Python机器学习从入门到精通:算法实践与应用全解析
发布时间: 2024-09-19 14:05:13 阅读量: 41 订阅数: 52 

基于遗传算法的动态优化物流配送中心选址问题研究(Matlab源码+详细注释),遗传算法与免疫算法在物流配送中心选址问题的应用详解(源码+详细注释,Matlab编写,含动态优化与迭代,结果图展示),遗传

# 1. Python机器学习入门基础
Python作为一门简洁且功能强大的编程语言,在机器学习领域也扮演着至关重要的角色。本章将带领读者从零开始,探讨Python在机器学习中的基本应用。
## 1.1 Python机器学习简介
Python机器学习是使用Python编程语言进行数据挖掘、数据分析及预测的实践。它使得复杂的算法和数据处理技术变得易于实现。Python库如NumPy, pandas, matplotlib等为数据处理提供了强大支持,而像scikit-learn和TensorFlow等库为构建和训练模型提供了便利。
## 1.2 Python在机器学习中的优势
Python之所以受到青睐,是因为它具有简单易学、开源免费、库丰富等优势。这些特性降低了学习门槛,并允许开发者快速搭建原型。另外,Python有着广泛的社区支持和丰富的教学资源,便于学习和解决问题。
## 1.3 安装Python和常用库
在开始机器学习项目之前,首先需要在计算机上安装Python。推荐使用Anaconda发行版,它包含了大量的数据科学库。安装完成后,使用pip或conda命令安装以下常用库:scikit-learn(机器学习)、NumPy和pandas(数据处理)、matplotlib(数据可视化)。
接下来的章节将深入探讨机器学习的核心算法,并通过实际案例来演示如何应用这些算法解决现实问题。从监督学习到无监督学习,再到强化学习,我们将逐步揭开机器学习的神秘面纱。
# 2. 核心机器学习算法的理论与实践
## 2.1 监督学习算法
### 2.1.1 线性回归的理论与代码实现
线性回归是监督学习中最简单、最常见的算法之一,用于预测连续值输出。它通过找到最优的回归系数,使得预测值与实际值之间的差异最小化。
#### 理论基础
线性回归模型假设特征与目标值之间存在线性关系,即:
y = β0 + β1x1 + β2x2 + ... + βnxn + ε
其中,y是目标变量,x1到xn是特征,β0是截距项,β1到βn是特征的权重,ε是误差项。
#### 代码实现
以下是使用Python的scikit-learn库实现线性回归的代码示例。
```python
# 导入线性回归模型和数据集
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
# 加载数据集
boston = load_boston()
X, y = boston.data, boston.target
# 创建线性回归模型实例
model = LinearRegression()
# 训练模型
model.fit(X, y)
# 打印回归系数
print('回归系数:', model.coef_)
print('截距:', model.intercept_)
# 预测并评估模型性能
from sklearn.metrics import mean_squared_error
y_pred = model.predict(X)
print('均方误差:', mean_squared_error(y, y_pred))
```
#### 参数说明
- `LinearRegression()`:创建线性回归模型。
- `fit`方法:用于训练模型。
- `coef_`属性:包含回归系数。
- `intercept_`属性:包含截距项。
- `predict`方法:用于基于模型进行预测。
- `mean_squared_error`:计算预测值与真实值之间的均方误差。
#### 执行逻辑
代码首先加载了波士顿房价数据集,然后创建了一个线性回归实例。使用`fit`方法将模型与数据拟合,之后通过`predict`方法进行预测,并使用均方误差来评估模型性能。
### 2.1.2 逻辑回归的理论与代码实现
逻辑回归虽然名字中包含“回归”,但实际上是用于分类问题的算法,它使用逻辑函数来预测二分类问题的概率。
#### 理论基础
逻辑回归模型基于sigmoid函数进行分类决策:
P(y=1|x) = 1 / (1 + e^(-z))
其中z为线性组合,z = β0 + β1x1 + ... + βnxn。
#### 代码实现
下面是使用scikit-learn库实现逻辑回归的代码示例。
```python
# 导入逻辑回归模型和数据集
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 创建逻辑回归模型实例,设置multi_class参数为'auto'
model = LogisticRegression(multi_class='auto')
# 训练模型
model.fit(X, y)
# 打印回归系数
print('回归系数:', model.coef_)
print('截距:', model.intercept_)
# 预测并评估模型性能
from sklearn.metrics import accuracy_score
y_pred = model.predict(X)
print('准确度:', accuracy_score(y, y_pred))
```
#### 参数说明
- `LogisticRegression()`:创建逻辑回归模型实例。
- `fit`方法:用于训练模型。
- `coef_`属性:包含逻辑回归的回归系数。
- `intercept_`属性:包含逻辑回归的截距项。
- `predict`方法:用于基于模型进行分类预测。
- `accuracy_score`:计算预测准确度。
#### 执行逻辑
在这段代码中,我们首先加载了鸢尾花数据集,然后创建了一个逻辑回归实例,并使用`fit`方法训练模型。之后,我们评估了模型在训练数据上的性能,通过计算准确度来了解模型的预测能力。
### 2.1.3 决策树与随机森林的理论与应用
决策树是一种分层的树状模型,用于分类和回归任务。而随机森林则是构建多个决策树并进行集成学习的算法。
#### 理论基础
决策树通过一系列问题的“是”或“否”来将数据分割成子集,直到达到特定的停止条件。随机森林则通过组合多个决策树来提高分类的准确性和防止过拟合。
#### 代码实现
以下是使用scikit-learn库实现决策树和随机森林的代码示例。
```python
# 导入决策树和随机森林模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 创建决策树模型实例
dt_model = DecisionTreeClassifier()
# 训练模型
dt_model.fit(X, y)
print("决策树模型的深度:", dt_model.tree_.max_depth)
# 创建随机森林模型实例
rf_model = RandomForestClassifier(n_estimators=100)
# 训练模型
rf_model.fit(X, y)
# 预测并评估模型性能
from sklearn.metrics import accuracy_score
y_pred = rf_model.predict(X)
print('随机森林的准确度:', accuracy_score(y, y_pred))
```
#### 参数说明
- `DecisionTreeClassifier()`:创建决策树模型实例。
- `RandomForestClassifier()`:创建随机森林模型实例,`n_estimators`参数设置树的数量。
- `fit`方法:用于训练模型。
- `tree_.max_depth`属性:输出决策树的深度。
- `predict`方法:用于基于模型进行预测。
- `accuracy_score`:计算预测准确度。
#### 执行逻辑
在这段代码中,我们使用鸢尾花数据集来训练一个决策树模型和一个随机森林模型。我们检查了决策树的深度,并使用随机森林模型在测试数据上评估准确度,以了解模型性能。
# 3. Python机器学习实战项目
在机器学习的世界里,理论知识与实际应用是相辅相成的。第二章深入探讨了机器学习的核心算法,现在,我们将通过实际的项目案例,将这些理论转化为实际应用。在本章节中,我们将着重讨论实战项目中的关键环节,包括数据预处理、特征工程、模型选择与评估,以及真实世界中的案例分析。我们不仅会介绍具体的实施步骤,还会分析背后的技术原理,帮助读者更好地理解如何将机器学习应用到实际问题解决中。
## 3.1 数据预处理与特征工程
数据是机器学习的基石。好的数据预处理和特征工程是确保模型能够有效学习的重要步骤。在本小节中,我们将深入探讨数据清洗的方法与技巧以及特征选择与提取技术。
### 3.1.1 数据清洗的方法与技巧
数据清洗是数据预处理中的一个核心环节,旨在去除数据中的噪声和异常值,确保数据的质量。以下是几种常见的数据清洗技巧:
- **处理缺失值**:缺失数据是数据集中的常见问题。常见的处理方法包括删除含有缺失值的样本、填充缺失值(如使用均值、中位数、众数或者根据模型预测的值)。
- **数据标准化/归一化**:在将数据输入到机器学习模型之前,通常需要对其进行标准化或归一化处理。这主要是为了消除不同量纲的影响,特别是当涉及到距离计算的算法时(比如K-NN算法)。
- **异常值处理**:异常值可能会影响模型的性能。处理异常值的常用方法包括使用Z-score、IQR(四分位距)等统计方法来识别异常值,并进行相应的处理。
- **数据转换**:数据转换是将数据从一个形式转换为另一种形式的过程。比如,对分类数据进行独热编码(One-Hot Encoding)使其适合算法模型处理。
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, ***
***pose import ColumnTransformer
from sklearn.pipeline import Pipeline
# 假设我们有一个包含数值型和分类型特征的DataFrame
data = pd.DataFrame({
'age': [25, 26, 27, 28, 29],
'category': ['A', 'B', None, 'C', 'D'],
'price': [200, 250, 205, 230, 260]
})
# 数值型特征的预处理步骤
numeric_features = ['age', 'price']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# 分类型特征的预处理步骤
categorical_features = ['category']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 预处理数据
data_cleaned = preprocessor.fit_transform(data)
```
### 3.1.2 特征选择与特征提取技术
特征选择是机器学

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“set python”专栏是一份全面的Python编程指南,专为新手和经验丰富的开发者设计。它涵盖了广泛的主题,从入门指南和环境配置到高级概念,如装饰器、上下文管理器和并发编程。专栏还深入探讨了异常处理、内存管理、数据分析和可视化,以及自动化脚本编写和性能优化。此外,它还提供了测试驱动开发的实用指南,帮助开发者编写健壮且可维护的代码。通过易于理解的解释、代码示例和实践技巧,“set python”专栏旨在帮助读者提升他们的Python技能,并有效地利用Python解决各种编程问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高效数据分析管理:C-NCAP 2024版数据系统的构建之道
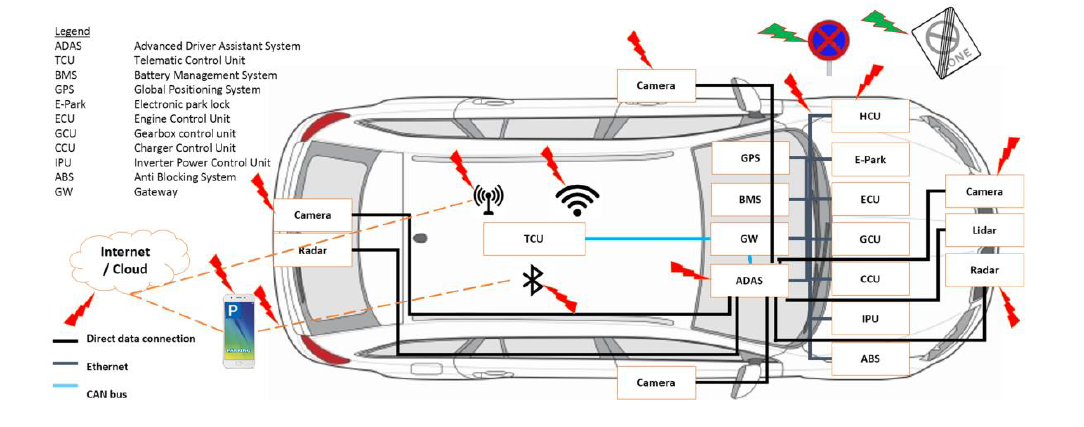
# 摘要
C-NCAP 2024版数据系统是涉及数据采集、存储、分析、挖掘及安全性的全面解决方案。本文概述了该系统的基本框架,重点介绍了数据采集技术、存储解决方案以及预处理和清洗技术的重要性。同时,深入探讨了数据分析方法论、高级分析技术的运用以及数据挖掘在实际业务中的案例分析。此外,本文还涵盖了数据可视化工具、管理决策支持以及系统安全性与可靠性保障策略,包括数据安全策略、系统冗余设计以及遵循相关法律法规。本文旨在为C
RS纠错编码在数据存储和无线通信中的双重大显身手
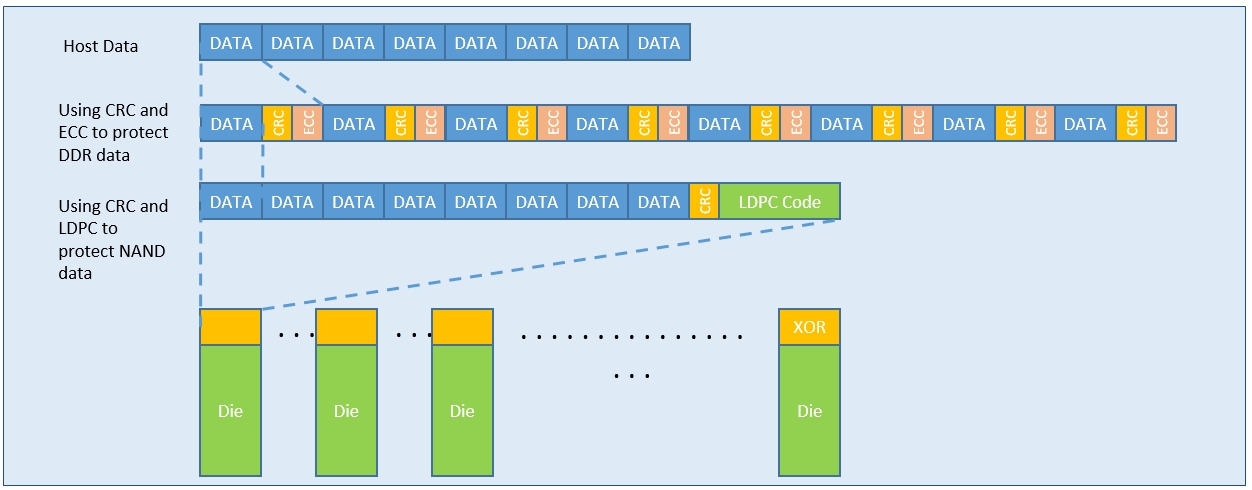
# 摘要
Reed-Solomon (RS)纠错编码是广泛应用于数据存储和无线通信领域的重要技术,旨在提高数据传输的可靠性和存储的完整性。本文从RS编码的理论基础出发,详细阐述了其数学原理、构造过程以及错误检测与纠正能力。随后,文章深入探讨了RS编码在硬盘驱动器、固态存储、内存系统以及无线通信系统中的实际应用和效能优化。最后,文章分析了RS编码技术面临的现代通信挑战,
【模式识别】:模糊数学如何提升识别准确性

# 摘要
模式识别与模糊数学是信息处理领域内的重要研究方向,它们在图像、语音以及自然语言理解等领域内展现出了强大的应用潜力。本文首先回顾了模式识别与模糊数学的基础理论,探讨了模糊集合和模糊逻辑在模式识别理论模型中的作用。随后,本文深入分析了模糊数学在图像和语音识别中的实
【Java异常处理指南】:四则运算错误管理与最佳实践

# 摘要
本文系统地探讨了Java异常处理的各个方面,从基础知识到高级优化策略。首先介绍了异常处理的基本概念、Java异常类型以及关键的处理关键字。接着,文章详细阐释了检查型和非检查型异常之间的区别,并分析了异常类的层次结构与分类。文章第三章专门讨论了四则运算中可能出现的错误及其管理方法,强调了用户交互中的异常处理策略。在最佳实践方面,文章探讨了代码组织、日志
【超效率SBM模型101】:超效率SBM模型原理全掌握

# 摘要
本文全面介绍和分析了超效率SBM模型的发展、理论基础、计算方法、实证分析以及未来发展的可能。通过回顾数据包络分析(DEA)的历史和基本原理,本文突出了传统SBM模型与超效率SBM模型的区别,并探讨了超效率SBM模型在效率评估中的优势。文章详细阐述了超效率SBM模型的计算步骤、软件实现及结果解释,并通过选取不同领域的实际案例分析了模
【多输入时序电路构建】:D触发器的实用设计案例分析

# 摘要
D触发器作为一种基础数字电子组件,在同步和异步时序电路设计中扮演着至关重要的角色。本文首先介绍了D触发器的基础知识和应用背景,随后深入探讨了其工作原理,包括电路组件、存储原理和电气特性。通过分析不同的设计案例,本文阐释了D触发器在复杂电路中实现内存单元和时钟控制电路的实用设计,同时着重指出设计过程中可能遇到的时序问题、功耗和散热问题,并提供了解
【内存管理技巧】:在图像拼接中优化numpy内存使用的5种方法

# 摘要
随着数据处理和图像处理任务的日益复杂化,图像拼接与内存管理成为优化性能的关键挑战。本文首先介绍了图像拼接与内存管理的基本概念,随后深入分析了NumPy库在内存使用方面的机制,包括内存布局、分配策略和内存使用效率的影响因素。本文还探讨了内存优化的实际技
【LDPC优化大揭秘】:提升解码效率的终极技巧
# 摘要
低密度奇偶校验(LDPC)编码与解码技术在现代通信系统中扮演着关键角色。本文从LDPC编码和解码的基础知识出发,深入探讨了LDPC解码算法的理论基础、不同解码算法的类别及其概率传播机制。接着,文章分析了LDPC解码算法在硬件实现和软件优化上的实践技巧,以及如何通过代码级优化提升解码速度。在此基础上,本文通过案例分析展示了优化技巧在实际应用中的效果,并探讨了LDPC编码和解码技术的未来发展方向,包括新兴应用领域和潜在技术突破,如量子计算与机器学习。通过对LDPC解码优化技术的总结,本文为未来通信系统的发展提供了重要的视角和启示。
# 关键字
LDPC编码;解码算法;概率传播;硬件实现
【跨平台开发技巧】:在Windows上高效使用Intel Parallel StudioXE

# 摘要
随着技术的发展,跨平台开发已成为软件开发领域的重要趋势。本文首先概述了跨平台开发的基本概念及其面临的挑战,随后介绍了Intel Parallel Studio XE的安装、配置及核心组件,探讨了其在Windows平台上的
Shape-IoU:一种更精准的空中和卫星图像分析工具(效率提升秘籍)
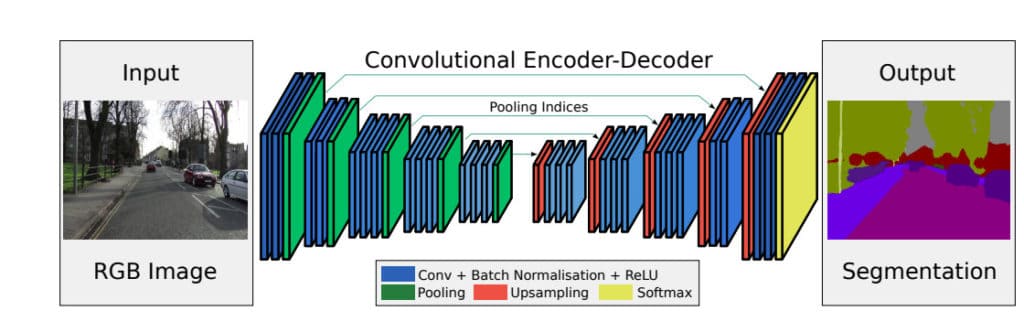
# 摘要
Shape-IoU工具是一种集成深度学习和空间分析技术的先进工具,旨在解决图像处理中的形状识别和相似度计算问题。本文首先概述了Shape-IoU工具及其理论基础,包括深度学习在图像处理中的应用、空中和卫星图像的特点以及空间分析的基本概念。随后,文章详细介绍了Shape-IoU工具的架构设计、IoU技术原理及其在空间分析中的优势
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )