自然语言处理技术在媒体大数据中的应用
发布时间: 2024-02-29 22:44:10 阅读量: 27 订阅数: 31 
# 1. 自然语言处理技术概述
## 1.1 自然语言处理技术的定义
自然语言处理(Natural Language Processing,NLP)是人工智能和语言学领域的交叉学科,旨在让计算机能够理解、解释、操纵人类语言。NLP技术致力于让计算机能够像人类一样处理自然语言,包括语音识别、语义理解、对话系统等方面。
NLP的目标是实现计算机对自然语言的深层理解,使得计算机能够像人类一样理解文本和语音输入,并以符合人类语言习惯的方式产生输出。NLP技术的发展对于媒体大数据的处理和分析至关重要。
## 1.2 自然语言处理技术的发展历程
自然语言处理技术源自于人工智能的发展,随着深度学习、大数据和计算力的提升,NLP技术取得了长足的发展。从早期的基于规则的语言处理系统,到如今基于大数据和深度学习的语言模型,NLP技术的发展经历了多个阶段,涌现出了许多重要技术和应用。
## 1.3 自然语言处理技术在媒体大数据中的重要性
在媒体大数据时代,海量的文本、语音和视频数据需要被高效地处理和分析。NLP技术能够帮助媒体行业实现信息的自动化提取、分类、推荐和情感分析,极大地提升了媒体大数据的价值和应用前景。从舆情分析到内容推荐,自然语言处理技术都发挥着不可替代的作用。
综上所述,自然语言处理技术作为媒体大数据处理的重要利器,将在媒体行业发挥越来越重要的作用。
# 2. 媒体大数据概述
在这一章节中,我们将深入探讨媒体大数据的定义、特点、来源、应用场景,以及该领域所面临的挑战和未来发展趋势。让我们一起来了解媒体大数据在当今信息时代的重要性和影响。
### 2.1 媒体大数据的定义和特点
媒体大数据是指在传统和数字媒体之间产生的大量数据,包括文字、图像、音频和视频等多媒体内容。这些数据在时间和空间上广泛分布,具有多样化、实时性和海量性的特点。媒体大数据的特点主要包括以下几个方面:
- **多样化**:媒体大数据来源丰富多样,包括新闻报道、社交媒体、博客文章、在线视频等多种形式的内容。
- **实时性**:媒体内容不断更新,数据产生和传播的速度非常快,需要即时处理和分析。
- **海量性**:媒体数据量庞大,需要借助大数据技术进行存储、处理和分析。
### 2.2 媒体大数据的来源和应用场景
媒体大数据的主要来源包括新闻机构、社交媒体平台、在线视频网站、博客和论坛等。这些数据可以用于很多领域,如舆情监控、媒体内容分析、用户行为分析等,具体应用场景包括但不限于以下几个方面:
- **舆情监控**:通过分析媒体大数据,了解公众对特定事件、产品或服务的看法和态度,做出相应的决策。
- **媒体内容分析**:对新闻报道、文章、视频等媒体内容进行分析,挖掘其中的信息和价值,为媒体编辑和生产提供参考。
- **用户行为分析**:通过媒体数据分析用户在不同平台上的行为和偏好,实现个性化推荐和精准营销。
### 2.3 媒体大数据面临的挑战和发展趋势
尽管媒体大数据在各个领域有着广泛的应用,但也面临诸多挑战,包括数据质量、隐私保护、信息安全等方面。未来,随着人工智能和大数据技术的不断发展,媒体大数据的应用前景仍然广阔,值得我们深入探讨和研究。
# 3. 自然语言处理技术在媒体大数据分析中的基础应用
自然语言处理技术在媒体大数据分析中扮演着重要角色,帮助我们有效地处理和理解海量的文本数据。以下是自然语言处理技术在媒体大数据分析中的基础应用:
#### 3.1 文本挖掘和情感分析
文本挖掘(Text Mining)是自然语言处理技术中的一项重要任务,旨在从文本数据中提取有用的信息。情感分析(Sentiment Analysis)则是文本挖掘的一个应用,用于判断文本中所表达的情感倾向,例如积极、消极或中性情感。
下面是一个简单的Python示例,演示如何使用自然语言处理工具NLTK进行情感分析:
```python
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
sia = SentimentIntensityAnalyzer()
def analyze_sentiment(text):
sentiment_score = sia.polarity_scores(text)
return sentiment_score
text = "I love this product, it's fantastic!"
sentiment = analyze_sentiment(text)
print(sentiment)
```
**代码解析:**
- 我们首先导入nltk库,并从中导入SentimentIntensityAnalyzer。
- 使用情感分析器对文本进行情感分析,返回情感得分。
- 输出情感分数,包括积极、消极、中性和复合得分。
**结果说明:**
该代码会输出对文本"I love this product, it's fantastic!"的情感分析结果,包括积极、消极、中性和复合得分。
#### 3.2 文本分类和主题建模
文本分类(Text Classification)是将文本分配到预定义的类别或标签中的任务。主题建模(Topic Modeling)则是一种统计建模方法,用于发现文本集合中隐藏的主题结构。
下面是一个简单的Python示例,展示如何使用gensim库进行主题建模:
```python
from gensim import corpora, models
from pprint import pprint
documents = ["Human machine interface for lab abc computer application
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
【MySQL大数据集成:融入大数据生态】
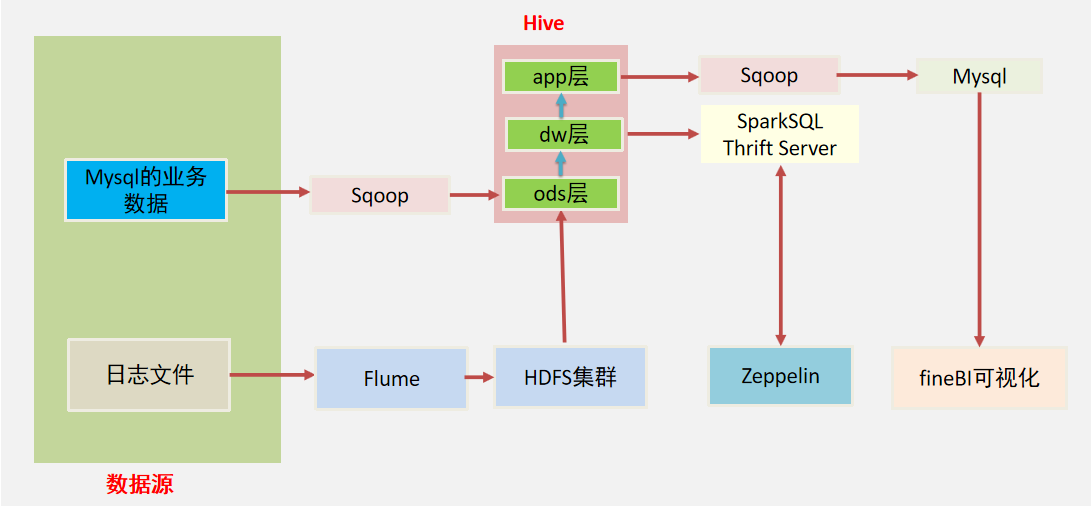
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
【数据分片技术】:实现在线音乐系统数据库的负载均衡
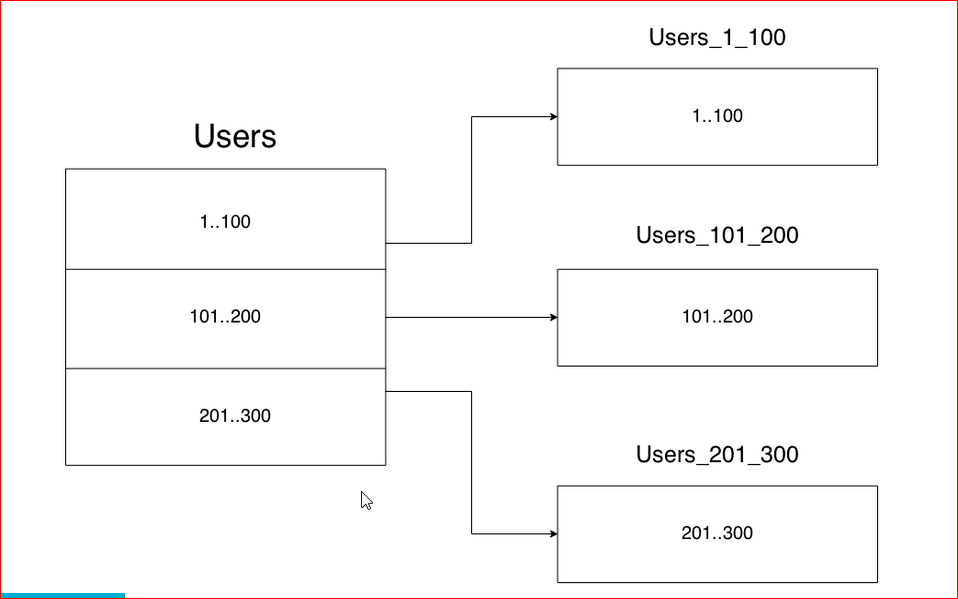
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
【面向对象编程:终极指南】:破解编程的神秘面纱,掌握23种设计模式及实践案例
# 1. 面向对象编程基础
## 1.1 面向对象编程简介
面向对象编程(Object-Oriented Programming,简称OOP)是一种通过对象来组织程序的编程范式。它强调将数据和操作数据的行为封装在一起,构成对象,以实现程序的模块化和信息隐藏。面向对象的四大基本特性包括:封装、继承、多态和抽象。
## 1.2 OOP基本
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )