【机器视觉缺陷识别】:从传统到深度学习的演进与优化


基于深度学习的工业缺陷检测(续篇)
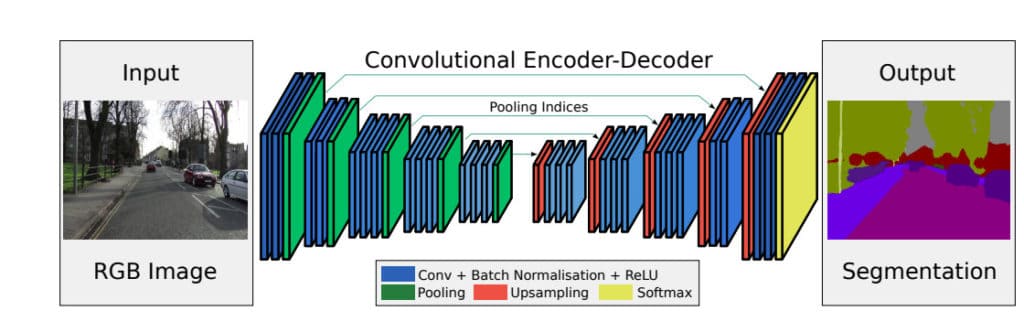
1. 机器视觉缺陷识别概述
1.1 机器视觉的发展背景
机器视觉作为自动化技术的一个分支,在工业生产、质量检测、安全保障等领域发挥着重要作用。近年来,随着计算机视觉技术的快速发展,机器视觉在缺陷识别领域的应用也日益广泛。
1.2 缺陷识别的重要性
缺陷识别涉及在生产线上实时检测出产品或组件的缺陷,以保证最终产品的质量。这不仅关系到消费者的使用体验,还涉及到企业的品牌信誉和经济效益。
1.3 缺陷识别技术的演进
最初,缺陷识别依赖人工视觉检查,效率低下且易受主观因素影响。随着技术的进步,传统机器视觉技术(如模板匹配、规则识别)逐渐兴起。而在今天,深度学习技术为缺陷识别带来了革命性的变革。
在接下来的章节中,我们将深入探讨这些技术的发展和实际应用。
2. 传统机器视觉技术
2.1 图像预处理基础
在现代机器视觉中,图像预处理是提高缺陷检测精度的关键步骤之一。图像预处理通常包括噪声去除、图像增强、边缘检测和特征提取等步骤。我们来详细了解这些技术。
2.1.1 噪声去除与图像增强技术
在获取图像的过程中,由于各种原因如传感器噪声、传输过程的干扰等,往往会在图像中引入噪声。噪声会干扰图像分析和特征提取,因此,噪声去除是预处理的首要步骤。
中值滤波是一种常用的图像去噪方法。它通过用窗口内的像素点的中值来替换窗口中心的像素值,从而去除小范围的随机噪声。例如,以下是一个中值滤波的简单应用:
- from skimage import io, filters
- import matplotlib.pyplot as plt
- # 加载图像
- image = io.imread('noisy_image.png', as_gray=True)
- # 应用中值滤波
- denoised_image = filters.median(image)
- # 显示结果
- plt.figure(figsize=(10, 5))
- plt.subplot(1, 2, 1)
- plt.title("Original Image")
- plt.imshow(image, cmap='gray')
- plt.subplot(1, 2, 2)
- plt.title("Denoised Image")
- plt.imshow(denoised_image, cmap='gray')
- plt.show()
除了去噪之外,图像增强也是常用的预处理技术,它旨在提高图像的对比度和清晰度,以便于后续处理。例如,直方图均衡化是一种常用的技术,它通过扩展图像的直方图来增强图像的全局对比度。
- from skimage import exposure
- # 应用直方图均衡化
- equalized_image = exposure.equalize.hist(image)
- # 显示原始图像和增强后的图像对比
- plt.figure(figsize=(10, 5))
- plt.subplot(1, 2, 1)
- plt.title("Original Image")
- plt.imshow(image, cmap='gray')
- plt.subplot(1, 2, 2)
- plt.title("Equalized Image")
- plt.imshow(equalized_image, cmap='gray')
- plt.show()
2.1.2 边缘检测与特征提取
在图像中检测边缘是提取物体特征的重要步骤。边缘检测可以通过检测图像中亮度变化较大的点来完成。Canny边缘检测算法是应用最广泛的边缘检测方法之一。
- from skimage.feature import canny
- # 应用Canny边缘检测
- edges = canny(image)
- # 显示边缘检测结果
- plt.imshow(edges, cmap='gray')
- plt.show()
特征提取涉及到识别图像中的特定模式或结构,它通常依赖于边缘检测的结果。例如,提取角点、圆形、椭圆形等几何特征能够用于后续的模式识别过程。SIFT、HOG等算法常用于特征提取。
2.2 传统算法缺陷检测原理
2.2.1 模板匹配
模板匹配是缺陷检测中一种简单直接的方法。它涉及到在一个较大的图像中寻找与小的模板图像最相似的区域。这种方法常用于检测固定形状和大小的缺陷。
- from scipy.ndimage import correlate
- # 读取模板和待检测图像
- template = io.imread('template.png', as_gray=True)
- search_image = io.imread('search_image.png', as_gray=True)
- # 计算相关性
- correlation = correlate(search_image, template, mode='constant')
- # 寻找最大相关性位置作为匹配点
- maxloc = np.unravel_index(np.argmax(correlation), correlation.shape)
- # 显示匹配结果
- plt.imshow(search_image, cmap='gray')
- plt.plot(maxloc[1], maxloc[0], 'ro')
- plt.show()
2.2.2 基于规则的识别技术
基于规则的识别技术依赖于预定义的规则来识别图像中的缺陷。这些规则通常基于缺陷的大小、形状、颜色等特征。例如,可以定义一个规则来识别表面划痕,该规则可能包括划痕的最小长度、最小宽度和特定的方向。
2.3 传统技术的实践应用与局限性
2.3.1 工业案例分析
在工业生产中,传统机器视觉技术被广泛应用于质量检测。例如,在电子行业,可以使用模板匹配技术来检测电路板上的缺陷。
2.3.2 局限性探讨与解决方案
尽管传统技术在工业上有广泛的应用,但它们也有局限性。如模板匹配技术依赖于预先定义的模板,对复杂背景下的缺陷检测效果有限。此外,基于规则的方法在面对复杂缺陷时,规则的设定往往非常复杂且难以覆盖所有情况。
为解决这些问题,通常需要结合多种技术以弥补单一方法的不足,或过渡到更先进的技术,如深度学习,以提高检测的准确性和鲁棒性。
3. 深度学习基础与架构
深度学习作为机器学习的一个子领域,近年来因在图像识别、语音识别、自然语言处理等众多领域取得了突破性进展而受到广泛关注。这一章将深入探讨深度学习的基本概念、核心技术以及常用的工具和框架,为后续章节中机器视觉缺陷识别的应用奠定基础。
3.1 深度学习的基本概念
3.1.1 神经网络简介
深度学习的核心是模拟人脑的神经网络结构,通过学习大量的数据来自动提取特征,无需人工设计特征。最基础的神经网络单元是感知器(Perceptron),它包括输入、加权求和和激活函数三个部分。神经网络中的每一层都由多个这样的单元组成,而深度学习的特点就是利用了深层次的神经网络结构,也就是隐藏层较多的网络,可以捕捉到数据的复杂结构和关系。
3.1.2 激活函数与损失函数
激活函数是神经网络中非线性化的关键,它允许网络学习和执行复杂的任务。常见的激活函数有ReLU、Sigmoid和Tanh等。ReLU(Rectified Linear Unit)因其计算效率和非饱和性质在深度网络中被广泛使用。损失函数衡量的是模型预测值和真实值之间的差异,它是优化算法的指导。常用的损失函数有均方误差(MSE)和交叉熵损失函数等。
3.2 卷积神经网络(CNN)详解
3

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从数据中学习,提升备份策略:DBackup历史数据分析篇
面向对象编程表达式:封装、继承与多态的7大结合技巧
【数据库升级】:避免风险,成功升级MySQL数据库的5个策略
【遥感分类工具箱】:ERDAS分类工具使用技巧与心得
【射频放大器设计】:端阻抗匹配对放大器性能提升的决定性影响
TransCAD用户自定义指标:定制化分析,打造个性化数据洞察
【数据分布策略】:优化数据分布,提升FOX并行矩阵乘法效率
数据分析与报告:一卡通系统中的数据分析与报告制作方法
电力电子技术的智能化:数据中心的智能电源管理
【终端打印信息的项目管理优化】:整合强制打开工具提高项目效率


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )