扩展API与插件系统深入探究:Psycopg2.extensions高级功能揭秘
发布时间: 2024-10-16 12:45:51 阅读量: 19 订阅数: 23 

# 1. Psycopg2.extensions模块概述
Psycopg2 是一个用于 PostgreSQL 数据库的 Pythonic PostgreSQL 适配器,它允许 Python 程序使用 PostgreSQL 数据库。`psycopg2.extensions` 模块是 Psycopg2 的核心部分之一,提供了许多重要的功能和扩展,使得 Python 代码能够更好地与 PostgreSQL 数据库交互。
## 理解 Psycopg2.extensions 模块
### 核心功能概述
`psycopg2.extensions` 模块提供了以下几个核心功能:
1. **连接扩展**:用于建立和管理数据库连接。
2. **数据类型扩展**:支持自定义数据类型的注册和使用。
3. **游标扩展**:提供了额外的游标操作和性能优化。
### 连接扩展
连接扩展主要关注于数据库连接的建立和管理。它允许用户自定义连接类,处理连接参数,并提供了事务控制的高级应用。
### 数据类型扩展
数据类型扩展使得用户可以自定义和注册新的数据类型,例如数组、JSON 和自定义范围类型,同时还能实现类型转换器以支持数据类型的自动转换。
### 游标扩展
游标扩展提供了游标的高级属性和方法,比如批量操作优化、缓冲和非缓冲模式的选择,以及异常处理和事务回滚的高级用法。
### 示例代码
```python
import psycopg2
from psycopg2 import extensions
# 示例:连接 PostgreSQL 数据库
conn = psycopg2.connect(
dbname="example_db",
user="example_user",
password="example_password"
)
# 示例:注册一个新的数据类型
class MyRangeType(psycopg2.extensions.RangeType):
pass
# 示例:使用自定义游标
cur = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
# 执行查询
cur.execute("SELECT * FROM my_table")
# 获取查询结果
rows = cur.fetchall()
for row in rows:
print(row)
# 关闭连接
cur.close()
conn.close()
```
通过以上代码示例,我们可以看到如何使用 `psycopg2.extensions` 模块中的功能来连接数据库、注册自定义数据类型以及使用自定义游标。这些功能为开发人员提供了灵活的数据库操作接口,使得与 PostgreSQL 数据库的交互更加高效和方便。
# 2. 深入理解Psycopg2.extensions的连接扩展
Psycopg2.extensions模块是Psycopg2库中的一个重要组成部分,它提供了一系列的扩展功能,用于优化和增强数据库连接的操作。在本章节中,我们将深入探讨这个模块,特别是其在连接扩展方面的应用。
## 2.1 连接对象的自定义扩展
### 2.1.1 创建自定义连接类
在Psycopg2中,连接对象是通过`connect`方法创建的,但有时候我们需要对连接对象进行更细粒度的控制,这时候我们可以创建自定义的连接类。下面是一个简单的例子,展示了如何定义一个自定义连接类:
```python
import psycopg2
from psycopg2 import extensions
class CustomConnection(psycopg2.extensions.connection):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 在这里添加自定义的初始化代码
def custom_method(self):
# 添加自定义的方法
pass
```
在这个例子中,我们继承了`psycopg2.extensions.connection`类,并添加了一个自定义的方法`custom_method`。这允许我们在连接对象上添加额外的功能,例如日志记录、自定义异常处理等。
### 2.1.2 连接参数的高级处理
在创建连接时,我们通常会使用`connect`方法并传入一些参数。Psycopg2允许我们通过自定义连接类来处理这些参数,从而实现更复杂的逻辑。例如,我们可以验证参数的合法性,或者根据参数动态地调整连接设置。
```python
def custom_connect(*args, **kwargs):
# 验证参数
if 'user' not in kwargs:
raise ValueError("Missing 'user' in connection parameters")
# 在这里可以添加更多参数处理逻辑
conn = psycopg2.connect(*args, **kwargs)
return CustomConnection(conn)
```
在这个例子中,我们定义了一个`custom_connect`函数,它在创建连接之前验证了必须的`user`参数是否存在。这是一个简单的参数处理示例,但在实际应用中,你可能需要根据实际需求实现更复杂的逻辑。
## 2.2 事务控制的高级应用
### 2.2.1 事务的隔离级别
在数据库操作中,事务的隔离级别是一个重要概念。它定义了一个事务可能受其他并发事务影响的程度。在Psycopg2中,我们可以通过设置连接的`isolation_level`属性来控制事务的隔离级别。
```python
import psycopg2.extensions
# 设置隔离级别为SERIALIZABLE
conn = psycopg2.connect('dbname=test user=postgres')
conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_SERIALIZABLE)
```
在这个例子中,我们将连接的隔离级别设置为`ISOLATION_LEVEL_SERIALIZABLE`,这是最高的隔离级别,可以避免脏读、不可重复读和幻读的问题。
### 2.2.2 保存点的创建和使用
保存点(Savepoint)是一种允许在事务中创建一个或多个中间状态的技术,这对于长事务的管理和错误恢复非常有用。在Psycopg2中,我们可以使用保存点来管理事务。
```python
import psycopg2
conn = psycopg2.connect('dbname=test user=postgres')
conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)
cursor = conn.cursor()
cursor.execute("INSERT INTO test (data) VALUES (%s)", ('data',))
# 创建保存点
savepoint_cursor = conn.cursor()
savepoint_cursor.execute("SAVEPOINT my_savepoint")
try:
cursor.execute("INSERT INTO test (data) VALUES (%s)", ('more data',))
except psycopg2.Error:
# 发生错误时回滚到保存点
savepoint_cursor.execute("ROLLBACK TO SAVEPOINT my_savepoint")
savepoint_cursor.close()
finally:
# 关闭保存点
savepoint_cursor.close()
```
在这个例子中,我们首先创建了一个连接和游标,然后在事务中插入了一些数据,并创建了一个保存点。如果在后续操作中发生异常,我们回滚到保存点,而不是回滚整个事务。
## 2.3 连接池的管理与优化
### 2.3.1 连接池的创建和配置
连接池是一种管理数据库连接的模式,它可以提高应用程序的性能和资源利用率。Psycopg2提供了一个`psycopg2.pool`模块,用于创建和管理连接池。
```python
import psycopg2.pool
class MyConnectionPool(psycopg2.pool.SimpleConnectionPool):
def __init__(self, minconn, maxconn, *args, **kwargs):
super().__init__(minconn, maxconn, *args, **kwargs)
# 在这里添加自定义的初始化代码
def getconn(self, *args, **kwargs):
conn = super().getconn(*args, **kwargs)
# 在这里可以添加获取连接时的自定义逻辑
return conn
pool = MyConnectionPool(minconn=1, maxconn=10, database='test', user='postgres')
```
在这个例子中,我们继承了`SimpleConnectionPool`类,并添加了一个自定义的初始化方法。这允许我们在创建连接池时添加额外的功能,例如日志记录、自定义异常处理等。
### 2.3.2 连接池性能的监控与调优
连接池的性能监控和调优是确保应用程序稳定运行的关键。我们可以通过记录连接的使用情况、监控连接池的状态等手段来实现这一点。
```python
from psycopg2.pool import AdvisoryLock
import time
def monitor_pool(pool, interval=1):
with AdvisoryLock(pool, 'monitor_lock') as lock:
while True:
print(f"Active connections: {pool.get_status().get('active', 0)}")
print(f"Idle connections: {pool.get_status().get('idle', 0)}")
print(f"Waiting connections: {pool.get_status().get('waiting', 0)}")
time.sleep(interval)
monitor_thread = threading.Thread(target=monitor_pool, args=(pool,))
monitor_thread.start()
```
在这个例子中,我们定义了一个`monitor_pool`函数,它会周期性地打印连接池的状态。这是连接池性能监控的一个简单示例,但在实际应用中,你可能需要根据实际需求实现更复杂的逻辑。
通过本章节的介绍,我们了解了Psycopg2.extensions模块在连接扩展方面的应用,包括创建自定义连接类、处理连接参数、事务的隔离级别、保存点的使用以及连接池的管理和优化。这些知识对于深入理解和使用Psycopg2库,以及构建高性能的数据库应用是非常有帮助的。
# 3. Psycopg2.extensions的数据类型扩展
在本章节中,我们将深入探讨Psycopg2.extensions模块中的数据类型扩展功能。这一部分对于理解如何在使用Psycopg2时扩展和自定义数据类型至关重要,尤其是在处理特定数据库类型如数组、JSON等时。我们将从自定义数据类型的注册开始,逐步深入到高级数据类型的应用场景,最后讨论数据类型转换器的实现。
## 3.1 自定义数据类型的注册
### 3.1.1 创建自定义数据类型
在数据库交互中,有时我们需要处理一些非标准的数据类型,比如自定义的数据结构或者特定格式的数据。在Psycopg2中

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Psycopg2.extensions 库,该库为 Python 与 PostgreSQL 数据库之间的交互提供了高级功能。从连接优化到错误处理,再到性能优化和安全最佳实践,本专栏涵盖了 10 大技巧,帮助您掌握 PostgreSQL 连接和优化。此外,还对 Psycopg2.extensions 源代码进行了深入分析,揭示了构建 PostgreSQL 连接适配器的秘籍。通过使用数据库连接池和类型转换攻略,您将学习如何提升效率和简化数据交互。本专栏还提供了线程安全实现和 Web 应用集成案例,帮助您在实际应用中应用这些技巧。通过遵循本专栏,您将掌握使用 Psycopg2.extensions 库进行高效、安全且可扩展的 PostgreSQL 连接和交互。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
拷贝构造函数的陷阱:防止错误的浅拷贝
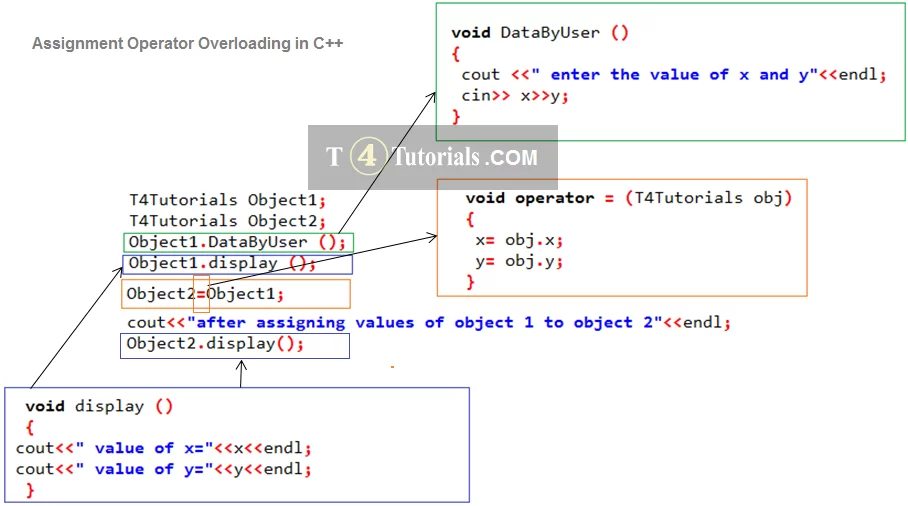
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
【设计的艺术】:CBAM模块构建,平衡复杂度与性能提升
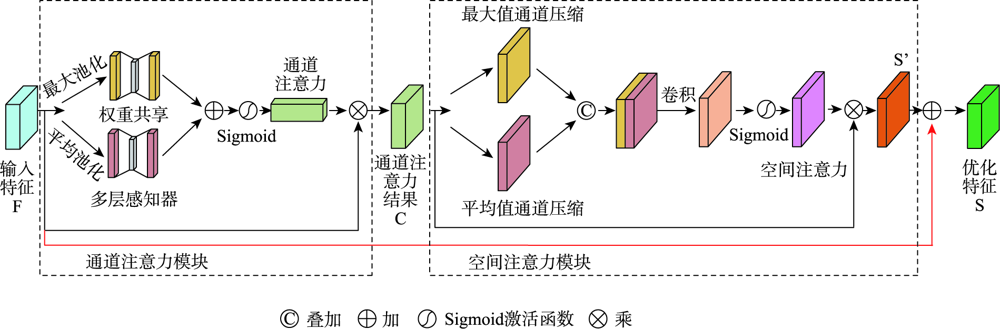
# 1. CBAM模块概述
在深度学习领域,CBAM(Convolutional Block Attention Module)模块已经成为一种重要的神经网络组件,主要用于提升网络对特征的注意力集中能力,进而改善模型的性能。本章将带您初步了解CBAM模块的含义、工作原理以及它在各种应用中的作用。通过对CBAM模块的概述,我们将建立对这一技术的基本认识,为后续章节深入探讨
消息队列在SSM论坛的应用:深度实践与案例分析

# 1. 消息队列技术概述
消息队列技术是现代软件架构中广泛使用的组件,它允许应用程序的不同部分以异步方式通信,从而提高系统的可扩展性和弹性。本章节将对消息队列的基本概念进行介绍,并探讨其核心工作原理。此外,我们会概述消息队列的不同类型和它们的主要特性,以及它们在不同业务场景中的应用。最后,将简要提及消息队列
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
【MATLAB在Pixhawk定位系统中的应用】:从GPS数据到精确定位的高级分析

# 1. Pixhawk定位系统概览
Pixhawk作为一款广泛应用于无人机及无人车辆的开源飞控系统,它在提供稳定飞行控制的同时,也支持一系列高精度的定位服务。本章节首先简要介绍Pixhawk的基本架构和功能,然后着重讲解其定位系统的组成,包括GPS模块、惯性测量单元(IMU)、磁力计、以及_barometer_等传感器如何协同工作,实现对飞行器位置的精确测量。
我们还将概述定位技术的发展历程,包括
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )