金融行业的数据可视化魔法:市场洞察与决策支持指南
发布时间: 2024-09-07 23:55:21 阅读量: 46 订阅数: 33 

"Python数据分析与可视化实战指南:为数据科学家揭示商业洞察与决策支持"

# 1. 金融数据可视化的概念与重要性
金融数据可视化是将复杂的金融数据通过图形、图表、地图等形式直观展示,使得金融信息能迅速被理解和分析。本章将探讨金融数据可视化的基本概念,阐明其对金融行业决策者的重要性,并讨论它如何在分析金融市场、评估风险以及做出投资决策中发挥作用。
金融数据可视化不仅有助于决策者迅速识别市场趋势和模式,而且通过将数据“视觉化”,还可以揭示那些隐藏在海量数字和统计表格之中的关键信息。对于分析师和普通投资者而言,数据可视化使得金融信息更容易消化吸收,能够更加高效地做出数据驱动的决策。
可视化技术对于金融领域尤为重要,因为金融市场中的数据变动快速且复杂。在当前的金融环境中,信息就是力量。可视化技术能将数据转化为可操作的洞察,助力金融专业人士和机构在竞争激烈的市场中保持领先。
# 2. 金融数据的收集与预处理
### 2.1 数据收集策略与方法
#### 2.1.1 数据来源分析
在金融数据的收集阶段,了解数据来源对于确保数据的质量与适用性至关重要。金融数据来源多样,可以从公开和私有两种渠道获取。
公开数据源包括:
- 金融市场交易所发布的实时行情和历史数据。
- 中央银行和金融机构发布的宏观经济数据。
- 开放数据平台如Kaggle、Google Finance提供的各种金融数据集。
私有数据源涉及:
- 金融机构自有的交易记录和客户资料。
- 通过数据授权协议从第三方数据提供商获得的数据。
为高效收集数据,可采用自动化工具和API接口来获取和同步数据流。例如使用Python的`pandas-datareader`库来从多种金融市场的API中收集股票价格数据。
```python
import pandas_datareader as pdr
import datetime
# 设置查询的时间范围
start = datetime.datetime(2020, 1, 1)
end = datetime.datetime(2021, 1, 1)
# 从雅虎财经获取苹果公司股票的历史数据
data = pdr.get_data_yahoo('AAPL', start, end)
```
逻辑分析:`pandas-datareader`库在背后使用API接口从网上直接读取股票市场的数据,允许用户以极低的技术门槛快速收集数据。
参数说明:`'AAPL'`为苹果公司的股票代码,`start`和`end`定义了查询数据的时间范围。
#### 2.1.2 数据抓取工具与技术
金融数据收集还涉及到爬虫技术,即从互联网上自动获取信息。Python的`Scrapy`框架或`BeautifulSoup`库常用于此目的。爬虫技术能高效地从网站上提取出结构化或半结构化的数据。
```python
import requests
from bs4 import BeautifulSoup
url = '***'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 假设数据被包裹在表格中
financial_table = soup.find('table', {'class': 'financial_data'})
```
逻辑分析:上述代码首先发送HTTP请求获取网页内容,然后使用`BeautifulSoup`解析页面,以找到包含金融数据的表格。
参数说明:`'***'`是数据源网站的URL,`{'class': 'financial_data'}`是需要查询的表格的类属性。
### 2.2 数据清洗与预处理技术
#### 2.2.1 缺失值和异常值处理
金融数据集常含有缺失值和异常值,需要处理以确保数据的准确性。使用Python的数据处理库,如`pandas`,可以方便地处理缺失值。
```python
import pandas as pd
# 加载数据集
df = pd.read_csv('financial_data.csv')
# 查看数据集中的缺失值
print(df.isnull().sum())
# 使用均值填充缺失值
df.fillna(df.mean(), inplace=True)
```
逻辑分析:该段代码首先导入`pandas`库,并读取一个CSV格式的金融数据集。通过`isnull()`方法检测缺失值,并用`fillna()`方法用每列的平均值填充这些缺失值。
参数说明:`'financial_data.csv'`是包含金融数据的CSV文件,`df.mean()`计算的是每列数据的平均值。
#### 2.2.2 数据归一化与标准化
金融数据中的不同特征可能具有不同的量纲和数值范围,这会影响模型的性能。因此,进行数据归一化或标准化是必要的预处理步骤。
```python
from sklearn.preprocessing import MinMaxScaler
# 初始化标准化器
scaler = MinMaxScaler()
# 选择需要标准化的特征列
features = ['feature1', 'feature2', 'feature3']
df[features] = scaler.fit_transform(df[features])
```
逻辑分析:上述代码使用了`MinMaxScaler`,它将数据缩放到0和1之间,这是归一化的一种形式。适用于金融数据中许多算法,如K近邻(KNN)。
参数说明:`MinMaxScaler`负责数据的归一化处理,`features`列表包含了需要进行归一化的特征列。
#### 2.2.3 特征选择与提取
特征选择是机器学习中的关键步骤,它涉及到从大量特征中选取最能代表数据特征的子集。特征提取技术如主成分分析(PCA)可以降低数据的维度,减少计算量。
```python
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 标准化数据
X = df.drop('target_column', axis=1)
X_std = StandardScaler().fit_transform(X)
# 进行PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_std)
```
逻辑分析:该代码首先对除目标列外的所有数据进行标准化处理,然后应用PCA降维至2个主成分,以简化数据集的结构。
参数说明:`PCA(n_components=2)`指定了我们希望PCA提取的主成分数量为2个,这在可视化高维数据时非常有用。
### 2.3 数据仓库与大数据技术
#### 2.3.1 数据仓库的设计原理
数据仓库是用来存储整合历史和当前数据的存储系统,用于管理和报告分析。它按照主题、时间、源数据等维度组织数据,方便对数据进行深层次的查询和分析。
设计一个数据仓库时,需要考虑数据的集成、转换、装载(ETL)流程。这些流程确保数据准确无误地从各种源系统转移到数据仓库。
#### 2.3.2 大数据处理框架简介
大数据技术如Hadoop和Spark对处理大规模的金融数据集极为重要。它们可以分布式地存储和处理PB级别的数据集,极大地提高了处理速度和效率。
```python
from pyspark.sql import SparkSession
# 初始化Spark会话
spark = SparkSession.builder \
.appName("Financial Data Processing") \
.getOrCreate()
# 读取数据
df = spark.read.csv('financial_data.csv', header=True, inferSchema=True)
# 展示数据集的前20行
df.show(20)
```
逻辑分析:上述代码通过Spark的会话对象读取了CSV格式的金融数据,并将其转换成DataFrame,这是Spark用于数据处理的主要数据结构。
参数说明:`appName`定义了应用的名称,`read.csv`用于读取CSV格式的数据文件,`header=True`表示第一行为列名,`inferSchema=True`允许Spark自动推断数据类型。
通过本章节的介绍,我们深入理解了金融数据收集与预处理的不同技术和方法,以及它们在金融分析和数据可视化中的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了数据可视化技术,涵盖了从基础技巧到高级策略的各个方面。它提供了全面的指南,帮助读者理解数据可视化的基本原理,并掌握创建有效且引人入胜的图表和图形的技巧。专栏还提供了深入的案例研究,展示了数据可视化在不同行业中的实际应用,并比较了领先的数据可视化工具。此外,它还探讨了数据可视化项目管理的最佳实践,以及如何设计用户友好的界面和利用交互式元素来增强用户参与度。无论你是数据分析师、设计师还是希望改善数据呈现的专业人士,本专栏都提供了宝贵的见解和实用技巧,帮助你充分利用数据可视化的力量。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据链路层深度剖析:帧、错误检测与校正机制,一次学懂

# 摘要
数据链路层是计算机网络架构中的关键组成部分,负责在相邻节点间可靠地传输数据。本文首先概述了数据链路层的基本概念和帧结构,包括帧的定义、类型和封装过程。随后,文章详细探讨了数据链路层的错误检测机制,包括检错原理、循环冗余检验(CRC)、奇偶校验和校验和,以及它们在错误检测中的具体应用。接着,本文介绍了数据链路层的错误校正技术,如自动重传请求(ARQ
【数据完整性管理】:重庆邮电大学实验报告中的关键约束技巧
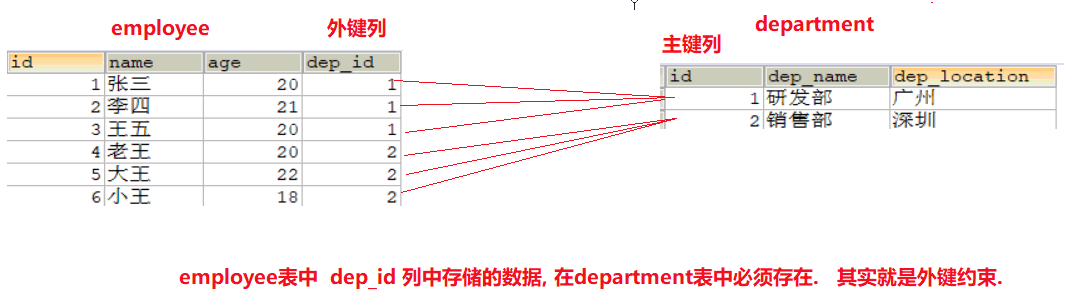
# 摘要
数据完整性是数据库管理系统中至关重要的概念,它确保数据的质量和一致性。本文首先介绍了数据完整性的概念、分类以及数据库约束的基本原理和类型。随后,文章深入探讨了数据完整性约束在实践中的具体应用,包括主键和外键约束的设置、域约束的管理和高级技巧如触发器和存储过程的运用。接着,本文分析了约束带来的性能影响,并提出了约束优化与维护的策略。最后,文章通过案例分析,对数据完整性管理进行了深度探讨,总结了实际操作中的
深入解析USB协议:VC++开发者必备的8个关键点
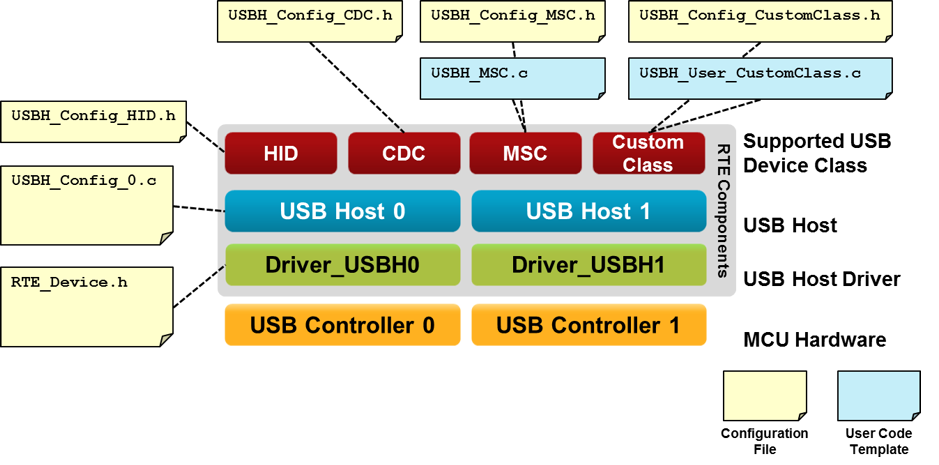
# 摘要
本文系统地介绍了USB协议的基础知识、硬件基础、数据传输机制、在VC++中的实现以及高级特性与编程技巧。首先概述USB协议的基础,然后详细探讨了USB硬件的物理接口、连接规范、电源管理和数据传输的机制。文章接着阐述了在VC++环境下USB驱动程序的开发和与USB设备通信的编程接口。此外,还涉及了USB设备的热插拔与枚举过程、性能优化,以及USB协议高级特性和编程技巧。最后,本文提供了USB设备的调试工具和方法,以
【科东纵密性能调优手册】:监控系统到极致优化的秘笈

# 摘要
性能调优是提高软件系统效率和响应速度的关键环节。本文首先介绍了性能调优的目的与意义,概述了其基本原则。随后,深入探讨了系统性能评估的方法论,包括基准测试、响应时间与吞吐量分析,以及性能监控工具的使用和系统资源的监控。在硬件优化策略方面,详细分析了CPU、内存和存储的优化方法。软件与服务优化章节涵盖了数据库、应用程序和网络性能调
【FPGA引脚规划】:ug475_7Series_Pkg_Pinout.pdf中的引脚分配最佳实践

# 摘要
本文全面探讨了FPGA引脚规划的关键理论与实践方法,旨在为工程师提供高效且可靠的引脚配置策略。首先介绍了FPGA引脚的基本物理特性及其对设计的影响,接着分析了设计时需考虑的关键因素,如信号完整性、热管理和功率分布。文章还详细解读了ug475_7S
BY8301-16P语音模块全面剖析:从硬件设计到应用场景的深度解读
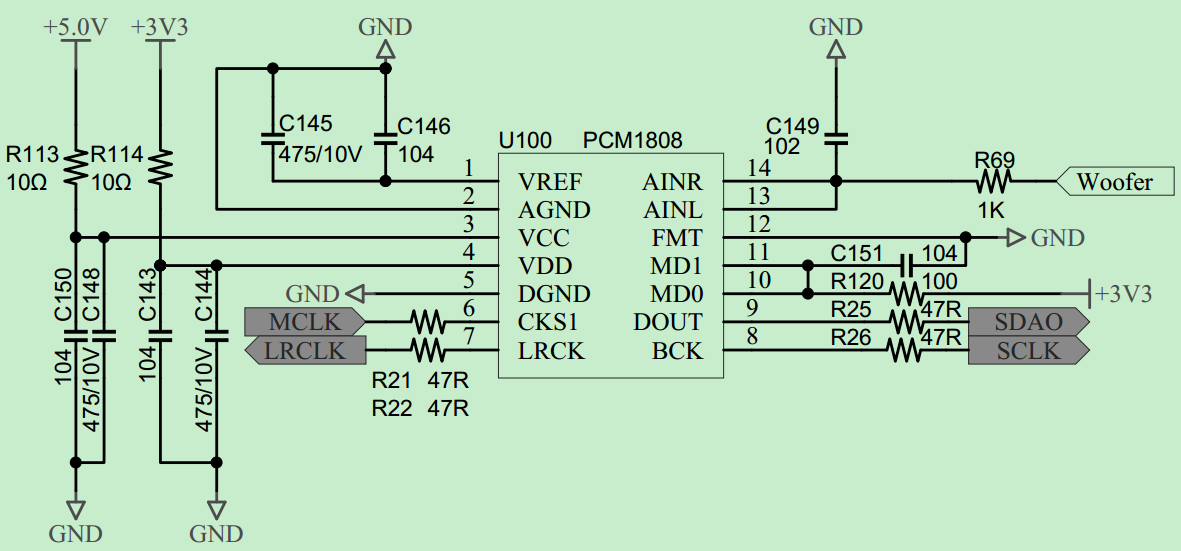
# 摘要
本文详细介绍了BY8301-16P语音模块的技术细节、硬件设计、软件架构及其应用场景。首先概述了该模块的基本功能和特点,然后深入解析其硬件设计,包括主控芯片、音频处理单元、硬件接口和电路设计的优化。接着,本文探讨了软件架构、编程接口以及高级编程技术,为开发者提供了编程环境搭建和
【Ansys命令流深度剖析】:从脚本到高级应用的无缝进阶
# 摘要
本文深入探讨了Ansys命令流的基础知识、结构和语法、实践应用、高级技巧以及案例分析与拓展应用。首先,介绍了Ansys命令流的基本构成,包括命令、参数、操作符和分隔符的使用。接着,分析了命令流的参数化、数组操作、嵌套命令流和循环控制,强调了它们在提高命令流灵活性和效率方面的作用。第三章探讨了命令流在材料属性定义、网格划分和结果后处理中的应用,展示了其在提高仿真精度和效率上的实际价值。第四章介绍了命令流的高级技巧,包括宏定义、用户自定义函数、错误处理与调试以及并行处理与性能优化。最后,第五章通过案例分析和扩展应用,展示了命令流在复杂结构模拟和多物理场耦合中的强大功能,并展望了其未来趋势
【Ubuntu USB转串口驱动安装】:新手到专家的10个实用技巧

# 摘要
本文详细介绍了在Ubuntu系统下安装和使用USB转串口驱动的方法。从基础介绍到高级应用,本文系统地探讨了USB转串口设备的种类、Ubuntu系统的兼容性检查、驱动的安装步骤及其验证、故障排查、性能优化、以及在嵌入式开发和远程管理中的实际应用场景。通过本指南,用户可以掌握USB转串口驱动的安装与管理,确保与各种USB转串口设备的顺畅连接和高效使用。同时,本文还提
RH850_U2A CAN Gateway高级应用速成:多协议转换与兼容性轻松掌握

# 摘要
本文全面概述了RH850_U2A CAN Gateway的技术特点,重点分析了其多协议转换功能的基础原理及其在实际操作中的应用。通过详细介绍协议转换机制、数据封装与解析技术,文章展示了如何在不同通信协议间高效转换数据包。同时,本文还探讨了RH850_U2A CAN Gateway在实际操作过程中的设备初始化、协议转换功能实现以及兼容性测试等关键环节。此外,文章还介
【FPGA温度监测:Xilinx XADC实际应用案例】

# 摘要
本文探讨了FPGA在温度监测中的应用,特别是Xilinx XADC(Xilinx Analog-to-Digital Converter)的核心
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )