在CentOS中利用Cron定时任务管理
发布时间: 2023-12-15 09:23:33 阅读量: 67 订阅数: 22 

linux(centos)中的cron计划任务配置方法.docx
# 1. 简介
## 1.1 什么是Cron定时任务
Cron定时任务是一种在特定时间或特定间隔执行的自动化任务。它可以在操作系统级别上设置和管理,使用户能够按照预定的时间表自动执行特定的任务或脚本。
## 1.2 为什么要在CentOS中使用Cron定时任务
CentOS是一种流行的Linux发行版,被广泛用于服务器和系统管理。使用Cron定时任务可以使系统管理员能够自动执行重复性的任务,减少人工操作并提高工作效率。同时,Cron还提供了灵活的配置选项和强大的调度功能,使其成为在CentOS中管理定时任务的首选工具。
## 1.3 基本概念和术语解释
在使用Cron定时任务之前,有几个基本概念和术语需要了解:
- **Cron表达式**:Cron表达式是一种特定的语法格式,用于指定任务在何时执行。它由5个或6个时间字段组成,分别表示分钟、小时、日期、月份和星期几。
- **Cron任务**:Cron任务是一条配置在Cron表中的任务,定义了任务的执行时间和要执行的命令或脚本。
- **Cron守护进程**:Cron守护进程是负责解析和执行Cron表中的任务的后台进程。它会按照指定的时间计划执行任务,并记录执行结果和日志。
- **Cron作业**:Cron作业是指定要在执行时间点运行的命令或脚本。每个Cron作业都有一个唯一的标识符,用于识别和管理。
- **Crontab文件**:Crontab文件是存储Cron任务和配置信息的文件,每个用户都有自己的Crontab文件。用户可以通过编辑Crontab文件来添加、修改或删除Cron任务。
现在,我们已经了解了Cron定时任务的基本概念和术语。接下来,我们将学习如何安装和配置Cron服务。
# 2. 安装Cron
Cron是一个用于在特定时间或间隔执行预定命令的Linux工具。在CentOS中使用Cron定时任务可以帮助管理员自动化系统管理任务,提高效率,降低人为出错几率。接下来将介绍如何在CentOS中安装Cron,并配置相关服务。
#### 2.1 检查Cron是否已安装
在开始安装Cron之前,首先要确认系统中是否已经安装了Cron。可以通过以下命令来检查:
```bash
rpm -q cronie
```
如果系统中已安装Cron,则会显示Cron的版本信息。若未安装,可以继续进行安装步骤。
#### 2.2 安装Cron的步骤
要在CentOS系统中安装Cron,可以使用以下命令来安装Cron软件包:
```bash
sudo yum install cronie
```
输入上述命令后,系统将自动下载安装所需的软件包,并进行安装。安装完成后,Cron服务会自动启动。
#### 2.3 配置Cron服务
安装完成后,可以使用以下命令来启动、停止、重启Cron服务:
```bash
sudo systemctl start crond # 启动Cron服务
sudo systemctl stop crond # 停止Cron服务
sudo systemctl restart crond # 重启Cron服务
```
此为Cron的安装及基本配置步骤。下一步,将介绍如何编写Cron脚本。
# 3. 编写Cron脚本
在CentOS中使用Cron定时任务,我们需要先编写Cron脚本。Cron脚本是一个包含了指令和命令的文本文件,指定了我们希望在特定时间或间隔内运行的任务。
#### 3.1 Cron脚本的基本语法
我们首先了解一下Cron脚本的基本语法:
```shell
* * * * * command
```
其中,`* * * * *` 是指定任务执行的时间和间隔,具体的含义如下:
- 第1列:分钟(0-59)
- 第2列:小时(0-23)
- 第3列:日期(1-31)
- 第4列:月份(1-12)
- 第5列:星期(0-6,0表示星期天)
我们可以使用通配符`*`表示任意值,例如`*`表示每分钟、每小时、每月、每周。除了通配符`*`,我们还可以使用固定值和范围值,例如`0,10,20,30,40,50`表示每个小时的0分、10分、20分、30分、40分和50分执行任务。
在`command`这一列,我们编写要执行的具体任务,可以是系统命令、脚本文件或可执行程序。
#### 3.2 编写简单的Cron脚本实例
我们以一个简单的实例来演示如何编写Cron脚本。假设我们想定时执行一个Python脚本,该脚本会输出当前时间和一条特定的消息。
首先,我们打开一个文本编辑器,创建一个名为`cron_script.py`的Python脚本文件:
```python
#!/usr/bin/env python3
import datetime
current_time = datetime.datetime.now()
message = "这是一个定时
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以CentOS操作系统为背景,涵盖了入门和基础配置、安装和配置Nginx服务器、使用YUM进行软件管理、使用systemctl管理系统服务、文件权限管理、部署和配置MariaDB数据库、搭建基础的Apache服务器、Firewalld进行网络安全配置、SELinux安全性配置、Cron定时任务管理、Docker容器的部署与管理、TCP_IP网络配置实践、RPM包管理器详解、配置SSH远程连接与安全性控制、服务器性能优化与调优技巧、搭建基于LAMP的Web应用、虚拟化技术KVM的部署与使用、使用NFS进行网络文件共享以及利用iptables进行网络流量控制等多个方面的内容。通过本专栏,读者将能够全面了解CentOS操作系统的基础知识、常用工具和技巧,并能够应用于实际生产环境中,提升系统管理和运维能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【XJC-608T-C控制器与Modbus通讯】:掌握关键配置与故障排除技巧(专业版指南)
.jpg)
# 摘要
本文全面介绍了XJC-608T-C控制器与Modbus通讯协议的应用与实践。首先概述了XJC-608T-C控制器及其对Modbus协议的支持,接着深入探讨了Modbus协议的理论基础,包括其发展历史和帧结构。文章详细说明了XJC-608T-C控制器的通信接口配置,以及如何进行Modbus参数的详细设置。第三章通过实践应用,阐述了Modbus RTU和TCP通讯模
掌握Walktour核心原理:测试框架最佳实践速成

# 摘要
本文详细介绍了Walktour测试框架的结构、原理、配置以及高级特性。首先,概述了测试框架的分类,并阐述了Walktour框架的优势。接着,深入解析了核心概念、测试生命周期、流程控制等关键要素。第三章到第五章重点介绍了如何搭建和自定义Walktour测试环境,编写测试用例,实现异常
【水文模拟秘籍】:HydrolabBasic软件深度使用手册(全面提升水利计算效率)

# 摘要
本文全面介绍HydrolabBasic软件,旨在为水文学研究与实践提供指导。文章首先概述了软件的基本功能与特点,随后详细阐述了安装与环境配置的流程,包括系统兼容性检查、安装步骤、环境变量与路径设置,以及针对安装过程中常见问题的解决方案。第三章重点讲述了水文模拟的基础理论、HydrolabBasic的核心算法以及数据处理技巧。第四章探讨了软件的高级功能,如参数敏感
光盘挂载效率优化指南:提升性能的终极秘籍
# 摘要
本文全面探讨了光盘挂载的基础知识、性能瓶颈、优化理论及实践案例,并展望了未来的发展趋势。文章从光盘挂载的技术原理开始,深入分析了影响挂载性能的关键因素,如文件系统层次结构、挂载点配置、读写速度和缓存机制。接着,提出了针对性的优化策略,包括系统参数调优、使用镜像文件以及自动化挂载脚本的应用,旨在提升光盘挂载的性能和效率。通过实际案例研究,验证了优化措施的有效
STM32F407ZGT6硬件剖析:一步到位掌握微控制器的10大硬件特性
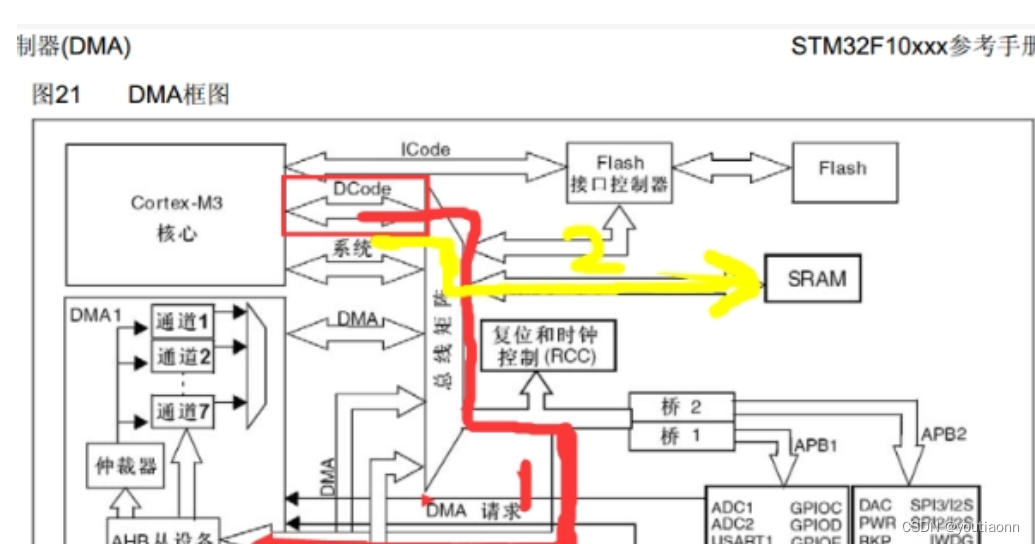
# 摘要
本文针对STM32F407ZGT6微控制器进行了全面的概述,重点分析了其核心处理器与存储架构。文章详细阐述了ARM Cortex-M4内核的特性,包括其性能和功耗管理能力。同时,探讨了内部Flash和RAM的配置以及内存保护与访问机制。此外,本文还介绍了STM32F407ZGT6丰富的外设接口与通信功能,包括高速通信接口和模拟/数字外设的集成。电源管理和低功耗
【系统性能优化】:专家揭秘注册表项管理技巧,全面移除Google软件影响

# 摘要
注册表项管理对于维护和优化系统性能至关重要。本文首先介绍了注册表项的基础知识和对系统性能的影响,继而探讨了优化系统性能的具体技巧,包括常规和高级优化方法及其效果评估。文章进一步深入分析了Google软件对注册表的作用,并提出了清理和维护建议。最后,通过综合案例分析,展示了注册表项优化的实际效果,并对注册表项管理的未来趋势进行了展望。本文旨在为读者提供注册表项管理的全面理解,并帮助他们有效提升系统性能。
SAPRO V5.7高级技巧大公开:提升开发效率的10个实用方法

# 摘要
本文全面介绍SAPRO V5.7系统的核心功能与高级配置技巧,旨在提升用户的工作效率和系统性能。首先,对SAPRO V5.7的基础知识进行了概述。随后,深入探讨了高级配置工具的使用方法,包括工具的安装、设置以及高级配置选项的应用。接着,本文聚焦于编程提升策略,分享了编码优化、IDE高级使用以及版本控制的策略。此外,文章详细讨论了系统维护和监控的
线扫相机选型秘籍:海康vs Dalsa,哪个更适合你?
# 摘要
本文对线扫相机技术进行了全面的市场分析和产品比较,特别聚焦于海康威视和Dalsa两个业界领先品牌。首先概述了线扫相机的技术特点和市场分布,接着深入分析了海康威视和Dalsa产品的技术参数、应用案例以及售后服务。文中对两者的核心性能、系统兼容性、易用性及成本效益进行了详尽的对比,并基于不同行业应用需求提出了选型建议。最后,本文对线扫相机技术的未来发展趋势进行了展望,并给出了综合决策建议,旨在帮助技术人员和采购者更好地理解和选择适合的线扫相机产品。
# 关键字
线扫相机;市场分析;技术参数;应用案例;售后服务;成本效益;选型建议;技术进步
参考资源链接:[线扫相机使用与选型指南——海
【Smoothing-surfer绘图性能飞跃】:图形渲染速度优化实战

# 摘要
图形渲染是实现计算机视觉效果的核心技术,其性能直接影响用户体验和应用的互动性。本文第一章介绍了图形渲染的基本概念,为理解后续内容打下基础。第二章探讨了图形渲染性能的理论基础,包括渲染管线的各个阶段和限制性能的因素,以及各种渲染算法的选择与应用。第三章则专注于性能测试与分析,包括测试工具的选择、常见性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )