大数据处理新选择:Google Guava在Bigtable与Table模块的应用(数据科学必读)
发布时间: 2024-09-26 09:53:55 阅读量: 71 订阅数: 37 

提升你的Java应用性能改善数据处理Java开发Java经

# 1. 大数据处理与Google Guava概述
随着数据量的指数级增长,大数据处理已成为IT领域的重要分支。在这个背景下,如何有效管理和处理海量数据成为行业关注的焦点。Google Guava作为一个成熟的Java库,它提供了一系列实用的工具和类库,极大地简化了大数据处理中的许多常见任务。
## 1.1 大数据处理的复杂性
大数据处理不仅仅是数据量的问题,它涉及到数据的采集、存储、计算和分析等多个环节。每个环节都可能遇到性能瓶颈、系统稳定性以及安全性等诸多挑战。
## 1.2 Google Guava库简介
Google Guava是由Google开发的开源Java库,它为Java集合框架提供了大量的扩展。这些扩展不仅简化了代码,还增加了许多新的集合类型,如不可变集合、多集、多映射等。Guava通过提供实用工具类,极大地提高了开发效率和代码质量。
## 1.3 Guava与大数据处理的结合
在大数据处理领域,Google Guava提供了一系列工具和方法来帮助开发者应对复杂性。例如,其集合框架的扩展可以用于高效的数据聚合和转换,而函数式编程的特性则为复杂的数据处理流程提供了便利。接下来的章节将深入探讨Guava的基础特性和其在大数据处理中的实际应用。
# 2. Google Guava基础与特性
## 2.1 Guava库的核心概念
### 2.1.1 Java集合框架的扩展
Google Guava库是对Java标准库的增强和补充。它由一群Google工程师维护,旨在简化Java开发,提供更丰富、更方便的集合框架操作,以及一系列实用工具。Java集合框架虽然强大,但缺少一些在实际应用中非常有用的工具,例如缓存、多线程处理、函数式编程接口等。Guava的出现就是为了弥补这些不足。
Guava提供了一些新的集合类型,例如`Multiset`, `Multimap`和`Table`,这些类型在特定情况下可以替代传统的`Set`, `Map`和`List`,提供更加灵活的数据处理能力。例如,`Multiset`允许存储重复的元素,而不需要额外的包装对象。
```java
// 示例代码:使用Multiset
Multiset<String> multiset = HashMultiset.create();
multiset.add("apple");
multiset.add("banana");
multiset.add("apple");
// 计算苹果和香蕉的数量
int appleCount = multiset.count("apple");
int bananaCount = multiset.count("banana");
```
Guava的集合类型还提供了很多方便的工具方法来处理集合,如`Iterables`和`Collections2`。这些工具方法极大地简化了集合的迭代和转换过程。
### 2.1.2 缓存机制与数据结构
Guava提供了一套非常实用的缓存机制,这些缓存不是简单的缓存策略,而是完整的缓存解决方案。例如`LoadingCache`,这是一个自动加载缓存的实现,能够根据需要延迟加载数据。这对于处理大数据集是非常有用的,可以有效地避免一次性加载所有数据到内存中。
缓存机制在大数据处理中的优势在于能够减少对原始数据源的访问,提高数据访问速度,同时通过缓存策略可以降低对数据的重复处理。
```java
// 示例代码:使用LoadingCache
LoadingCache<String, MyObject> cache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterAccess(5, TimeUnit.MINUTES)
.build(new CacheLoader<String, MyObject>() {
public MyObject load(String key) throws Exception {
// 根据key加载数据
return loadDataFromDatabase(key);
}
});
MyObject myObject = cache.get("someKey");
```
Guava提供的数据结构如`ForwardingList`, `ForwardingMap`等,允许开发者在不改变原有接口的基础上,实现对集合的扩展和定制。这样的设计允许开发者在不影响现有代码的情况下,轻松地扩展集合的功能。
## 2.2 Guava在大数据处理中的作用
### 2.2.1 提高数据处理效率
在大数据环境中,效率是至关重要的。传统的数据处理方法可能无法满足性能要求,这时候Guava就可以发挥巨大作用。它提供的各种工具和库,能够帮助开发者写出更高效、更简洁的代码。
例如,Guava的`Joiner`和`Splitter`工具类提供了一种简单而强大的方法来处理字符串的合并和分割,这对于处理数据记录非常有用。
```java
// 示例代码:使用Joiner和Splitter
Joiner joiner = Joiner.on(',').skipNulls();
String result = joiner.join("apple", null, "banana", "cherry");
Splitter splitter = Splitter.on(',').omitEmptyStrings();
List<String> parts = splitter.splitToList(result);
```
Guava还提供了对并行处理的强大支持,如`Iterables`类中的`partition`方法,可以将迭代器中的元素分割成固定大小的多个片段,这有助于实现并行处理,从而提高处理大数据的效率。
### 2.2.2 强大的函数式编程支持
函数式编程是一种编写代码的方式,它强调使用函数来处理数据和流程。Guava为Java提供了丰富的函数式编程工具,使得在Java中实现函数式编程成为可能。例如,`Function`, `Predicate`和`Supplier`等函数式接口,可以在集合处理中大量使用。
在处理大数据集时,函数式编程可以提供更清晰的代码结构和更好的抽象,从而提高代码的可读性和可维护性。同时,利用函数式编程的特性,还可以更容易地实现并行处理和高阶函数。
```java
// 示例代码:使用Predicate过滤集合
Predicate<String> startsWithA = new Predicate<String>() {
public boolean apply(String input) {
return input.startsWith("a");
}
};
List<String> filteredList = Lists.newArrayList(Iterables.filter(strings, startsWithA));
```
在大数据处理中,函数式编程特别有用,因为它可以帮助开发者以声明式的方式表达数据处理逻辑,降低程序的复杂度,使得数据流的处理更加直观。
## 2.3 Guava与Bigtable的结合
### 2.3.1 Bigtable的数据模型与操作
Google Bigtable是一个可扩展的、分布式的非关系型数据库。它由Google内部用于处理大量数据,比如搜索索引、用户数据等。Guava与Bigtable的结合,可以让开发者在使用Bigtable时获得更简洁、更方便的代码。
Bigtable的数据模型非常简单,它的核心是一个稀疏的、分布式的、持久化排序映射。这意味着Bigtable的数据是由行、列(以及列族)、时间戳和单元格值构成的。Guava可以帮助我们在操作Bigtable数据时进行更高效的数据映射和处理。
```java
// 示例代码:使用Guava进行Bigtable数据操作
Table<String, String, Long> table = ... // 初始化Bigtable Table实例
// 插入数据
Put put = Put.builder("row-key").set("column-family", "column", 12345L).build();
table.put(put);
```
### 2.3.2 利用Guava简化Bigtable操作
Bigtable的API可以比较复杂,但是利用Guava的功能可以使操作变得更简单。Guava提供的`FluentIterable`、`Optional`等工具可以帮助我们以更声明式的方式进行数据操作和转换。
```java
// 示例代码:使用FluentIterable对Bigtable数据进行处理
FluentIterable<Row> rows = FluentIterable.from(table.readRows("start-key", "end-key"))
.limit(100);
List<Row> filteredRows = rows.filter(new Predicate<Row>() {
public boolean apply(Row row) {
return row.cells().hasCell("some-family", "some-column");
}
}).transform(new Function<Row, Row>() {
public Row apply(Row row) {
// 处理每一个Row对象
return row;
}
}).toList();
```
此外,Guava的`BiMap`、`Multimap`等数据结构可以与Bigtable的行键设计相结合,通过将不同的键值映射到同一数据行,提供了一种灵活的行键设计方式。
在大数据处理中,利用Guava简化Bigtable操作是一个非常实际且有效的方法,它不仅提升了代码的可读性,也提高了开发效率。
# 3. Google Guava在Bigtable模块的应用
## 3.1 Bigtable的数据模型与Guava特性结合
### 3.1.1 利用Guava进行高效数据映射
在处理大数据时,数据映射是一个关键步骤,它确保了数据从一个格式转换到另一个格式的准确性和效率。Google Guava库提供了一套丰富的工具来优化数据映射过程。通过Guava的`Table`接口,开发者可以创建一个可以同时作为Map和List使用的数据结构,使得映射过程更加直观和高效。
考虑一个Bigtable的场景,其中的行键可能需要映射到多个不同的属性值。利用Guava的`HashBasedTable`或`TreeBasedTable`可以为每行创建一个映射,把行键映射到一个包含多个列值的`Multimap`。以下是使用Guava进行高效数据映射的示例代码:
```java
// 引入Guava库
***mon.collect.HashBasedTable;
***mon.collect.Table;
// 创建一个Table,用于存储行键到列值的映射
Table<String, String, List<String>> bigtableDataMap = HashBasedTable.create();
// 假设有一个数据条目,行键为"row1",列键为"col1",值为"data1"
String rowKey = "row1";
String columnKey = "col1";
String dataValue = "data1";
// 将数据添加到Table中,如果存在相同的行键和列键,则值将被添加到列表中
List<String> values = bigtableDataMap.get(rowKey, columnKey);
if (values == null) {
values = new ArrayList<>();
bigtableDataMap.put(rowKey, columnKey, values);
}
values.add(dataValue);
// 输出Table的内容
System.out.println(bigtableDataMap);
```
在上述

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Google Guava 工具包的全面指南!本专栏深入探讨了 Guava 的核心 API 和使用技巧,旨在帮助您掌握这个强大的 Java 库。从集合处理到并发编程、高效 IO 操作和 JSON 处理,我们涵盖了广泛的主题。
通过真实案例分析、独家技巧和专家建议,您将学习如何使用 Guava 简化日常开发任务、提升代码健壮性、优化数据操作效率并解决数学问题。此外,我们还探讨了 Guava 在 Bigtable 和 Table 模块中的应用,以及如何将其与 Java 8 协同工作以提升性能。
无论您是 Java 开发新手还是经验丰富的专家,本专栏都将为您提供宝贵的见解和实用技巧,帮助您充分利用 Google Guava,提升您的 Java 编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
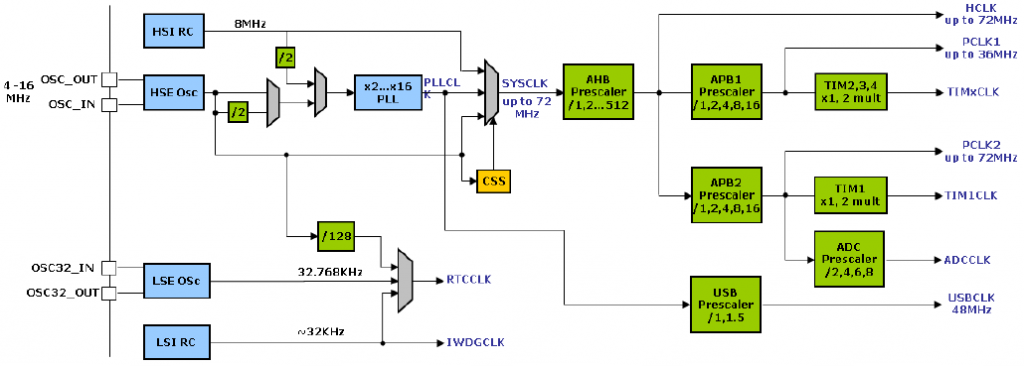
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
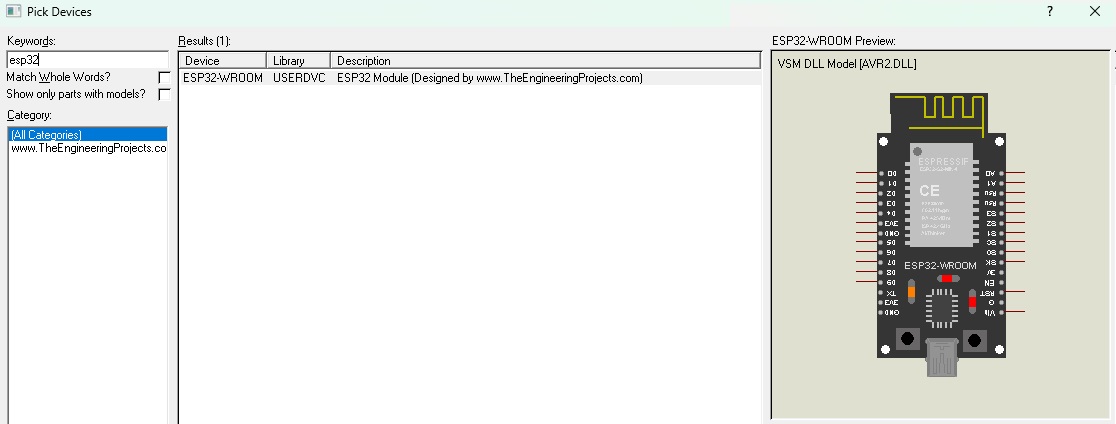
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )