必看!深入理解Psycopg2.extensions:数据库连接的高级秘密
发布时间: 2024-10-16 11:31:49 阅读量: 29 订阅数: 23 

# 1. Psycopg2.extensions简介
## 简介
Psycopg2 是一个 PostgreSQL 数据库适配器,而 Psycopg2.extensions 模块是 Psycopg2 的核心部分,提供了一系列的功能来扩展和增强数据库连接的行为。这个模块对于理解如何高效地与 PostgreSQL 数据库交互至关重要。
## 功能概述
Psycopg2.extensions 模块主要提供了以下几个方面的功能:
1. **连接扩展**:通过注册扩展的转换器和类型,能够处理 Python 中自定义类型的数据库存储和检索。
2. **事务控制**:提供了对数据库事务控制的细粒度管理,包括嵌套事务的支持。
3. **上下文管理**:通过上下文管理器,可以确保资源的正确分配和释放,简化代码并提高效率。
## 重要组件
该模块中最重要的组件包括:
- **连接工厂**:用于创建数据库连接,可以配置连接参数。
- **游标**:用于执行查询和管理数据库事务。
- **转换器**:将 Python 数据类型转换为 PostgreSQL 支持的数据类型,反之亦然。
## 使用场景
了解 Psycopg2.extensions 模块对于想要深入使用 Psycopg2 进行数据库操作的开发者来说是必不可少的。无论是在创建自定义的数据类型映射,还是在处理复杂的数据库事务时,这个模块都能提供强大的支持。
通过本章的学习,你将掌握 Psycopg2.extensions 模块的基本概念和核心功能,为进一步学习如何使用 Psycopg2 进行高级数据库操作打下坚实的基础。
# 2. 数据库连接管理
在本章节中,我们将深入探讨如何在使用Psycopg2时进行数据库连接管理。这包括建立和维护数据库连接的各个方面,如连接池的创建和管理,以及如何正确关闭和清理连接资源。此外,我们还将讨论在数据库操作中不可避免的错误处理和重连策略,确保数据库操作的健壮性和稳定性。
## 2.1 连接数据库
### 2.1.1 建立数据库连接
建立数据库连接是使用Psycopg2的第一步。通常,我们使用`psycopg2.connect()`函数来创建一个数据库连接。这个函数接受一个包含数据库连接参数的字典作为输入,返回一个连接对象。
```python
import psycopg2
# 数据库连接参数
conn_params = {
'dbname': 'your_database',
'user': 'your_username',
'password': 'your_password',
'host': 'localhost',
'port': 5432,
}
# 建立数据库连接
conn = psycopg2.connect(**conn_params)
```
在上述代码中,我们首先导入了`psycopg2`模块,并定义了一个包含数据库连接参数的字典`conn_params`。然后,我们使用`psycopg2.connect()`函数并通过`**conn_params`语法将参数字典传递给该函数,创建了一个数据库连接`conn`。
### 2.1.2 连接池的创建和管理
连接池是一种管理数据库连接的技术,它可以提高应用程序的性能和资源利用率。Psycopg2通过`psycopg2.pool`模块提供了连接池的支持。
```python
from psycopg2 import pool
# 创建一个连接池对象
minconn = 1 # 最小连接数
maxconn = 6 # 最大连接数
pool_size = maxconn - minconn + 1
threaded = True # 是否支持多线程
pool conn_pool = psycopg2.pool.SimpleConnectionPool(minconn, maxconn, conn_params,
threadafety=threaded)
# 从连接池获取一个连接
conn = conn_pool.getconn()
# 使用完毕后,将连接还回连接池
conn_pool.putconn(conn)
```
在上述代码中,我们首先从`psycopg2`模块导入了`pool`模块,并创建了一个`SimpleConnectionPool`对象`conn_pool`。这个对象负责管理最小和最大连接数,并提供线程安全的支持。我们通过调用`conn_pool.getconn()`和`conn_pool.putconn()`方法来从连接池中获取和释放数据库连接。
## 2.2 关闭和清理连接
### 2.2.1 正确关闭连接
在完成数据库操作后,我们应该正确关闭数据库连接。这不仅可以释放服务器端资源,还可以避免潜在的连接泄露。
```python
# 关闭连接
if conn is not None:
conn.close()
```
在上述代码中,我们首先检查连接`conn`是否为`None`。如果连接存在,我们调用`conn.close()`方法来关闭连接。
### 2.2.2 清理资源的最佳实践
除了关闭连接之外,我们还应该确保释放所有相关的资源,如游标和结果集。
```python
# 使用try/finally确保资源释放
try:
# 执行数据库操作
pass
finally:
# 清理资源
if conn is not None:
conn.close()
if cursor is not None:
cursor.close()
```
在上述代码中,我们使用了`try/finally`语句块来确保即使在发生异常时也能释放资源。在`finally`块中,我们关闭了连接`conn`和游标`cursor`。
## 2.3 错误处理和重连策略
### 2.3.1 错误处理机制
Psycopg2提供了错误处理机制,可以通过捕获异常来处理数据库操作中可能发生的错误。
```python
try:
# 执行可能引发异常的数据库操作
pass
except psycopg2.DatabaseError as e:
# 处理数据库错误
print(f"Database error: {e}")
```
在上述代码中,我们使用`try/except`语句块来捕获`psycopg2.DatabaseError`异常。如果在数据库操作中发生错误,我们将捕获该异常并打印错误信息。
### 2.3.2 自动重连策略实现
为了提高应用程序的健壮性,我们可以实现一个自动重连策略。这通常涉及到在捕获到特定异常后重新建立连接,并重试数据库操作。
```python
import time
def execute_with_retry(func, retries=3, delay=2):
for i in range(retries):
try:
return func()
except (psycopg2.OperationalError, psycopg2.InterfaceError) as e:
if i < retries - 1:
time.sleep(delay)
print(f"Retrying after {delay} seconds... (Attempt {i+2}/{retries})")
else:
raise
# 使用重连策略执行数据库操作
try:
execute_with_retry(lambda: cursor.execute("SELECT * FROM your_table"))
except Exception as e:
print(f"Failed to execute query: {e}")
```
在上述代码中,我们定义了一个名为`execute_with_retry`的函数,它接受一个执行数据库操作的函数`func`、重试次数`retries`和每次重试之间的延迟时间`delay`作为参数。该函数尝试执行传入的函数,并在捕获到数据库操作错误时进行重试,直到达到最大重试次数或操作成功。我们还展示了如何使用这个重连策略来执行一个简单的查询。
通过本章节的介绍,我们了解了如何在Psycopg2中建立和管理数据库连接,包括连接池的创建和管理,以及错误处理和重连策略的实现。这些知识对于构建高性能和高可靠性的数据库应用程序至关重要。在接下来的章节中,我们将深入探讨如何进行类型转换和注册,以及如何执行高级数据库操作。
# 3. 类型转换和注册
## 3.1 数据类型转换
### 3.1.1 默认类型映射
在使用Psycopg2进行数据库操作时,我们经常会遇到数据类型转换的问题。Psycopg2为常见的Python数据类型和PostgreSQL的数据类型提供了默认的映射关系。例如,Python的`int`类型会自动映射到PostgreSQL的`INTEGER`类型,Python的`str`类型会映射到PostgreSQL的`TEXT`类型等。这种默认映射简化了开发过程,使得开发者无需为每一种数据类型编写转换代码。
默认类型映射表:
| Python类型 | PostgreSQL类型 |
|------------|----------------|
| int | INTEGER |
| str | TEXT |
| float | FLOAT |
| bool | BOOLEAN |
| list | ARRAY |
### 3.1.2 自定义数据类型转换
在某些情况下,默认的类型映射可能不满足我们的需求,此时我们可以自定义数据类型转换。自定义转换可以通过实现`register_type()`函数来完成。例如,我们可能希望将Python的`datetime`类型直接转换为PostgreSQL的`TIMESTAMP`类型,而不是默认的`TEXT`类型。
自定义类型转换的代码示例如下:
```python
import psycopg2
from psycopg2.extras import register_type
from psycopg2.extensions import register_adapter
from datetime import datetime
# 自定义转换器
class DateTimeAdapter:
def __init__(self, val):
self.val = val
def getquoted(self):
return "'{}'::TIMESTAMP".format(self.val.strftime("%Y-%m-%d %H:%M:%S"))
# 注册适配器
register_adapter(datetime, DateTimeAdapter)
# 注册转换器
register_type(psycopg2.extensions.new_type(
psycopg2.extensions.DECIMAL.adapt_types,
"TIMESTAMP", lambda val: val[1]))
# 使用自定义转换器
conn = psycopg2.connect('dbname=test user=postgres')
cur = conn.cursor()
cur.execute("SELECT '2023-04-01 12:00:00'::TIMESTAMP")
print(cur.fetchone()[0]) # 输出: 2023-04-01 12:00:00
# 关闭连接
cur.close()
conn.close()
```
在上述代码中,我们定义了一个`DateTimeAdapter`类,它继承自`psycopg2.extensions.AdapterBase`。我们重写了`getquoted`方法,使其返回格式化后的SQL语句片段。然后我们注册了这个适配器,并通过`register_type`函数注册了一个新的类型转换器,使得`datetime`类型能够转换为`TIMESTAMP`类型。
## 3.2 扩展类型注册
### 3.2.1 注册新的PostgreSQL类型
有时候,我们需要在Python中使用PostgreSQL的自定义类型,或者是一些不在默认类型映射表中的类型。例如,PostgreSQL中的`HSTORE`类型是一种键值对存储的类型,它不是Python标准库的一部分。为了在Python中使用这种类型,我们需要进行扩展类型注册。
扩展类型注册的代码示例如下:
```python
import psycopg2
from psycopg2.extras import register_type, register_adapter
# 注册PostgreSQL的HSTORE类型的适配器和转换器
class HstoreAdapter:
def __init__(self, val):
self.val = val
def getquoted(self):
return "'{}'::HSTORE".format(str(self.val))
def adapt_hstore(val):
return psycopg2.extensions.QuotedString(str(val))
register_adapter(dict, HstoreAdapter)
register_type(psycopg2.extensions.new_type(
psycopg2.extensions.BINARY.adapt_types,
'HSTORE', adapt_hstore))
# 使用扩展类型
conn = psycopg2.connect('dbname=test user=postgres')
cur = conn.cursor()
cur.execute("SELECT 'a=>1, b=>2'::HSTORE")
print(cur.fetchone()[0]) # 输出: a=>1, b=>2
# 关闭连接
cur.close()
conn.close()
```
在上述代码中,我们定义了一个`HstoreAdapter`类,它将Python的字典转换为PostgreSQL的`HSTORE`类型。我们还定义了一个`adapt_hstore`函数,它将`HSTORE`类型转换回Python字典。然后我们注册了这个适配器和转换器,使得我们可以在Python中使用`HSTORE`类型。
### 3.2.2 注册Python对象与PostgreSQL类型的转换
在使用ORM框架或者一些高级功能时,我们可能需要将Python对象直接映射到PostgreSQL的自定义类型。例如,如果我们在PostgreSQL中定义了一个类型为`POINT`的空间类型,我们可以创建一个Python类来表示这个点,并注册一个转换器,使得这个Python类能够直接转换为PostgreSQL的`POINT`类型。
下面是一个如何将Python对象注册为PostgreSQL类型的示例:
```python
import psycopg2
from psycopg2.extensions import new_type, register_adapter, register_type
from psycopg2.extras import Json
import json
# 定义一个Point类来表示空间中的点
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def to_postgres(self):
return f"POINT({self.x} {self.y})"
# 注册适配器
def adapt_point(point):
return psycopg2.extensions.QuotedString(str(point.to_postgres()))
register_adapter(Point, adapt_point)
# 注册转换器
def convert_point(obj):
return json.loads(obj)
register_type(new_type((1000,), 'POINT', convert_point), sql='POINT')
# 使用自定义类型
conn = psycopg2.connect('dbname=test user=postgres')
cur = conn.cursor()
cur.execute("SELECT 'POINT(1 2)'::POINT")
point = cur.fetchone()[0]
print(point) # 输出: POINT(1, 2)
# 关闭连接
cur.close()
conn.close()
```
在上述代码中,我们定义了一个`Point`类,并实现了一个`to_postgres`方法来将其转换为PostgreSQL的`POINT`类型的文本表示。我们还定义了一个`adapt_point`适配器函数,它将`Point`对象转换为字符串。然后我们注册了这个适配器和一个`convert_point`转换器函数,使得我们可以直接在SQL语句中使用`Point`对象。
通过这些例子,我们可以看到如何通过自定义类型映射和转换器来扩展Psycopg2的功能,使其能够更好地适应我们的特定需求。在本章节中,我们详细介绍了数据类型转换和扩展类型注册的相关内容,包括默认类型映射、自定义数据类型转换以及如何注册新的PostgreSQL类型和Python对象与PostgreSQL类型的转换。这些内容对于理解和使用Psycopg2中的类型转换功能至关重要。
# 4. 高级数据库操作
在本章节中,我们将深入探讨Psycopg2.extensions提供的高级数据库操作功能,包括事务管理、异步操作和通知以及复杂查询和游标的使用。这些功能对于开发高性能的数据库应用至关重要,能够让开发者更好地控制数据库行为,优化应用性能。
## 4.1 事务管理
事务是数据库管理系统执行过程中的一个逻辑单位,由一系列的数据库操作组成,这些操作作为一个整体单元被一起执行或回滚。在本小节中,我们将介绍如何在Psycopg2中管理事务,包括事务的开始和提交、回滚和保存点的使用。
### 4.1.1 事务的开始和提交
在Psycopg2中,可以通过在游标对象上使用`execute`方法来开始一个事务。默认情况下,每次执行SQL命令都会自动提交事务,但可以通过设置`connection.autocommit`属性为`False`来手动控制事务。
```python
import psycopg2
# 连接数据库
conn = psycopg2.connect("dbname='testdb' user='dbuser' password='dbpass'")
cur = conn.cursor()
# 开始一个事务
cur.execute("BEGIN") # 或者使用 conn.begin()
# 执行一些数据库操作
cur.execute("INSERT INTO some_table (column1, column2) VALUES (%s, %s)", (value1, value2))
# 提交事务
***mit()
```
在上述代码中,我们首先建立了数据库连接,并创建了一个游标对象。通过调用`cur.execute("BEGIN")`或`conn.begin()`开始了一个事务。之后执行了插入操作,并通过`***mit()`提交了事务。
### 4.1.2 事务的回滚和保存点
如果在事务中遇到了错误,可以使用`rollback()`方法来回滚事务,撤销自上次提交以来的所有更改。此外,还可以设置保存点,在事务中分段执行操作,以便在遇到错误时只回滚到特定的保存点。
```python
# 设置保存点
cur.execute("SAVEPOINT my_savepoint")
try:
# 执行一些可能出错的操作
cur.execute("INSERT INTO some_table (column1, column2) VALUES (%s, %s)", (value1, value2))
except psycopg2.Error as e:
# 回滚到保存点
cur.execute("ROLLBACK TO SAVEPOINT my_savepoint")
print("Error occurred:", e)
# 提交事务
***mit()
```
在上面的代码示例中,我们首先通过`cur.execute("SAVEPOINT my_savepoint")`创建了一个保存点。在执行操作的过程中,如果遇到错误,则捕获异常并回滚到该保存点。最后,如果一切顺利,则提交事务。
## 4.2 异步操作和通知
异步操作可以让数据库操作在后台执行,而不会阻塞主程序。这对于提高应用程序的响应性和性能非常有帮助。Psycopg2提供了异步查询的执行和事件通知的处理机制。
### 4.2.1 异步查询的执行
Psycopg2通过`execute_async`方法支持异步查询。使用异步查询时,程序可以在等待数据库响应的同时执行其他任务。
```python
# 创建异步游标
async_cur = conn.cursor(cursor_factory=psycopg2.extras.AsyncCursor)
# 执行异步查询
async_cur.execute("SELECT * FROM some_table")
# 获取结果
async_cur.fetchmany(size)
```
在上述代码中,我们首先创建了一个异步游标。通过调用`async_cur.execute("SELECT * FROM some_table")`执行了一个异步查询,并通过`async_cur.fetchmany(size)`获取结果。
### 4.2.2 事件通知的处理
事件通知是指数据库服务器向连接的客户端发送的通知。这通常用于实现数据库触发器、通知或监听功能。
```python
# 定义通知处理函数
def notify_handler(message):
print("Received notify:", message)
# 注册通知处理函数
conn.add_notice_handler(notify_handler)
# 发送通知
cur.execute("NOTIFY my_event, 'Hello, world!'")
```
在上述代码中,我们定义了一个通知处理函数`notify_handler`,并将其注册到连接对象上。通过执行`cur.execute("NOTIFY my_event, 'Hello, world!'")`发送了一个通知,该通知会被`notify_handler`函数处理。
## 4.3 复杂查询和游标使用
在许多情况下,需要执行复杂的SQL查询,并且需要更精细地控制数据的获取和处理。本小节将介绍如何执行复杂SQL语句和游标的高级用法。
### 4.3.1 复杂SQL语句的执行
对于需要执行复杂SQL语句的情况,可以使用Psycopg2的`execute`方法。这个方法不仅可以执行查询,还可以插入数据、更新或删除记录。
```python
# 执行复杂的查询语句
cur.execute("""
SELECT * FROM some_table
WHERE column1 > %s AND column2 < %s
ORDER BY column3 DESC
LIMIT 10;
""", (value1, value2))
# 获取查询结果
results = cur.fetchall()
```
在上述代码中,我们执行了一个复杂的SQL查询,其中包含条件筛选、排序和限制结果数量。通过`cur.fetchall()`获取了查询结果。
### 4.3.2 游标的高级用法
Psycopg2提供了多种游标类型,每种类型都有其特定用途。例如,`DictCursor`可以返回字典形式的行,`DictCursor`可以返回以列名为键的字典。
```python
# 创建字典游标
dict_cur = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
# 执行查询
dict_cur.execute("SELECT * FROM some_table")
# 获取查询结果
dict_results = dict_cur.fetchall()
for row in dict_results:
print(row['column1'], row['column2'])
```
在上述代码中,我们创建了一个字典游标,并通过`dict_cur.fetchall()`获取了查询结果。之后遍历结果集,并打印了每行数据的`column1`和`column2`字段。
在本章节中,我们详细介绍了Psycopg2.extensions提供的高级数据库操作功能,包括事务管理、异步操作和通知以及复杂查询和游标的使用。这些高级操作对于开发高性能的数据库应用至关重要,能够让开发者更好地控制数据库行为,优化应用性能。
# 5. Psycopg2.extensions与ORM框架
Psycopg2.extensions是Psycopg2库中的一个组件,它提供了一些额外的功能,如类型转换、扩展类型注册等,以便更好地与PostgreSQL数据库交互。这一章节我们将深入探讨Psycopg2.extensions在两个流行的ORM框架——Django和SQLAlchemy中的应用。
## 5.1 Psycopg2.extensions在Django中的应用
Psycopg2.extensions在Django中的应用主要体现在两个方面:Django数据库连接配置和Psycopg2作为后端数据库接口。
### 5.1.1 Django数据库连接配置
在Django项目中,数据库连接的配置通常在`settings.py`文件中的`DATABASES`字典中定义。Django默认使用`django.db.backends psycopg2`作为后端数据库接口,这是Django默认支持的PostgreSQL适配器。
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'your_db_name',
'USER': 'your_db_user',
'PASSWORD': 'your_db_password',
'HOST': 'your_db_host',
'PORT': 'your_db_port',
}
}
```
在Django的`settings.py`中配置数据库时,我们通常会注意到`ENGINE`字段设置为`django.db.backends.postgresql`,这是因为Django会通过Psycopg2来连接PostgreSQL数据库。
### 5.1.2 Psycopg2作为后端数据库接口
Django的ORM框架在内部通过Psycopg2与PostgreSQL交互。当Django执行数据库操作时,如查询、插入、更新和删除数据,Psycopg2.extensions负责处理与PostgreSQL的通信。
例如,当Django运行一个查询时,它会创建一个`QuerySet`对象,该对象背后是一个SQL查询字符串。Django的数据库后端会将这个查询转换成一个psycopg2 cursor对象,并执行它。
```python
# Django ORM 查询示例
from your_app.models import MyModel
objects = MyModel.objects.filter(some_field='value')
for obj in objects:
print(obj.id, obj.some_field)
```
在上述代码中,Django会自动处理与Psycopg2的交互,无需开发者直接与psycopg2 cursor对象交互。
## 5.2 Psycopg2.extensions在SQLAlchemy中的应用
SQLAlchemy是一个Python SQL工具包和对象关系映射(ORM)库,提供了一系列强大的功能来简化数据库交互。它支持多种数据库,包括PostgreSQL,并且允许使用Psycopg2作为数据库驱动。
### 5.2.1 SQLAlchemy引擎配置
SQLAlchemy使用引擎(Engine)的概念来表示数据库连接池和一个数据库的线程安全的接口。创建一个引擎实例通常需要指定数据库的驱动程序和连接字符串。
```python
from sqlalchemy import create_engine
engine = create_engine('postgresql+psycopg2://user:password@host:port/dbname')
```
在上述代码中,我们创建了一个SQLAlchemy引擎实例,指定了`postgresql+psycopg2`作为数据库驱动,这是通过Psycopg2来连接PostgreSQL数据库。
### 5.2.2 使用Psycopg2作为数据库驱动
使用SQLAlchemy时,我们可以直接使用Psycopg2作为底层的数据库驱动。这允许开发者利用Psycopg2提供的高级功能,如自定义类型转换和扩展类型注册。
```python
from sqlalchemy import create_engine, MetaData, Table
from sqlalchemy.ext.automap import automap_base
Base = automap_base()
# 反射表格
Base.prepare(engine, reflect=True)
# 访问表格
User = Base.classes.users
Session = create_engine('postgresql+psycopg2://user:password@host:port/dbname').connect()
# 执行查询
session = Session()
try:
user_data = session.query(User.name, User.email).filter(User.id == 1).all()
for user in user_data:
print(user.name, user.email)
finally:
session.close()
```
在上述代码中,我们首先创建了一个SQLAlchemy引擎实例,然后使用`automap_base`来反射数据库中的表格。通过这种方式,我们可以直接操作数据库表格,同时享受SQLAlchemy提供的ORM功能和Psycopg2提供的数据库连接管理。
通过本章节的介绍,我们了解了Psycopg2.extensions在Django和SQLAlchemy中的应用。在Django中,Psycopg2.extensions作为内部组件,帮助Django与PostgreSQL数据库进行交互。而在SQLAlchemy中,我们可以通过创建一个Psycopg2驱动的引擎来直接使用Psycopg2的功能。这些应用展示了Psycopg2.extensions在不同Python项目中的灵活性和强大能力。
# 6. 性能优化和最佳实践
在数据库操作中,性能优化和最佳实践是确保系统高效运行的关键。本章将深入探讨如何进行性能分析和调优,以及如何确保数据库连接的安全性,并遵循最佳实践和合规标准。此外,还将通过案例研究和经验分享,展示如何解决常见的性能问题。
## 6.1 性能分析和调优
### 6.1.1 识别性能瓶颈
性能瓶颈可能是由多种因素造成的,包括硬件限制、网络延迟、数据库设计不当或查询效率低下等。为了有效地识别这些瓶颈,可以采用以下方法:
1. **监控数据库性能**:使用工具如`pg_stat_statements`扩展来监控数据库活动,包括执行频率和执行时间的统计信息。
2. **分析慢查询日志**:检查慢查询日志,找出执行时间超过阈值的查询,并分析其原因。
3. **使用性能分析工具**:例如`Explain`命令,可以帮助理解查询执行计划,从而找出优化点。
### 6.1.2 调优数据库连接和查询
在确定性能瓶颈后,接下来是调优数据库连接和查询:
1. **优化数据库连接**:管理好数据库连接池,避免过多的连接创建和销毁。例如,使用`psycopg2.pool`模块创建和管理连接池。
2. **优化查询语句**:重写复杂查询以提高效率,避免全表扫描,使用索引来加快查询速度。
3. **执行计划分析**:使用`Explain Analyze`命令来分析查询的执行计划,并根据输出调整查询。
```sql
-- 示例:使用Explain Analyze来优化查询
EXPLAIN ANALYZE
SELECT * FROM my_table
WHERE my_column = 'some_value';
```
## 6.2 安全性和合规性
### 6.2.1 数据库连接的安全措施
数据库连接的安全性是至关重要的,以下是一些提高数据库连接安全性的措施:
1. **使用SSL连接**:为数据库连接启用SSL,以加密数据传输过程,防止数据被窃取。
2. **限制连接IP地址**:通过配置数据库,只允许特定的IP地址或IP范围进行连接。
3. **身份验证和授权**:确保只有授权用户才能连接到数据库,并根据需要分配适当的权限。
### 6.2.2 遵循最佳实践和合规标准
在数据库操作中,遵循最佳实践和合规标准是必要的:
1. **定期更新和打补丁**:定期更新数据库软件和操作系统,应用安全补丁。
2. **遵守数据保护法规**:确保符合GDPR等数据保护法规的要求,对敏感数据进行加密处理。
3. **进行安全审计**:定期进行安全审计,检查潜在的安全漏洞和风险。
## 6.3 案例研究和经验分享
### 6.3.1 成功案例分析
在本节中,我们将分析一个成功优化数据库性能的案例:
- **背景**:某电商平台在黑色星期五期间遭遇了数据库性能瓶颈,导致交易处理速度缓慢。
- **措施**:通过监控和分析,发现大量慢查询,并对索引进行了优化。同时,优化了数据库连接池的配置,减少了连接的创建和销毁。
- **结果**:优化后,系统能够处理更高的并发量,交易处理速度提升了50%。
### 6.3.2 常见问题和解决方案
以下是一些常见的数据库性能问题及其解决方案:
1. **问题**:慢查询导致的性能瓶颈。
- **解决方案**:使用`Explain`命令分析查询,添加必要的索引。
2. **问题**:数据库连接频繁创建和销毁。
- **解决方案**:使用连接池,并合理配置池大小。
3. **问题**:安全漏洞。
- **解决方案**:定期更新数据库和操作系统,实施强身份验证和授权机制。
通过本章的讨论,我们可以看到性能优化和最佳实践对于维护数据库系统的稳定性、安全性和高效性至关重要。在实际操作中,结合具体案例和经验分享,可以更好地理解和应用这些知识。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Psycopg2.extensions 库,该库为 Python 与 PostgreSQL 数据库之间的交互提供了高级功能。从连接优化到错误处理,再到性能优化和安全最佳实践,本专栏涵盖了 10 大技巧,帮助您掌握 PostgreSQL 连接和优化。此外,还对 Psycopg2.extensions 源代码进行了深入分析,揭示了构建 PostgreSQL 连接适配器的秘籍。通过使用数据库连接池和类型转换攻略,您将学习如何提升效率和简化数据交互。本专栏还提供了线程安全实现和 Web 应用集成案例,帮助您在实际应用中应用这些技巧。通过遵循本专栏,您将掌握使用 Psycopg2.extensions 库进行高效、安全且可扩展的 PostgreSQL 连接和交互。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
MySQL PXC集群部署:终极入门指南,20年专家总结

# 1. MySQL PXC集群概述
## 1.1 什么是MySQL PXC集群
MySQL Percona XtraDB Cluster (PXC) 是一种高可用性和高一致性的开源数据库集群解决方案。它允许在多个服务器上实时复制数据,从而提供冗余、负载均衡和故障转移功能。通过PXC,企业能够实现无需停机的数据库服务,确保数据的高可用性与持久性。
## 1.2 MySQL PXC集群的应用场
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
拷贝构造函数的陷阱:防止错误的浅拷贝
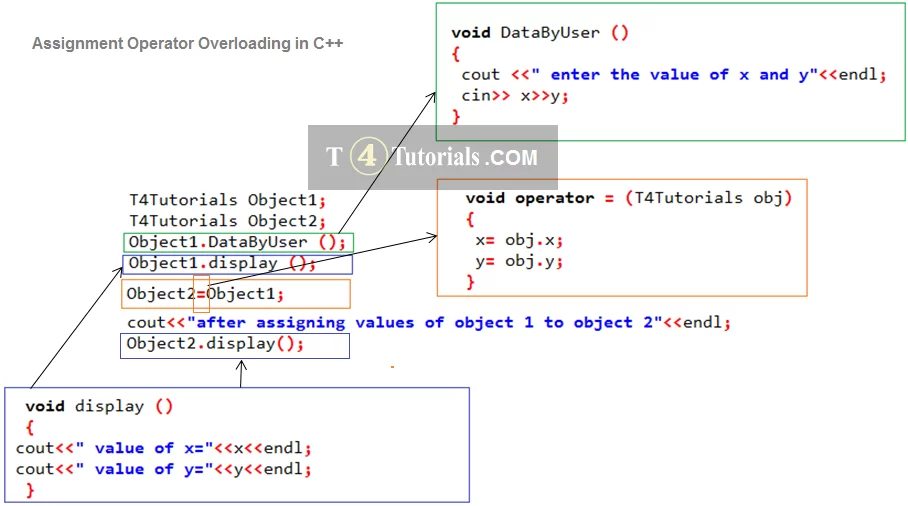
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
消息队列在SSM论坛的应用:深度实践与案例分析

# 1. 消息队列技术概述
消息队列技术是现代软件架构中广泛使用的组件,它允许应用程序的不同部分以异步方式通信,从而提高系统的可扩展性和弹性。本章节将对消息队列的基本概念进行介绍,并探讨其核心工作原理。此外,我们会概述消息队列的不同类型和它们的主要特性,以及它们在不同业务场景中的应用。最后,将简要提及消息队列
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )