【对象散列与序列化】:Google Guava的Hashing与Objectify高级应用(Java开发者攻略)
发布时间: 2024-09-26 09:45:32 阅读量: 94 订阅数: 37 

guava-stream:用于 Guava 不可变集合的 Java 8 Stream API 收集器

# 1. 对象散列与序列化的理论基础
在软件开发领域,数据的存储与传输处理是核心问题之一。对象散列与序列化是解决这一问题的关键技术,它们在数据结构、数据库和网络通信等领域发挥着重要作用。本章将介绍对象散列和序列化的基础理论,为深入理解后续章节中的框架和应用打下坚实基础。
## 1.1 对象散列的定义及其重要性
对象散列是一种将对象转换为固定长度值(散列码)的技术,该值能代表对象的唯一性。散列码通常用于提高数据检索的速度,尤其是在哈希表(Hash Table)结构中。一个好的散列函数应该能够均匀分布散列码,减少冲突的可能性,从而提升整体性能。
## 1.2 序列化的概念及其应用场景
序列化是指将对象状态转换为可存储或可传输的格式(如字节流)的过程。反序列化则是将这些字节流恢复为原始对象状态的过程。序列化在分布式应用、数据持久化、网络通信等场景中至关重要,它允许对象在不同的环境和系统中被轻松存储和传输。
## 1.3 对象散列与序列化的关联
尽管散列和序列化是解决不同问题的技术,但它们在实际应用中经常交织在一起。例如,在需要高效检索的场景中,对象可能首先被散列以获得快速定位,然后再序列化以存储或传输。了解它们之间的关联,有助于更好地设计和优化数据处理流程。
在后续章节中,我们将深入探讨Google Guava Hashing框架如何实现高效的散列处理,Java序列化机制的原理及高级特性,以及Google Guava Objectify库如何简化对象持久化操作。通过这些内容,我们将构建起对对象散列与序列化全面而深入的理解。
# 2. Google Guava Hashing框架的深入解析
### 2.1 Hashing框架的核心概念
#### 2.1.1 散列函数的作用与重要性
散列函数在计算机科学中充当了关键角色,尤其是在数据存储和检索方面。它能将输入数据转换为固定长度的唯一散列值,无论输入数据的大小如何。在哈希表或数据结构的上下文中,散列函数是高效的关键,因为它们允许快速定位存储的数据。使用散列函数时,最重要的是要确保它均匀地分布散列值,以减少冲突,提高整体性能。
#### 2.1.2 Hashing框架的结构与组成
Google Guava的Hashing框架提供了高效、高质量的散列函数实现。它允许开发者选择不同的散列算法,如MD5、SHA-1、Adler32等,并为散列值的生成提供了清晰的API。在Hashing框架的结构中,可以通过工厂模式来创建散列器实例,它们都被设计为不可变且线程安全的。
### 2.2 实现高效散列的策略
#### 2.2.1 常见的散列算法与选择
选择合适的散列算法取决于应用程序的需求。例如,SHA-256提供了一个强度较高的散列值,适用于加密目的,而Fowler–Noll–Vo (FNV) 散列函数则在性能上表现出色。Guava Hashing框架通过提供的各种实现,使得开发者可以根据应用场景轻松选择和使用不同的散列算法。
#### 2.2.2 优化散列性能的实践方法
为了优化散列性能,需要考虑散列算法的选择、输入数据的处理以及散列值的使用。例如,合理设计数据结构的键可以减少冲突;同时,为了避免性能瓶颈,可以采用并行处理和分批散列等策略。Guava Hashing框架也提供了如Hashing.md5()和Hashing.sha256()等便捷方法,使得在Java中实现这些策略变得轻而易举。
### 2.3 实战:基于Guava Hashing的应用案例
#### 2.3.1 创建自定义哈希函数
创建自定义哈希函数时,我们可以通过继承AbstractHashFunction并重写makeHasher()方法来完成。以下是使用Guava Hashing框架创建一个自定义哈希函数的示例代码:
```java
public class CustomHashFunction extends AbstractHashFunction {
@Override
public Hasher newHasher() {
return new CustomHasher();
}
}
class CustomHasher extends Hasher {
private byte[] bytes = new byte[16]; // 假设我们的哈希值为128位
private int len = 0; // 当前缓存的字节数
@Override
public Hasher putBytes(byte[] bytes, int off, int len) {
// 更新内部状态的逻辑
// ...
return this;
}
@Override
public HashCode hash() {
return HashCode.fromBytesNoCopy(bytes);
}
}
```
在这个示例中,我们创建了一个基本的框架,定义了如何处理输入的字节,并提供了如何计算最终散列值的逻辑。
#### 2.3.2 案例分析:如何处理散列冲突
处理散列冲突是散列应用中的一个重要方面。在实践中,我们可以采用“链地址法”或“开放寻址法”等策略。Guava Hashing框架的实现允许我们利用其强大的API来辅助冲突解决。例如,我们可以设计键的哈希码算法以最小化冲突,或者使用Guava的表结构来处理冲突,其内部已经为我们处理好了大部分冲突解决的机制。
通过上述案例,我们可以看出,借助Guava Hashing框架的强大功能,实现高效的散列和处理散列冲突变得更加简单和高效。从选择合适的散列算法到创建自定义哈希函数,再到案例分析中的冲突处理,Guava Hashing框架都提供了丰富的工具和方法,以应对不同的散列需求。
# 3. Java对象序列化与反序列化的机制
## 3.1 Java序列化的基础
### 3.1.1 序列化的定义和序列化过程
序列化是指将对象状态信息转换为可以存储或传输的形式的过程。在Java中,这一过程主要通过ObjectOutputStream类实现。序列化可以保存对象的字段以及类的元数据,以便在需要时,能够完整地重建对象。
序列化过程通常涉及到以下几个步骤:
1. 确保你的类实现了Serializable接口。这是使用Java序列化所必需的。
2. 创建一个ObjectOutputStream实例,它与某个输出流(如文件输出流)关联。
3. 调用ObjectOutputStream实例的writeObject方法,将对象写入到输出流。
```java
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("objectfile.ser"))) {
oos.writeObject(yourObject);
}
```
上述代码中,`yourObject`是我们想要序列化的对象。`ObjectOutputStream`的`writeObject`方法会将对象的状态信息写入到`"objectfile.ser"`文件中。注意,我们使用了try-with-resources语句来自动关闭流。
### 3.1.2 序列化的控制与优化策略
为了更好的控制序列化过程,可以通过以下策略进行优化:
1. 使用`transient`关键字。这个关键字可以防止类的特定字段被序列化。通常用于那些不应该被保存下来的敏感数据,比如密码。
2. 实现`writeObject`和`readObject`方法。如果默认的序列化行为不满足需求,可以通过这两个方法自定义序列化的行为。
3. 使用`Externalizable`接口。如果需要更细粒度的控制,可以通过实现`Externalizable`接口替换`Serializable`接口,并实现`readExternal`和`writeExternal`方法。
```java
private void writeObject(ObjectOutputStream out) throws IOException {
// 自定义写入逻辑
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
// 自定义读取逻辑
}
```
在上述代码中,`writeObject`和`readObject`方法允许开发者精确控制哪些对象数据应该被序列化和反序列化。
## 3.2 序列化技术的高级特性
### 3.2.1 可外部化对象(Externalizable)
`Externalizable`接口继承自`Serializable`接口,允许对象控制自己的序列化过程。当对象实现`Externalizable`接口时,必须提供两个方法:`writeExternal`和`readExternal`。这些方法分别用于写入和读取对象状态。
```java
public class MyObject implements Externalizable {
private int data;
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeInt(data);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
data = in.readInt();
}
}
```
在上面的例子中,`MyObject`类实现了`Externalizable`接口,通过`writeExternal`和`readExternal`方法,我们可以自定义对象数据的序列化和反序列化逻辑。
### 3.2.2 版本控制与兼容性处理
随着应用程序的发展,对象的类可能会改变。为了处理序列化对象的版本兼容性问题,可以使用`serialVersionUID`。这个版本号可以帮助系统识别序列化对象的版本,从而解决兼容性问题。
```java
private static final long serialVersionUID = 1L;
```
通过声明一个`serialVersionUID`

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Google Guava 工具包的全面指南!本专栏深入探讨了 Guava 的核心 API 和使用技巧,旨在帮助您掌握这个强大的 Java 库。从集合处理到并发编程、高效 IO 操作和 JSON 处理,我们涵盖了广泛的主题。
通过真实案例分析、独家技巧和专家建议,您将学习如何使用 Guava 简化日常开发任务、提升代码健壮性、优化数据操作效率并解决数学问题。此外,我们还探讨了 Guava 在 Bigtable 和 Table 模块中的应用,以及如何将其与 Java 8 协同工作以提升性能。
无论您是 Java 开发新手还是经验丰富的专家,本专栏都将为您提供宝贵的见解和实用技巧,帮助您充分利用 Google Guava,提升您的 Java 编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
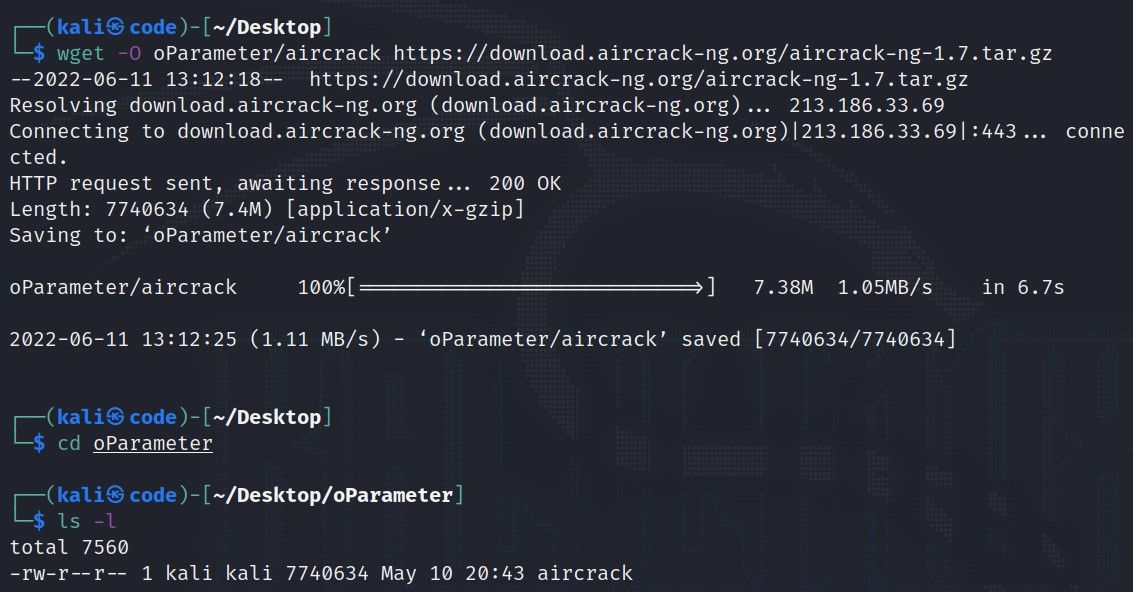
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )