务的开始和提交
在GraphQL服务中,变更操作(如创建、更新、删除)通常需要在数据库事务中执行。事务保证了操作的原子性,确保了要么所有的变更都成功应用,要么在出现错误时全部回滚。
在Go中,我们可以使用数据库的事务API来开始和提交事务。例如,使用`sql.DB`的`Begin`方法来开始事务,并通过`Commit`方法来提交事务。以下是一个简单的示例:
```go
func createUser(db *sql.DB, name string) (int, error) {
tx, err := db.Begin()
if err != nil {
return 0, err
}
var id int
rows, err := tx.Query("INSERT INTO users (name) VALUES ($1) RETURNING id", name)
if err != nil {
tx.Rollback()
return 0, err
}
defer rows.Close()
if rows.Next() {
err = rows.Scan(&id)
if err != nil {
tx.Rollback()
return 0, err
}
}
err = ***mit()
if err != nil {
return 0, err
}
return id, nil
}
```
在GraphQL解析器中,我们需要调用这样的函数来处理创建用户的请求,并确保在操作成功时提交事务,在操作失败时回滚事务。
### 4.2.2 处理变更中的错误和冲突
在事务中处理错误和冲突是变更管理的一个重要方面。错误处理确保了在遇到问题时能够给客户端返回准确的错误信息,而冲突检测则确保了并发操作不会导致数据不一致。
错误处理可以通过在事务执行过程中添加适当的错误检查来实现。如果遇到错误,我们需要回滚事务,并将错误返回给客户端。
冲突检测通常需要根据业务场景来设计。例如,假设我们有一个用户邮箱地址的唯一性约束,我们可以先查询邮箱是否存在,如果存在,则不允许创建新的用户记录。冲突检测可能涉及到版本控制或乐观锁机制。
在GraphQL中,我们可以使用`ErrorType`来表示不同类型的错误。客户端可以根据这些错误类型来采取相应的行动。
## 4.3 使用中间件扩展功能
### 4.3.1 中间件的作用和设计模式
在构建复杂的服务时,中间件是一种有效的抽象方式,它允许我们在请求处理的生命周期中执行一些通用功能,例如日志记录、身份验证、权限检查等。
中间件可以被设计成拦截器(interceptors)的形式,它们可以访问请求和响应上下文,并可以修改这些上下文。在Go中,我们可以使用拦截器模式或装饰器模式来实现中间件功能。
一个中间件通常执行以下步骤:
1. 执行某些预处理操作。
2. 决定是否调用链中的下一个中间件或解析器。
3. 执行某些后处理操作。
### 4.3.2 实现日志记录和性能监控
日志记录和性能监控是服务中不可或缺的部分,它们可以帮助我们了解服务的运行状态,以及在出现问题时快速定位问题。
对于日志记录中间件,我们可以记录请求的类型、参数、开始时间和结束时间,以及任何在处理请求过程中发生的错误。通过中间件模式,我们可以将日志记录逻辑应用于所有的请求。
性能监控中间件则可以用来测量处理请求的时间。我们可以在中间件中记录时间戳,并计算执行解析器所需的时间,然后输出这些性能数据。
这里展示一个简单的日志记录中间件示例:
```go
func LoggingMiddleware(next resolver.ResolveFn) resolver.ResolveFn {
return func(ctx context.Context, obj interface{}, args map[string]interface{}, info *graphql.Field) (result interface{}, err error) {
start := time.Now()
result, err = next(ctx, obj, args, info)
log.Printf("Request handled in %v, error: %v", time.Since(start), err)
return
}
}
```
在服务启动时,我们可以将这个中间件应用于所有的解析器函数。这样,每个请求都会被日志记录中间件处理,而无需修改现有的业务逻辑代码。
通过上述方法,我们可以为GraphQL服务添加强大的中间件功能,提高其可维护性和性能。
# 5. 优化和测试GraphQL服务
当我们构建完GraphQL服务之后,我们需要确保它能够高效稳定地运行。在本章节中,我们将深入探讨如何对GraphQL服务进行性能优化,并进行详尽的测试来保证服务质量。
## 5.1 性能优化策略
性能优化是任何服务成功的关键,GraphQL服务也不例外。我们可以通过多种手段来提高GraphQL服务的性能。
### 5.1.1 缓存机制的实现
缓存是提升性能最直接的手段之一。在GraphQL中,我们可以利用缓存来避免重复的数据库查询和计算。对于经常请求的数据,我们可以将其保存在内存中以快速响应未来的查询。
```go
// 示例:使用Go的cache包来实现简单的缓存机制
package main
import (
"fmt"
"time"
"***/patrickmn/go-cache"
)
func main() {
c := cache.New(5*time.Minute, 10*time.Minute) // 创建一个缓存实例,有效期5分钟,清除间隔10分钟
// 模拟一个函数,该函数查询数据库获取数据
expensiveQuery := func(key string) (interface{}, error) {
// 模拟数据库查询操作
return "result for " + key, nil
}
// 获取数据,如果缓存中没有,则执行查询函数,并将结果存入缓存
value, err := c.GetWithExpiration("key", expensiveQuery, "key")
if err != nil {
fmt.Println(err)
} else {
fmt.Println(value)
}
// 此处可进行其他操作,例如解析和处理GraphQL请求...
// 获取数据,如果还在缓存有效期内,将直接从缓存中返回
value, err = c.Get("key")
if err != nil {
fmt.Println(err)
} else {
fmt.Println(value)
}
}
```
### 5.1.2 优化解析器的执行效率
GraphQL解析器是服务的核心,其执行效率直接影响到整个服务的性能。为了优化解析器,我们需要减少不必要的工作、使用并发处理、避免阻塞操作等。
```go
// 示例:并发处理多个解析器任务
package main
import (
"sync"
"fmt"
)
func resolver1() int {
// 模拟解析器1的工作
return 1
}
func resolver2() int {
// 模拟解析器2的工作
return 2
}
func main() {
var wg sync.WaitGroup
// 启动并发处理
wg.Add(2)
go func() {
defer wg.Done()
fmt.Println(resolver1())
}()
go func() {
defer wg.Done()
fmt.Println(resolver2())
}()
wg.Wait()
}
```
## 5.2 GraphQL服务测试
为了确保GraphQL服务的可靠性和正确性,测试是一个不可或缺的环节。测试不仅可以帮助我们发现错误,还能帮助我们验证业务逻辑。
### 5.2.1 编写单元测试和集成测试
单元测试关注单个函数或组件的行为,而集成测试则是测试多个组件协同工作时的整体表现。
```go
// 示例:测试GraphQL解析器函数
package main
import (
"testing"
"***/graphql-go/graphql"
)
func TestResolver(t *testing.T) {
resolver := graphql.Field{
Type: graphql.String,
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
// 模拟解析器逻辑
return "Resolver Result", nil
},
}
// 这里可以添加具体的测试逻辑,验证解析器的返回结果是否正确
// ...
}
```
### 5.2.2 使用模拟和测试框架进行测试
模拟(Mocking)可以让我们在不依赖外部服务(如数据库)的情况下测试代码。Go语言中有多种库可以实现模拟,如`testify`。
```go
// 示例:使用Go的testify库进行模拟测试
package main
import (
"***/stretchr/testify/mock"
"***/stretchr/testify/assert"
)
type MockResolver struct {
mock.Mock
}
func (m *MockResolver) Resolve(p graphql.ResolveParams) (interface{}, error) {
// 调用模拟方法
args := m.Called(p)
return args.Get(0), args.Error(1)
}
func TestMockResolver(t *testing.T) {
mockResolver := new(MockResolver)
mockResolver.On("Resolve").Return("Mocked Result", nil)
// 验证模拟方法是否被调用
result, _ := mockResolver.Resolve(mock.Anything)
assert.Equal(t, "Mocked Result", result)
}
```
在本章节中,我们学习了如何对GraphQL服务进行性能优化,包括缓存机制和解析器执行效率的优化。同时,我们还了解了如何编写单元测试和集成测试,并利用模拟和测试框架进行有效的测试工作。通过这些方法,我们能够确保GraphQL服务的高质量和高效能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Java消息服务(JMS)深入解析:构建稳定消息系统的必备知识
# 1. Java消息服务(JMS)概述
Java消息服务(JMS)是Java平台中的一种消息传递标准,它允许应用程序创建、发送、接收和读取消息。JMS定义了一套通用的API,使得不同厂商的消息中间件能够在Java应用程序之间提供互操作性。JMS为消息驱动的应用程序提供了两种基本的消息传递模式:点对点(P2P)和发布/订阅(Pub/Sub)。JMS不仅促进了消息的异步处理,还提高了应用程序的可靠性和可伸缩性。通过JMS,应用程序
大数据环境下的JSON-B性能评估:优化策略与案例分析

# 1. JSON-B简介与大数据背景
## JSON-B简介
JavaScript Object Notation Binary (JSON-B) 是一种基于 JSON 的二进制序列化规范,它旨在解决 JSON 在大数据场景下存在的性能和效率问题。与传统文本格式 JSON 相比,JSON-B 通过二进制编码大幅提高了数据传输和存储的效率。
【日志保留策略制定】:有效留存日志的黄金法则

# 1. 日志保留策略制定的重要性
在当今数字化时代,日志保留策略对于维护信息安全、遵守合规性要求以及系统监控具有不可或缺的作用。企业的各种操作活动都会产生日志数据,而对这些数据的管理和分析可以帮助企业快速响应安全事件、有效进行问题追踪和性能优化。然而,随着数据量的激增,如何制定合理且高效的数据保留政策,成为了一个亟待解决的挑战。
本章将探讨制定日志保留策略的重要性,解释为什么正确的保
微服务架构中的***配置管理:服务发现与配置中心实战
# 1. 微服务架构的基本概念和挑战
微服务架构作为现代软件开发和部署的一种流行模式,它将一个大型复杂的应用分解成一组小服务,每个服务运行在其独立的进程中,服务间通过轻量级的通信机制进行交互。这种模式提高了应用的模块性,使得各个服务可以独立开发、部署和扩展。然而,在实践中微服务架构也带来了诸多挑战,包括但不限于服务治理、数据一致性、服
【Go API设计蓝图】:构建RESTful和GraphQL API的最佳实践

# 1. Go语言与API设计概述
## 1.1 Go语言特性与API设计的联系
Go语言以其简洁、高效、并发处理能力强而闻名,成为构建API服务的理想选择。它能够以较少的代码实现高性能的网络服务,并且提供了强大的标准库支持。这为开发RESTful和GraphQL API提供了坚实的基础。
## 1.2 API设计的重要性
应用程序接口(AP
std::deque自定义比较器:深度探索与排序规则

# 1. std::deque容器概述与标准比较器
在C++标准模板库(STL)中,`std::deque`是一个双端队列容器,它允许在容器的前端和后端进行快速的插入和删除操作,而不影响容器内其他元素的位置。这种容器在处理动态增长和缩减的序列时非常有用,尤其是当需要频繁地在序列两端添加或移除元素时。
`std::deque`的基本操作包括插入、删除、访问元素等,它的内部实现通常采用一段连续的内存块,通
C++ std::array与STL容器混用:数据结构设计高级策略
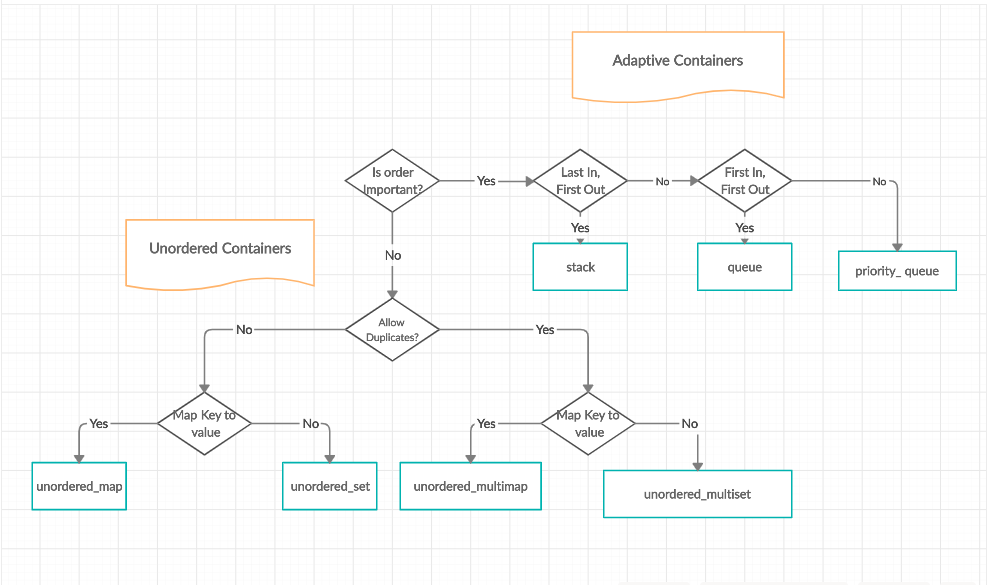
# 1. C++数据结构设计概述
C++语言凭借其丰富的特性和高性能,成为开发复杂系统和高效应用程序的首选。在C++中,数据结构的设计是构建高效程序的基石。本章将简要介绍C++中数据结构设计的重要性以及其背后的基本原理。
## 1.1 数据结构设计的重要性
数据结构是计算机存储、组织数
深入理解C#验证机制:创建自定义验证属性的终极指南
# 1. C#验证机制概述
## 1.1 验证机制的重要性
在构建健壮的应用程序时,验证用户输入是一个不可或缺的环节。C#作为一种现代编程语言,提供了丰富的验证机制来确保数据的准确性和安全性。无论是在Web开发、桌面应用还是服务端程序中,确保数据的有效性和完整性都是防止错误和提高用户体验的关键。
## 1.2 C#中的验证机制
C#中验证机制的主要构成是数据注解和验证属性。通过在数据模型上应用标准或自定义的验证属性,开发者可以定义输入规则,并在运行时进行验证。数据注解通过在实体类的属性上使用特性(Attribute),在不需要编写大量验证逻辑代码的情况下,轻松实现复杂的验证规则。
##
【C++并发编程】:std::unordered_map线程安全的正确操作
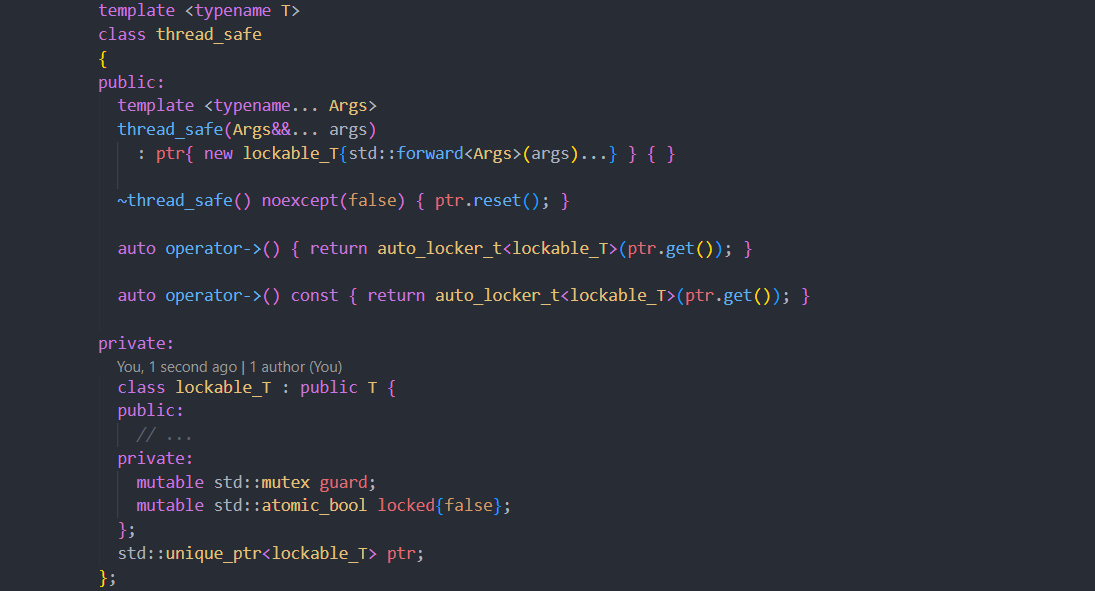
# 1. 并发编程与线程安全基础
在现代软件开发中,随着多核处理器的普及,应用程序往往需要并发执行多个任务以提高效率。并发编程涉及多个线程或进程同时执行,它们可能需要共享资源,这就涉及到线程安全的问题。线程安全是指当多个线程访问一个对象时,该对象的状态仍然可以保持一致的特性。
理解并发编程的基础概念是至关重要的,包括线程、进程、同步、死锁、竞态条件等。在实际
【Go并发分布式计算】:Fan-out_Fan-in模式在分布式任务中的关键作用
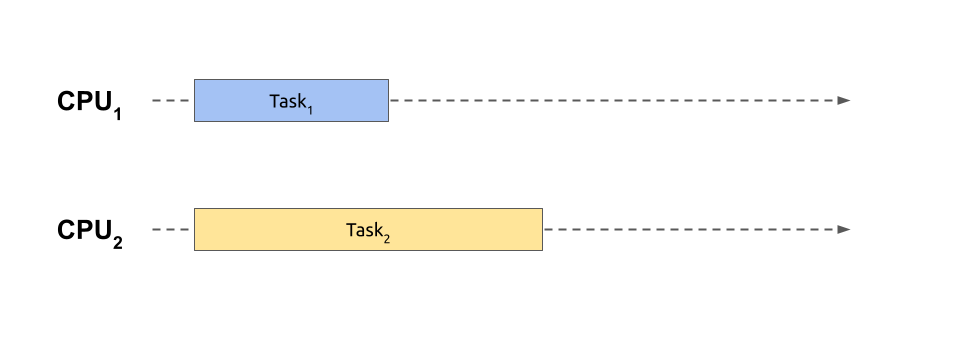
# 1. Go并发分布式计算概述
在当今IT行业中,大规模数据处理和实时计算需求日益增长,Go语言以其原生支持并发的特性脱颖而出,成为构建高性能分布式系统的理想选择。本章将简要介绍Go语言在并发和分布式计算方面的一些基础概念和优势。
Go语言通过其创新的并发模型,使得开发者能够轻松地编写出高效且易于理解的并发程序。语言内置的轻量级线程——Goroutine,和通信机制——Chann
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )