【R语言进阶秘籍】:解锁数据包高级功能,自定义函数打造专属分析工具
发布时间: 2024-11-03 05:25:10 阅读量: 38 订阅数: 48 

踏上R语言之旅:解锁数据世界的神秘密码(二)数据案例表

# 1. R语言数据包的高级应用
在数据分析和统计建模领域,R语言以其强大的数据处理能力和灵活的函数库而闻名。本章旨在深入探讨R语言数据包的高级应用,从而帮助读者更高效地利用R语言进行复杂的数据分析任务。
## 1.1 数据包的基础使用
R语言拥有一个庞大的社区,不断地贡献着数以千计的包。在R中使用这些包首先需要了解它们的基本用法。例如,对于数据清洗和预处理,常用的包包括`dplyr`和`tidyr`。通过简单的命令,如`library(dplyr)`,你可以加载这个包,使其函数可用于当前的会话。
```r
# 加载dplyr包以进行数据操作
library(dplyr)
# 使用dplyr的管道操作符(|>)进行数据转换
data %>%
filter(column_name > value) %>%
select(-column_to_drop)
```
## 1.2 数据包的高级功能与最佳实践
当需要执行特定的任务,如时间序列分析时,`forecast`包能够提供强大的工具。最佳实践包括在项目的开始阶段就确定所需的包,并且编写可重用的函数来处理常见的数据处理任务。
```r
# 使用forecast包进行时间序列预测
library(forecast)
# 假设data是已经准备好的时间序列数据
ts_data <- ts(data)
model <- auto.arima(ts_data)
forecasted_values <- forecast(model, h=10)
```
通过本章的学习,我们将掌握R语言数据包的高级应用,使数据分析工作更加高效和精确。
# 2. 自定义函数的创建与优化
## 2.1 掌握R语言函数的基础
### 2.1.1 函数定义与参数传递
在R语言中,函数是一组执行特定任务的代码块,它们可以接受输入参数,执行处理,并返回输出结果。函数定义使用关键字`function`,并跟上括号内的参数列表和大括号内的代码块。以下是创建一个简单函数的示例:
```r
# 函数定义
add <- function(x, y) {
return(x + y)
}
```
在这个例子中,`add`函数接收两个参数`x`和`y`,将它们相加并返回结果。R语言支持多种参数类型,包括位置参数、命名参数、默认参数和可变参数。
#### 参数传递的细节
- **位置参数**:如上例所示,调用函数时参数的顺序必须与定义时保持一致。
- **命名参数**:在调用函数时可以指定参数名称,允许调用者不按顺序传递参数值。
- **默认参数**:在函数定义时可以为参数设置默认值,调用者可以不传递这些参数。
- **可变参数**:使用`...`语法可以接受不定数量的参数,这在创建可以接受任意数量输入的函数时非常有用。
### 2.1.2 函数作用域与环境
函数作用域定义了函数内部变量的可见性和生命周期。R语言遵循词法作用域规则,意味着函数中使用的变量查找将基于函数定义时的环境。
#### 作用域相关概念
- **局部变量**:在函数内部定义的变量只能在该函数内部访问。
- **全局变量**:在函数外部定义的变量可以在整个程序中访问,包括函数内部。
- **环境**:R中的环境是一个集合,它保存了变量名与变量值之间的绑定关系。每个函数都有自己的环境。
```r
# 局部变量示例
my_func <- function() {
local_var <- 10
return(local_var)
}
my_func() # 调用函数返回局部变量值
#> [1] 10
local_var # 尝试访问局部变量,会产生错误
#> Error in eval(expr, envir, enclos): object 'local_var' not found
```
在上面的代码块中,`local_var`是一个局部变量,它只在`my_func`函数内部有效。函数外部无法访问这个变量。
## 2.2 函数的高级特性
### 2.2.1 默认参数与可变参数
在编写函数时,为参数设置默认值可以简化函数的使用,并允许调用者只提供必须的参数。
#### 默认参数的使用
```r
# 带默认参数的函数定义
greet <- function(name = "Guest") {
cat("Hello", name, "!\n")
}
greet() # 使用默认参数调用
#> Hello Guest !
greet("Alice") # 提供参数值调用
#> Hello Alice !
```
在上面的示例中,`name`参数有一个默认值"Guest",如果调用时不提供`name`值,函数就会使用"Guest"。
#### 可变参数的使用
可变参数允许函数接受不定数量的参数。`...`符号用于定义可变参数。
```r
# 使用可变参数的函数
sum_args <- function(...) {
sum_args <- as.numeric(list(...))
return(sum(sum_args))
}
sum_args(1, 2, 3, 4) # 调用函数,返回所有参数的和
#> [1] 10
```
这个函数`sum_args`可以接受任意数量的数值参数,并计算它们的总和。
### 2.2.2 函数嵌套与闭包
函数嵌套指的是在函数内部定义另一个函数。R语言支持闭包,即外部函数可以返回内部函数,允许内部函数访问外部函数的局部变量。
#### 函数嵌套的示例
```r
# 函数嵌套与闭包
outer_func <- function(x) {
inner_func <- function() {
return(x)
}
return(inner_func)
}
outer <- outer_func(10) # 调用外部函数,返回内部函数
outer() # 调用内部函数,返回外部函数的参数值
#> [1] 10
```
在这个例子中,`outer_func`函数返回了内部函数`inner_func`。即使`outer_func`的执行已经结束,`inner_func`仍然可以访问变量`x`,这展示了闭包的特性。
## 2.3 函数性能优化策略
### 2.3.1 代码剖析与分析
代码剖析是评估和优化代码性能的重要步骤。在R中,可以使用`profvis`包进行代码的剖析。
#### 使用profvis进行代码剖析
```r
# 安装并加载profvis包
if (!requireNamespace("profvis", quietly = TRUE)) {
install.packages("profvis")
}
library(profvis)
# 定义被剖析的函数
profiling_function <- function(n) {
results <- c()
for (i in 1:n) {
results <- c(results, i)
}
return(results)
}
# 使用profvis进行代码剖析
profvis({
profiling_function(1000)
})
```
在上述代码块中,我们定义了一个简单的函数`profiling_function`,它计算从1到n的整数序列。然后,使用`profvis`函数对这段代码执行进行剖析,并输出剖析结果。
### 2.3.2 并行计算在函数中的应用
R语言支持并行计算,可以使用`parallel`包来实现。这在处理大量数据或复杂计算时可以显著减少执行时间。
#### 并行计算的示例
```r
# 安装并加载parallel包
if (!requireNamespace("parallel", quietly = TRUE)) {
install.packages("parallel")
}
library(parallel)
# 创建并行计算的函数
parallel_function <- function(data) {
cl <- makeCluster(detectCores()) # 创建并行集群
results <- parLapply(cl, data, function(x) {
x^2 # 对数据进行操作
})
stopCluster(cl) # 停止集群
return(unlist(results))
}
# 测试数据
data <- 1:1000
# 执行并行计算
parallel_function(data)
```
在这个例子中,我们创建了一个`parallel_function`函数,它使用`parallel`包创建多个工作节点来并行计算一个数值序列的平方。这可以提高大数据集的处理效率。
在接下来的章节中,我们将继续深入探讨R语言的其他高级应用,包括数据包的开发与管理、R语言与其他系统的交互,以及如何创建和优化自定义分析工具。
# 3. 数据包开发与管理
在本章节中,我们将深入探讨R语言中数据包开发与管理的全过程。R语言是数据分析和统计计算领域内广泛使用的语言,随着数据科学的不断发展,开发和维护R包已经成为许多数据科学从业者的核心技能之一。我们将从包的结构和组成开始,逐步介绍如何编写文档、进行测试,以及版本控制和发布的相关知识。此外,我们还将讨论如何有效地管理和更新这些包以满足不断变化的需求。
## 3.1 开发个人R包的流程
### 3.1.1 包的结构与组成
R包是R的一个标准打包单元,用于组织和分发R代码、数据、文档和测试。创建一个R包的目的是为了提高代码的可复用性、可维护性以及便于共享和协作。
一个标准的R包通常包含以下几个核心组件:
- `DESCRIPTION` 文件:这个文件包含了包的元数据,如包的名称、版本、作者、维护者、依赖关系等。
- `NAMESPACE` 文件:定义了包的导出函数和导入其他包的函数。
- `R` 目录:包含R代码,一般按照功能或文件名组织。
- `man` 目录:存放R包的文档,每个函数都有对应的.Rd文件。
- `tests` 目录:存放测试代码,确保包的各个功能正常运行。
- 其他可能的目录,如数据集(`data`)、编译代码(`src`)、示例(`examples`)和系统文件(`sysdata.rda`)。
```r
# 一个简单的DESCRIPTION文件示例
Package: mypackage
Version: 0.1.0
Title: My personal R package
Description: This package contains personal utilities for data analysis.
Author: Your Name <***>
Maintainer: Your Name <***>
License: MIT + file LICENSE
Imports: dplyr, ggplot2
Suggests: testthat
Depends: R (>= 3.5.0)
RoxygenNote: 7.1.1
```
在创建包的结构时,可以使用`devtools`包中的`create`函数快速生成包的基本框架:
```r
# 使用devtools创建R包
devtools::create("mypackage")
```
### 3.1.2 编写文档和测试代码
为了确保R包的质量和用户友好性,编写良好的文档和测试代码是非常关键的。在R包开发中,文档是通过注释和.Rd文件来编写的,而测试通常是通过`testthat`包来实现的。
- **编写文档:** R包中的每个公共函数都应该有详细的文档。文档应该包括函数的用途、参数描述、返回值以及函数使用示例。可以通过`roxygen2`标签来编写文档,然后使用`devtools::document()`函数来生成.Rd文件。
- **编写测试代码:** 测试代码位于`tests`目录下,测试套件应该覆盖包中的所有主要功能。可以使用`testthat`包来组织和运行测试。测试文件通常以`test-`开头,以`.R`结尾。
```r
# 示例:编写一个函数的文档
#' Add two numbers
#'
#' This function takes two numbers and returns the sum.
#' @param x A number.
#' @param y A number.
#' @return A number, the sum of x and y.
#' @examples
#' add_numbers(1, 2)
#' @export
add_numbers <- function(x, y) {
x + y
}
# 示例:创建一个测试用例
test_that("add_numbers adds two numbers", {
expect_equal(add_numbers(1, 2), 3)
expect_error(add_numbers("a", 2)) # 应当返回错误
})
```
## 3.2 包的版本控制与发布
### 3.2.1 使用Git进行版本控制
版本控制是软件开发中不可或缺的环节,它允许开发者记录和管理代码的变化。`Git`是一个广泛使用的版本控制系统,而`GitHub`则提供了一个便于协作的在线平台。
在R包的开发过程中,使用`Git`可以:
- 跟踪文件的变更历史。
- 方便地与协作者共享代码。
- 创建版本标签(Release)。
R包的每个提交(commit)都应该是一个有意义的更改,例如添加一个新函数或修复一个错误。每个提交应该有清晰的提交信息(commit message),以说明所做的更改。
### 3.2.2 CRAN提交流程与注意事项
提交R包到CRAN(Comprehensive R Archive Network)是一个正式的过程,需要遵循CRAN的政策和指南。
提交过程通常包括以下几个步骤:
1. 确保包满足CRAN的提交标准,包括代码风格、文档完整性和测试覆盖率。
2. 使用`devtools`的`check()`函数检查包是否符合CRAN的要求。
3. 创建一个tarball文件(使用`devtools::build()`)。
4. 登录到CRAN的提交系统,上传包的tarball文件。
注意事项:
- 确保包没有警告或错误。
- 确保所有的函数都经过充分的测试。
- 包的描述文件(DESCRIPTION)和文档(man目录下的.Rd文件)应该是最新的,并且没有拼写或语法错误。
- 上传的包版本应该是符合语义版本控制的。
```r
# 创建并检查R包
devtools::check() # 运行所有检查
devtools::build() # 构建包的tarball文件
```
## 3.3 包的维护与更新
### 3.3.1 处理用户反馈与错误报告
在R包发布后,开发者需要处理用户的反馈和错误报告。有效的用户支持不仅可以提高用户的满意度,还能帮助开发者发现和修复潜在的问题。
处理用户反馈的基本流程如下:
1. 欢迎用户反馈并鼓励提供问题报告。
2. 使用问题跟踪系统(如GitHub Issues)收集和管理用户报告的问题。
3. 对于每个问题,复现问题、确定问题的范围,并确定优先级。
4. 开发修复或改进。
5. 更新包并重新发布。
### 3.3.2 包的升级策略与兼容性
随着R语言和依赖包的更新,R包可能需要升级以保持最新状态。在升级包时,需要考虑以下几点:
- **向后兼容性:** 尽量保证新版本的包与旧版本的用户代码兼容。
- **新功能和改动:** 提供清晰的升级指南,说明新版本中引入的新功能和需要用户注意的任何改变。
- **版本控制:** 使用语义版本控制(major.minor.patch)来跟踪更新。
- **用户通知:** 通过邮件列表、社交媒体等方式通知用户有关包的更新。
```r
# 示例:更新包的版本号
usethis::use_version("major") # 主版本更新
usethis::use_version("minor") # 次版本更新
usethis::use_version("patch") # 补丁更新
```
以上是本章节内容的详细介绍。在下一章节中,我们将继续深入探讨R语言与外部系统的交互,包括与数据库的交互以及在Web应用中的应用。
# 4. R语言与外部系统的交互
在当今大数据的时代背景下,单一的数据处理能力已经不足以满足复杂的数据分析需求。为了扩大R语言的应用范围和增强其实用性,与外部系统的交互能力成为了一个重要的课题。R语言通过多种方式与其他系统进行交互,这包括但不限于数据库、Web服务、云平台等。第四章将详细探讨R语言如何与外部系统进行有效的交互。
## 4.1 R语言与数据库的交互
数据库是企业存储和管理数据的核心,R语言通过数据库连接可以实现数据的导入导出、复杂查询、数据清洗等操作。本节将分别介绍如何连接数据库、执行查询,以及在大数据环境下的应用。
### 4.1.1 数据库连接与查询
R语言通过多种数据库接口包(如DBI、RMySQL、RPostgreSQL等)可以连接和操作不同类型的数据库系统。使用这些接口包时,R语言的用户可以编写SQL语句,或者使用R语言的高级函数直接与数据库进行交互。
首先,以连接MySQL数据库为例,展示如何在R中建立连接:
```r
# 安装和加载RMySQL包
if (!require("RMySQL", quietly = TRUE)) {
install.packages("RMySQL")
}
library(RMySQL)
# 连接到MySQL数据库
# 注意替换以下参数中的用户名、密码以及数据库名等信息
con <- dbConnect(MySQL(), user = 'your_username', password = 'your_password', dbname = 'your_dbname', host = 'your_host')
```
接下来是执行查询的例子:
```r
# 查询数据表中的记录
data <- dbGetQuery(con, "SELECT * FROM your_table")
# 使用事务执行多个SQL语句
dbSendStatement(con, "INSERT INTO your_table (column1, column2) VALUES (value1, value2)")
dbSendStatement(con, "UPDATE your_table SET column1 = 'new_value' WHERE condition")
dbClearResult(res) # 清除结果集,避免占用资源
```
数据库连接和查询是数据处理不可或缺的一部分,它们不仅可以完成数据的增删改查操作,还可以用来执行复杂的SQL语句进行数据的批量处理。
### 4.1.2 大数据环境下的R语言应用
在大数据环境下,R语言面对的挑战是如何有效地处理和分析海量的数据集。由于R语言在内存处理上的限制,我们需要采取一些策略来优化大数据操作。
一种常见的方法是使用数据库的分批查询功能,将数据分批加载到R环境中进行处理。分批查询可以有效控制内存使用,但是增加了编程的复杂性。
```r
# 以1000条记录为一批次进行分批查询
n <- 1000
start <- 1
end <- n
while(end < nrow(your_data_table)) {
data_batch <- dbGetQuery(con, sprintf("SELECT * FROM your_table LIMIT %d, %d", start, end))
# 对data_batch进行分析处理
start <- start + n
end <- end + n
}
# 关闭数据库连接
dbDisconnect(con)
```
此外,可以利用R语言的并行计算能力,通过`parallel`包进行并行数据处理,或者使用`bigmemory`等包来管理大型内存数据结构。这些方法可以显著提升R语言处理大数据的能力,但同时需要对R语言的并行编程和内存管理有深入的理解。
## 4.2 R语言在Web应用中的角色
R语言并非只能进行统计分析和数据可视化,随着Shiny、Rook等Web开发框架的出现,R语言也逐渐成为构建Web应用的一股力量。
### 4.2.1 构建Web应用的基础框架
Shiny是R语言中一个非常受欢迎的Web应用框架。它允许数据科学家快速构建交互式的Web应用,而无需深入了解Web开发的细节。Shiny应用由两个主要部分组成:用户界面(UI)和服务器逻辑。
下面是一个简单的Shiny应用的代码示例:
```r
library(shiny)
# 定义UI
ui <- fluidPage(
titlePanel("Simple Shiny App"),
sidebarLayout(
sidebarPanel(
sliderInput("bins",
"Number of bins:",
min = 1,
max = 50,
value = 30)
),
mainPanel(
plotOutput("distPlot")
)
)
)
# 定义服务器逻辑
server <- function(input, output) {
output$distPlot <- renderPlot({
# 生成随机数据
x <- faithful$waiting
bins <- seq(min(x), max(x), length.out = input$bins + 1)
# 绘制直方图
hist(x, breaks = bins, col = 'darkgray', border = 'white')
})
}
# 运行应用
shinyApp(ui = ui, server = server)
```
通过Shiny,开发者可以轻松创建用于数据探索、模型展示或报告生成的Web应用。Shiny应用的开发流程简单直观,适合快速原型开发和迭代。
### 4.2.2 Shiny应用开发案例分析
为了深入了解Shiny应用的实际开发过程,我们可以通过一个案例分析来具体说明。假设我们需要开发一个用于股票市场分析的Shiny应用,该应用需要能够展示股票的实时价格,历史价格趋势图,以及一些简单的技术分析指标。
我们首先需要加载必要的R包,如`quantmod`用于获取股票数据,`dygraphs`用于制作交互式的时间序列图表等。
```r
library(shiny)
library(quantmod)
library(dygraphs)
# UI部分
ui <- fluidPage(
titlePanel("Stock Market Analysis App"),
sidebarLayout(
sidebarPanel(
textInput("stock", "Stock Ticker", "AAPL"),
dateRangeInput("date", "Date range", start = Sys.Date()-30, end = Sys.Date())
),
mainPanel(
dygraphOutput("dygraph"),
tableOutput("stock_table")
)
)
)
# 服务器逻辑部分
server <- function(input, output) {
getStockData <- reactive({
getSymbols(input$stock, src = "yahoo", from = input$date[1], to = input$date[2])
Cl(get(input$stock))
})
output$dygraph <- renderDygraph({
dygraph(getStockData(), main = paste("Stock Price of", input$stock))
})
output$stock_table <- renderTable({
tail(getStockData(), 10)
})
}
# 运行应用
shinyApp(ui = ui, server = server)
```
在这个案例中,我们创建了一个包含两个组件的UI,一个用于输入股票代码和日期范围,另一个用于显示股票价格的图表和表格。服务器逻辑部分使用`reactive`函数来响应用户输入的变化,实时获取并展示股票数据。
通过这个案例,我们可以看到Shiny不仅能够构建交互式的Web应用,还能够实现数据的动态处理和可视化。这对于需要快速构建数据展示平台的业务场景尤为重要。
通过本章节的介绍,我们了解了R语言与外部系统的交互能力,并通过实际的例子展示了如何将R语言应用于数据库操作和Web应用开发。这些交互方式极大地扩展了R语言在数据分析和应用领域的适用性,使其成为一个更为全面的数据科学工具。
# 5. 案例研究:自定义R语言分析工具
## 5.1 案例分析:打造行业特定分析工具
### 5.1.1 需求分析与设计思路
在构建一个行业特定的R语言分析工具时,需求分析至关重要。它涉及到收集使用者的反馈,确定工具需要解决的问题,以及预期的工作流。比如,在金融行业,分析工具可能需要从股票市场获取数据,分析趋势,并提供预测功能。
设计思路首先从确定核心功能开始,比如:
- 数据获取:自定义函数从外部API抓取数据。
- 数据处理:清洗和转换数据以便于分析。
- 数据分析:利用统计模型或机器学习算法进行分析。
- 结果可视化:提供图表和报告。
```r
# 示例:金融分析工具的核心函数
get_stock_data <- function(stock_symbol) {
# 使用API获取股票数据
# 返回数据结构为data.frame
}
process_data <- function(data) {
# 数据清洗和预处理
# 返回处理后的数据结构为data.frame
}
perform_analysis <- function(processed_data) {
# 实施统计分析或机器学习模型
# 返回模型结果
}
visualize_results <- function(model_results) {
# 生成图表或报告
# 无返回值,直接生成可视化内容
}
```
### 5.1.2 工具开发过程详解
开发过程中的每一步都需要详细记录和测试,以确保工具的健壮性和准确性。开发流程可以分为以下几个步骤:
1. **工具框架搭建**:确定工具的基本结构,包括输入输出模块,数据处理模块,分析模块和可视化模块。
2. **模块开发**:对每个模块进行独立开发,确保各模块间的接口定义清晰。
3. **单元测试**:为每个函数编写单元测试,确保其正确执行。
4. **集成测试**:在模块开发完成后,进行集成测试,确保模块间协同工作无误。
5. **用户反馈**:在工具的初步版本完成后,邀请目标用户进行测试,并收集反馈。
6. **迭代优化**:根据用户反馈,对工具进行持续的优化和功能迭代。
## 5.2 实践挑战与解决方案
### 5.2.1 遇到的实际问题与解决方法
在开发和使用R语言分析工具的过程中,可能遇到的挑战包括但不限于性能瓶颈、数据质量问题、用户反馈的多样性等。
面对性能瓶颈,可以采取以下解决方法:
- **代码优化**:审查并优化低效的代码段。
- **并行计算**:利用R的并行包(如`parallel`)来加速计算。
- **内存管理**:使用R6、data.table等内存高效的数据结构。
```r
# 并行计算示例代码
library(parallel)
# 创建一个集群
cl <- makeCluster(detectCores())
# 执行并行计算
result <- parLapply(cl, 1:10, function(x) {
# 执行复杂的运算任务
})
# 关闭集群
stopCluster(cl)
```
对于数据质量问题,可以建立严格的数据审核流程和数据质量校验机制。
### 5.2.2 工具的测试、部署与维护
测试阶段是确保分析工具质量和稳定性的关键环节。这包括:
- **单元测试**:确保每个函数按预期工作。
- **集成测试**:验证函数间交互是否无误。
- **系统测试**:模拟真实使用场景测试整个工具。
部署阶段,可以利用Shiny Server或RStudio Connect将分析工具部署到服务器,使之对用户可用。维护阶段包括:
- **持续集成**:利用CI/CD工具如GitHub Actions自动化测试和部署。
- **更新日志**:记录每次更新的内容和原因,便于追踪和管理。
- **用户支持**:建立帮助文档和用户反馈渠道,快速响应用户需求。
通过实践中的挑战与解决方案,我们可以构建出一个既健壮又高效的R语言分析工具,满足特定行业的需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 R 语言数据包和 kmeans 聚类分析为主题,提供了一系列深入且实用的教程。从基础入门到高级功能,从数据清洗到图表绘制,再到机器学习集成和性能优化,涵盖了数据分析的各个方面。专栏还深入探讨了 kmeans 统计原理、内存管理和数据安全,帮助读者全面掌握数据分析技术。通过案例剖析和实战指导,读者可以将所学知识应用到实际问题中,提升数据处理能力和决策制定水平。无论你是 R 语言新手还是经验丰富的分析师,本专栏都能为你提供有价值的见解和实用技巧,助力你成为一名数据分析专家。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【靶机环境侦察艺术】:高效信息搜集与分析技巧

# 摘要
本文深入探讨了靶机环境侦察的艺术与重要性,强调了在信息搜集和分析过程中的理论基础和实战技巧。通过对侦察目标和方法、信息搜集的理论、分析方法与工具选择、以及高级侦察技术等方面的系统阐述,文章提供了一个全面的靶机侦察框架。同时,文章还着重介绍了网络侦察、应用层技巧、数据包分析以及渗透测试前的侦察工作。通过案例分析和实践经验分享,本文旨在为安全专业人员提供实战指导,提升他们在侦察阶段的专业
【避免数据损失的转换技巧】:在ARM平台上DWORD向WORD转换的高效方法

# 摘要
本文对ARM平台下DWORD与WORD数据类型进行了深入探讨,从基本概念到特性差异,再到高效转换方法的理论与实践操作。在基础概述的基础上,文章详细分析了两种数据类型在ARM架构中的表现以及存储差异,特别是大端和小端模式下的存储机制。为了提高数据处理效率,本文提出了一系列转换技巧,并通过不同编程语言实
高速通信协议在FPGA中的实战部署:码流接收器设计与优化
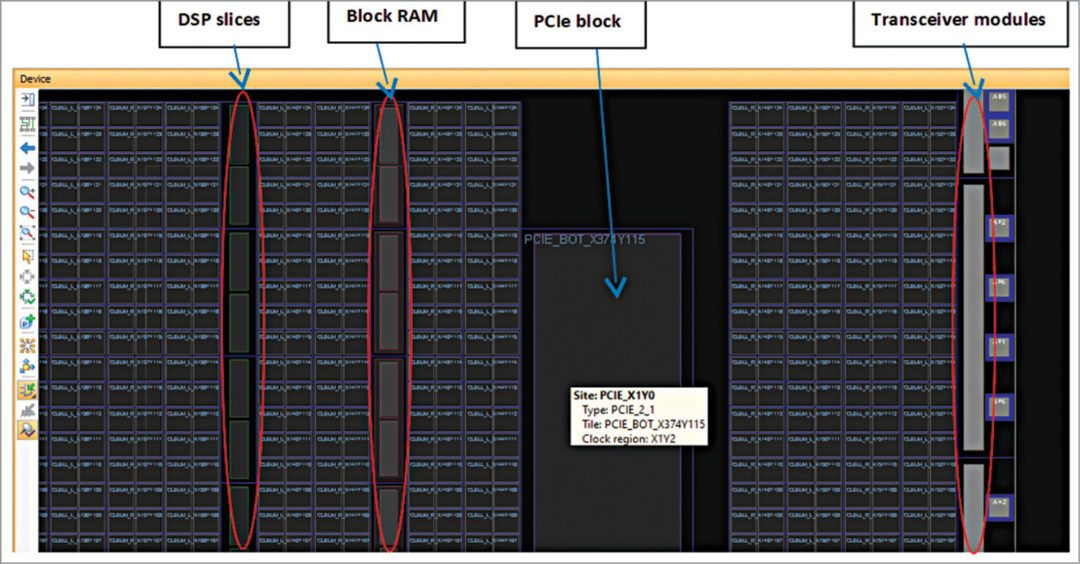
# 摘要
高速通信协议在现代通信系统中扮演着关键角色,本文详细介绍了高速通信协议的基础知识,并重点阐述了FPGA(现场可编程门阵列)中码流接收器的设计与实现。文章首先概述了码流接收器的设计要求与性能指标,然后深入讨论了硬件描述语言(HDL)的基础知识及其在FPGA设计中的应用,并探讨了FPGA资源和接口协议的选择。接着,文章通过码流接收器的硬件设计和软件实现,阐述了实践应用中的关键设计要点和性能优化方法。第
贝塞尔曲线工具与插件使用全攻略:提升设计效率的利器
# 摘要
贝塞尔曲线是图形设计和动画制作中广泛应用的数学工具,用于创建光滑的曲线和形状。本文首先概述了贝塞尔曲线工具与插件的基本概念,随后深入探讨了其理论基础,包括数学原理及在设计中的应用。文章接着介绍了常用贝塞尔曲线工具
CUDA中值滤波秘籍:从入门到性能优化的全攻略(基础概念、实战技巧与优化策略)

# 摘要
本论文旨在探讨CUDA中值滤波技术的入门知识、理论基础、实战技巧以及性能优化,并展望其未来的发展趋势和挑战。第一章介绍CUDA中值滤波的基础知识,第二章深入解析中值滤波的理论和CUDA编程基础,并阐述在CUDA平台上实现中值滤波算法的技术细节。第三章着重讨论CUDA中值滤波的实战技巧,包括图像预处理与后处理
深入解码RP1210A_API:打造高效通信接口的7大绝技

# 摘要
本文系统地介绍了RP1210A_API的架构、核心功能和通信协议。首先概述了RP1210A_API的基本概念及版本兼容性问题,接着详细阐述了其通信协议框架、数据传输机制和错误处理流程。在此基础上,文章转入RP1210A_API在开发实践中的具体应用,包括初始化、配置、数据读写、传输及多线程编程等关键点。文中还提供多个应用案例,涵盖车辆诊断工具开发、嵌入式系统集成以及跨平台通
【终端快捷指令大全】:日常操作速度提升指南
# 摘要
终端快捷指令作为提升工作效率的重要工具,其起源与概念对理解其在不同场景下的应用至关重要。本文详细探讨了终端快捷指令的使用技巧,从基础到高级应用,并提供了一系列实践案例来说明快捷指令在文件处理、系统管理以及网络配置中的便捷性。同时,本文还深入讨论了终端快捷指令的进阶技巧,包括自动化脚本的编写与执行,以及快捷指令的自定义与扩展。通过分析终端快捷指令在不同用户群体中的应用
电子建设工程预算动态管理:案例分析与实践操作指南

# 摘要
电子建设工程预算的动态管理是指在项目全周期内,通过实时监控和调整预算来优化资源分配和控制成本的过程。本文旨在综述动态管理在电子建设工程预算中的概念、理论框架、控制实践、案例分析以及软件应用。文中首先界定了动态管理的定义,阐述了其重要性,并与静态管理进行了比较。随后,本文详细探讨了预算管理的基本原则,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )