pandas入门教程:数据结构和基本操作
发布时间: 2023-12-21 00:22:29 阅读量: 64 订阅数: 26 

pandas数据结构与基本操作
# 1. 简介
## 1.1 pandas是什么
Pandas是一个开源的Python数据分析工具,提供了快速、灵活和富有表达力的数据结构,旨在简化数据操作和分析的过程。它基于NumPy库构建,可以处理结构化和时间序列数据,并提供了大量的数据操作和处理方法。
## 1.2 为什么要学习pandas
学习pandas有以下几个重要原因:
- 数据处理效率高:pandas采用了高性能的数据结构和算法,可以快速处理大规模数据集。
- 数据预处理工具:pandas提供了丰富的数据清洗和处理方法,可以处理缺失值、重复值、异常值等问题。
- 数据分析工具:pandas提供了丰富的统计分析工具,可以进行数据聚合、排序、透视表等操作。
- 数据可视化支持:pandas可以与其他数据可视化库(如Matplotlib和Seaborn)结合使用,进行数据可视化及结果展示。
## 1.3 安装pandas
要安装pandas,可以使用pip命令在命令行中执行以下命令:
```python
pip install pandas
```
或者通过Anaconda进行安装:
```python
conda install pandas
```
安装完成后,就可以在Python代码中引入pandas库并开始使用了。
以上是pandas简介章节的内容。在下一章节中,将详细介绍pandas的数据结构。
# 2. pandas的数据结构
pandas提供了两种主要的数据结构,即Series和DataFrame。它们是处理和分析数据的核心工具,具有灵活性和高效性。
### 2.1 Series
Series是一种类似于一维数组的数据结构,由一组数据和与之相关的标签(索引)组成。
#### 2.1.1 创建Series对象
```python
import pandas as pd
# 从列表创建Series
data = [1, 3, 5, 7]
s = pd.Series(data)
print(s)
# 指定索引创建Series
s = pd.Series(data, index=['a', 'b', 'c', 'd'])
print(s)
# 从字典创建Series
data = {'a': 1, 'b': 3, 'c': 5, 'd': 7}
s = pd.Series(data)
print(s)
```
**总结:** 通过`pd.Series`可以从列表或字典等数据结构创建Series对象,并可以指定索引。
#### 2.1.2 索引和切片
```python
# 通过索引访问元素
print(s[1])
print(s['b'])
# 切片操作
print(s[1:3])
print(s['b':'d'])
```
**总结:** 可以通过位置或标签进行索引和切片操作。
#### 2.1.3 数据操作和统计
```python
# 累加
print(s.cumsum())
# 最大最小值
print(s.max())
print(s.min())
# 均值和标准差
print(s.mean())
print(s.std())
```
**总结:** Series对象支持多种数据操作和统计方法,包括累加、最大最小值、均值、标准差等。
### 2.2 DataFrame
DataFrame是一个表格型的数据结构,它包含了一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
#### 2.2.1 创建DataFrame对象
```python
# 从字典创建DataFrame
data = {'name': ['Tom', 'Jerry', 'Mickey', 'Minnie'],
'age': [25, 30, 28, 27]}
df = pd.DataFrame(data)
print(df)
# 指定行索引和列名创建DataFrame
df = pd.DataFrame(data, index=['one', 'two', 'three', 'four'], columns=['name', 'age'])
print(df)
```
**总结:** 通过`pd.DataFrame`可以从字典等数据结构创建DataFrame对象,并可以指定行索引和列名。
#### 2.2.2 索引和切片
```python
# 通过列名访问列数据
print(df['name'])
# 通过行索引访问行数据
print(df.loc['one'])
```
**总结:** 可以通过列名或行索引进行数据的访问和操作。
#### 2.2.3 数据操作和统计
```python
# 数据转置
print(df.T)
# 描述性统计
print(df.describe())
# 列数据之间的相关性
print(df.corr())
```
**总结:** DataFrame对象支持数据转置、描述性统计、相关性分析等操作。
以上是pandas的基本数据结构和操作,下一章将介绍pandas的数据读取和写入功能。
# 3. pandas的数据读取和写入
pandas提供了丰富的方法来读取和写入不同格式的数据,包括CSV文件、Excel文件等。在数据分析和处理过程中,数据的读取和写入是非常重要的环节,接下来我们将介绍pandas中数据读取和写入的方法。
#### 3.1 读取CSV文件
在pandas中,可以通过`read_csv`方法来读取CSV文件。CSV(Comma-Separated Values)文件是一种常见的文本文件格式,广泛应用于数据存储和交换中。
```python
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
# 显示数据前几行
print(df.head())
```
**代码说明:**
- 首先导入pandas库,并将其重命名为`pd`。
- 使用`read_csv`方法读取名为`data.csv`的CSV文件,并将结果存储在DataFrame对象`df`中。
- 通过`head`方法显示DataFrame的前几行数据,默认显示前5行,可以通过参数指定显示行数。
**结果说明:**
- 打印出CSV文件的前几行数据。
#### 3.2 读取Excel文件
除了CSV文件,pandas也支持读取Excel文件。Excel文件是一种常见的电子表格格式,通过pandas可以方便地读取和处理。
```python
# 读取Excel文件
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')
# 显示数据前几行
print(df.head())
```
**代码说明:**
- 使用`read_excel`方法读取名为`data.xlsx`的Excel文件中的`Sheet1`表格,并将结果存储在DataFrame对象`df`中。
- 通过`head`方法显示DataFrame的前几行数据。
**结果说明:**
- 打印出Excel文件中Sheet1表格的前几行数据。
#### 3.3 写入CSV和Excel文件
通过pandas,我们也可以将数据写入到CSV和Excel文件中,以便进行数据的导出和共享。
```python
# 将数据写入CSV文件
df.to_csv('output.csv', index=False) # index=False表示不写入索引列
# 将数据写入Excel文件
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)
```
**代码说明:**
- 使用`to_csv`方法将DataFrame对象`df`中的数据写入到名为`output.csv`的CSV文件中,参数`index=False`表示不写入索引列。
- 使用`to_excel`方法将DataFrame对象`df`中的数据写入到名为`output.xlsx`的Excel文件中的`Sheet1`表格,参数`index=False`同样表示不写入索引列。
**结果说明:**
- 生成了`output.csv`和`output.xlsx`两个文件,其中包含了DataFrame对象`df`中的数据。
通过以上介绍,我们了解了pandas读取和写入数据的方法,这些功能使得数据的导入和导出变得非常简单,为后续的数据处理和分析提供了便利。
# 4. pandas的数据清洗和处理
pandas提供了丰富的功能来清洗和处理数据,包括处理缺失值、重复值、异常值,以及数据类型转换、数据合并和拆分等操作。
#### 4.1 缺失值处理
缺失值在实际数据分析中非常常见,pandas提供了多种方法来处理缺失值,包括删除、填充等操作。
```python
# 创建含有缺失值的DataFrame
import pandas as pd
import numpy as np
data = {'A': [1, 2, np.nan, 4], 'B': [5, np.nan, np.nan, 8], 'C': [np.nan, 12, 13, 14]}
df = pd.DataFrame(data)
# 删除含有缺失值的行
df.dropna()
# 填充缺失值
df.fillna(0) # 使用0填充缺失值
```
#### 4.2 重复值处理
重复值可能会影响数据分析的准确性,pandas提供了方法来检测和去除重复值。
```python
# 创建含有重复值的DataFrame
data = {'A': [1, 1, 2, 3], 'B': [4, 4, 5, 6], 'C': [7, 7, 8, 9]}
df = pd.DataFrame(data)
# 检测重复值
df.duplicated()
# 去除重复值
df.drop_duplicates()
```
#### 4.3 异常值处理
异常值可能会对数据分析结果产生影响,pandas可以通过统计方法来识别和处理异常值。
```python
# 创建含有异常值的DataFrame
data = {'A': [1, 2, 3, 100], 'B': [5, 6, 7, 200]}
df = pd.DataFrame(data)
# 根据均值和标准差识别异常值
mean = df['A'].mean()
std = df['A'].std()
threshold = 3 # 一般取3倍标准差
df[(df['A'] - mean) > threshold * std]
```
#### 4.4 数据类型转换
在数据处理过程中,经常需要将数据类型进行转换,pandas可以轻松实现数据类型转换。
```python
# 创建DataFrame并进行数据类型转换
data = {'A': ['1', '2', '3'], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 将A列转换为整型
df['A'] = df['A'].astype(int)
```
#### 4.5 数据合并和拆分
数据合并和拆分是数据处理中常见的操作,pandas提供了丰富的方法来实现数据的合并和拆分。
```python
# 创建两个DataFrame并进行合并和拆分
data1 = {'A': [1, 2, 3], 'B': [4, 5, 6]}
data2 = {'A': [7, 8, 9], 'B': [10, 11, 12]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 合并两个DataFrame
pd.concat([df1, df2])
# 按照指定条件拆分DataFrame
split_criteria = df['A'] > 2
df1 = df[split_criteria]
df2 = df[~split_criteria]
```
通过以上方法,可以轻松地进行数据清洗和处理,使数据更具有准确性和可分析性。
# 5. pandas的数据分析和可视化
pandas提供了丰富的数据分析和可视化功能,可以帮助用户更好地理解和分析数据。本章节将介绍pandas中数据分组和聚合、数据排序和排名、数据透视表以及数据可视化的操作方法。
#### 5.1 数据分组和聚合
在数据分析中,通常需要对数据进行分组和聚合,pandas提供了`groupby()`函数来实现数据分组,并且支持各种聚合操作。下面是一个示例:
```python
import pandas as pd
# 创建DataFrame对象
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emma'],
'Age': [25, 30, 35, 30, 28],
'Salary': [50000, 60000, 80000, 55000, 62000],
'Department': ['HR', 'Engineering', 'Engineering', 'HR', 'Marketing']}
df = pd.DataFrame(data)
# 按部门分组,计算平均薪资
avg_salary = df.groupby('Department')['Salary'].mean()
print(avg_salary)
```
这段代码展示了如何使用`groupby()`函数按部门分组,并计算各部门的平均薪资。
#### 5.2 数据排序和排名
pandas也提供了丰富的排序和排名方法,可以帮助用户快速整理和分析数据。下面是一个示例:
```python
# 按年龄降序排列
sorted_data = df.sort_values(by='Age', ascending=False)
print(sorted_data)
# 计算薪资排名
df['Salary_Rank'] = df['Salary'].rank(ascending=False)
print(df)
```
这段代码展示了如何使用`sort_values()`方法按年龄降序排列数据,以及如何使用`rank()`方法计算薪资排名。
#### 5.3 数据透视表
数据透视表是数据分析中常用的工具,可以帮助用户对数据进行多维度的分析和汇总。pandas提供了`pivot_table()`函数来实现数据透视表的功能。下面是一个示例:
```python
# 创建数据透视表,计算各部门的平均薪资和平均年龄
pivot = df.pivot_table(index='Department', values=['Salary', 'Age'], aggfunc='mean')
print(pivot)
```
这段代码展示了如何使用`pivot_table()`函数创建数据透视表,计算各部门的平均薪资和平均年龄。
#### 5.4 数据可视化
除了数据分析之外,pandas还提供了数据可视化的功能,可以帮助用户直观地展现数据分布和趋势。下面是一个简单的数据可视化示例:
```python
import matplotlib.pyplot as plt
# 绘制薪资分布直方图
plt.hist(df['Salary'], bins=3)
plt.xlabel('Salary')
plt.ylabel('Frequency')
plt.title('Salary Distribution')
plt.show()
```
这段代码展示了如何使用matplotlib库来绘制薪资的分布直方图,从而对薪资分布进行可视化展现。
以上是关于pandas数据分析和可视化的简要介绍,读者可以根据实际需求进一步深入学习和应用。
# 6. pandas的高级应用
在前面的章节中,我们已经学习了pandas库的基本用法,包括数据结构、数据读取和写入、数据清洗和处理,以及数据分析和可视化。在本章中,我们将深入探讨pandas的高级应用。
#### 6.1 多层索引
pandas的多层索引(MultiIndex)提供了一种在DataFrame中处理高维数据的方式。通过多层索引,我们可以将数据分层次组织,实现更复杂的数据分析和操作。
##### 6.1.1 创建多层索引
要创建多层索引,可以使用`pd.MultiIndex`类,并将其作为DataFrame或Series的索引。下面的示例演示了如何创建一个带有两个级别的多层索引:
```python
import pandas as pd
# 创建一个多层索引
index = pd.MultiIndex.from_tuples([('A', 'a'), ('A', 'b'), ('B', 'a'), ('B', 'b')])
```
##### 6.1.2 索引和切片
使用多层索引进行索引和切片操作有一些特殊的用法。要根据多层索引进行索引,可以使用`loc`方法。下面的示例演示了如何使用多层索引进行索引和切片操作:
```python
# 创建一个带有多层索引的DataFrame
data = {'value': [1, 2, 3, 4]}
df = pd.DataFrame(data, index=index)
# 根据多层索引进行索引和切片
print(df.loc['A']) # 获取'A'级别的数据
print(df.loc[('A', 'a')]) # 获取('A', 'a')的数据
print(df.loc['A':'B']) # 获取'A'到'B'级别的数据
```
##### 6.1.3 数据操作和统计
在处理多层索引的DataFrame时,我们可以使用各种操作和统计函数。下面的示例演示了如何对多层索引的DataFrame进行操作和统计:
```python
# 创建一个带有多层索引的DataFrame
data = {'value': [1, 2, 3, 4]}
df = pd.DataFrame(data, index=index)
# 操作和统计
print(df.sum(level=0)) # 对第一级索引进行求和
print(df.mean(level=1)) # 对第二级索引进行求平均值
print(df.groupby(level=0).count()) # 对第一级索引进行分组计数
```
#### 6.2 时间序列数据处理
pandas提供了丰富的功能来处理时间序列数据。通过将时间作为索引,我们可以轻松地进行各种时间相关的操作。
##### 6.2.1 创建时间序列
要创建时间序列,可以使用`pd.date_range`函数。下面的示例演示了如何创建一个时间序列:
```python
import pandas as pd
# 创建一个时间序列
time_index = pd.date_range('2020-01-01', periods=5, freq='D')
```
##### 6.2.2 时间戳索引
在处理时间序列数据时,我们可以使用时间戳作为索引,以便更容易地进行时间相关的操作。下面的示例演示了如何使用时间戳索引:
```python
# 创建一个带有时间戳索引的Series
data = [1, 2, 3, 4]
ts = pd.Series(data, index=time_index)
# 时间戳索引的操作和统计
print(ts['2020-01-01'])
print(ts['2020-01-01':'2020-01-03'])
print(ts.resample('W').sum())
```
##### 6.2.3 移动窗口函数
pandas提供了一些移动窗口函数,可以方便地进行滚动计算。下面的示例演示了如何使用移动窗口函数:
```python
# 创建一个带有时间戳索引的Series
data = [1, 2, 3, 4]
ts = pd.Series(data, index=time_index)
# 移动窗口函数
print(ts.rolling(window=2).sum()) # 计算滚动和
print(ts.rolling(window=3).mean()) # 计算滚动均值
```
#### 6.3 扩展应用:数据预处理与特征工程
除了基本的数据处理功能,pandas还支持一些高级的数据预处理和特征工程技术。这些技术可以帮助我们更好地理解数据、处理缺失值和异常值、进行特征选择和构造等。
在这一章节中,我们将介绍一些常用的数据预处理和特征工程技术,并展示如何使用pandas来实现它们。以下是一些常见的技术:
- 特征缩放
- 数据归一化和标准化
- 数据平滑和去噪
- 数据编码和哑变量处理
- 数据降维和特征选择
- 特征构造和衍生
这些技术可以根据不同的数据情况和分析目标来灵活应用,提高数据分析的精度和效率。
到此为止,我们已经完成了关于pandas的入门教程。希望本教程能够帮助你快速掌握pandas库的使用,提高数据处理和分析的能力。如果你对pandas的更多高级功能感兴趣,可以参考pandas官方文档和其他相关资料,深入学习和探索。祝你在数据领域取得更多的成果!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《python进阶课程-数据分析库pandas》是一门针对想要深入学习数据分析的python开发者的专栏。该专栏涵盖了从入门到高级的各种主题,包括数据结构和基本操作、数据筛选和过滤技巧、常见数据清洗技术、向量化操作的优势、数据聚合与分组操作、时间序列数据处理、数据合并与连接方法、数据透视表应用技巧、数据统计与描述性分析、数据可视化技术应用等。专栏中还涵盖了实际应用场景的案例,例如处理大规模数据集和进行机器学习数据预处理。此外,专栏还深入剖析了高级分析函数的应用和数据索引与选择技术。通过学习该专栏,读者将能够掌握pandas库的各种高级技术和最佳实践,从而提升数据分析的能力和效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyQt5界面布局全实战:QStackedLayout的高级应用秘籍
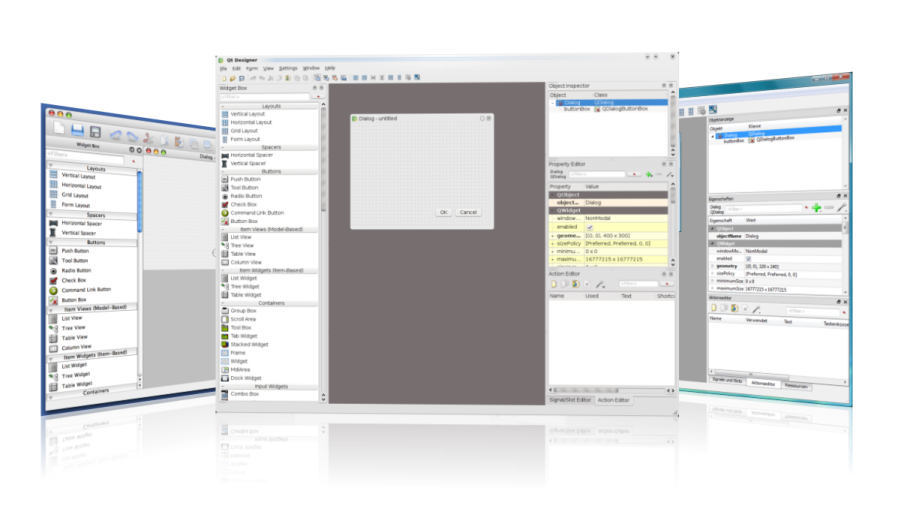
# 摘要
PyQt5的QStackedLayout是一种强大的界面布局管理工具,它允许开发者通过堆叠的方式管理多个界面元素,从而创建出具有多视图和动态交互的复杂应用程序。本文首先介绍了PyQt5和QStackedLayout的基础知识,随后深入探讨了QStackedLayout的布局原理、界面设计原则及高级特性。通过实战案例,本文展示了如何在具体项目中应用QStackedLayout,包括界
递归功能在MySQL中的扩展:自定义函数的全面解析
# 摘要
本文全面介绍了MySQL中的递归功能,从理论基础到实际应用,详细阐述了递归的概念、重要性以及递归模型的实现和性能考量。文章深入分析了自定义函数在MySQL中的实现方式,结合递归逻辑的设计原则和高级特性,为构建复杂的树状结构和图数据提供了具体的应用案例。同时,本文还探讨了递归功能的性能优化和安全维护的最佳实践,并对未来递归功能和自定义函数的发展趋势进行了展望。
# 关键字
MySQL;递归查询;自定义函数;性能优化;树状结构;图数据处理
参考资源链接:[MySQL自定义函数实现无限层级递归查询](https://wenku.csdn.net/doc/6412b537be7fbd17
日常监控与调整:提升 MATRIX加工中心性能的黄金法则
# 摘要
加工中心性能的提升对于制造业的效率和精度至关重要。本文首先介绍了监控与调整的重要性,并阐述了加工中心的基本监控原理,包括监控系统的分类和关键性能指标的识别。其次,文中探讨了提升性能的实践策略,涉及机床硬件升级、加工参数优化和软件层面的性能提升。本文还探讨了高级监控技术的应用,如自动化监控系统的集成、数据分析和与ERP系统的整合。案例研究部分深入分析了成功实施性能提升的策略与效果。最后,本文展望了加工中心技术的发展趋势,并提出创新思路,包括智能制造的影响、监控技术的新方向以及长期性能管理的策略。
# 关键字
加工中心性能;监控系统;性能优化;自动化监控;数据分析;智能制造
参考资源
【用户体验评测】:如何使用UXM量化5GNR网络性能

# 摘要
本文探讨了5GNR网络下的用户体验评测理论和实践,重点阐述了用户体验的多维度理解、5GNR关键技术对用户体验的影响,以及评测方法论。文章介绍了UXM工具的功能、特点及其在5GNR网络性能评测中的应用,并通过实际评测场景的搭建和评测流程的实施,深入分析了性能评测结果,识别性能瓶颈,并提出了优化建议。最后,探讨了网络性能优化策略、UXM评测工具的发展趋势以及5GNR网络技术的未来展望,强调了用户体验评测在5G
【Oracle 12c新功能】:升级前的必备功课,确保你不会错过

# 摘要
Oracle 12c作为一款先进的数据库管理系统,引入了多项创新功能来提升数据处理能力、优化性能以及增强安全性。本文从新功能概览开始,深度解析了其革新性的多租户架构、性能管理和安全审计方面的改进。通过对新架构(CDB/PDB)、自适应执行计划的优化和透明数据加密(TDE)等功能的详细剖析,展示了Oracle 12c如何
【数控车床维护关键】:马扎克MAZAK-QTN200的细节制胜法

# 摘要
本文全面介绍了马扎克MAZAK-QTN200数控车床的维护理论与实践。文章从数控车床的工作原理和维护基本原则讲起,强调了预防性维护和故障诊断的重要性。接着,文章深入探讨了日常维护、定期深度维护以及关键部件保养的具体流程和方法。在专项维护章节中,重点介绍了主轴、刀塔、进给系统、导轨以及传感器与测量系统的专项维护技术。最后
无人机航测数据融合与分析:掌握多源数据整合的秘诀
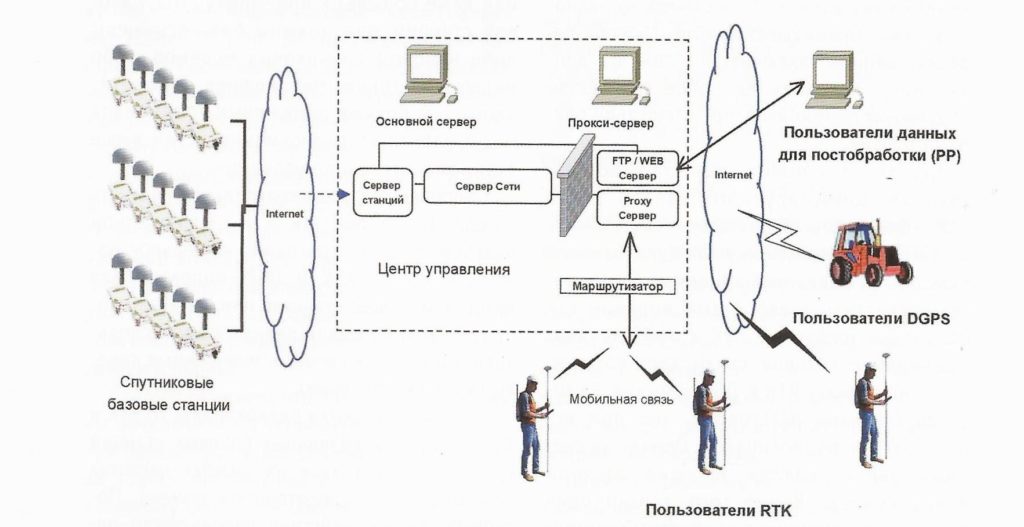
# 摘要
无人机航测数据融合与分析是遥感技术发展的关键领域,该技术能够整合多源数据,提高信息提取的精确度与应用价值。本文从理论基础出发,详述了数据融合技术的定义、分类及方法,以及多源数据的特性、处理方式和坐标系统的选择。进而,文章通过实践层面,探讨了无人机航测数据的预处理、标准化,融合算法的选择应用以及融合效果的评估与优化。此外,本文还介绍了一系列无人机航测数据分析方法,
【性能调优技巧】:Oracle塑性区体积计算实战篇
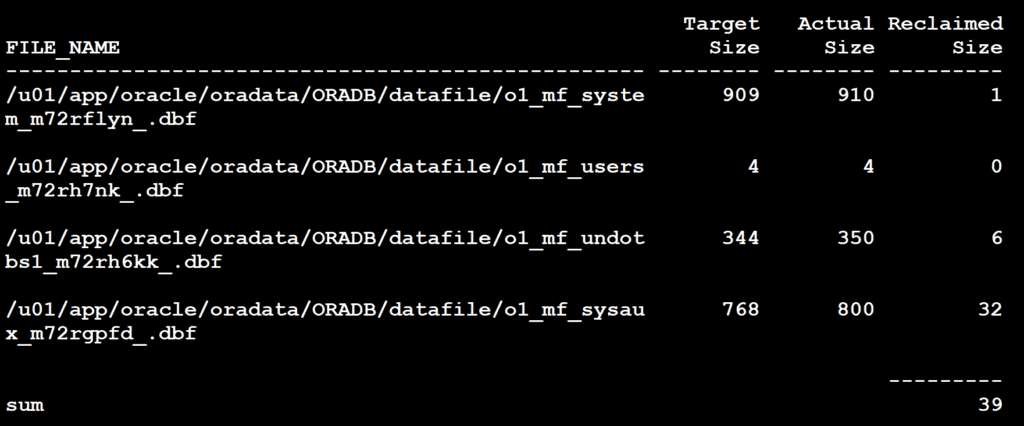
# 摘要
本论文详细探讨了Oracle数据库中塑性区体积计算的基础知识与高级调优技术。首先,介绍了塑性区体积计算的基本理论和实践方法,随后深入研究了Oracle性能调优的理论基础,包括系统资源监控和性能指标分析。文章重点论述了数据库设计、SQL性能优化、事务和锁管理的策略,以及内存管理优化、CPU和I/O资源调度技术。通过案例研究,本文分析了真实
现代测试方法:电气机械性能评估与质量保证,全面指南
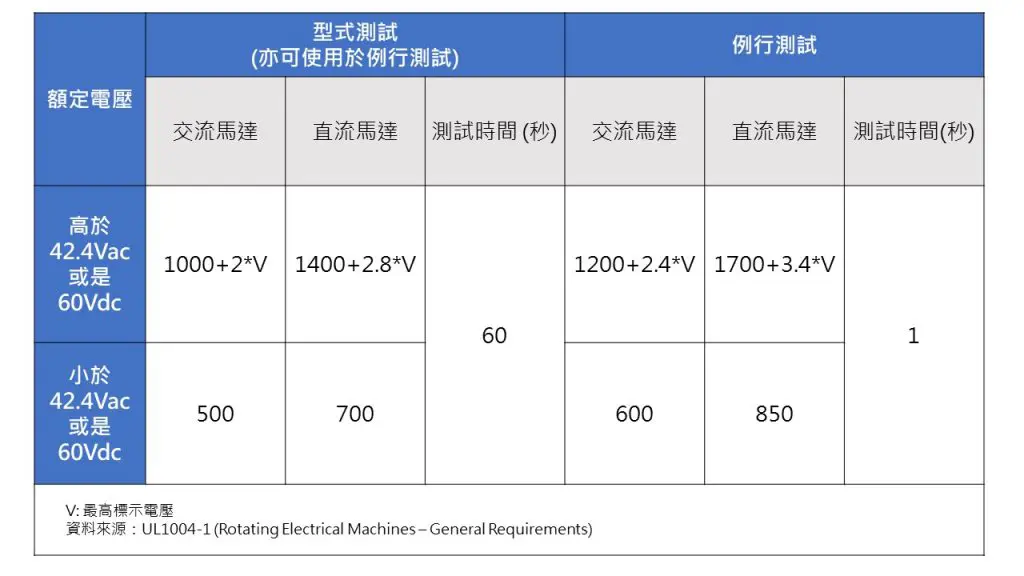
# 摘要
本文从电气机械性能评估的基础知识出发,详细探讨了电气性能与机械性能测试的方法与实践,包括理论基础、测试程序、以及案例分析。文章进一步阐述了电气与机械性能的联合评估理论框架及其重要性,并通过测试案例展示如何设计与执行联合性能测试,强调了数据采集与处理的关键性。最后,文章介绍了质量保证体系在电气机械评估中的应用,并探讨了质量改进策略与实施。通过对未来趋势的
软件工程可行性分析中的风险评估与管理

# 摘要
软件工程中的可行性分析和风险管理是确保项目成功的关键步骤。本文首先概述了软件工程可行性分析的基本概念,随后深入探讨风险评估的理论基础,包括风险的定义、分类、评估目标与原则,以及常用的风险识别方法和工具。接着,文章通过实际案例,分析了风险识别过程及其在软件工程项目中的实践操作,并探讨了风险评估技术的应用。此外,本文还讨论
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )