【大数据预测模型指南】:揭秘寿命预测的科学与实践
发布时间: 2024-07-11 05:18:42 阅读量: 60 订阅数: 25 
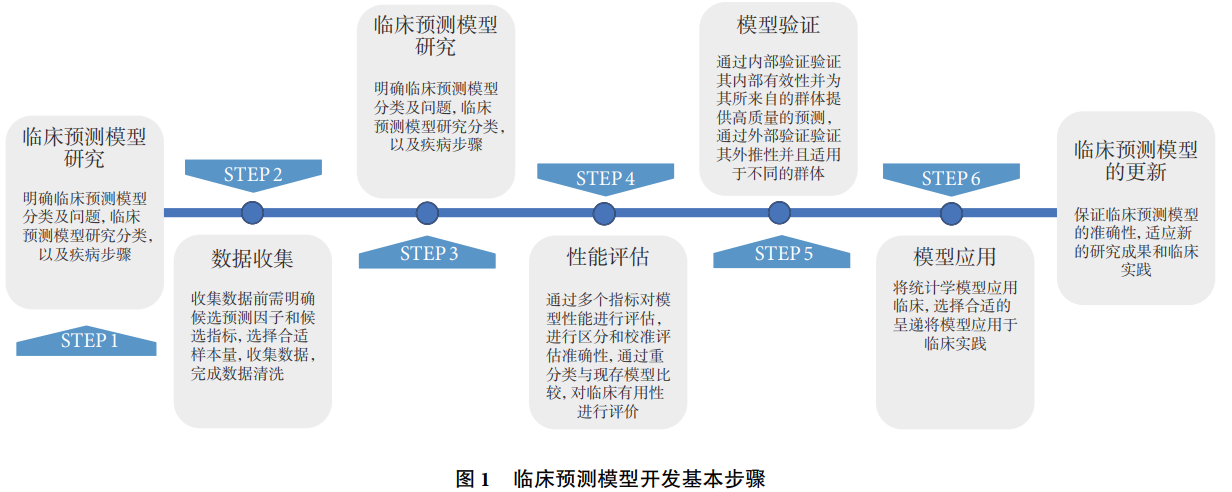
# 1. 大数据预测模型的理论基础**
大数据预测模型是利用大数据技术和机器学习算法,对未来事件或结果进行预测的模型。其理论基础主要涉及以下两个方面:
* **统计学基础:**概率论和统计推断为预测模型提供了数学基础。概率论描述了随机事件发生的可能性,而统计推断则允许我们从样本数据中推断总体特征。
* **机器学习算法:**机器学习算法是计算机从数据中学习模式和关系的能力。监督学习算法(如线性回归、决策树)用于预测数值或分类目标,而无监督学习算法(如聚类、降维)用于识别数据中的模式和结构。
# 2. 寿命预测模型的实践应用
### 2.1 数据收集与预处理
#### 2.1.1 数据来源和获取
寿命预测模型的构建依赖于高质量的数据。数据来源可以包括:
- **医疗记录:**电子病历、诊断代码、实验室结果和影像学数据。
- **人口统计数据:**年龄、性别、种族、教育水平和社会经济地位。
- **环境数据:**空气污染、水质和噪音水平。
- **行为数据:**吸烟、饮酒、饮食和运动习惯。
获取这些数据的方法包括:
- **数据采集:**从医疗机构、政府机构和研究机构收集数据。
- **数据购买:**从商业数据供应商购买匿名数据。
- **数据共享:**与其他研究人员和机构合作共享数据。
#### 2.1.2 数据清洗和转换
收集到的数据通常包含噪声、缺失值和不一致性。因此,需要进行数据清洗和转换以确保数据的质量:
- **数据清洗:**删除或更正错误、重复和异常值。
- **数据转换:**将数据转换为模型可用的格式,例如标准化、归一化和哑变量化。
### 2.2 模型选择与训练
#### 2.2.1 常用寿命预测模型
常用的寿命预测模型包括:
- **线性回归:**一种简单的线性模型,用于预测连续变量(例如寿命)与一组自变量(例如年龄和性别)之间的关系。
- **逻辑回归:**一种非线性模型,用于预测二分类结果(例如生存或死亡)的概率。
- **决策树:**一种基于规则的模型,将数据分割成更小的子集,直到达到停止条件。
- **随机森林:**一种集成模型,它组合多个决策树以提高预测精度。
- **神经网络:**一种受人脑启发的模型,可以学习复杂的数据模式。
#### 2.2.2 模型训练与评估
模型训练涉及将数据输入模型并调整模型参数以最小化预测误差。模型评估使用留出数据或交叉验证来评估模型的性能。评估指标包括:
- **均方误差 (MSE):**连续变量预测误差的平方。
- **准确率:**二分类变量预测正确的比例。
- **ROC 曲线:**绘制真实阳性率与假阳性率之间的关系,以评估模型区分能力。
### 2.3 模型部署与验证
#### 2.3.1 模型部署方法
训练好的模型可以通过以下方式部署:
- **批量预测:**一次性对大量数据进行预测。
- **实时预测:**对单个数据点进行实时预测。
- **API 集成:**将模型作为 API 公开,以便其他应用程序使用。
#### 2.3.2 模型验证与优化
部署后,模型需要持续验证和优化以确保其准确性和可靠性:
- **监控性能:**定期检查模型的预测性能,并识别任何下降迹象。
- **数据漂移检测:**监视数据分布的变化,并根据需要更新模型。
- **模型再训练:**使用新数据重新训练模型以提高其性能。
# 3. 寿命预测模型的科学原理
### 3.1 统计学基础
#### 3.1.1 概率论与统计推断
概率论是研究随机事件发生可能性的数学分支。它提供了量化不确定性的框架,是寿命预测模型的基础。
* **概率分布:**描述随机变量取值的可能性分布。常见分布包括正态分布、指数分布和泊松分布。
* **统计推断:**从样本数据中推断总体特征的过程。常用方法包括置信区间和假设检验。
#### 3.1.2 回归分析与预测
回归分析是一种统计建模技术,用于确定自变量与因变量之间的关系。在寿命预测中,回归模型可用于预测基于年龄、性别、健康状况等因素的预期寿命。
* **线性回归:**最简单的回归模型,假设因变量与自变量呈线性关系。
* **非线性回归:**用于处理因变量与自变量之间存在非线性关系的情况。
* **预测:**使用训练好的回归模型对新数据进行预测。
### 3.2 机器学习算法
#### 3.2.1 监督学习与无监督学习
* **监督学习:**从带标签的数据中学习,即数据中包含输入变量和目标变量。
* **无监督学习:**从不带标签的数据中学习,即数据中只有输入变量。
#### 3.2.2 常见机器学习算法
**监督学习算法:**
* **决策树:**根据特征值将数据递归地划分为子集,形成决策树。
* **支持向量机:**在高维空间中找到最佳超平面,将数据点分类。
* **神经网络:**受生物神经网络启发的算法,可学习复杂非线性关系。
**无监督学习算法:**
* **聚类:**将数据点分组为具有相似特征的簇。
* **降维:**将高维数据投影到低维空间,保留重要信息。
* **异常检测:**识别与正常数据点显著不同的异常值。
### 代码示例
#### 概率分布
```python
import numpy as np
# 创建正态分布
dist = np.random.normal(50, 10, 1000)
# 绘制分布直方图
plt.hist(dist, bins=50)
plt.show()
```
**逻辑分析:**
* `np.random.normal()` 函数生成一个正态分布的随机样本,其中 50 为均值,10 为标准差,1000 为样本大小。
* `plt.hist()` 函数绘制分布直方图,将数据划分为 50 个箱子。
#### 回归分析
```python
import statsmodels.api as sm
# 导入数据
data = sm.datasets.get_rdataset("stackloss").data
# 构建回归模型
model = sm.OLS(data["stackloss"], data[["airflow", "temp"]])
results = model.fit()
# 打印模型摘要
print(results.summary())
```
**逻辑分析:**
* `sm.OLS()` 函数构建一个普通最小二乘回归模型,其中 `stackloss` 为因变量,`airflow` 和 `temp` 为自变量。
* `results.fit()` 函数拟合模型并返回拟合结果。
* `results.summary()` 函数打印模型摘要,包括系数估计、标准误、t 值和 p 值。
# 4. 寿命预测模型的实践案例
### 4.1 医疗保健领域的应用
#### 4.1.1 疾病风险预测
在医疗保健领域,寿命预测模型被广泛用于预测个体患上特定疾病的风险。这对于早期干预和预防至关重要。
**案例:心脏病风险预测**
* **数据收集:**收集患者的年龄、性别、家族病史、生活方式和医疗记录等数据。
* **模型选择:**使用逻辑回归模型,该模型可以处理二分类问题(心脏病风险高/低)。
* **模型训练:**将数据分为训练集和测试集,使用训练集训练模型,并使用测试集评估模型的性能。
* **模型部署:**将训练好的模型部署到临床环境中,为患者提供心脏病风险预测。
#### 4.1.2 治疗方案优化
寿命预测模型还可以用于优化治疗方案,帮助医生为患者选择最合适的治疗方法。
**案例:癌症治疗方案优化**
* **数据收集:**收集患者的肿瘤类型、分期、治疗史和预后等数据。
* **模型选择:**使用决策树模型,该模型可以处理多分类问题(不同治疗方案)。
* **模型训练:**将数据分为训练集和测试集,使用训练集训练模型,并使用测试集评估模型的性能。
* **模型部署:**将训练好的模型部署到临床环境中,为医生提供治疗方案建议。
### 4.2 保险领域的应用
#### 4.2.1 保费定价
在保险领域,寿命预测模型被用于确定保费。通过预测个体的预期寿命,保险公司可以评估其承保风险并相应调整保费。
**案例:人寿保险保费定价**
* **数据收集:**收集投保人的年龄、性别、健康状况、生活方式和家族病史等数据。
* **模型选择:**使用生存分析模型,该模型可以处理生存时间数据。
* **模型训练:**将数据分为训练集和测试集,使用训练集训练模型,并使用测试集评估模型的性能。
* **模型部署:**将训练好的模型部署到保险公司系统中,用于保费定价。
#### 4.2.2 风险评估
寿命预测模型还可以用于评估保险公司的风险敞口。通过预测客户群体的预期寿命,保险公司可以制定适当的风险管理策略。
**案例:健康保险风险评估**
* **数据收集:**收集投保人的年龄、性别、健康状况、生活方式和医疗记录等数据。
* **模型选择:**使用贝叶斯网络模型,该模型可以处理复杂的不确定性。
* **模型训练:**将数据分为训练集和测试集,使用训练集训练模型,并使用测试集评估模型的性能。
* **模型部署:**将训练好的模型部署到保险公司系统中,用于风险评估。
# 5. 寿命预测模型的未来发展
### 5.1 新兴技术与趋势
**5.1.1 大数据与云计算**
大数据和云计算的兴起为寿命预测模型的发展带来了新的机遇。大数据提供了海量的历史数据,使模型能够从更全面的数据中学习,提高预测精度。云计算平台提供了强大的计算能力,使模型能够处理大规模的数据集,缩短训练和预测时间。
**5.1.2 人工智能与深度学习**
人工智能(AI)和深度学习技术在寿命预测领域也发挥着越来越重要的作用。深度学习算法能够自动从数据中提取特征,并建立复杂非线性的预测模型。这些模型能够捕捉数据中的隐藏模式,提高预测性能。
### 5.2 伦理与社会影响
**5.2.1 隐私保护**
寿命预测模型使用个人数据进行训练和预测,因此隐私保护至关重要。需要制定严格的隐私法规和道德准则,以保护个人信息免遭滥用。
**5.2.2 歧视与偏见**
寿命预测模型可能会受到训练数据中的偏见影响,导致对某些群体的不公平预测。例如,如果模型在训练时使用的是来自特定人口群体的历史数据,它可能会对其他人口群体做出不准确的预测。需要采取措施减轻偏见,确保模型公平公正。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《寿命预测》专栏深入探讨了寿命预测科学的各个方面,从传统统计到机器学习的演进,以及机器学习算法在寿命预测中的应用。文章涵盖了特征工程、模型评估、偏差和方差优化、落地实践、伦理考量和社会科学应用等主题。专栏还探讨了寿命预测模型在医疗保健、保险业、养老金管理中的应用,以及其局限性、误差来源和误用。此外,文章还强调了跨学科研究、国际合作和监管政策的重要性,以确保寿命预测模型的负责任和有效使用。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
拷贝构造函数的陷阱:防止错误的浅拷贝
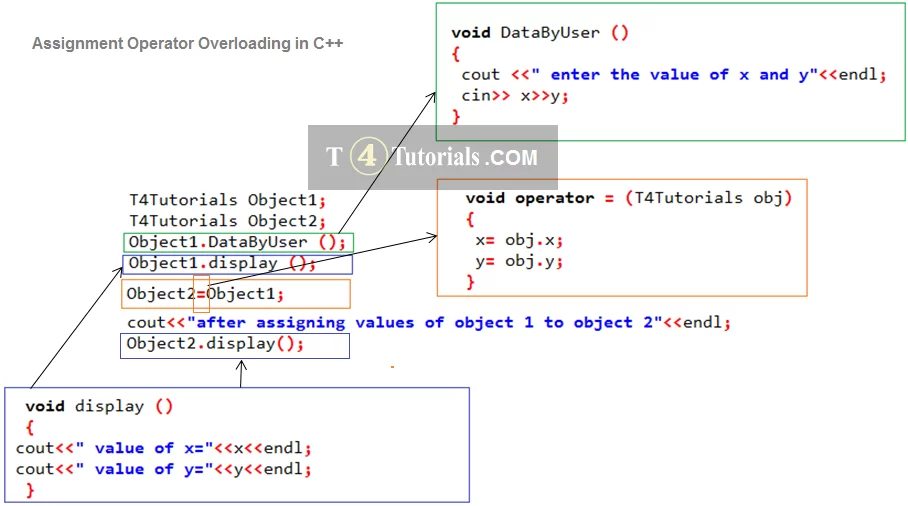
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
消息队列在SSM论坛的应用:深度实践与案例分析

# 1. 消息队列技术概述
消息队列技术是现代软件架构中广泛使用的组件,它允许应用程序的不同部分以异步方式通信,从而提高系统的可扩展性和弹性。本章节将对消息队列的基本概念进行介绍,并探讨其核心工作原理。此外,我们会概述消息队列的不同类型和它们的主要特性,以及它们在不同业务场景中的应用。最后,将简要提及消息队列
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
【MATLAB在Pixhawk定位系统中的应用】:从GPS数据到精确定位的高级分析

# 1. Pixhawk定位系统概览
Pixhawk作为一款广泛应用于无人机及无人车辆的开源飞控系统,它在提供稳定飞行控制的同时,也支持一系列高精度的定位服务。本章节首先简要介绍Pixhawk的基本架构和功能,然后着重讲解其定位系统的组成,包括GPS模块、惯性测量单元(IMU)、磁力计、以及_barometer_等传感器如何协同工作,实现对飞行器位置的精确测量。
我们还将概述定位技术的发展历程,包括
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
JavaScript人脸识别中的实时反馈机制:提升用户体验

# 1. JavaScript人脸识别技术概述
人脸识别技术正变得越来越普及,并在各种应用中扮演着重要角色,从安全系统到社交媒体应用,再到个性化用户体验。JavaScript由于其在浏览器端的原生支持,已成为实现网页上的人脸识别功能的首选语言。使用JavaScript进行人脸识别不仅依赖于高效的算法,还需要强大的浏览器兼容性和用户友好的实
【注意力计算之谜】:CBAM背后的数学原理与计算策略

# 1. 注意力计算概述
## 1.1 计算机视觉中的注意力机制
计算机视觉作为人工智能领域的重要分支,在模式识别、图像分类、目标检测等任务中取得了显著的成果。传统的计算机视觉模型依赖于手工特征提取,而深度学习的出现使得自动特征学习成为可能。在深度学习
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )