MySQL排序规则实战指南:解决常见排序问题和性能调优
发布时间: 2024-07-27 09:40:46 阅读量: 35 订阅数: 23 

# 1. MySQL排序基础**
排序是数据库中一项重要的操作,它允许我们按特定顺序组织和检索数据。MySQL提供了多种排序选项,包括按单个字段排序、按多个字段排序以及使用自定义排序规则排序。
**1.1 排序语法**
MySQL中使用`ORDER BY`子句进行排序,其语法如下:
```sql
SELECT column_name(s)
FROM table_name
ORDER BY column_name(s) [ASC | DESC];
```
其中:
* `column_name(s)`:要排序的列名,可以是单个列或多个列。
* `ASC`:按升序排序(从最小到最大)。
* `DESC`:按降序排序(从最大到最小)。
# 2. 常见排序问题及解决方法
### 2.1 排序顺序错误
#### 2.1.1 忽略大小写和区分大小写
**问题描述:**
在对包含大小写字母的字符串字段进行排序时,如果未指定排序规则,MySQL默认采用区分大小写的排序,导致排序结果可能与预期不一致。
**解决方法:**
使用 `COLLATE` 子句指定排序规则,例如:
```sql
SELECT * FROM table_name ORDER BY column_name COLLATE utf8_general_ci;
```
其中,`utf8_general_ci` 表示不区分大小写的排序规则。
#### 2.1.2 多字段排序
**问题描述:**
对多个字段进行排序时,如果未指定排序顺序,MySQL会按照字段出现的顺序进行排序。这可能导致排序结果与预期不一致,尤其是当某些字段包含空值时。
**解决方法:**
使用 `ORDER BY` 子句明确指定排序顺序,例如:
```sql
SELECT * FROM table_name ORDER BY column1 ASC, column2 DESC;
```
其中,`ASC` 表示升序,`DESC` 表示降序。
### 2.2 排序结果不准确
#### 2.2.1 空值处理
**问题描述:**
当排序字段包含空值时,MySQL默认将空值视为最小值。这可能导致排序结果不准确,尤其是当排序字段是主键或唯一索引时。
**解决方法:**
使用 `COALESCE()` 函数将空值替换为非空值,例如:
```sql
SELECT * FROM table_name ORDER BY COALESCE(column_name, ' ');
```
其中,`' '` 表示空值的替代值。
#### 2.2.2 NULL值处理
**问题描述:**
MySQL将 `NULL` 值视为特殊值,在排序时将 `NULL` 值排在非 `NULL` 值之前或之后。这可能导致排序结果不准确,尤其是当排序字段包含大量 `NULL` 值时。
**解决方法:**
使用 `ISNULL()` 函数将 `NULL` 值替换为非 `NULL` 值,例如:
```sql
SELECT * FROM table_name ORDER BY ISNULL(column_name, 0);
```
其中,`0` 表示 `NULL` 值的替代值。
### 2.3 排序性能不佳
#### 2.3.1 索引使用
**问题描述:**
在对大数据集进行排序时,如果没有使用适当的索引,MySQL需要扫描整个表来获取排序所需的数据。这会导致排序性能不佳。
**解决方法:**
在排序字段上创建合适的索引,例如:
```sql
CREATE INDEX idx_column_name ON table_name (column_name);
```
使用索引后,MySQL可以快速找到排序所需的数据,从而提升排序性能。
#### 2.3.2 数据分布
**问题描述:**
当排序字段的数据分布不均匀时,MySQL需要进行额外的排序操作,导致排序性能不佳。例如,当排序字段包含大量重复值时,MySQL需要对这些重复值进行额外的比较和交换操作。
**解决方法:**
使用 `DISTINCT` 子句消除重复值,例如:
```sql
SELECT DISTINCT column_name FROM table_name ORDER BY column_name;
```
消除重复值后,MySQL只需要对唯一值进行排序,从而提升排序性能。
# 3. MySQL排序优化技巧
### 3.1 选择合适的排序算法
MySQL中常用的排序算法包括归并排序和快速排序。
**归并排序**是一种稳定的排序算法,它将数据分成较小的子集,对子集进行排序,然后合并排序后的子集。归并排序的时间复杂度为 O(n log n),在数据量较大时性能较好。
```sql
-- 使用归并排序
SELECT * FROM table_name ORDER BY column_name DESC;
```
**快速排序**是一种不稳定的排序算法,它选择一个基准元素,将数据分成两部分:小于基准元素的部分和大于基准元素的部分。然后对两部分分别进行排序。快速排序的时间复杂度为 O(n log n),在数据量较小时性能较好。
```sql
-- 使用快速排序
SELECT * FROM table_name ORDER BY column_name DESC USING BTREE;
```
### 3.2 使用索引加速排序
索引是存储在数据库中的数据结构,它可以帮助MySQL快速找到数据。在排序操作中,索引可以帮助MySQL避免扫描整个表,从而提高排序性能。
**创建合适的索引**
为经常用于排序的列创建索引可以显著提高排序性能。索引类型应根据排序需求选择。例如,如果需要按降序排序,则应创建降序索引。
```sql
-- 创建降序索引
CREATE INDEX index_name ON table_name (column_name) DESC;
```
**优化索引结构**
索引结构也会影响排序性能。如果索引包含冗余数据或不必要的列,则会降低排序性能。因此,应优化索引结构,只包含必要的列。
```sql
-- 优化索引结构
ALTER TABLE table_name DROP INDEX index_name;
CREATE INDEX index_name ON table_name (column_name);
```
### 3.3 优化查询语句
除了使用索引外,还可以通过优化查询语句来提高排序性能。
**减少不必要的排序**
如果查询中有多个排序条件,则应考虑是否所有条件都必须排序。如果某些条件不需要排序,则可以将其从 ORDER BY 子句中删除。
```sql
-- 减少不必要的排序
SELECT * FROM table_name ORDER BY column_name1 DESC, column_name2;
```
**使用临时表**
如果排序操作涉及大量数据,则可以使用临时表来提高性能。临时表存储排序后的数据,从而避免对原始表进行多次排序。
```sql
-- 使用临时表
CREATE TEMPORARY TABLE temp_table AS
SELECT * FROM table_name ORDER BY column_name DESC;
SELECT * FROM temp_table;
```
# 4. MySQL排序高级应用
### 4.1 自定义排序规则
#### 4.1.1 使用 COLLATE 子句
COLLATE 子句用于指定字符串比较时使用的字符集和排序规则。通过使用 COLLATE 子句,我们可以自定义排序规则,以满足特定的需求。
**语法:**
```sql
SELECT column_name
FROM table_name
ORDER BY column_name COLLATE collation_name;
```
**参数:**
* **column_name:**要排序的列名
* **collation_name:**要使用的字符集和排序规则的名称
**示例:**
```sql
SELECT name
FROM users
ORDER BY name COLLATE utf8_general_ci;
```
此查询将使用 utf8_general_ci 字符集和排序规则对 name 列进行排序。
#### 4.1.2 创建自定义排序规则
除了使用内置的排序规则外,我们还可以创建自己的自定义排序规则。这可以通过使用 CREATE COLLATION 语句来实现。
**语法:**
```sql
CREATE COLLATION collation_name
FOR charset_name
FROM parent_collation_name
[USING comparison_function];
```
**参数:**
* **collation_name:**要创建的自定义排序规则的名称
* **charset_name:**要使用的字符集的名称
* **parent_collation_name:**要基于的父排序规则的名称
* **comparison_function:**自定义比较函数的名称(可选)
**示例:**
```sql
CREATE COLLATION my_collation
FOR utf8
FROM utf8_general_ci
USING my_comparison_function;
```
此语句将创建一个名为 my_collation 的自定义排序规则,它基于 utf8_general_ci 排序规则,并使用 my_comparison_function 作为自定义比较函数。
### 4.2 多表排序
#### 4.2.1 UNION 操作
UNION 操作符可以将来自多个表的查询结果合并到一个结果集中。通过使用 UNION 操作,我们可以对来自不同表的记录进行排序。
**语法:**
```sql
SELECT column_name
FROM table1
UNION
SELECT column_name
FROM table2
ORDER BY column_name;
```
**示例:**
```sql
SELECT name
FROM users
UNION
SELECT name
FROM customers
ORDER BY name;
```
此查询将来自 users 表和 customers 表的 name 列合并到一个结果集中,并按 name 列进行排序。
#### 4.2.2 JOIN 操作
JOIN 操作符可以将来自多个表的记录基于公共列连接在一起。通过使用 JOIN 操作,我们可以对来自不同表的记录进行排序。
**语法:**
```sql
SELECT column_name
FROM table1
JOIN table2
ON table1.column_name = table2.column_name
ORDER BY column_name;
```
**示例:**
```sql
SELECT name
FROM users
JOIN orders
ON users.id = orders.user_id
ORDER BY name;
```
此查询将 users 表和 orders 表基于 id 列连接在一起,并按 name 列进行排序。
# 5. MySQL排序性能调优案例
### 5.1 案例一:优化大型数据集的排序
**问题描述:**
需要对一个包含数百万条记录的大型表进行排序,但排序性能非常缓慢。
**优化方案:**
* **使用索引加速排序:**创建覆盖索引,包含排序字段。
* **优化索引结构:**使用合适的索引类型(例如 B+ 树索引)和适当的索引长度。
* **减少不必要的排序:**使用 LIMIT 子句限制返回的行数,避免对整个表进行排序。
* **使用临时表:**将数据复制到临时表中,然后在临时表上进行排序,避免对原始表进行昂贵的排序操作。
### 5.2 案例二:解决排序顺序错误问题
**问题描述:**
排序结果与预期不一致,某些记录的排序顺序错误。
**优化方案:**
* **忽略大小写和区分大小写:**使用 COLLATE 子句指定排序规则,例如 COLLATE utf8mb4_general_ci。
* **多字段排序:**使用 ORDER BY 子句指定多个排序字段,并使用 ASC 或 DESC 关键字指定排序顺序。
* **空值处理:**使用 IS NULL 或 COALESCE 函数处理空值,确保空值按照预期进行排序。
### 5.3 案例三:提升多表排序性能
**问题描述:**
需要对多个表进行排序,但多表排序性能不佳。
**优化方案:**
* **使用 UNION 操作:**将多个表的查询结果合并到一个结果集中,然后使用 UNION ALL 子句进行排序。
* **使用 JOIN 操作:**将多个表连接起来,然后使用 ORDER BY 子句对连接后的结果集进行排序。
* **优化查询语句:**使用适当的连接类型(例如 INNER JOIN 或 LEFT JOIN)和适当的索引,避免不必要的表扫描。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 MySQL 数据库排序规则的权威指南!本专栏深入探讨了 MySQL 排序规则的方方面面,从基础概念到高级技巧。您将了解如何使用排序规则解决常见问题,优化查询性能,并充分利用索引。本指南涵盖了广泛的主题,包括排序规则对字符集、性能、全文索引、存储过程、触发器、视图、临时表、子查询、连接查询、联合查询、分组查询、窗口函数、游标、存储引擎和事务的影响。通过本专栏,您将掌握 MySQL 排序规则的精髓,并成为一名排序规则专家,能够有效地利用排序规则来提升查询效率和应用程序性能。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S57 Map XML Encoding Standards: Parsing the Association Between XML Format and Business Information
# 1. Introduction to S57 Maps
S57 maps, as a nautical chart data format, are widely used in the maritime domain. XML, as a general-purpose data storage format, has gradually been applied to the storage and exchange of S57 map data. This chapter will introduce an overview of S57 maps, explore the ad
【揭开JSON神秘面纱】:解析复杂JSON结构的实用策略
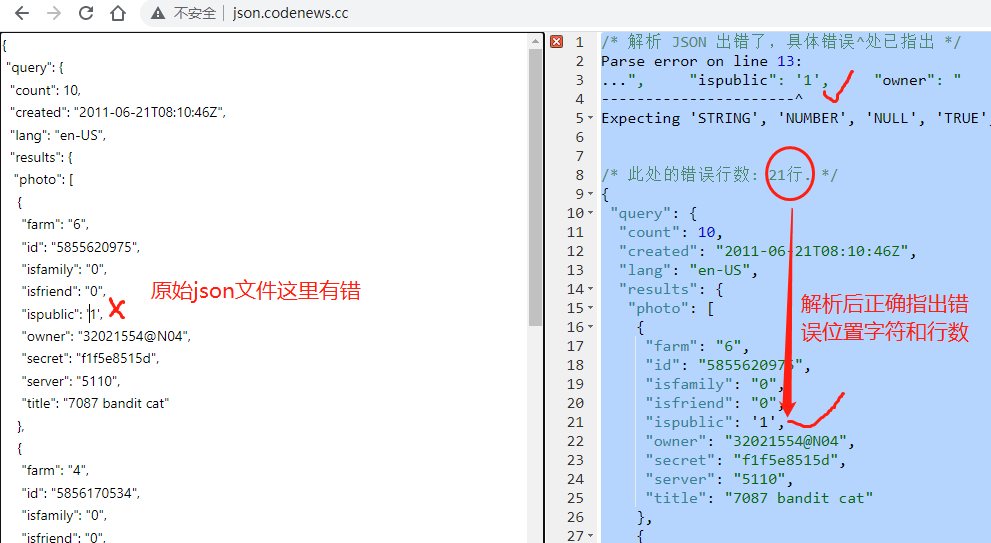
# 1. JSON基础概述
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript的一个子集,但是JSON是语言无关的。任何支持字符串和数组的数据处理语言都能够处理JSON数据。
在IT行业中,JSON常被用于Web前后端的数据交换,如Web API服务通常以JSON格式返回数据供前端处理
Application of Edge Computing in Multi-Access Communication
# 1. Introduction to Edge Computing and Multi-access Communication
## 1.1 Fundamental Concepts and Principles of Edge Computing
Edge computing is a computational model that pushes computing power and data storage closer to the source of data generation or the consumer. Its basic principle involves
【源码级深拷贝分析】:揭秘库函数背后的数据复制逻辑

# 1. 深拷贝与浅拷贝概念解析
## 深拷贝与浅拷贝基本概念
在编程中,当我们需要复制一个对象时,通常会遇到两种拷贝方法:浅拷贝(Shallow Copy)和深拷贝(Deep Copy)。浅拷贝仅仅复制对象的引用,而不复制对象本身的内容,这意味着两个变量指向同一块内存地址。深拷贝则会复制对象及其所包含的所有成员变量,创建一个全新的对象,与原对象在内存中不共享任何内容。
## 浅拷贝的
Unveiling MATLAB Normal Distribution: From Random Number Generation to Confidence Interval Estimation
### Theoretical Foundation of Normal Distribution
The normal distribution, also known as the Gaussian distribution, is a continuous probability distribution characterized by a bell-shaped curve. It is widely present in nature and scientific research and is commonly used to describe various random v
The Role of uint8 in Cloud Computing and the Internet of Things: Exploring Emerging Fields, Unlocking Infinite Possibilities
# The Role of uint8 in Cloud Computing and IoT: Exploring Emerging Fields, Unlocking Infinite Possibilities
## 1. Introduction to uint8
uint8 is an unsigned 8-bit integer data type representing integers between 0 and 255. It is commonly used to store small integers such as counters, flags, and sta
MATLAB Path and Image Processing: Managing Image Data Paths, Optimizing Code Efficiency for Image Processing, and Saying Goodbye to Slow Image Processing
# MATLAB Path and Image Processing: Managing Image Data Paths, Optimizing Image Processing Code Efficiency, Saying Goodbye to Slow Image Processing
## 1. MATLAB Path Management
Effective path management in MATLAB is crucial for its efficient use. Path management involves setting up directories whe
Online Course on Insufficient Input Parameters in MATLAB: Systematically Master Knowledge and Skills
# Online Course on Insufficient MATLAB Input Parameters: Systematically Mastering Knowledge and Skills
## 1. Introduction to MATLAB
MATLAB (Matrix Laboratory) is a programming language and interactive environment designed specifically for matrix computations and numerical analysis. It is developed
Optimizing Conda Environment Performance: How to Tune Your Conda Environment for Enhanced Performance?
# 1. How to Optimize Conda Environment for Performance Enhancement?
1. **Introduction**
- During the development and deployment of projects, proper environment configuration and dependency management are crucial for enhancing work efficiency and project performance. This article will focus on
Installation and Uninstallation of MATLAB Toolboxes: How to Properly Manage Toolboxes for a Tidier MATLAB Environment
# Installing and Uninstalling MATLAB Toolboxes: Mastering the Art of Tool Management for a Neat MATLAB Environment
## 1. Overview of MATLAB Toolboxes
MATLAB toolboxes are supplementary software packages that extend MATLAB's functionality, offering specialized features for specific domains or appli
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )