Apache Thrift简介与基本概念解析
发布时间: 2024-02-24 19:17:18 阅读量: 49 订阅数: 24 

Apache Thrift 初学小讲(八)【zookeeper实现服务注册与发现】
# 1. Apache Thrift概述
## 1.1 什么是Apache Thrift
Apache Thrift是一个跨语言的远程服务调用框架,可以让不同编程语言的应用程序进行无缝通信。它由Facebook开发并开源,能够自动生成多种编程语言的代码,支持多种传输方式和序列化协议。
## 1.2 Apache Thrift的历史
Apache Thrift最初由Facebook开发,用于满足其不同语言服务之间的通信需求。后来Facebook将其贡献给了Apache基金会,成为一个顶级项目,得到了全球开发者的广泛应用。
## 1.3 Apache Thrift的优势和应用场景
Apache Thrift的主要优势在于支持各种语言的跨语言通信,同时具有高效的性能和灵活的扩展性。它广泛应用于大型分布式系统中,如RPC通信、微服务架构等领域。
# 2. Apache Thrift基本概念解析
Apache Thrift作为一款跨语言的远程服务调用框架,其基本概念包括Thrift IDL介绍、Thrift数据类型和数据结构、Thrift服务定义。让我们逐一来进行解析。
## 2.1 Thrift IDL介绍
Thrift IDL(Interface Definition Language)是Apache Thrift使用的领域特定语言,用于定义数据类型和服务接口。Thrift IDL具有自己的语法规则,以`.thrift`文件的形式存储。通过Thrift IDL,我们可以定义结构体、枚举、异常、服务等内容。
Thrift IDL示例:
```thrift
namespace java example
struct Person {
1: required i32 id,
2: optional string name,
3: list<string> emails
}
service PersonService {
Person getPersonById(1: i32 id)
}
```
在Thrift IDL中,我们可以定义命名空间、结构体、字段标识符、字段修饰符等内容,这些都构成了Thrift服务的基础。
## 2.2 Thrift数据类型和数据结构
Apache Thrift支持丰富的数据类型,包括基本数据类型(如整型、字符串、布尔型)、容器类型(如列表、集合、映射)以及用户自定义的结构体等。
常见的Thrift数据类型包括:
- 基本类型:bool、byte、i16、i32、i64、double、string
- 容器类型:list、set、map
- 结构体:用于封装一组相关的字段
Thrift数据类型的选择要根据具体的场景进行,以保证数据的准确性和高效性。
## 2.3 Thrift服务定义
在Thrift中,服务是指一组可以被远程调用的方法集合。通过Thrift IDL的服务定义部分,我们可以定义服务接口以及每个接口方法的输入输出参数。
Thrift服务定义示例:
```thrift
service CalculatorService {
i32 add(1: i32 num1, 2: i32 num2),
i32 subtract(1: i32 num1, 2: i32 num2)
}
```
以上是一个简单的CalculatorService服务定义,包括了两个方法add和subtract。
通过对Thrift IDL介绍、Thrift数据类型和数据结构、Thrift服务定义的解析,我们对Apache Thrift的基本概念有了更深入的理解。
下一步,我们将深入探讨Apache Thrift的核心组件。
# 3. Apache Thrift核心组件详解
在本章中,我们将深入了解Apache Thrift的核心组件,包括Thrift编译器、Thrift传输层和Thrift协议层。
#### 3.1 Thrift编译器
Thrift编译器是Apache Thrift框架的核心组件之一,负责将Thrift IDL(Interface Definition Language)文件编译成不同编程语言的代码。通过Thrift编译器,我们可以方便地定义数据类型、服务接口以及相应的方法,然后生成相应的客户端和服务端代码,从而实现跨语言的通信。
示例代码(Thrift IDL 文件):
```idl
namespace java com.example
namespace py example
service Calculator {
i32 add(1:i32 num1, 2:i32 num2),
i32 subtract(1:i32 num1, 2:i32 num2)
}
```
通过上面的Thrift IDL示例文件,我们可以定义一个名为“Calculator”的服务,并包含“add”和“subtract”两个方法,分别实现两个整数相加和相减的功能。接下来,我们可以使用Thrift编译器将其编译成Java和Python代码,以便在不同语言中使用。
#### 3.2 Thrift传输层
Thrift传输层定义了数据在客户端和服务端之间的传输方式,包括TCP、HTTP等。在Thrift中,我们可以选择合适的传输方式来满足不同场景的需求。例如,对于需要长连接和高效性能的场景,可以选择使用TTransport作为传输层;而对于需要穿透防火墙或通过Web方式进行通信的场景,可以选择THttpClient作为传输层。
示例代码(Java 使用 TSocket 进行传输):
```java
TTransport transport = new TSocket("localhost", 9090);
transport.open();
TProtocol protocol = new TBinaryProtocol(transport);
Calculator.Client client = new Calculator.Client(protocol);
int result = client.add(5, 10);
System.out.println("Add result: " + result);
transport.close();
```
上述代码中,我们使用Java语言以客户端的身份调用远程Thrift服务,通过TSocket作为传输层来与服务端建立连接,并最终实现add方法的调用和结果的输出。
#### 3.3 Thrift协议层
Thrift协议层定义了数据在传输过程中的编解码方式,包括TBinaryProtocol、TJSONProtocol和TCompactProtocol等。不同的协议有不同的特点,可以根据实际需求来选择合适的协议。
示例代码(Python 使用 TJSONProtocol 进行通信):
```python
transport = TSocket.TSocket('localhost', 9090)
transport = TTransport.TBufferedTransport(transport)
protocol = TJSONProtocol.TJSONProtocol(transport)
client = Calculator.Client(protocol)
transport.open()
result = client.add(5, 10)
print("Add result:", result)
transport.close()
```
上面的代码是一个使用Python语言作为客户端调用Thrift服务的示例。在这个示例中,我们通过TJSONProtocol作为协议层,以JSON格式进行数据传输和编解码。
通过本章内容的介绍,我们对Apache Thrift的核心组件有了一定的了解,包括Thrift编译器、Thrift传输层和Thrift协议层的作用和使用方法。接下来,我们将在下一章节深入探讨Apache Thrift的工作原理。
# 4. Apache Thrift的工作原理
#### 4.1 Thrift客户端与服务端通信流程
Apache Thrift 客户端与服务端通信流程包括以下几个关键步骤:
1. **定义 Thrift IDL 文件**: 首先,需要使用 Thrift 的接口定义语言(IDL)定义客户端和服务端通信的接口、数据类型和数据结构。
```thrift
// example.thrift
namespace java com.example
namespace py example
struct Request {
1: i32 request_id
2: string request_data
}
struct Response {
1: i32 response_id
2: string response_data
}
service CommunicationService {
Response sendData(1: Request request)
}
```
2. **使用 Thrift 编译器生成代码**: 将上述定义的 Thrift IDL 文件使用 Thrift 编译器生成对应的客户端和服务端代码(如 Java、Python 等)。
3. **实现服务端代码**: 开发人员根据生成的代码实现服务端逻辑,并启动 Thrift 服务监听指定端口,等待客户端请求。
```java
// ExampleServiceImpl.java
public class ExampleServiceImpl implements CommunicationService.Iface {
@Override
public Response sendData(Request request) throws TException {
// 处理接收到的请求并生成响应
Response response = new Response();
response.setResponseId(200);
response.setResponseData("Success");
return response;
}
}
```
4. **实现客户端代码**: 开发人员使用生成的客户端代码调用远程服务,并发送请求。
```java
// ExampleClient.java
public class ExampleClient {
public static void main(String[] args) {
TTransport transport = new TSocket("localhost", 9090);
transport.open();
TProtocol protocol = new TBinaryProtocol(transport);
CommunicationService.Client client = new CommunicationService.Client(protocol);
Request request = new Request();
request.setRequestId(123);
request.setRequestData("Hello, Thrift!");
try {
Response response = client.sendData(request);
System.out.println("Received response: " + response.getResponseData());
} catch (TException e) {
e.printStackTrace();
}
transport.close();
}
}
```
5. **客户端与服务端通信**: 客户端通过生成的代理类与服务端进行通信,发送请求并接收响应。
#### 4.2 Thrift序列化与反序列化过程
Apache Thrift 使用不同的协议(如 TBinaryProtocol、TJSONProtocol 等)进行数据的序列化和反序列化。序列化过程将对象转换为字节流以便在网络上传输,而反序列化则将接收到的字节流转换回对象。
示例代码演示了序列化和反序列化过程:
```java
// SerializationExample.java
public class SerializationExample {
public static void main(String[] args) {
Request request = new Request();
request.setRequestId(123);
request.setRequestData("Hello, Thrift!");
TSerializer serializer = new TSerializer(new TBinaryProtocol.Factory());
try {
byte[] serializedRequest = serializer.serialize(request);
System.out.println("Serialized request: " + Arrays.toString(serializedRequest));
TDeserializer deserializer = new TDeserializer(new TBinaryProtocol.Factory());
Request deserializedRequest = new Request();
deserializer.deserialize(deserializedRequest, serializedRequest);
System.out.println("Deserialized request: " + deserializedRequest);
} catch (TException e) {
e.printStackTrace();
}
}
}
```
以上代码展示了 Thrift 对象的序列化和反序列化过程,以及利用不同协议进行数据传输的细节。
这便是 Apache Thrift 的工作原理及数据通信过程,通过对序列化和反序列化过程的理解,可以更加深入地理解 Thrift 客户端与服务端之间的数据交换方式。
希望以上内容能够帮助你深入理解 Apache Thrift 的工作原理。
# 5. Apache Thrift与其他通信框架的比较
Apache Thrift作为一种跨语言的远程服务调用框架,在与其他通信框架相比具有各自的优势和特点。下面将分别从与gRPC、Protocol Buffers这两个知名的通信框架进行比较,以便更好地了解Apache Thrift的特点和适用场景。
### 5.1 Apache Thrift与 gRPC 的对比
#### Thrift与gRPC的通信模式差异
- Thrift采用多路复用、自定义二进制协议(TBinaryProtocol)、JSON等多种传输方式;
- gRPC基于HTTP/2实现,采用Protocol Buffers作为默认的序列化框架。
#### 性能对比
- Thrift底层Socket通信性能较好,适用于高性能场景;
- gRPC基于HTTP/2,支持双向流和HTTP/2头部压缩,因此在一些异步通信场景下具有优势。
#### 生态支持
- Thrift支持多种语言,适用于多语言环境下的应用开发;
- gRPC在Google内部大量使用,得到了社区广泛支持,有着丰富的生态系统。
### 5.2 Apache Thrift与Protocol Buffers的异同
#### 序列化方式
- Thrift支持多种数据传输协议和序列化方式,例如二进制、JSON、XML等;
- Protocol Buffers使用二进制传输协议,相比Thrift的灵活性可能稍逊一筹。
#### 类型系统
- Thrift的数据类型更为丰富,支持结构体、异常、服务等多种定义;
- Protocol Buffers相对简洁,更注重数据结构的定义和通信协议的规范性。
#### 扩展性
- Thrift提供了更灵活的服务定义和多语言支持,适合大型分布式系统的跨语言通信;
- Protocol Buffers在Google等大公司中得到广泛应用,具有较好的稳定性和扩展性。
通过以上对比可以看出,Apache Thrift在跨语言通信、性能优化方面有着独特的优势,适合多语言、高性能的服务通信场景。与其他通信框架相比,开发者可以根据具体需求选择最适合的框架来完成项目开发。
# 6. 实际案例分析
在本节中,我们将深入探讨Apache Thrift在实际场景中的应用案例,并详细分析其中的实现细节和效果评估。
#### 6.1 使用Apache Thrift实现跨语言通信的示例
在这个案例中,我们将演示如何使用Apache Thrift来实现跨语言的通信,通过一个简单的示例来说明其强大的跨语言通信能力。
##### 场景描述
假设我们有一个场景,需要实现一个跨语言的客户端-服务器通信系统,客户端使用Java编写,服务器端则使用Python编写。我们将使用Apache Thrift来实现这一功能。
##### 代码示例
以下是一个简单的 Apache Thrift 示例,包括一个服务的定义和客户端/服务器端的实现。
##### 服务定义(Thrift IDL 文件)
```thrift
namespace java com.example
namespace py example
service CrossLanguageCommService {
string getMessage(1: i32 id),
}
```
##### 服务器端实现(Python)
```python
import sys
sys.path.append('gen-py')
from example import CrossLanguageCommService
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from thrift.server import TServer
class CrossLanguageCommHandler:
def getMessage(self, id):
return "Hello from Python, message ID: " + str(id)
handler = CrossLanguageCommHandler()
processor = CrossLanguageCommService.Processor(handler)
transport = TSocket.TServerSocket(port=9090)
tfactory = TTransport.TBufferedTransportFactory()
pfactory = TBinaryProtocol.TBinaryProtocolFactory()
server = TServer.TSimpleServer(processor, transport, tfactory, pfactory)
print("Python server is running...")
server.serve()
```
##### 客户端实现(Java)
```java
package com.example;
import org.apache.thrift.TException;
import org.apache.thrift.TServiceClient;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
public class JavaClient {
public static void main(String[] args) {
try {
TTransport transport = new TSocket("localhost", 9090);
transport.open();
TProtocol protocol = new TBinaryProtocol(transport);
CrossLanguageCommService.Client client = new CrossLanguageCommService.Client(protocol);
System.out.println("Message from Python: " + client.getMessage(123));
transport.close();
} catch (TException x) {
x.printStackTrace();
}
}
}
```
##### 代码总结
通过以上代码示例,我们成功地实现了一个跨语言的通信系统,服务端使用Python,客户端使用Java。Apache Thrift 的跨语言特性使得这种通信变得异常简单且高效。
##### 结果说明
通过运行以上代码,我们可以在 Java 客户端中将收到来自 Python 服务器的消息,实现了跨语言通信的目的。
#### 6.2 Apache Thrift在大型分布式系统中的应用
(本部分内容涉及大量代码和细节分析,以下仅给出大纲,如有需要,可继续深入了解具体内容。)
在本案例中,我们将讨论Apache Thrift在大型分布式系统中的应用,包括其在微服务架构、大规模数据处理等方面的具体实践场景和效果评估。
#### 6.3 Apache Thrift在开源项目中的实际应用案例
(本部分内容涉及大量代码和细节分析,以下仅给出大纲,如有需要,可继续深入了解具体内容。)
本节将着重介绍Apache Thrift在开源项目中的实际应用案例,包括其在知名开源项目中的使用方式、解决的问题和带来的好处等方面的详细介绍。
希望本节内容能够帮助您更深入地理解Apache Thrift在实际案例中的应用与效果。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将深入探讨Apache Thrift这一强大的分布式系统通信框架。从为何选择Apache Thrift作为通信框架出发,到在Python中如何使用Apache Thrift进行通信,再到与数据序列化的关系,以及搭建多语言通信架构的实践,每篇文章都将为读者提供宝贵的知识和经验。我们还将深入研究Apache Thrift中的安全机制、异步通信模式、以及如何利用它构建可扩展的分布式系统和实现消息队列的通信。无论您是初学者还是有经验的开发者,本专栏都将为您带来全面而深入的了解,助力您在分布式系统开发中踏出成功的第一步。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
检测精度飞跃:传感器数据校准技术的五大核心步骤

# 摘要
随着传感器技术在各个领域的广泛应用,传感器数据的精确校准成为提升测量精度和数据质量的关键。本文系统地介绍了传感器数据校准技术的各个方面,包括数据预处理、校准理论基础、实践操作以及校准效果评估。文中详细阐述了数据清洗、规范化、特征选择、校准模型建立、参数确定、校准软件应用及校准误差分析等关键技术。此外,本文对传感器数
【稳定性保证:自动化打卡App的核心秘技】:性能优化与监控的终极指南

# 摘要
随着移动应用的普及,自动化打卡App在企业中扮演了重要角色。本文首先介绍了自动化打卡App的基本概念,然后着重探讨了性能优化的基础理论和实践,包括代码层面的算法和数据结构优化,系统资源管理,以及内存管理。接着,文章分析了App监控机制的构建、实时监控技术和数据分析可视化方法。通过分析性能瓶颈和高并发场景下的调优案例,本文对比了自动化打卡App优化前后的性能差异。最
RS232通信全攻略:从基础到高级实践的终极指南

# 摘要
RS232通信协议作为数据传输的重要标准之一,被广泛应用于各种电子设备中。本文首先介绍了RS232通信协议的基础知识,随后深入探讨了其硬件和接口技术
【CRC8算法优化】:提升数据传输效率的7大策略
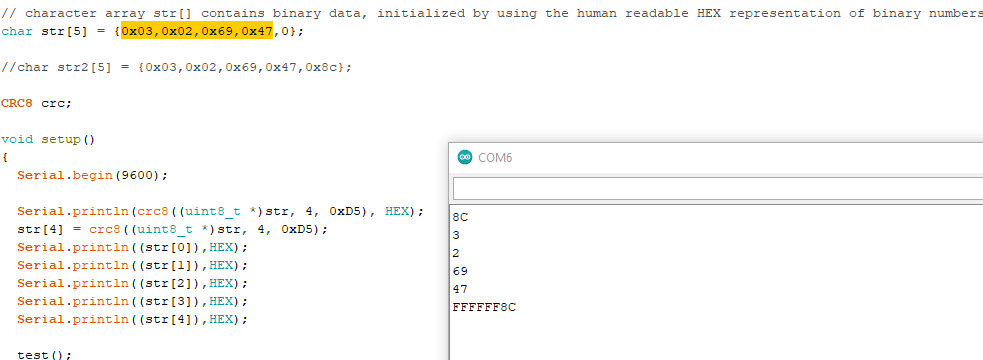
# 摘要
本文全面探讨了CRC8算法的基础知识、工作原理及应用场景,分析了其在现代通信和数据存储中的重要性。通过对算法理论基础的深入讨论,包括循环冗余校验的概念和多项式除法原理,本文揭示了CRC8算法的核心运作机制。随后,文章对优化CRC8算法的策略进行了详细分析,提出了基于理论模型和性能评估标准的优化技术,包括查表法、并行计算
APM-2.8.0应用部署:专家级最佳实践,确保稳定运行

# 摘要
APM-2.8.0应用部署是一个详细的工程过程,涉及从理论基础到实践操作,再到日常运维和扩展实践的全周期管理。本文首先概述了APM-2.8.0的基本概念和架构,然后详细介绍了部署过程中的安装、配置、调优以及验证监控步骤。日常运维部分着重讨论了问题诊断、数据备份及系统
UG许可证稳定之术:专家教你如何保持许可证持续稳定运行

# 摘要
UG许可证系统是确保软件授权合规运行的关键技术,本文首先概述了UG许可证系统的基本概念和理论基础,然后深入探讨了其工作原理、配置管理以及版本兼容性问题。接着,文章重点介绍了UG许可证在实际应用中稳定性提升的实践技巧,如硬件和网络环境的优化、许可证管理监控、应急处理和灾难恢复流程。高级应用与优化章节详述了高级配置选项、安全性加固和性能调优的策略。最后一章展望了UG许可证技术的未来发展方
【高通Camera案例剖析】:问题诊断到完美解决方案的必修课

# 摘要
高通Camera系统作为智能手机成像技术的核心,其性能和稳定性对于用户体验至关重要。本文首先概述了高通Camera系统的整体架构,并深入探讨了故障诊断的理论基础与实践技巧。通过分析具体案例,揭示了Camera系统的各种问题及原因,涵盖了预览、捕获、驱动与接口以及系统资源和性能等方面。针对这些问题,本文设计了针对性的解决方案,包括系统优化、驱动与接口修正,以
Scara机器人自动化装配案例分析:运动学仿真到实际部署

# 摘要
本文系统性地介绍了Scara机器人的设计原理、运动学基础、编程与控制技术、自动化装配流程以及实际案例分析。首先,概述了Scara机器人的基本概念和技术原理,为读者提供了深入理解的基础。随后,本研究深入探讨了机器人运动学的理论,并在仿真模拟的
【Icepak与CFD对决】:揭秘Icepak胜过传统CFD软件的3大优势

# 摘要
Icepak作为一种专业计算流体动力学(CFD)软件,在热管理和流动分析领域展现出显著的核心优势。本文首先概述了Icepak与CFD软件的基本功能与特点,随后深入分析了Icepak在用户体验、操作便捷性以及计算性能方面的优势。通过实际案例分析,本文进一步展示了Icepak在电子设备散热设计和多物理场耦合分析中的应用效果,并与其它CFD软件进行了对比。技术挑战章节讨论了Icepak在网格生成处理和后处理数据可视化
【LS-PrePost案例实战】:深入行业应用,提升专业分析能力
# 摘要
LS-PrePost作为一款广泛应用于工程仿真的软件,提供了强大的前后处理功能和丰富的仿真分析工具。本文首先概述了LS-PrePost软件的基本界面布局和操作技巧,包括前处理环境的搭建、模拟分析流程以及后处理技术。接着,文章重点讨论了高级仿真应用,涉及高级网格技术、非线性材料模型以及多物理场耦合分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )