可扩展性与架构设计实践指南
发布时间: 2024-02-13 08:38:27 阅读量: 45 订阅数: 26 

构建未来就绪的数据库架构:可扩展性设计指南
# 1. 理解可扩展性的重要性
在软件开发中,可扩展性是一项至关重要的特性,它不仅决定了一个系统是否能够适应未来的业务发展,还直接影响着系统的性能和用户体验。本章将深入探讨可扩展性的重要性,以及具有良好可扩展性的系统对业务发展的积极影响。
## 1.1 可扩展性在软件开发中的意义
可扩展性是指系统在面对不断变化的需求时,能够通过简单的方式进行扩展和修改,而不会对现有系统造成影响。在软件开发中,需求的变化是不可避免的,一个具有良好可扩展性的系统能够快速响应并适应这些变化,从而保持系统的健壮性和灵活性。
## 1.2 可扩展性对系统性能和用户体验的影响
系统的可扩展性直接影响着系统的性能和用户体验。当系统的可扩展性较差时,随着业务规模的增长,系统往往会出现性能下降、响应缓慢甚至崩溃的情况,给用户带来极大的困扰。而具有良好可扩展性的系统能够更好地应对大流量、高并发等挑战,保持系统稳定性并提供良好的用户体验。
## 1.3 成功案例分析:具有良好可扩展性的系统对业务发展的影响
通过分析一些具有良好可扩展性的系统,可以发现它们往往能够更好地支撑业务的快速发展。例如,一些知名的互联网企业在面对用户爆发式增长时,由于其系统具有良好的可扩展性,能够较快地进行水平扩展,保持系统稳定并满足用户需求,从而取得了长足的发展。
在第一章中,我们从多个角度探讨了可扩展性的重要性,在接下来的章节中,我们将深入探讨可扩展性的架构设计原则与实践,以及在实际项目中应该如何进行可扩展性的考量与抉择。
# 2. 架构设计原则与实践
在软件开发过程中,架构设计是确保系统具备良好可扩展性的关键因素之一。下面将介绍一些常用的架构设计原则与实践,帮助开发者更好地实现可扩展的系统架构。
### 2.1 设计原则:松耦合与高内聚
松耦合和高内聚是架构设计中最基本的原则之一。松耦合指的是模块之间的依赖关系尽量减少,模块之间的解耦度高,各个模块可以独立演化和维护。高内聚是指模块内部的代码功能相关且紧密,一个模块应该有一个明确的职责。
如何实现松耦合和高内聚呢?首先,可以通过使用接口来定义模块之间的依赖关系,而不是具体的实现类。这样,在模块的实现方面可以有更大的灵活度,可以随时替换实现。
示例代码(Java):
```java
// 定义接口
public interface UserService {
void addUser(User user);
void deleteUser(User user);
void updateUser(User user);
User getUserById(int id);
}
// 模块A依赖模块B
public class ModuleA {
private UserService userService;
// 通过构造函数注入依赖
public ModuleA(UserService userService) {
this.userService = userService;
}
// 使用userService进行操作
public void doSomething() {
// ...
userService.addUser(user);
// ...
}
}
```
上述示例中,模块A通过构造函数接收一个实现了`UserService`接口的依赖,而不是具体的实现类。这样就实现了模块A与具体实现的解耦,提高了系统的可扩展性。
### 2.2 架构设计思维导向:从单体到微服务
随着业务规模的扩大和功能的增加,原先的单体架构可能无法满足业务的需求。这时候,可以考虑将系统拆分成多个微服务,每个微服务负责独立的业务功能,通过网络调用进行通信。
微服务架构可以提供更好的可扩展性和部署灵活性。每个微服务可以独立运行、独立扩展和独立维护,便于团队的协作和敏捷开发。此外,微服务架构还可以通过使用轻量级的通信协议,提高系统的性能和可靠性。
示例代码(Python):
```python
# 微服务A
from flask import Flask, request
app = Flask(__name__)
@app.route('/user', methods=['POST'])
def add_user():
# 添加用户逻辑
return 'User added successfully'
@app.route('/user/<id>', methods=['DELETE'])
def delete_user(id):
# 删除用户逻辑
return 'User deleted successfully'
if __name__ == '__main__':
app.run()
# 微服务B
from flask import Flask, request
app = Flask(__name__)
@app.route('/order', methods=['POST'])
def add_order():
# 添加订单逻辑
return 'Order added successfully'
@app.route('/order/<id>', methods=['DELETE'])
def delete_order(id):
# 删除订单逻辑
return 'Order deleted successfully'
if __name__ == '__main__':
app.run()
```
上述示例中,通过使用Flask框架分别创建了两个微服务,一个负责用户相关的业务,一个负责订单相关的业务。每个微服务都有独立的路由和业务逻辑,可以独立运行和部署。
### 2.3 实践指南:选择适合业务需求的架构模式
在实际的架构设计过程中,根据业务需求选择合适的架构模式是至关重要的。不同的模式对可扩展性的影响不同,合理选择适合业务需求的模式可以最大程度地提升系统的可扩展性。
常见的架构模式包括分层架构、事件驱动架构、微服务架构等。具体的选择要根据具体的业务场景来决定,综合考虑业务需求、性能要求、团队技术栈等方面的因素。
示例代码(Java):
```java
// 分层架构示例
public class UserController {
private UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
public void addUser(User user) {
// 调用userService进行用户添加逻辑
userService.addUser(user);
}
// 其他Controller方法
}
public class UserService {
// 用户添加逻辑
public void addUser(User user) {
// ...
}
// 其他Service方法
}
// 事件驱动架构示例
public class EventListener {
public void onEvent(Event event) {
// 处理事件逻辑
}
// 其他监听方法
}
public class EventPublisher {
private List<EventListener> eventListeners;
public void addEventListener(EventListener eventListener) {
// 添加事件监听器
eventListeners.add(eventListener);
}
public void publishEvent(Event event) {
// 发布事件,触发监听器的处理方法
for (EventListener listener : eventListeners) {
l
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Next.js从入门到精通:构建企业级项目》是一本专注于使用Next.js框架构建企业级项目的专栏。从入门到精通,结合详细的教学和实践经验,该专栏将帮助读者掌握Next.js的基础概念与安装配置,深入理解页面路由与导航,以及样式管理与CSS-in-JS的应用。同时,还将通过对比分析服务端渲染与客户端渲染的优劣,讨论数据预取与缓存优化的技巧,探索国际化与本地化支持的实现方法。此外,专栏还涵盖了错误处理与调试技巧,自定义服务器配置与部署,可扩展性与架构设计实践指南,多页应用与单页应用的选择与对比,以及SEO优化与身份认证等实践经验。通过该专栏,读者将掌握Next.js的核心功能,并能够应用于构建稳健、高效的企业级项目。无论是开发者、设计师还是项目经理,都能从中获得大量的实用指导和经验总结。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CI_CD效率秘籍】:提升开发速度的8大策略与技巧
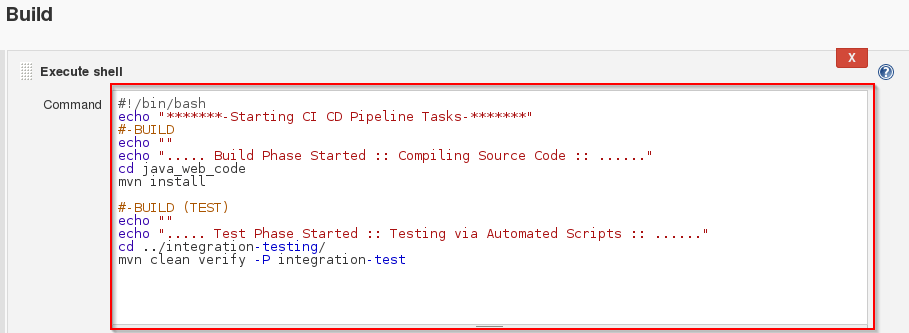
# 摘要
本文介绍了CI/CD(持续集成/持续部署)的理论基础及其在软件开发中的重要性,并探讨了优化CI/CD流程的有效策略。通过分析自动化测试、代码合并、构建监控和持续部署的实践案例,本文揭示了CI/CD工具的实际应用和高级技巧。文章还讨论了提升CI/CD性能与监控的关键技术,并着眼于云原生集
移动设备的内存革命:低功耗设计中的JESD209-5B应用
# 摘要
随着移动设备性能需求的不断提升,内存技术的发展和应用成为了推动移动设备性能进步的关键因素。本文首先概述了移动设备内存技术的背景及其低功耗设计的重要性,随后深入探讨了JESD209-5B标准的理论基础、核心特点及其在低功耗设计中的应用。接着,文章聚焦于JESD209-5B在移动设备中的实际应用,包括硬件设计、软件与固件优化,以及性能测试与分析。此外,本文还分析了JESD209-5B技术带来的创新点
从零开始:Xilinx FPGA上实现DisplayPort协议的全面指南
# 摘要
随着数字视频应用的不断增长,DisplayPort作为高速视频接口标准,在FPGA平台上的实现变得尤为重要。本文首先介绍了FPGA的基础知识及DisplayPort协议的概述,随后深入探讨了DisplayPort协议的核心概念与技术原理,包括协议标准、信号与接口技术
VisionPro实战指南:深度剖析10个行业案例与解决方案

# 摘要
VisionPro作为一种先进的机器视觉软件,已在多个行业中展现出其应用前景和实际价值。本文首先介绍了VisionPro的基本理论和工具,包括其软件
【电源芯片性能升级】:TPS74401关键参数全面解读

# 摘要
电源芯片TPS74401作为电源管理领域的重要组件,其性能直接关系到电子系统的稳定性和效率。本文首先概述了TPS74401的基本特性,并详细分析了其关键性能参数,包括电气特性、保护功能及稳定性与噪声表现。接着,重点介绍了TPS74401在创新设计方面的突破,涵盖了封装散热技术、电路设计创新和系统级优化。随后,通过多个应用案例分析,本文展示了TPS74401在不同领域的
单片机高级步进电机控制:效率与精度倍增的10大策略
# 摘要
步进电机作为执行元件在现代自动化控制系统中发挥着关键作用。本文系统地梳理了步进电机控制的基础知识,探讨了提升控制效率和精度的多种策略,包括选型与配置、控制算法优化、电源管理、位置反馈系统、误差补偿以及时序控制技术。文章还研究了多轴协
PyCAD图形与参数处理:数据结构与算法的精通之道
# 摘要
本文系统介绍了PyCAD软件在图形与参数处理方面的应用,重点阐述了PyCAD的数据结构和图形处理算法,以及参数化设计的理论和实践。首先概述了PyCAD处理基本图形数据结构的方法和参数化设计的数据结构,其次通过具体算法实践,展示了图形绘制、变换与处理的技术细节,以及图形分析与优化策略。之后深入探讨了参数化设计的理论基础和模型构建过程,并探讨了面向对象的参数化设计方法,以便于
【模拟电子电路分析】:MC1496调幅原理及Multisim10应用实战指南
# 摘要
本文详细介绍了MC1496调幅器的基本概念、工作原理以及在通信系统中的应用。首先概述了MC1496调幅器及其在模拟电子电路中的重要性,随后深入分析了其调幅技术的理论基础。文章还介绍了Multisim10仿真软件的基本操作和仿真分析方法,这些方法被应用于MC1496调幅电路的仿真测试和性能优化。最后,结合实际案例,探讨了MC1496调幅电路在通信系统中的应用及维护策略,旨在为电子工程师和通信技术人员提供实践指导。通过本文,读者将能够更好地理解和应用MC1496调幅器及其仿真测试,提高电路设计的可靠性和性能。
# 关键字
MC1496调幅器;模拟电子电路;Multisim10仿真;调幅
【操作系统设计:磁盘调度算法实战】:实验、测试与应用的全面指南

# 摘要
磁盘调度算法是操作系统中管理磁盘I/O请求的核心技术,对提高数据存取效率至关重要。本文首先概述了磁盘调度算法的基本概念与理论基
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )