在CentOS中部署和配置MariaDB数据库
发布时间: 2023-12-15 09:13:10 阅读量: 43 订阅数: 24 

CentOS安装和设置MariaDB的教程
# 1. 简介
## 1.1 什么是MariaDB数据库
MariaDB是一个开源的关系型数据库管理系统(RDBMS),它是MySQL数据库的一个分支。它提供了高性能、稳定性和安全性的特性,并且与MySQL兼容。MariaDB数据库被广泛用于Web应用程序和企业级解决方案。
## 1.2 CentOS操作系统的优势
CentOS是一种基于Linux的操作系统,它是一个免费、开源且稳定的操作系统。CentOS具有强大的安全性和稳定性,适用于各种不同规模的服务器环境。CentOS还提供广泛的软件包和工具,方便用户进行软件安装和管理。
在接下来的章节中,我们将介绍如何在CentOS操作系统中部署和配置MariaDB数据库,以及常见问题的解决方法。让我们开始吧!
# 2. 系统准备
在进行MariaDB数据库的部署和配置之前,我们需要对系统进行一些准备工作,确保系统符合要求并安装配置必要的依赖项。
### 2.1 确认系统要求
在开始之前,确保你的CentOS操作系统版本符合MariaDB的要求。目前,MariaDB支持的最新稳定版本是CentOS 7和CentOS 8。
### 2.2 安装和配置依赖项
在安装MariaDB之前,需要确认系统已安装并配置了必要的依赖项,例如gcc、gcc-c++、make和cmake等。你可以使用以下命令来安装这些依赖项:
```bash
sudo yum install gcc gcc-c++ make cmake
```
### 2.3 下载和安装MariaDB
接下来,你需要下载并安装MariaDB软件包。你可以通过以下命令在CentOS中安装MariaDB:
```bash
sudo yum install mariadb-server mariadb
```
一旦安装完成,MariaDB服务将自动启动,并且会在系统启动时自动启动。接下来,我们将进入初始化设置阶段。
# 3. 初始化设置
在安装完MariaDB后,需要进行一些初始化设置来确保数据库的安全性和稳定性。
#### 3.1 启动MariaDB服务
首先,使用以下命令启动MariaDB服务:
```shell
sudo systemctl start mariadb
```
还可以使用以下命令来检查MariaDB服务的运行状态:
```shell
sudo systemctl status mariadb
```
如果服务成功启动,将会看到类似以下的输出:
```
● mariadb.service - MariaDB 10.5.12 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2021-08-10 15:30:32 UTC; 3s ago
Docs: man:mysqld(8)
https://mariadb.com/kb/en/library/systemd/
Process: 82712 ExecStartPre=/usr/libexec/mariadb-prepare-db-dir %n (code=exited, status=0/SUCCESS)
Main PID: 82727 (mysqld)
Status: "Taking your SQL requests now..."
Tasks: 30 (limit: 9503)
Memory: 78.6M
CGroup: /system.slice/mariadb.service
└─82727 /usr/libexec/mysqld --basedir=/usr
```
#### 3.2 设置root密码
MariaDB安装后,root账户默认没有密码,为了数

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以CentOS操作系统为背景,涵盖了入门和基础配置、安装和配置Nginx服务器、使用YUM进行软件管理、使用systemctl管理系统服务、文件权限管理、部署和配置MariaDB数据库、搭建基础的Apache服务器、Firewalld进行网络安全配置、SELinux安全性配置、Cron定时任务管理、Docker容器的部署与管理、TCP_IP网络配置实践、RPM包管理器详解、配置SSH远程连接与安全性控制、服务器性能优化与调优技巧、搭建基于LAMP的Web应用、虚拟化技术KVM的部署与使用、使用NFS进行网络文件共享以及利用iptables进行网络流量控制等多个方面的内容。通过本专栏,读者将能够全面了解CentOS操作系统的基础知识、常用工具和技巧,并能够应用于实际生产环境中,提升系统管理和运维能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机矩阵键盘扫描终极指南】:全面解析编程技巧及优化策略

# 摘要
本论文主要探讨了基于51单片机的矩阵键盘扫描技术,包括其工作原理、编程技巧、性能优化及高级应用案例。首先介绍了矩阵键盘的硬件接口、信号特性以及单片机的选择与配置。接着深入分析了不同的扫
【Pycharm源镜像优化】:提升下载速度的3大技巧

# 摘要
Pycharm作为一款流行的Python集成开发环境,其源镜像配置对开发效率和软件性能至关重要。本文旨在介绍Pycharm源镜像的重要性,探讨选择和评估源镜像的理论基础,并提供实践技巧以优化Pycharm的源镜像设置。文章详细阐述了Pycharm的更新机制、源镜像的工作原理、性能评估方法,并提出了配置官方源、利用第三方源镜像、缓存与持久化设置等优化技巧。进一步,文章探索了多源镜像组
【VTK动画与交互式开发】:提升用户体验的实用技巧
# 摘要
本文旨在介绍VTK(Visualization Toolkit)动画与交互式开发的核心概念、实践技巧以及在不同领域的应用。通过详细介绍VTK动画制作的基础理论,包括渲染管线、动画基础和交互机制等,本文阐述了如何实现动画效果、增强用户交互,并对性能进行优化和调试。此外,文章深入探讨了VTK交互式应用的高级开发,涵盖了高级交互技术和实用的动画
【转换器应用秘典】:RS232_RS485_RS422转换器的应用指南
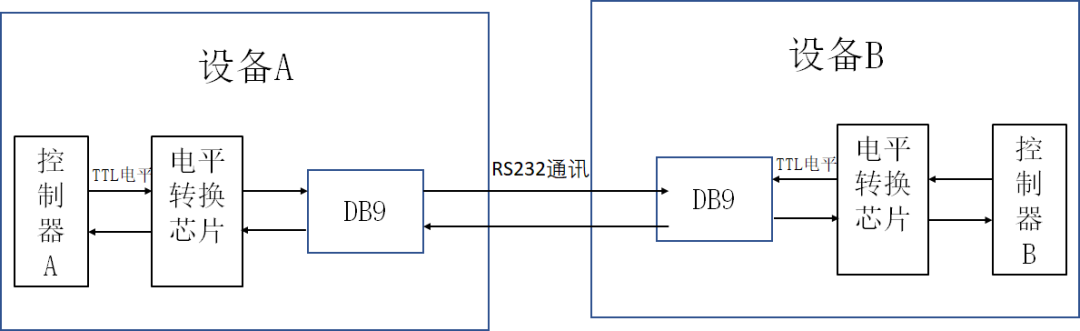
# 摘要
本论文全面概述了RS232、RS485、RS422转换器的原理、特性及应用场景,并深入探讨了其在不同领域中的应用和配置方法。文中不仅详细介绍了转换器的理论基础,包括串行通信协议的基本概念、标准详解以及转换器的物理和电气特性,还提供了转换器安装、配置、故障排除及维护的实践指南。通过分析多个实际应用案例,论文展示了转
【Strip控件多语言实现】:Visual C#中的国际化与本地化(语言处理高手)

# 摘要
本文全面探讨了Visual C#环境下应用程序的国际化与本地化实施策略。首先介绍了国际化基础和本地化流程,包括本地化与国际化的关系以及基本步骤。接着,详细阐述了资源文件的创建与管理,以及字符串本地化的技巧。第三章专注于Strip控件的多语言实现,涵盖实现策略、高级实践和案例研究。文章第四章则讨论了多语言应用程序的最佳实践和性能优化措施。最后,第五章通过具体案例分析,总结了国际化与本地化的核心概念,并展望了未来的技术趋势。
# 关
C++高级话题:处理ASCII文件时的异常处理完全指南
# 摘要
本文旨在探讨异常处理在C++编程中的重要性以及处理ASCII文件时如何有效地应用异常机制。首先,文章介绍了ASCII文件的基础知识和读写原理,为理解后续异常处理做好铺垫。接着,文章深入分析了C++中的异常处理机制,包括基础语法、标准异常类使用、自定义异常以及异常安全性概念与实现。在此基础上,文章详细探讨了C++在处理ASCII文件时的异常情况,包括文件操作中常见异常分析和异常处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )