机器学习算法在寿命预测中的应用:探索模型优劣
发布时间: 2024-07-11 05:22:52 阅读量: 60 订阅数: 50 

# 1. 机器学习算法概述
机器学习是一种人工智能领域,它使计算机能够从数据中学习,而无需显式编程。机器学习算法是执行学习过程的数学模型,它们可以从数据中提取模式和知识,并做出预测或决策。
机器学习算法可分为两大类:监督学习和无监督学习。监督学习算法使用带有标签的数据(输入和输出),而无监督学习算法使用未标记的数据。监督学习算法的示例包括线性回归、逻辑回归和决策树,而无监督学习算法的示例包括聚类分析和主成分分析。
# 2. 机器学习算法在寿命预测中的应用
机器学习算法在寿命预测中发挥着至关重要的作用,通过分析历史数据,这些算法可以识别影响寿命的关键因素并建立预测模型。这些模型可用于评估个体的寿命风险,从而制定个性化的健康干预措施。
### 2.1 监督学习算法
监督学习算法利用标记数据进行训练,其中输入数据与目标变量相关联。在寿命预测中,目标变量通常是寿命或与寿命相关的指标,例如死亡风险或预期寿命。
#### 2.1.1 线性回归
线性回归是一种监督学习算法,用于预测连续的目标变量。它建立一条直线,该直线拟合输入特征和目标变量之间的关系。在寿命预测中,线性回归可用于预测基于年龄、性别和其他人口统计信息的预期寿命。
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 加载数据
data = pd.read_csv('life_expectancy.csv')
# 提取特征和目标变量
X = data[['age', 'sex', 'country']]
y = data['life_expectancy']
# 训练模型
model = LinearRegression()
model.fit(X, y)
# 预测寿命
life_expectancy = model.predict([[60, 'male', 'United States']])
print(life_expectancy)
```
**逻辑分析:**
* `LinearRegression()` 创建一个线性回归模型。
* `fit()` 方法使用训练数据训练模型。
* `predict()` 方法使用训练好的模型预测寿命。
#### 2.1.2 逻辑回归
逻辑回归是一种监督学习算法,用于预测二分类的目标变量。它建立一个逻辑函数,该函数将输入特征映射到 0 和 1 之间的概率。在寿命预测中,逻辑回归可用于预测个体是否会在特定年龄之前死亡。
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
# 加载数据
data = pd.read_csv('mortality_risk.csv')
# 提取特征和目标变量
X = data[['age', 'sex', 'smoking', 'obesity']]
y = data['mortality_risk']
# 训练模型
model = LogisticRegression()
model.fit(X, y)
# 预测死亡风险
mortality_risk = model.predict_proba([[60, 'male', True, True]])[:, 1]
print(mortality_risk)
```
**逻辑分析:**
* `LogisticRegression()` 创建一个逻辑回归模型。
* `fit()` 方法使用训练数据训练模型。
* `predict_proba()` 方法使用训练好的模型预测死亡风险概率。
#### 2.1.3 决策树
决策树是一种监督学习算法,用于预测分类或连续的目标变量。它构建一个树状结构,其中每个节点表示一个特征,每个分支表示特征的不同值。在寿命预测中,决策树可用于预测影响寿命的因素,例如吸烟、肥胖和教育水平。
```python
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
# 加载数据
data = pd.read_csv('life_expectancy_factors.csv')
# 提取特征和目标变量
X = data[['age', 'sex', 'smoking', 'obesity', 'education']]
y = data['life_expectancy']
# 训练模型
model = DecisionTreeClassifier()
model.fit(X, y)
# 预测寿命
life_expectancy = model.predict([[60, 'male', True, True, 'high school']])
print(life_expectancy)
```
**逻辑分析:**
* `DecisionTreeClassifier()` 创建一个决策树分类器。
* `fit()` 方法使用训练数据训练模型。
* `predict()` 方法使用训练好的模型预测寿命。
# 3.1 评估指标
在评估机器学习模型的性能时,使用适当的指标至关重要。这些指标衡量模型预测的准确性和可靠性,并为模型选择和优化提供指导。在寿命预测中,常用的评估指标包括:
#### 3.1.1 均方根误差 (RMSE)
RMSE 衡量预测值与实际值之间的平均偏差。它计算如下:
```
RMSE = sqrt(1/n * Σ(y_pred - y_true)^2)
```
其中:
* `y_pred` 是预测值
* `y_true` 是实际值
* `n` 是样本数量
RMSE 值越小,模型预测的准确性越高。
#### 3.1.2 准确率
准确率衡量模型正确预测样本的比例。它计算如下:
```
Accuracy = (TP + TN) / (TP + TN + FP + FN)
```
其中:
* `TP` 是真阳性 (正确预测为阳性) 的样本数量
* `TN` 是真阴性 (正确预测为阴性) 的样本数量
* `FP` 是假阳性 (错误预测为阳性) 的样本数量
* `FN` 是假阴性 (错误预测为阴性) 的样本数量
准确率适用于二分类问题,其中输出只能是阳性或阴性。
#### 3.1.3 召回率
召回率衡量模型识别实际为阳性的样本的比例。它计算如下:
```
Recall = TP / (TP + FN)
```
召回率对于识别罕见事件或异常值非常重要。
### 3.2 模型选择
选择最佳的机器学习模型对于寿命预测至关重要。有几种方法可以帮助进行模型选择,包括:
#### 3.2.1 交叉验证
交叉验证是一种评估模型性能的统计方法。它将数据集分成多个子集,并使用每个子集作为测试集,而其余子集作为训练集。交叉验证可以防止过度拟合,并提供模型泛化能力的更可靠估计。
#### 3.2.2 网格搜索
网格搜索是一种超参数优化的技术。它通过在预定义的超参数值范围内系统地评估模型,来确定最佳超参数组合。网格搜索可以帮助提高模型的性能,并防止手动调整超参数带来的猜测。
# 4. 机器学习算法在寿命预测中的实践应用
### 4.1 数据收集和预处理
#### 4.1.1 数据源
寿命预测模型的准确性很大程度上取决于输入数据的质量和相关性。常用的数据源包括:
- **人口普查数据:**包含人口统计信息,如年龄、性别、教育水平和收入。
- **医疗记录:**提供有关疾病、治疗和生活方式的详细信息。
- **基因数据:**揭示遗传因素对寿命的影响。
- **环境数据:**包括空气质量、水质和气候条件。
#### 4.1.2 数据清洗和转换
收集到的原始数据通常包含缺失值、异常值和不一致性。为了提高模型性能,需要对数据进行清洗和转换,包括:
- **处理缺失值:**使用平均值、中位数或众数填充缺失值,或使用更复杂的算法(如 k-最近邻)进行插补。
- **处理异常值:**识别并删除异常值,或将其转换为更合理的值。
- **特征工程:**将原始特征转换为更适合建模的特征,如创建二元变量、对连续变量进行二值化或标准化。
### 4.2 模型训练和部署
#### 4.2.1 模型训练
选择合适的机器学习算法并对其进行训练是寿命预测的关键步骤。常用的算法包括:
- **线性回归:**用于预测连续变量(如寿命)。
- **逻辑回归:**用于预测二分类变量(如存活/死亡)。
- **决策树:**用于预测分类变量(如健康状况)。
训练过程涉及以下步骤:
1. **划分数据集:**将数据分为训练集和测试集。
2. **选择算法和超参数:**确定要使用的算法及其超参数(如学习率、正则化参数)。
3. **训练模型:**使用训练集训练模型。
4. **评估模型:**使用测试集评估模型的性能。
#### 4.2.2 模型部署
训练后的模型需要部署到生产环境中,以便对新数据进行预测。部署过程包括:
1. **选择部署平台:**选择云平台或本地服务器来部署模型。
2. **打包模型:**将训练好的模型打包成可执行文件或 API。
3. **集成模型:**将模型集成到应用程序或系统中。
4. **监控模型:**定期监控模型的性能并进行必要的调整。
# 5. 机器学习算法在寿命预测中的挑战和展望
### 5.1 数据质量和可用性
机器学习算法的性能高度依赖于训练数据的质量和可用性。在寿命预测中,收集和准备高质量的数据可能具有挑战性,原因如下:
- **数据稀缺性:**寿命数据通常难以获得,因为人们通常不会主动提供他们的健康信息。
- **数据偏差:**收集到的数据可能存在偏差,例如来自特定人群或地理区域的数据。
- **数据不一致:**不同来源的数据可能使用不同的测量标准或定义,导致不一致和难以比较。
为了解决这些挑战,需要采用以下策略:
- **数据增强:**通过合成或采样技术增加数据集的大小和多样性。
- **数据清洗和转换:**应用数据清洗技术来处理缺失值、异常值和数据不一致。
- **数据标准化:**建立标准化的数据收集和存储实践,以确保数据的质量和可比性。
### 5.2 模型解释性和可信度
机器学习算法的复杂性可能会导致其难以解释和理解。在寿命预测中,模型的可解释性和可信度至关重要,因为它们影响决策制定和患者信任。
以下策略可以提高模型的可解释性:
- **可解释性方法:**使用可解释性方法,例如SHAP值或LIME,来解释模型的预测。
- **简化模型:**探索更简单的模型,例如线性回归,以提高可解释性。
- **可视化:**创建可视化来展示模型的预测和决策过程。
提高模型的可信度需要:
- **模型验证:**通过交叉验证和独立测试数据集对模型进行彻底验证。
- **专家反馈:**征求领域专家的意见,以评估模型的合理性和可信度。
- **持续监控:**定期监控模型的性能,并根据需要进行调整和更新。
### 5.3 未来研究方向
机器学习算法在寿命预测中的应用是一个不断发展的领域,有许多令人兴奋的研究方向:
- **新的算法和技术:**探索新的机器学习算法和技术,例如深度学习和强化学习,以提高预测准确性。
- **多模态数据:**利用来自不同来源的多模态数据,例如电子健康记录、可穿戴设备和基因组数据。
- **个性化预测:**开发个性化的寿命预测模型,考虑个体特征和生活方式因素。
- **因果推理:**使用因果推理技术来确定影响寿命的因素,并制定有针对性的干预措施。
- **伦理和社会影响:**探索机器学习算法在寿命预测中的伦理和社会影响,例如公平性、隐私和偏见。
# 6. 结论
机器学习算法在寿命预测领域发挥着至关重要的作用,通过对大量数据的分析和建模,可以帮助我们更准确地预测个体的寿命。然而,这一领域仍面临着一些挑战和机遇。
**挑战:**
* **数据质量和可用性:**寿命预测需要高质量的数据,但收集和整理这些数据可能具有挑战性。
* **模型解释性和可信度:**机器学习模型的复杂性可能导致其解释和可信度下降,这可能会影响其在实际应用中的采用。
**机遇:**
* **不断发展的算法:**机器学习算法的持续发展为寿命预测提供了新的机会,例如深度学习和强化学习。
* **可穿戴设备和物联网:**可穿戴设备和物联网设备的普及提供了大量实时健康数据,可用于提高寿命预测模型的准确性。
* **个性化医疗:**机器学习算法可以帮助定制寿命预测模型,以适应个人的健康状况和生活方式。
随着这些挑战和机遇的不断演变,机器学习算法在寿命预测领域的前景一片光明。通过持续的研究和创新,我们可以进一步提高寿命预测的准确性,并为改善个体健康和福祉做出重大贡献。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《寿命预测》专栏深入探讨了寿命预测科学的各个方面,从传统统计到机器学习的演进,以及机器学习算法在寿命预测中的应用。文章涵盖了特征工程、模型评估、偏差和方差优化、落地实践、伦理考量和社会科学应用等主题。专栏还探讨了寿命预测模型在医疗保健、保险业、养老金管理中的应用,以及其局限性、误差来源和误用。此外,文章还强调了跨学科研究、国际合作和监管政策的重要性,以确保寿命预测模型的负责任和有效使用。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Django 事务管理:结合 django.db.models.sql.where 实现复杂事务逻辑
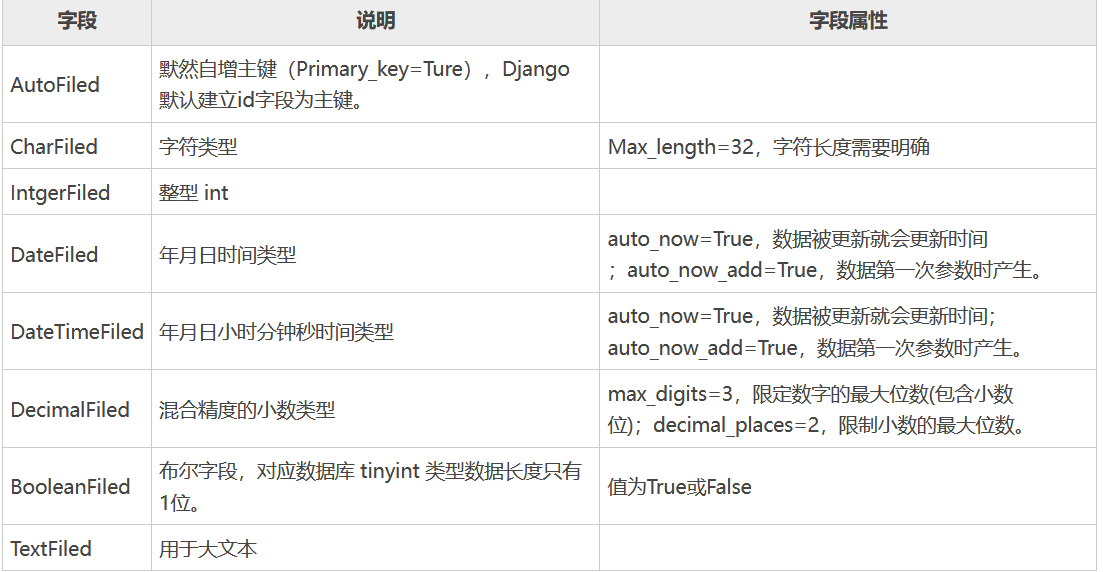
# 1. Django 事务管理概述
## 事务管理的重要性
在Web应用中,数据的一致性和完整性至关重要。Django作为一个强大的Python Web框架,提供了全面的事务管理支持,以确保数据操作的原子性、一致性、隔离性和持久性(ACID特性)。无论是处理复杂的业务逻辑,还是确保并发操作的安全性,Django的事务管理都是不可或
【Django意大利本地化应用】:选举代码与社会安全号码的django.contrib.localflavor.it.util模块应用

# 1. Django框架与本地化的重要性
## 1.1 Django框架的全球影响力
Django是一个高级的Python Web框架,它鼓励快速开发和干净、实用的设计。自2005年问世以来,它已经成为全球开发者社区的重要组成部分,支持着数以千计的网站和应用程序。
## 1.2 本地化在Django中的角色
本地化是软件国际化的一部分,它允许软件适应不同地区
Twisted.web.client的SSL_TLS支持:安全处理HTTPS连接的必知技巧
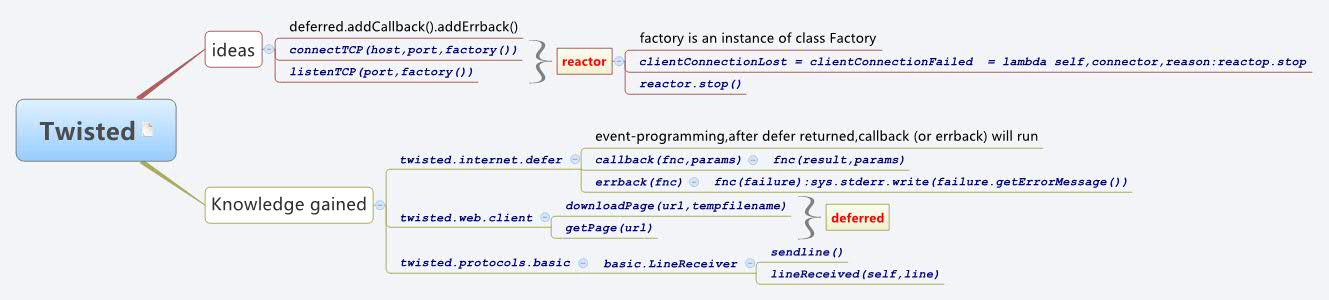
# 1. Twisted.web.client与SSL_TLS基础
在本章中,我们将首先介绍Twisted.web.client库的基础知识,以及SSL和TLS协议的基本概念。Twisted是一个事件驱动的Python网络框架,它提供了一个强大的异步HTTP客户端接口,而SSL/TLS是网络安全通信中不可或缺的加密协议,它们共同确保了数据传输的安全性和完整性。
##
Zope Component与测试驱动开发(TDD):编写可测试组件代码的10大技巧

# 1. Zope Component基础和测试驱动开发(TDD)简介
## 1.1 Zope Component基础
Zope Component(简称ZC)是一种用于构建Python应用程序的组件架构,它提供了一种灵活的方式来组装和重用代码。ZC的核心是基于接口的编程,
Werkzeug.exceptions库的异常监控:实时监控异常的发生和处理的秘诀
# 1. Werkzeug.exceptions库概述
在现代Web开发中,异常处理是保障应用稳定性和用户体验的关键环节。Werkzeug库提供了一个强大的异常处理模块,它为Python的WSGI标准提供了丰富的异常处理工具。Werkzeug.exceptions库不仅支持标准的异常类型,还允许开发者自定义异常,使得错误处理更加灵活和强
【WebOb与异步IO】:协程在WebOb中的应用与实践

# 1. WebOb与异步IO的基础概念
在现代Web开发中,异步IO和WebOb框架是提升性能和响应能力的关键技术。WebOb是一个用于Web请求处理的Python库,它提供了一套丰富的工具来模拟和分析HTTP请求和响应。异步IO则是一种编程范式,允许程序在等待I/O操作(如网络请求、文件读写)完成时继续执行其他任务,而不是阻塞
Twisted.web.http自定义服务器:构建定制化网络服务的3大步骤
# 1. Twisted.web.http自定义服务器概述
## 1.1 Twisted.web.http简介
Twisted是一个事件驱动的网络框架,它允许开发者以非阻塞的方式处理网络事件,从而构建高性能的网络应用。Twisted.web.http是Twisted框架中处理HTTP协议的一个子模块,它提供了一套完整的API来构建HTTP服务器。通过使用Twisted.web.http,开发者可以轻松地创
【Django admin自定义视图】:扩展功能,创建专属视图的高级教程
# 1. Django admin自定义视图基础
## Django admin自定义视图概述
Django admin是Django框架提供的一个强大的后台管理系统,它默认提供了很多方便的功能,如数据的增删改查等。然而,有时候我们需要根据自己的需求对admin进行一些定制化的修改,这就需要用到自定义视图的概念。自定义视图不仅可以提高我们
【Django Admin验证进阶】:实现复杂数据验证逻辑的6大策略
# 1. Django Admin的基本验证机制
## Django Admin的内置验证机制
Django Admin提供了一套内置的验证机制,这包括对模
【Python库文件学习之odict】:自定义odict类:专家指南

# 1. odict库概述与安装
## 1.1 odict库简介
odict(OrderedDict)是Python中collections模块提供的一个字典类,与普通的字典不同,odict保持了元素的插入顺序。这一特性使得odict在处理需要有序数据的场景中非常有用,比如数据的序列化、反序列化,以及需要保持数据顺序的算法实现等。odict的有序性是通过内部维护一个双向链表来实现的。
## 1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )