【Python filters库并发处理】:多线程_多进程环境下的应用策略
发布时间: 2024-10-15 17:51:13 阅读量: 24 订阅数: 18 

# 1. Python filters库概述
## 简介Python filters库
Python Filters库是一个用于构建复杂的迭代处理管道的库。它可以用于数据处理、文件操作、网络请求等众多场景。filters库允许开发者将一系列的处理步骤链接在一起,形成一个数据处理流水线,使得代码更加清晰和易于维护。
## filters库的设计和功能
Filters库的设计理念是使得数据的处理过程能够被分解为多个独立的步骤,每个步骤都可以单独进行优化和调整。它提供了多种内置的过滤器,如映射(map)、过滤(filter)、排序(sort)等,并且支持自定义过滤器,以便开发者可以轻松地扩展其功能以适应特定的需求。Filters库通过链式调用和延迟计算,优化了数据处理的性能,特别适合于处理大规模数据集。
# 2. 并发编程基础
## 2.1 线程与进程的概念
### 2.1.1 线程的基本原理
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。在多线程环境中,每个线程都共享其所属进程的内存空间和资源,但同时拥有自己的线程栈,用于管理函数调用和局部变量。
线程之间的切换比进程之间要快得多,因为线程共享了进程的大部分资源,仅需要切换线程上下文(即线程栈和寄存器状态)。这使得多线程编程在需要频繁进行任务切换的应用中显得尤为重要,例如图形用户界面(GUI)和网络服务器。
### 2.1.2 进程的基本原理
进程是程序的一次执行,是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间,系统资源(如CPU时间、内存等)是以进程为单位进行分配的。进程之间的通信主要通过进程间通信(IPC)机制实现,如管道、消息队列、共享内存、信号量等。
进程之间相互独立,一个进程崩溃不会影响其他进程,这使得进程结构具有更高的稳定性和安全性。但进程间通信的成本较高,因为需要频繁进行上下文切换和资源隔离。
## 2.2 并发编程模型
### 2.2.1 多线程模型
多线程模型是并发编程中的一种常见模型,它允许程序中存在多个线程,这些线程可以同时执行,从而提高程序的执行效率。在多线程模型中,线程是轻量级的,创建、销毁和切换开销相对较小。
### 2.2.2 多进程模型
多进程模型通过创建多个进程来实现并发,每个进程拥有独立的内存空间和资源。在多进程模型中,进程间通信较为复杂,需要使用特定的IPC机制。虽然进程间通信成本较高,但由于进程之间的独立性,它在安全性和稳定性方面表现更佳。
### 2.2.3 协程模型
协程模型是一种用户级的轻量级线程,也称为微线程或纤程。协程由程序员控制,在单线程内部实现任务切换,因此不需要操作系统进行上下文切换。协程之间的切换仅涉及到局部变量和栈的切换,开销极小。
协程模型适用于I/O密集型任务,如网络服务器,因为它可以有效避免I/O操作导致的线程阻塞问题。然而,协程不适用于CPU密集型任务,因为它依赖于单线程执行,无法利用多核处理器的优势。
```python
import asyncio
async def main():
# 异步执行的协程函数
print('Hello ')
await asyncio.sleep(1) # 模拟I/O操作
print('World!')
# 创建事件循环
loop = asyncio.get_event_loop()
# 运行主函数
loop.run_until_complete(main())
```
#### 代码逻辑解读分析
上述代码展示了Python中的协程模型的基本用法。`async def main():` 定义了一个协程函数,其中包含了两个打印操作和一个模拟I/O操作的`await asyncio.sleep(1)`。通过`asyncio.get_event_loop()`获取事件循环,`loop.run_until_complete(main())`运行主协程直到完成。
### 表格:线程、进程和协程模型对比
| 模型 | 描述 | 优势 | 劣势 |
| ---------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 多线程模型 | 操作系统级的并发单元,共享进程内存和资源 | 创建、销毁和切换开销小,适用于计算密集和I/O密集型任务 | 线程安全问题,需要额外的同步机制 |
| 多进程模型 | 独立的执行单元,拥有独立的内存和资源 | 高安全性和稳定性,适用于需要隔离的安全和稳定性关键任务 | 进程间通信成本高,创建和销毁开销大 |
| 协程模型 | 用户级轻量级线程,单线程内任务切换 | 开销极小,适用于I/O密集型任务 | 依赖于单线程执行,不适用于CPU密集型任务,需要特定的运行环境支持 |
#### 代码块:线程安全示例
```python
from threading import Thread, Lock
import time
counter = 0
lock = Lock()
def increment():
global counter
for _ in range(1000000):
lock.acquire()
counter += 1
lock.release()
threads = [Thread(target=increment) for _ in range(10)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print("Counter value:", counter)
```
#### 代码逻辑解读分析
上述代码演示了如何使用线程锁(`threading.Lock`)来保证线程安全。`increment`函数模拟了一个增加计数器的操作,通过`lock.acquire()`和`lock.release()`确保同一时间只有一个线程能够修改`counter`变量。`lock`对象保证了每次只有一个线程可以执行加法操作,从而避免了多线程导致的竞态条件。
#### 流程图:多线程执行流程
```mermaid
graph TD;
A[Start] --> B[Create Thread 1]
A --> C[Create Thread 2]
B --> D[Acquire Lock]
C --> E[Acquire Lock]
D --> F[Increment Counter]
E --> F
F --> G[Release Lock]
G --> H[Join Thread]
H --> I[End]
```
通过本章节的介绍,我们了解了并发编程的基础知识,包括线程与进程的概念、并发编程模型以及线程安全的重要性。在本章节中,我们探讨了不同并发模型的原理和特点,并通过代码示例和图表的形式加深了对这些概念的理解。本文的下一章节将继续深入探讨Python filters库在并发处理中的应用,包括在多线程和多进程环境中的具体实现。
# 3. Python filters库并发处理
在本章节中,我们将深入探讨Python filters库在并发编程中的应用,包括多线程和多进程环境下的使用,以及高级并发策略的实现。我们将通过代码示例、逻辑分析和性能优化建议,帮助你更好地理解和运用filters库。
## 3.1 filters库在多线程中的应用
### 3.1.1 创建线程安全的filters
在多线程环境中,数据安全和线程同步是至关重要的。Python filters库提供了一种机制,使得在多线程环境下创建线程安全的filters成为可能。
#### 线程安全的filter设计
线程安全的filter设计需要考虑数据的同步和隔离。我们可以使用锁(例如`threading.Lock`)来同步线程对共享资源的访问。以下是一个简单的示例代码:
```python
import threading
from filters import BaseFilter
class ThreadSafeFilter(BaseFilter):
def __init__(self):
super().__init__()
self.data = None
self.lock = threading.Lock()
def process(self, item):
with self.lock:
# 线程安全地处理数据
self.data = item
# 执行一些操作
return item
```
在这个例子中,`ThreadSafeFilter`类通过`threading.Lock`确保了`process`方法的线程安全。每次调用`process`方法时,都会使用`with self.lock:`语句块来锁定资源,防止其他线程同时访问共享资源。
### 3.1.2 线程间的数据共享和同步
在多线程程序中,线程间的数据共享和同步是常见的需求。我们可以使用`queue.Queue`来安全地在线程间传递数据。
#### 使用queue.Queue同步数据
`queue.Queue`是一个线程安全的队列实现,适用于生产者-消费者模式。以下是一个示例代码:
```python
import queue
import threading
def producer(q):
for i in range(5):
q.put(i)
print(f'Produced {i}')
def consumer(q):
while True:
item = q.get()
if item is None:
break
print(f'Consumed {item}')
q.task_done()
q = queue.Queue()
t1 = threading.Thread(target=producer, args=(q,))
t2 = threading.Thread(target=consumer, args=(q,))
t1.start()
t2.start()
t1.join()
q.join()
```
在这个例子中,`producer`函数生产数据并将其放入队列,而`consumer`函数从队列中取出数据并消费。`queue.Queue`确保了在多线程环境下的数据共享和同步。
## 3.2 filters库在多进程中的应用
### 3.2.1 创建进程安全的filters
多进程编程中,进程间的内存是隔离的,因此我们需要使用不同的机制来共享数据。Python的`multiprocessing`模块提供了多种方式来实现进程间通信。
#### 使用multiprocessing.Queue同步数据
`multiprocessing.Queue`是进程安全的队列,用于在多进程程序中传输数据。以下是一个示例代码:
```python
import multiprocessing
def producer(q):
for i in range(5):
q.put(i)
print(f'Produced {i}')
def consumer(q):
while True:
item = q.get()
if item is None:
break
print(f'Consumed {item}')
q.task_done()
if __name__ == '__main__':
q = multiprocessing.Queue()
p1 = multiprocessing.Process(target=producer, arg
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地介绍了 Python filters 库,从入门到高级技巧,涵盖了过滤器的使用、原理、应用、性能优化、安全防护、调试、集成、异常处理、源码剖析、并发处理、行业最佳实践、算法探索、代码复用、数据预处理和数据清洗等方方面面。通过循序渐进的讲解和丰富的案例分析,专栏旨在帮助读者掌握 filters 库的精髓,并将其应用于实际项目中,提升代码效率、数据质量和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
【MySQL大数据集成:融入大数据生态】
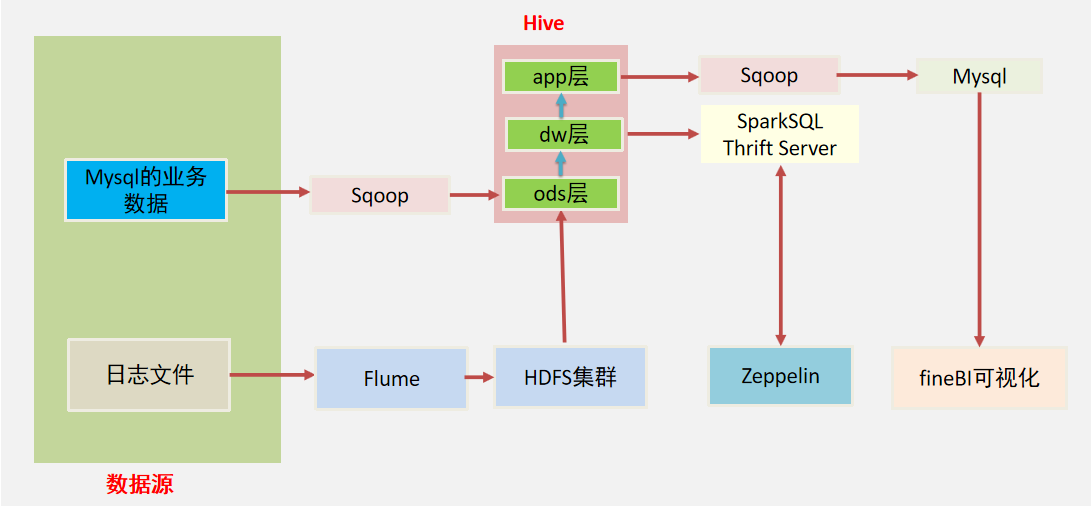
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
【数据分片技术】:实现在线音乐系统数据库的负载均衡
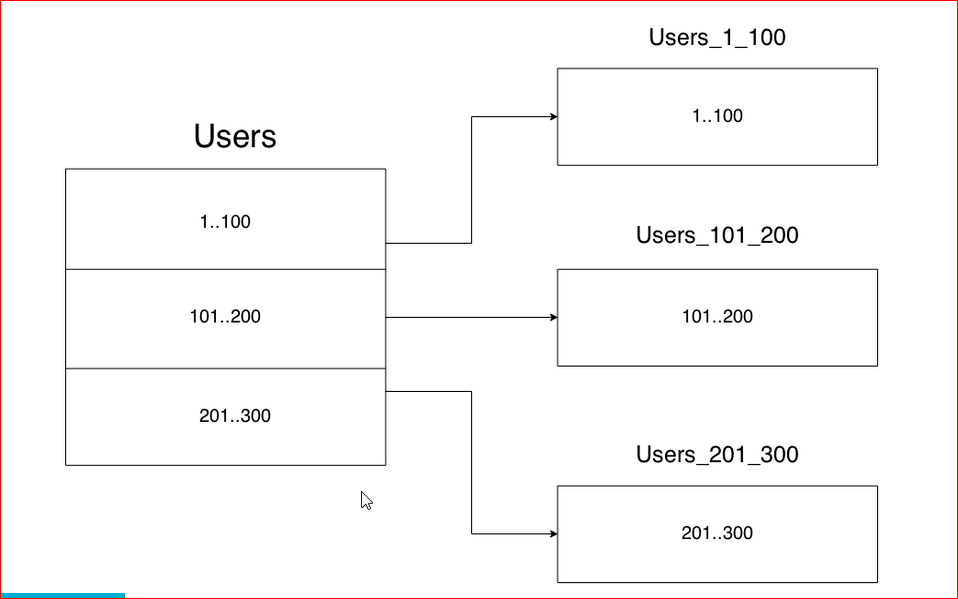
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
【面向对象编程:终极指南】:破解编程的神秘面纱,掌握23种设计模式及实践案例
# 1. 面向对象编程基础
## 1.1 面向对象编程简介
面向对象编程(Object-Oriented Programming,简称OOP)是一种通过对象来组织程序的编程范式。它强调将数据和操作数据的行为封装在一起,构成对象,以实现程序的模块化和信息隐藏。面向对象的四大基本特性包括:封装、继承、多态和抽象。
## 1.2 OOP基本
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )