MapReduce实战指南:优缺点分析与大数据优化技巧揭秘
发布时间: 2024-10-30 11:06:17 阅读量: 22 订阅数: 30 

# 1. MapReduce概念与基础
MapReduce是一种分布式数据处理模型和框架,最初由Google提出,并被广泛应用于大规模数据集的处理和分析。MapReduce将复杂的数据处理过程分解为两个关键步骤:Map(映射)和Reduce(归约)。Map阶段负责处理输入数据,将其转换为一系列中间的键值对;Reduce阶段则对这些中间键值对进行合并处理,最终输出结果。
MapReduce框架隐藏了分布式计算的复杂性,允许开发者仅关注于编写Map和Reduce函数本身,而无需关心底层的并行计算细节。它通常在Hadoop分布式文件系统(HDFS)上运行,利用其容错性和扩展性,能够高效地处理PB级别的数据。
让我们通过一个简单的例子来说明MapReduce的工作原理:
```java
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
```
在这个例子中,TokenizerMapper类将输入的文本分割成单词,并输出单词作为键,数值1作为值。IntSumReducer类则将相同键的所有值累加,最终得到每个单词的总出现次数。
MapReduce的这种编程模式非常适合于处理大量无结构或半结构化的数据,如日志文件分析、数据仓库ETL(提取、转换、加载)等场景。通过MapReduce,开发者可以轻松构建可扩展的数据处理任务,利用大规模的计算资源来加快数据处理速度。
# 2. MapReduce框架深入解析
## 2.1 MapReduce的运行机制
### 2.1.1 作业执行流程
MapReduce作业从提交到执行完毕,涉及几个关键的阶段:作业初始化、任务调度、任务执行、任务监控和状态更新、作业完成。
- **作业初始化**:用户通过编写MapReduce程序后,提交给Hadoop集群,这个阶段,作业会进行初始化,包括对程序代码的验证,资源配置的检查等。
- **任务调度**:Hadoop集群的资源管理器(YARN的ResourceManager)根据集群的资源使用情况和作业需求,对作业进行任务调度。
- **任务执行**:一旦任务被分配到具体节点,任务执行器(NodeManager)会启动Map或Reduce任务。
- **任务监控和状态更新**:任务执行期间,ResourceManager和NodeManager会不断监控任务执行的状态,并更新状态信息。
- **作业完成**:所有任务执行完毕并且成功,作业即被标记为完成状态,结果被写入到输出路径。
### 2.1.2 Map和Reduce阶段的工作原理
- **Map阶段**:Map阶段的任务是处理输入数据,并将处理结果写入到内存缓冲区,然后写入磁盘。Map任务主要功能是读取输入数据,并将数据分解成键值对(key-value pairs),然后根据key进行分区处理,并进行初级排序(Shuffle前的排序)。
- **Reduce阶段**:Reduce阶段的任务是对Map阶段输出的中间数据进行处理,一般包含Shuffle和Reduce两个过程。Shuffle过程是指把Map端的输出根据key的值进行合并,并传递给相应的Reduce任务。Reduce任务则进行全局排序,然后执行应用逻辑处理,最后输出结果。
### 2.1.3 MapReduce作业调度流程
为了更深入了解MapReduce的运行机制,下面是一个详细解释的作业调度流程图:
```mermaid
graph LR
A[开始] --> B[作业提交]
B --> C[初始化作业]
C --> D[任务调度]
D -->|任务分配给节点| E[任务执行]
E --> F[监控任务状态]
F --> G{任务完成?}
G -- 是 --> H[作业成功结束]
G -- 否 --> I[处理失败任务]
I --> E
```
## 2.2 MapReduce编程模型
### 2.2.1 Key-Value对处理
MapReduce编程模型核心是处理键值对(key-value pairs)。在Map阶段,输入数据被切分成多个小块(split),每个split被一个Map任务处理。Map函数读取输入数据,输出一系列的中间键值对(key-value pairs)。
在Reduce阶段,所有相同key的中间键值对被汇总起来,然后传递给Reduce函数进行处理。Reduce函数的输入是键(key)和与之关联的值(values)列表。
### 2.2.2 分区器和排序机制
**分区器**的作用是确定输出的中间键值对应该发送给哪个Reduce任务。默认情况下,使用的是HashPartitioner,它根据key的哈希值对key进行分区。
**排序机制**包括两个阶段:Map端排序和Reduce端排序。Map端排序在输出键值对前,对它们进行局部排序。然后这些数据被写入到磁盘上。Reduce端排序则是在Shuffle阶段从所有Map任务中拉取数据,进行全局排序。
## 2.3 MapReduce的配置与优化
### 2.3.1 集群参数调优
Hadoop的配置参数非常丰富,通过合理配置参数,能够显著提高MapReduce作业的执行效率和集群资源的利用率。重要的配置参数包括:
- `mapreduce.job.maps`:设置Map任务的数量。
- `mapreduce.job.reduces`:设置Reduce任务的数量。
- `mapreduce.input.fileinputformat.split.minsize`:设置输入数据的最小块大小。
- `mapreduce.task.io.sort.factor`:设置排序时使用的缓冲区大小。
### 2.3.2 任务执行器和资源调度
在YARN中,任务执行器是NodeManager。它负责启动和终止任务容器(Container),监控任务资源使用情况,并与ResourceManager协同工作,以满足应用程序的资源需求。ResourceManager通过调度器来管理集群资源,常见的调度器有Fair Scheduler和Capacity Scheduler。
以上章节内容对MapReduce框架进行了深入解析。接下来的章节将讨论MapReduce的实战技巧与案例分析。
# 3. MapReduce实战技巧与案例分析
## 3.1 数据预处理与输入格式
### 3.1.1 数据清洗和格式化
在进行MapReduce任务之前,数据预处理是一个至关重要的步骤,它包括数据清洗和数据格式化,这两者是确保数据质量、提高MapReduce处理效率的关键。
数据清洗是去除无效数据、修正错误数据、处理重复记录以及填充缺失值的过程。有效的数据清洗可以减少Map阶段处理的不必要工作,避免资源的浪费,并且减少错误的输出。
数据格式化涉及到数据的规范整理,比如统一日期时间格式,将文本数据转换为结构化数据,例如CSV或JSON格式。这对于后续MapReduce处理中键值对的提取至关重要。
代码块示例:
```java
// 示例:使用Java代码进行简单的数据清洗和格式化
public static List<String> preprocessData(String inputPath, String outputPath) {
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析了 MapReduce,一种大数据处理框架。它深入探讨了 MapReduce 的原理、优缺点、实际应用和性能优化指南。通过与 Spark 的对比分析,它突出了 MapReduce 的优势和劣势。专栏还提供了 MapReduce 的实战指南,包括优化技巧和在金融和电信行业中的应用。此外,它探讨了 MapReduce 在机器学习、云计算和日志分析中的应用,以及如何发挥其优势并应对挑战。通过深入浅出的解释和实际案例,本专栏为读者提供了全面了解 MapReduce 及其在各种大数据场景中的应用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
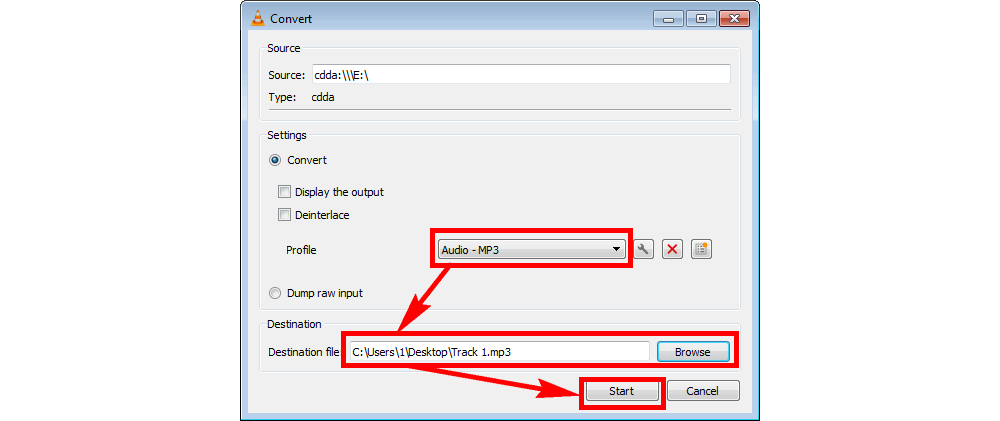
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
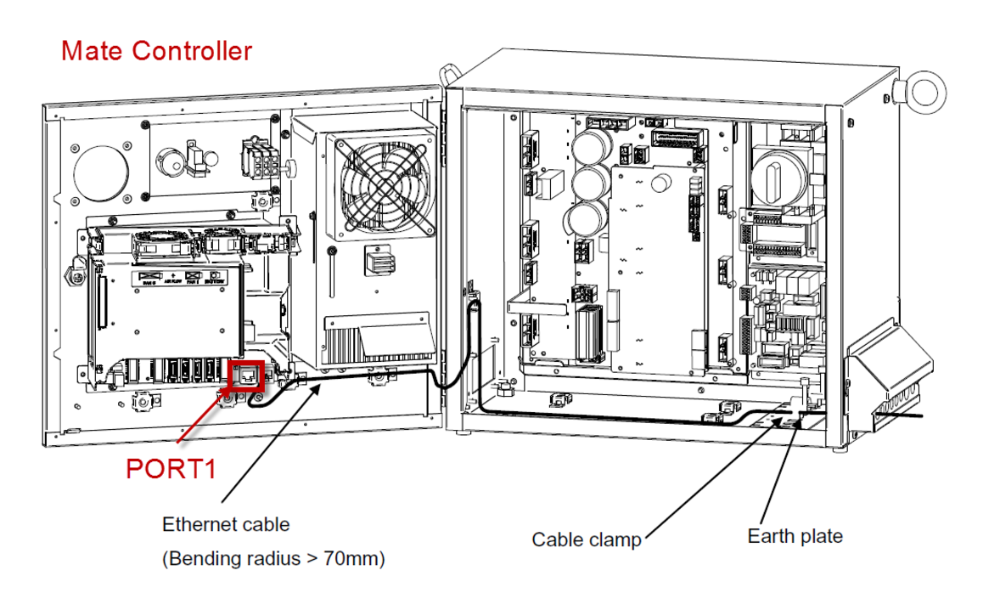
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
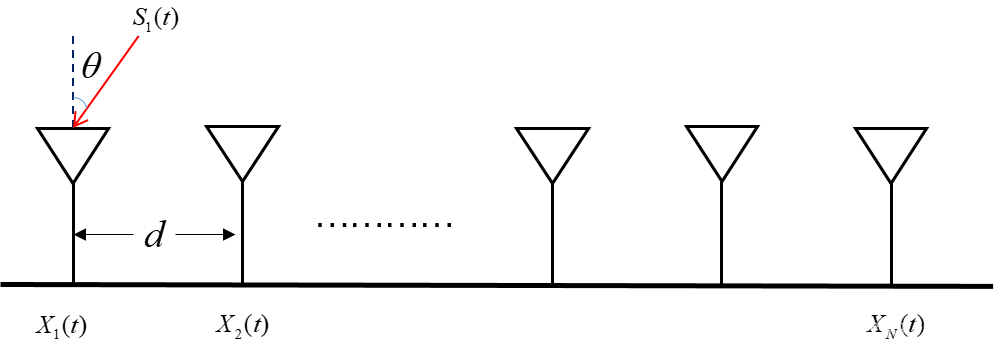
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
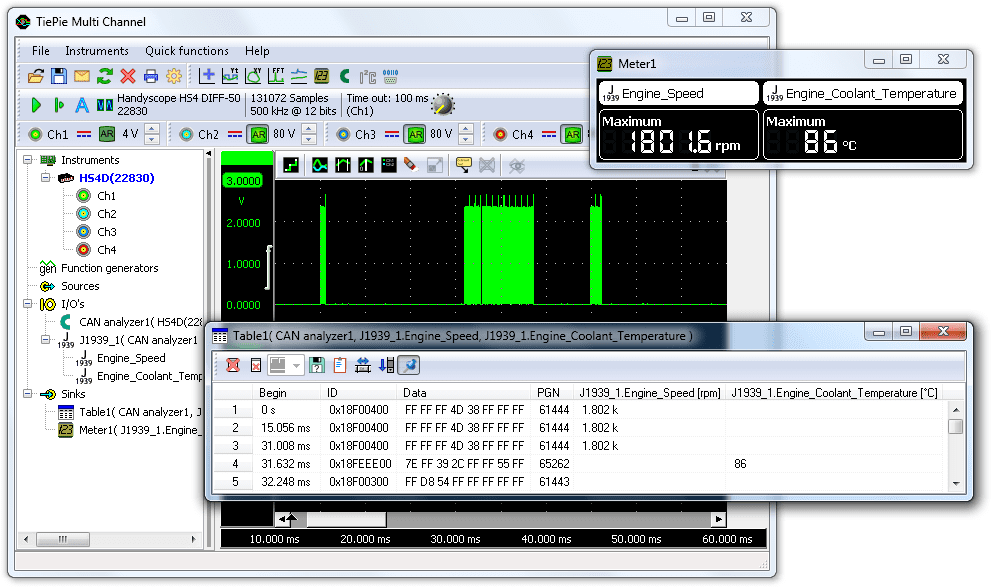
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )