高效算法构建指南:掌握栈、队列与树结构的实战应用
发布时间: 2024-12-19 04:00:09 阅读量: 4 订阅数: 4 

计算机算法秘籍阅读指南
# 摘要
本文全面介绍了数据结构的基础知识,并深入探讨了栈和队列在理论与实践中的应用,包括其基本操作、性质以及算法实例。接着,文章深入分析了树结构的构建与遍历,二叉搜索树的原理及平衡树和堆结构的高级应用。此外,本文还论述了高效算法设计技巧,如算法复杂度分析、贪心算法与动态规划,以及分治法与回溯算法。最后,文章通过实际案例分析展示了数据结构在大数据处理、网络编程和算法优化中的应用。本文旨在为读者提供一份全面的数据结构知识指南,并着重强调了在解决实际问题时选择合适数据结构的重要性。
# 关键字
数据结构;栈;队列;树结构;算法设计;大数据处理
参考资源链接:[数据结构1800题详解:考研&自学必备](https://wenku.csdn.net/doc/6469ced0543f844488c330fd?spm=1055.2635.3001.10343)
# 1. 数据结构基础知识概述
数据结构是计算机存储、组织数据的方式,是程序设计的基础。它不仅影响代码的效率,也决定了程序解决问题的能力。掌握数据结构,就如同拥有了建筑大师手中的工具箱,可以更加灵活地设计出满足特定需求的高效算法。
## 1.1 数据结构的分类
数据结构通常分为两大类:线性结构和非线性结构。
- 线性结构包括数组、链表、栈和队列,它们在逻辑上呈现一条线,每个元素最多只有一个前驱和一个后继。
- 非线性结构包括树和图,它们的元素之间有多个前驱和后继,例如树的每个节点可以有多个子节点。
## 1.2 抽象数据类型(ADT)
在讨论数据结构时,我们经常听到抽象数据类型(ADT)这个概念。ADT是指一个定义明确的数据和操作集,它们与具体的实现细节无关。例如,栈是一种ADT,它提供了一组操作:压入(push)、弹出(pop)、查看栈顶元素(peek)等。
## 1.3 数据结构的重要性
理解数据结构的核心在于选择合适的数据结构以解决实际问题。例如,在需要快速检索的情况下,我们可能会选择哈希表而不是列表。掌握数据结构知识,可以帮助我们编写出更优雅、高效的代码。
在接下来的章节中,我们将深入了解一些基本的数据结构,包括栈和队列,以及它们在算法中的应用实例。我们将探讨它们的基本操作、性质以及如何在实际问题中运用。让我们开始这段探索之旅吧!
# 2. 栈和队列的理论与实践
## 2.1 栈的概念及其算法应用
### 2.1.1 栈的基本操作和性质
栈是一种后进先出(Last In First Out, LIFO)的数据结构,它有两个主要的操作:压栈(push)和弹栈(pop)。压栈操作将一个元素添加到栈顶,而弹栈操作则移除栈顶元素。栈的这种特性使得它非常适合解决一些特定类型的问题,比如括号匹配、函数调用栈和撤销操作等。
```plaintext
栈的操作可以总结为:
- push(e):将元素e加入到栈顶。
- pop():移除并返回栈顶元素,如果栈为空则抛出异常。
- top():返回栈顶元素,不移除它。
- isEmpty():检查栈是否为空。
```
栈的实现通常有数组和链表两种方式。数组实现的栈具有固定大小,访问速度快,但可能会有空间浪费;链表实现的栈可以动态扩展,空间利用更灵活,但增加了额外的空间开销用于存储指针。
### 2.1.2 栈在算法中的应用实例
栈在算法中的应用非常广泛,特别是在处理递归调用、表达式求值和深度优先搜索(DFS)等问题时显得尤为重要。
以表达式求值为例,考虑一个后缀表达式(逆波兰表示法)的计算问题。算法可以通过一个栈来实现,从左到右扫描表达式中的每个字符,遇到数字就压栈,遇到操作符就从栈中弹出两个元素进行计算,并将结果压栈。最后,栈顶元素就是整个表达式的计算结果。
```plaintext
输入:[1, 2, '+', 3, '*', 4, '+']
输出:20
解释:
首先将1和2压栈,然后遇到'+',弹出2和1进行加法操作得到3,压栈。
接着,数字3压栈,遇到'*',弹出3和3进行乘法操作得到9,压栈。
然后数字4压栈,最后遇到'+',弹出4和9进行加法操作得到13,压栈。
栈顶元素13即为最终结果。
```
## 2.2 队列的概念及其算法应用
### 2.2.1 队列的基本操作和性质
队列是一种先进先出(First In First Out, FIFO)的数据结构,它同样有两个基本操作:入队(enqueue)和出队(dequeue)。入队操作是在队列尾部添加一个元素,而出队操作则是移除队列头部的元素。队列的这种性质使得它在处理如任务调度、缓冲区管理和广度优先搜索(BFS)等问题时非常有效。
```plaintext
队列的操作可以总结为:
- enqueue(e):将元素e添加到队尾。
- dequeue():移除并返回队首元素,如果队列为空则抛出异常。
- front():返回队首元素,不移除它。
- isEmpty():检查队列是否为空。
```
队列的实现方法主要有数组和链表两种。数组实现的队列具有固定大小,适合实现环形队列,以提高空间利用率;链表实现的队列可以动态扩展,适合实现单向或双向循环链表。
### 2.2.2 队列在算法中的应用实例
队列的一个典型应用实例是广度优先搜索算法(BFS)。在图的遍历中,BFS能够确保从起点出发,访问距离起点最近的所有顶点,然后再访问距离更远的顶点。这保证了最短路径问题的解的正确性。
以图的遍历为例,算法使用一个队列来存储待访问的顶点,从起点开始将所有相邻的顶点入队,然后出队一个顶点并访问它,将其未被访问的相邻顶点入队,重复此过程直到队列为空。
```plaintext
输入:图G = (V, E),起始顶点v
输出:顶点的访问顺序
过程:
1. 创建一个空队列Q。
2. 将顶点v入队。
3. 当Q不为空时,执行以下步骤:
a. 将顶点u从Q中出队。
b. 访问u。
c. 遍历u的所有未被访问的邻接顶点w,将它们入队并标记为已访问。
```
## 2.3 栈与队列的混合运用
### 2.3.1 双端队列和优先队列的实现
双端队列是一种既可以从头部入队也可以从尾部入队,既可以从头部出队也可以从尾部出队的数据结构。它结合了栈和队列的特点,适用于需要在两端频繁插入和删除的场景。
优先队列是一种元素按照某种优先级顺序出队的数据结构。通常,它允许插入任意的元素,但每次出队的是优先级最高的元素。优先队列通常使用堆(最小堆或最大堆)来实现。
### 2.3.2 实际问题中的栈与队列结合使用
在实际问题中,栈和队列的结合使用能够解决更复杂的问题。例如,在操作系统中,进程调度可以通过一个优先队列来实现,以决定下一个执行的进程;同时,每个进程的内部可以使用栈来存储其调用栈信息。又如,在网络通信中,数据包的传输可以使用队列来进行缓冲处理,而栈则可以在数据包的解析过程中使用,以跟踪协议栈的状态。
```plaintext
例如,一个简单的邮件系统可能需要实现邮件的发送和接收:
- 发送邮件时,新邮件被加入到一个队列中,邮件服务器按照先进先出的顺序将邮件发送出去。
- 接收邮件时,可以将接收到的邮件存入栈中,用户在读取邮件时可以按照后进先出的顺序阅读最新的邮件。
```
```mermaid
flowchart LR
A[开始] --> B{是否有新邮件}
B -- 是 --> C[加入队列]
B -- 否 --> D{用户请求读取}
C --> E[按FIFO顺序发送]
D -- 是 --> F[加入栈]
F --> G[按LIFO顺序读取]
D -- 否 --> H[等待用户请求]
G --> I[结束]
```
通过这种方式,栈和队列的结合使用不仅提高了效率,还优化了用户体验。
# 3. 树结构的深入理解和应用
## 3.1 二叉树的构建与遍历
### 3.1.1 二叉树的定义和性质
二叉树是一种重要的数据结构,它是每个节点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。二叉树在逻辑上可以形成一种层次结构,从树根开始,每个节点都可能延伸出两个分支,这种数据结构在计算机科学中具有广泛的应用。
二叉树的性质包括但不限于:
- 第 i 层的节点数最多为 2^(i-1) (i ≥ 1)。
- 深度为 k 的二叉树最多有 2^k - 1 个节点(k ≥ 1)。
- 对于任何非空二叉树,如果叶节点的数目为 n0,度为 2 的节点数为 n2,则 n0 = n2 + 1。
### 3.1.2 前序、中序、后序遍历算法
二叉树的遍历是指按照某种规则访问树中的每个节点一次且仅一次。常见的遍历方法有前序遍历、中序遍历和后序遍历。
- 前序遍历(Pre-order Traversal):首先访问根节点,然后前序遍历左子树,接着前序遍历右子树。
- 中序遍历(In-order Traversal):首先中序遍历左子树,然后访问根节点,最后中序遍历右子树。
- 后序遍历(Post-order Traversal):首先后序遍历左子树,然后后序遍历右子树,最后访问根节点。
这些遍历方法可以通过递归函数或者迭代方法(使用栈)实现。下面是一个使用递归方法实现的前序遍历的伪代码示例:
```python
def preorder_traversal(node):
if node is None:
return
visit(node)
preorder_traversal(node.left)
preorder_traversal(node.right)
```
### 3.1.3 遍历算法的代码逻辑解读
上述前序遍历的伪代码中,`visit(node)` 函数的作用是对当前节点进行操作,如打印节点值。递归调用 `preorder_traversal` 函数分别对左子树和右子树进行前序遍历。递归方法之所以简单是因为它隐藏了栈的使用,每次递归都会在系统调用栈中增加一层,直到访问到叶子节点,然后逐层返回。
在实际编程中,递归方法可能造成栈溢出,特别是在处理大型二叉树时。因此,迭代方法使用显式的栈来避免这个问题:
```python
def preorder_traversal_iterative(root):
stack = []
stack.append(root)
while stack:
node = stack.pop()
visit(node)
if node.right:
stack.append(node.right)
if node.left:
stack.append(node.left)
```
迭代方法中,我们首先将根节点推入栈中,然后在栈非空的情况下,重复以下步骤:从栈中弹出一个节点并访问它,先将右子节点推入栈中(如果存在),再将左子节点推入栈中(如果存在)。这样可以保证左子树先于右子树被处理,因为栈是后进先出的数据结构。
## 3.2 二叉搜索树的原理及其实现
### 3.2.1 二叉搜索树的特性
二叉搜索树(BST, Binary Search Tree)是一种特殊的二叉树,它满足以下性质:
- 每个节点的左子树只包含小于当前节点的数。
- 每个节点的右子树只包含大于当前节点的数。
- 左右子树也必须分别为二叉搜索树。
这种特性使得二叉搜索树对于查找、插入和删除操作非常高效,时间复杂度为 O(log n),在最坏的情况下(如树退化为链表时)退化为 O(n)。
### 3.2.2 查找、插入和删除操作
查找操作的逻辑是:
- 从根节点开始,比较目标值与当前节点值。
- 如果目标值小于当前节点值,递归查找左子树。
- 如果目标值大于当前节点值,递归查找右子树。
- 如果目标值等于当前节点值,则查找成功。
```python
def search_bst(node, key):
if node is None or node.value == key:
return node
if key < node.value:
return search_bst(node.left, key)
else:
return search_bst(node.right, key)
```
插入操作的逻辑是:
- 查找插入位置:通过与查找类似的过程找到叶子节点的父节点。
- 创建新节点:创建一个新节点作为父节点的左子节点(或右子节点),如果父节点的值大于(或小于)新节点的值。
```python
def insert_bst(node, key):
if node is None:
return Node(key)
else:
if key < node.value:
node.left = insert_bst(node.left, key)
else:
node.right = insert_bst(node.right, key)
return node
```
删除操作的逻辑是最复杂的,因为它需要处理以下三种情况:
1. 被删除的节点是叶子节点,直接删除。
2. 被删除的节点有一个子节点,用其子节点代替被删除节点。
3. 被删除的节点有两个子节点,用其右子树中的最小节点(或左子树中的最大节点)替换被删除节点,然后删除那个最小(或最大)节点。
```python
def delete_bst(node, key):
if node is None:
return node
if key < node.value:
node.left = delete_bst(node.left, key)
elif key > node.value:
node.right = delete_bst(node.right, key)
else:
# Node with only one child or no child
if node.left is None:
temp = node.right
node = None
return temp
elif node.right is None:
temp = node.left
node = None
return temp
# Node with two children: Get the inorder successor (smallest in the right subtree)
temp = minValueNode(node.right)
node.value = temp.value
node.right = delete_bst(node.right, temp.value)
return node
```
## 3.3 平衡树和堆结构的应用
### 3.3.1 AVL树和红黑树的平衡原理
为了维持二叉搜索树的效率,需要通过一些技术来保持树的平衡,其中AVL树和红黑树是两种常用的自平衡二叉搜索树。
AVL树是一种高度平衡的二叉搜索树,任何节点的两个子树的高度最大差别为1,因此AVL树在查找操作上效率很高,但在插入和删除操作上因为可能要进行多次树旋转操作而变得效率较低。
红黑树在插入和删除操作上比AVL树效率更高,因为它允许树在平衡条件上更宽松。红黑树必须满足以下性质:
1. 每个节点要么是红色,要么是黑色。
2. 根节点是黑色。
3. 所有叶子节点(NIL节点,空节点)都是黑色。
4. 每个红色节点的两个子节点都是黑色(即从每个叶子到根的所有路径上不能有两个连续的红色节点)。
5. 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
### 3.3.2 堆和优先队列的关系及其应用
堆是一种特殊的完全二叉树,它的特性是任何一个父节点的值都必须大于或等于(小于或等于)其子节点的值。在堆中,父节点的键值总是大于(或小于)任何一个子节点的键值。堆通常用来实现优先队列。
优先队列是一种可以提供多种优先级的数据结构,可以高效地管理一组元素和它们的优先级,允许插入任意数据值,而具有最高优先级的元素总能被最先移除。
堆可以通过数组来实现,父节点和子节点之间的关系可以用以下公式表示:
- 父节点的索引 = (子节点的索引 - 1) / 2
- 左子节点的索引 = 父节点索引 * 2 + 1
- 右子节点的索引 = 父节点索引 * 2 + 2
下面是一个简单的堆操作的伪代码,包括插入和删除最大元素的操作:
```python
def heapify(arr, n, i):
largest = i
l = 2 * i + 1
r = 2 * i + 2
if l < n and arr[i] < arr[l]:
largest = l
if r < n and arr[largest] < arr[r]:
largest = r
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
def insert_heap(arr, n, key):
n += 1
arr[n] = key
while n != 1 and arr[n] > arr[(n - 1) // 2]:
arr[n], arr[(n - 1) // 2] = arr[(n - 1) // 2], arr[n]
n = (n - 1) // 2
return arr
def extract_max(arr, n):
key = arr[0]
arr[0] = arr[n - 1]
n -= 1
heapify(arr, n, 0)
return key
```
在以上伪代码中,`heapify` 函数用于重新调整堆以满足堆的性质;`insert_heap` 函数用于向堆中插入新元素;`extract_max` 函数用于移除堆中的最大元素,并返回它。通过这些操作,我们可以用堆实现优先队列的高效管理。
# 4. 高效算法设计技巧
## 4.1 算法复杂度分析
在软件开发过程中,算法的性能至关重要。无论是处理海量数据,还是实现实时交互,一个高效的算法设计都能显著提升应用的性能。算法复杂度是衡量算法性能的标尺,它包括时间和空间两个主要维度。
### 4.1.1 时间复杂度和空间复杂度
时间复杂度关注的是算法执行时间随输入数据规模增长的变化趋势,而空间复杂度则关注算法执行过程中所需的存储空间随输入数据规模增长的变化趋势。在实际应用中,理想的状态是算法的时间复杂度和空间复杂度都尽可能低,但在很多情况下,两者之间存在权衡。
为了更直观地表达这些复杂度,通常使用大O表示法,例如,一个简单的遍历操作具有O(n)的时间复杂度,意味着算法执行时间与输入数据量n成正比。
### 4.1.2 最坏情况、平均情况和最好情况分析
复杂度分析还涉及对算法在不同情况下的性能进行评估。最坏情况分析能为算法性能提供保障,保证在任何情况下算法都不会超过这个性能瓶颈。平均情况分析则给出了算法在实际应用中的平均性能,尽管它可能难以精确计算。而最好情况分析提供了算法性能的最佳可能,但往往并不具有实际参考价值。
下面是分析算法性能的典型代码示例:
```python
def linear_search(arr, target):
for index, value in enumerate(arr):
if value == target:
return index
return -1
# 代码逻辑分析
# 此函数实现线性搜索,遍历数组arr以寻找目标值target。
# 时间复杂度分析:在最坏情况下(目标值位于数组末尾或不存在),需要遍历整个数组,因此时间复杂度为O(n)。
# 空间复杂度分析:由于只使用了固定数量的额外空间,空间复杂度为O(1)。
```
## 4.2 贪心算法与动态规划
贪心算法和动态规划是两种常用的算法设计技术,它们都能高效地解决特定类型的问题。
### 4.2.1 贪心策略的基本原理和适用场景
贪心算法是每一步选择中都采取当前状态下最优的选择,从而希望导致结果是全局最优的算法。它适用于问题具有"贪心选择性质"的情况,即局部最优解能决定全局最优解。
### 4.2.2 动态规划解决问题的步骤和实例
动态规划(Dynamic Programming, DP)则是一种将复杂问题分解为更小的子问题,并存储子问题的解,避免重复计算的技术。它适用于问题具有"最优子结构"和"重叠子问题"特性。
下面通过一个经典问题来说明动态规划的应用:
```python
def fibonacci(n):
dp = [0] * (n+1)
dp[1] = 1
for i in range(2, n+1):
dp[i] = dp[i-1] + dp[i-2]
return dp[n]
# 代码逻辑分析
# 此函数通过动态规划方法计算斐波那契数列的第n项。
# 每一步的状态都是前两个状态的和,体现了最优子结构。
# 时间复杂度为O(n),空间复杂度也为O(n),因为存储了所有子问题的解。
```
## 4.3 分治法与回溯算法
分治法和回溯算法是解决复杂问题的又一策略,它们在很多问题上有出色的表现。
### 4.3.1 分治法的设计思想和经典问题
分治法(Divide and Conquer)的核心思想是将大问题分解为若干个小问题,分别解决这些小问题,再将小问题的解合并为大问题的解。经典的分治算法包括快速排序、归并排序等。
### 4.3.2 回溯法在组合问题中的应用
回溯法(Backtracking)是一种在问题求解过程中回溯搜索解空间的技术。通过尝试分步去解决一个问题,在分步的每一步中,都会利用以前步骤的结果,若发现已不满足求解条件,则取消上一步甚至是上几步的计算,再通过其他的可能的分步解来求解问题。
下面是使用回溯法解决组合问题的示例代码:
```python
def solve_n_queens(n):
def is_safe(board, row, col):
# 检查列冲突
for i in range(row):
if board[i] == col or \
board[i] - i == col - row or \
board[i] + i == col + row:
return False
return True
def solve(board, row):
if row == n:
result.append(board[:])
return
for col in range(n):
if is_safe(board, row, col):
board[row] = col
solve(board, row + 1)
board[row] = -1
result = []
solve([-1]*n, 0)
return result
# 代码逻辑分析
# 此函数解决N皇后问题,找到所有不冲突的N皇后放置方式。
# is_safe函数检查当前放置是否会导致冲突。
# solve函数尝试所有可能的放置,并在找到解决方案时记录下来。
# 时间复杂度为O(n!),因为有n!种可能的放置方式。
```
下一章将具体探讨在实际问题中如何应用数据结构,结合树结构来处理大数据,使用栈和队列优化网络编程,以及在算法优化中选择合适的数据结构。
# 5. 实际问题中的数据结构应用案例
在IT行业,数据结构不仅是一门理论知识,更是解决实际问题的利器。本章将深入探讨数据结构在不同领域中的应用案例,以及如何根据问题场景选择合适的数据结构,以达到优化算法和提高性能的效果。
## 5.1 大数据处理中的树结构应用
在处理海量数据时,树结构因其出色的性能和特性,成为数据存储和检索的首选。本节将分析B树和B+树在数据库索引中的应用,以及哈希树在数据去重和快速检索中的应用。
### 5.1.1 B树和B+树在数据库索引中的应用
数据库索引是提高查询速度的关键技术之一。B树和B+树具有良好的平衡性和多路搜索能力,在数据库索引中广泛应用。
#### B树特性
- 保证树的平衡性,所有叶子节点都在同一层。
- 节点可存储多于两个子节点,使得树的高度大大减小。
- 适合读写操作频繁的环境。
#### B+树特性
- B+树的所有数据都存储在叶子节点中,且相邻叶子节点之间有指针连接。
- 非叶子节点仅用作索引,提高空间利用率。
- 由于有指针连接,范围查询效率更高。
在数据库设计时,如果需要频繁地进行范围查询,B+树通常是更好的选择。而对于读写平衡的场景,则可以使用B树。
### 5.1.2 哈希树在数据去重和快速检索中的应用
哈希树,又称为哈希表,它通过哈希函数将键映射到数据所在的位置。这种数据结构在数据去重和快速检索中表现出色。
#### 哈希树结构
- 数据存储在一个数组中,每个数组元素是一个数据节点,或称为桶。
- 哈希函数根据数据的关键字计算出该数据应该存储的索引位置。
#### 应用场景
- 快速查找:哈希函数直接计算出关键字对应的索引,实现快速访问。
- 数据去重:通过哈希函数确保关键字相同的元素只能存储在一个位置。
在处理大数据时,哈希树可以有效减少数据冗余,并提高数据检索的速度。
## 5.2 网络编程中的栈和队列应用
在进行网络编程时,栈和队列是处理数据流和消息队列的基础结构。
### 5.2.1 网络通信协议中的队列模型
在网络通信中,队列模型被用于数据包的排队发送和接收。
#### 队列在TCP/IP中的应用
- 数据发送:TCP协议使用队列模型管理待发送的数据包,按照先进先出的原则进行发送。
- 数据接收:服务器端应用程序通常通过队列来处理并发连接,保证请求的顺序处理。
#### 队列在消息队列系统中的应用
- 消息队列系统(如RabbitMQ、Kafka)利用队列对异步消息进行管理,保证消息顺序和高效传输。
### 5.2.2 栈在HTTP请求处理中的应用
HTTP请求处理过程中,栈的数据结构可以用于存储和管理请求的历史记录。
#### 栈的应用
- 浏览器的历史记录就是使用栈结构来管理的。后进的页面会覆盖先进页面,后退按钮可以迅速返回到之前的页面。
通过栈的特性,我们可以快速地进行历史记录的管理,提高用户体验。
## 5.3 优化算法中的数据结构选择
算法优化往往伴随着对数据结构的深入理解和合理应用。本节将分析数据结构选择对算法效率的影响,并通过实际案例说明其作用。
### 5.3.1 选择合适数据结构对算法效率的影响
在解决算法问题时,数据结构的合理选择可以优化算法性能。
#### 数据结构选择原则
- 根据问题特点选择:例如图问题适合使用邻接表或邻接矩阵。
- 考虑时间与空间复杂度:权衡算法的时间和空间效率。
- 算法操作的便利性:如排序问题选择堆结构。
### 5.3.2 实际案例分析:数据结构在算法优化中的作用
通过对比使用不同数据结构解决问题的效果,可以明显看到优化前后的性能差异。
#### 实际案例
- 使用堆结构实现优先队列可以显著提高任务调度效率。
- 哈希表在解决查找问题时比数组或链表更高效。
通过实际案例的分析,我们可以更直观地理解数据结构在优化算法中所扮演的角色,以及如何根据具体情况选择最合适的结构。
本章通过对数据结构在实际问题中的应用案例进行深入分析,展示了数据结构在现实世界问题解决中的重要性。理解并掌握这些高级的应用技巧,对于IT行业从业者来说,不仅能够提升编程能力和系统设计水平,更能为解决复杂问题提供强有力的工具支持。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【面试杀手锏】:清华数据结构题,提炼面试必杀技

# 摘要
本文系统地探讨了数据结构在软件工程面试中的重要性和应用技巧。首先介绍了数据结构的理论基础及其在面试中的关键性,然后深入分析了线性结构、树结构和图论算法的具体概念、特点及其在解决实际问题中的应用。文章详细阐述了各种排序和搜索算法的原理、优化策略,并提供了解题技巧。最
WMS系统集成:ERP和CRM协同工作的智慧(无缝对接,高效整合)

# 摘要
随着信息技术的发展,企业资源规划(ERP)和客户关系管理(CRM)系统的集成变得日益重要。本文首先概述了ERP系统与仓库管理系统(WMS)的集成,并分析了CRM系统与WMS集成的协同工作原理。接着,详细探讨了ERP与CRM系统集成的技术实现,包括集成方案设计、技术挑战
HiGale数据压缩秘籍:如何节省存储成本并提高效率
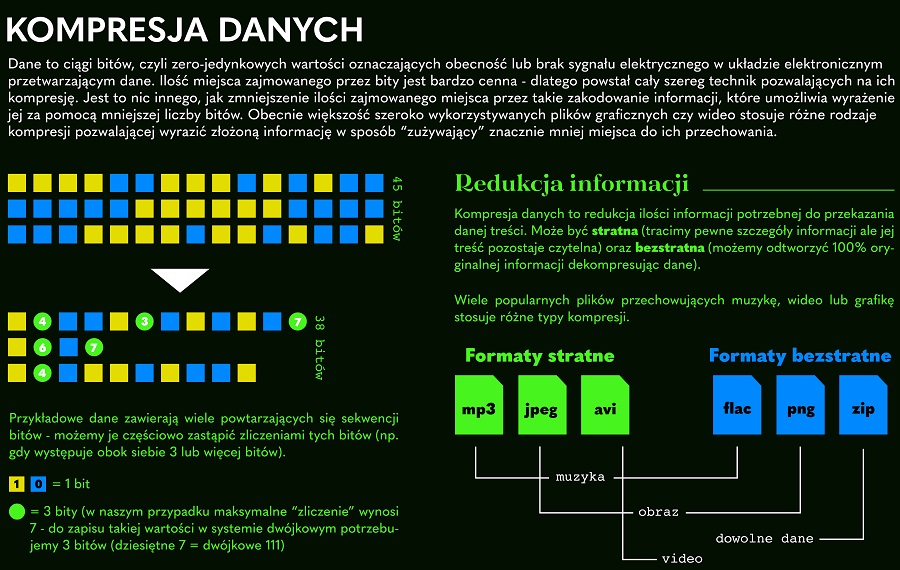
# 摘要
随着数据量的激增,数据压缩技术显得日益重要。HiGale数据压缩技术通过深入探讨数据压缩的理论基础和实践操作,提供了优化数据存储和传输的方法。本论文概述了数据冗余、压缩算法原理、压缩比和存储成本的关系,以及HiGale平台压缩工具的使用和压缩效果评估。文中还分析了数据压缩技术在
温度传感器校准大师课:一步到位解决校准难题

# 摘要
温度传感器校准对于确保测量数据的准确性和可靠性至关重要。本文从温度传感器的基础概念入手,详细介绍了校准的分类、工作原理以及校准过程中的基本术语和标准。随后,本文探讨了校准工具和环境的要求,包括实验室条件、所需仪器设备以及辅助软件和工具。文章第三章深入解析了校准步骤,涉及准备工作、测量记录以及数据
CPCI规范中文版深度解析:掌握从入门到精通的实用技巧
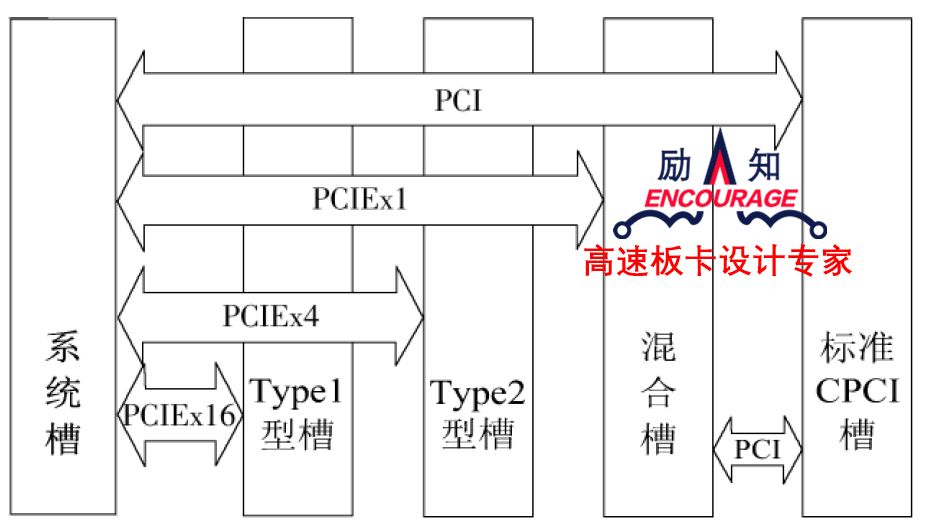
# 摘要
CPCI规范作为一种在特定行业内广泛采用的技术标准,对工业自动化和电子制造等应用领域具有重要影响。本文首先对CPCI规范的历史和发展进行了概述,阐述了其起源、发展历程以及当前的应用现状。接着,深入探讨了CPCI的核心原理,包括其工作流程和技术机制。本文还分析了CPCI规范在实际工作中的应用,包括项目管理和产品开发,并通过案例分析展示了CPCI规范的成功应用与经验教训。此外,文章对CPCI规范的高级应用技
【UML用户体验优化】:交互图在BBS论坛系统中的应用技巧
# 摘要
UML交互图作为软件开发中重要的建模工具,不仅有助于理解和设计复杂的用户交互流程,还是优化用户体验的关键方法。本文首先对UML交互图的基础理论进行了全面介绍,包括其定义、分类以及在软件开发中的作用。随后,文章深入探讨了如何在论坛系统设计中实践应用UML交互图,并通过案例分析展示了其在优化用户体验方面的具体应用。接着,本文详细讨论了UML交互图的高级应用技巧,包括与其他UML图的协同工作、自动化工具的运用以及在敏捷开发中的应用。最后,文章对UML交互图在论坛系统中的深入优化策略进行了研究,并展望了其未来的发展方向。
# 关键字
UML交互图;用户体验;论坛系统;软件开发;自动化工具;
【CRYSTAL BALL软件全攻略】:从安装到高级功能的进阶教程
# 摘要
CRYSTAL BALL软件是一套先进的预测与模拟工具,广泛应用于金融、供应链、企业规划等多个领域。本文首先介绍了CRYSTAL BALL的安装和基本操作,包括界面布局、工具栏、菜单项及预测模型的创建和管理。接着深入探讨了其数据模拟技术,涵盖概率分布的设定、模拟结果的分析以及风险评估和决策制定的方法。本文还解析了CRYSTAL BALL的
【复杂设计的公差技术】:ASME Y14.5-2018高级分析应用实例
# 摘要
公差技术是确保机械组件及装配精度的关键工程方法。本文首先
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )